多层感知机(MLP)深度解析
多层感知机(MLP)作为深度学习中的一个基础模型,在众多领域中发挥着重要作用。本文将深入探讨MLP的基本概念、优缺点、应用场景、构建模型时的注意事项、实现类库、评价指标,并通过实际代码示例来详细解析MLP的实现过程。
MLP是什么
多层感知机的定义与结构
多层感知机(Multilayer Perceptron,简称MLP)是一种前馈神经网络,由多个神经元层组成,每层与前一层全连接。这种结构使得MLP能够处理分类、回归和聚类等机器学习问题。在MLP中,输入层接收输入特征,隐藏层提取特征和进行非线性变换,输出层给出预测结果。
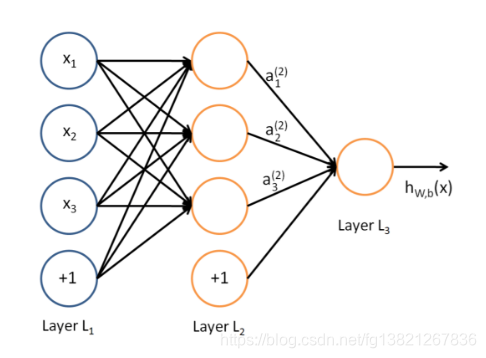
神经元与连接权重
MLP中的每个神经元接收前一层的输出,通过加权和与激活函数运算产生当前层的输出。通过迭代训练,MLP学习输入特征间的复杂关系,对新数据进行预测。
MLP的优点与缺点
优点分析
强大的表达能力
MLP能够处理非线性问题和高维数据,具有强大的表达能力。
自动学习特征
通过反向传播算法,MLP可以自动学习特征和模式,无需人工干预。
泛化能力强
MLP能够处理多分类和回归问题,具有较好的泛化能力。
防止过拟合
通过添加正则化项、dropout等技术,MLP可以有效地防止过拟合。
缺点探讨
训练时间长
MLP的训练时间较长,需要大量的计算资源和时间。
对初始化敏感
MLP对初始权重和偏置的选择比较敏感,可能导致模型陷入局部最优解。
数据预处理要求高
MLP对数据的标准化和预处理要求较高,需要进行归一化、标准化等处理。
可解释性差
MLP难以解释和理解,不如决策树等模型具有可解释性。
MLP的应用场景
计算机视觉
MLP在计算机视觉领域有广泛应用,如图像分类、目标检测和图像分割等。
自然语言处理
在自然语言处理领域,MLP可以用于文本分类、情感分析和机器翻译等任务。
推荐系统
MLP在推荐系统中用于个性化推荐和广告推荐。
金融风控
MLP在金融风控领域用于信用评分和欺诈检测。
医疗健康
MLP在医疗健康领域用于疾病诊断、药物预测和基因分类。
工业制造
MLP在工业制造中用于质量控制、故障诊断和预测维护。
构建MLP模型的注意事项
在构建MLP模型时,需要根据实际情况调整网络结构、激活函数、优化器和损失函数,以达到最佳效果。这一过程对经验依赖较大。
MLP模型的实现类库
TensorFlow与Keras
TensorFlow和Keras是实现MLP的常用框架,它们提供了丰富的API和灵活的模型定制能力。
PyTorch
PyTorch也是一个流行的深度学习框架,其动态图模式方便了模型的调试和开发。
scikit-learn
scikit-learn提供了MLPClassifier和MLPRegressor类,可以方便地构建MLP模型。
MLP模型的评价指标
准确率
准确率是最常用的分类问题评价指标,反映了分类正确的样本数占总样本数的比例。
精确率与召回率
精确率和召回率分别反映了模型对正类的识别能力和覆盖能力。
F1值
F1值是精确率和召回率的调和平均数,综合考虑了两者的性能。
ROC曲线与AUC值
ROC曲线和AUC值反映了模型在不同阈值下的性能,AUC值越大,模型性能越好。
scikit-learn实现MLP的例子
示例代码
以下是使用scikit-learn库实现MLP的示例代码:
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy: ", accuracy)
digits = load_digits()
X = digits.data
y = digits.target
X = X / 16.0
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
model = MLPClassifier(hidden_layer_sizes=(100,), max_iter=200, alpha=1e-4,
solver='sgd', verbose=10, tol=1e-4, random_state=1,
learning_rate_init=.1)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy: ", accuracy)代码解释
上述代码首先加载了MNIST数据集,并进行了数据预处理。然后,使用train_test_split函数将数据集划分为训练集和测试集。接着,使用MLPClassifier类构建了一个MLP模型,并指定了隐层神经元个数、最大迭代次数、正则化参数等超参数。最后,使用fit方法训练模型,并使用accuracy_score函数计算模型在测试集上的准确率。
MLP的模型参数
以下是MLPClassifier的一些常见模型参数:
hidden_layer_sizes:隐藏层神经元的数量和层数。activation:激活函数的类型,可以是’identity’、’logistic’、’tanh’或’relu’。solver:优化算法的类型,可以是’lbfgs’、’sgd’或’adam’。alpha:L2正则化项的权重。batch_size:优化算法中使用的小批量样本的数量。learning_rate:学习率的类型,可以是’constant’、’invscaling’或’adaptive’。learning_rate_init:初始学习率。power_t:学习率更新的指数。max_iter:最大迭代次数。shuffle:在每次迭代中是否对样本进行洗牌。random_state:随机种子。tol:优化算法的收敛容忍度。early_stopping:是否启用早停策略。validation_fraction:用于早停策略的验证集比例。beta_1:Adam优化算法的指数衰减率。beta_2:Adam优化算法的指数衰减率的平方。
FAQ
问:MLP的隐藏层应该设置多少神经元?
答:MLP隐藏层神经元的数量取决于具体问题和数据集的大小,通常需要通过实验来确定。
问:MLP的训练时间为什么那么长?
答:MLP的训练时间长是因为其需要进行大量的迭代计算,尤其是在处理大规模数据集时。
问:MLP如何防止过拟合?
答:MLP可以通过添加正则化项、dropout等技术来防止过拟合。
问:MLP与决策树相比有什么优势?
答:MLP能够处理非线性问题和高维数据,具有更强的表达能力和泛化能力。
问:MLP的评价指标有哪些?
答:MLP的评价指标包括准确率、精确率、召回率、F1值、ROC曲线和AUC