

获取汽车品牌的API接口及图片链接

在深度学习和人工智能领域,DeepSeek模型因其独特的创新性和卓越的性能而备受瞩目。本篇文章将深入解析DeepSeek的源码,从网络架构、训练算法到具体实现,全面揭示其背后的技术原理和应用场景。
传统的Transformer模型在处理注意力机制时,通常会消耗大量的计算资源,尤其是在大规模数据推理时更为明显。DeepSeek通过引入多头潜在注意力机制(MLA),在保证高效推理的同时,大幅减少了kv缓存的需求。MLA通过低秩key-value联合压缩,实现了比传统多头注意力(MHA)更高的效率。
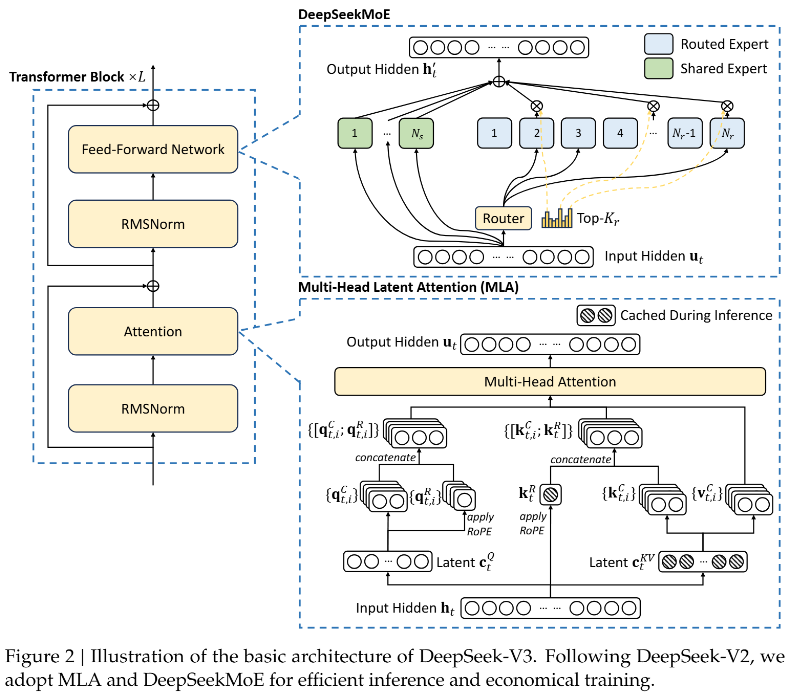
DeepSeek在其前馈神经网络(FFN)层中采用了MoE架构,将专家划分为更细粒度的专业化模块。这样做的目的是在相同的激活参数下,能比传统MoE架构获得更高的准确性和更优的性能。通过合理的路由机制,DeepSeek保证不同设备间的负载均衡,从而提高整体计算效率。
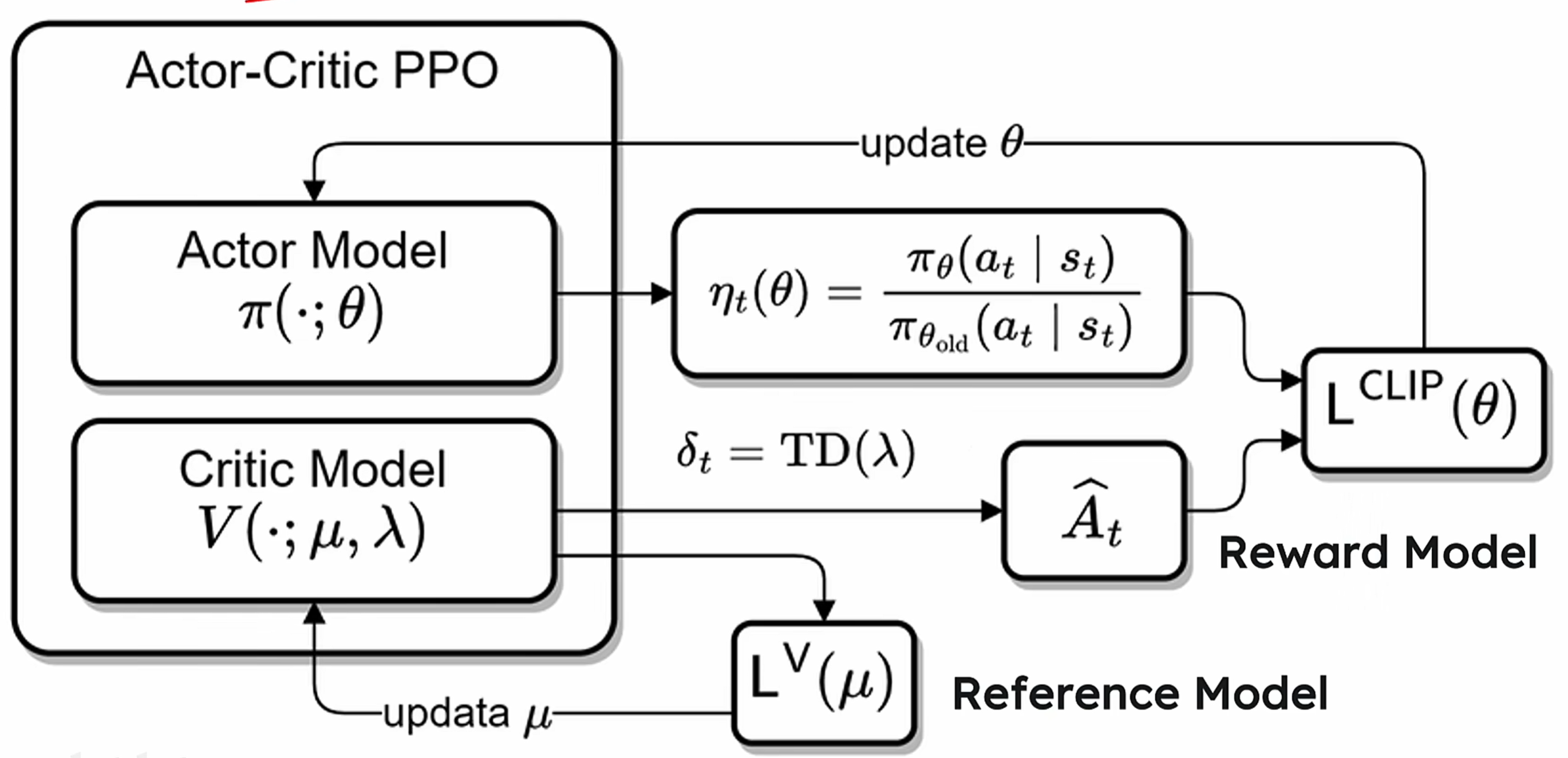
DeepSeek在训练过程中使用了强化学习技术,尤其是采用了Group Relative Policy Optimization(GRPO)算法。与传统的PPO和DPO相比,GRPO去掉了价值模型,通过对多个输出的奖励进行计算,有效推动了模型的进化。其独特的奖励函数设计,避免了复杂的advantage计算,使得模型在逻辑推理和复杂任务上的表现尤为出色。
为了应对大模型在推理时的显存消耗,DeepSeek使用了量化技术,将浮点数转换为更低位的整数形式。这不仅降低了存储需求,还提高了推理的速度。在FP8格式下,DeepSeek通过分块量化计算,避免了精度损失,确保了计算的准确性。
DeepSeek在推理阶段采用了多种并行计算策略,包括数据并行、模型并行和流水线并行等。在DualPipe框架下,DeepSeek实现了计算和通信的高效重叠,显著减少了流水线气泡,提高了GPU的利用率。

与传统的逐Token预测不同,DeepSeek采用了多Token预测策略,大幅提升了推理速度。通过在训练阶段引入MTP模块,使得模型能够同时输出多个Token的表示,大大增加了上下文信息的利用。
DeepSeek在自然语言处理任务中表现出色,尤其是在长文本处理和复杂逻辑推理上。通过其独特的架构和训练方法,DeepSeek能够有效理解和生成高质量的文本内容。
在大规模数据分析中,DeepSeek的快速推理能力和高效的资源利用,使其成为处理海量信息的理想选择。其创新的量化和并行策略,确保了在复杂计算任务中的稳定性和准确性。
随着技术的发展,DeepSeek团队正在探索更多的自我迭代和优化方式。通过进一步提升模型的自我反思能力,DeepSeek有望在不久的将来实现更高层次的智能化应用。
DeepSeek的开源策略为开发者提供了宝贵的学习和应用机会。通过社区的共同努力,DeepSeek将不断更新迭代,为更多行业带来创新的解决方案。
DeepSeek凭借其在网络架构、训练算法和推理优化上的多重创新,已成为大模型领域的佼佼者。其在多样化应用场景中的优异表现,为未来的人工智能发展提供了重要的参考和启示。
问:DeepSeek的多头潜在注意力机制有什么优势?
问:DeepSeek如何实现并行计算的优化?
问:DeepSeek适用于哪些应用场景?
问:DeepSeek模型的训练如何保证数据的高效利用?
问:DeepSeek在未来的发展方向是什么?







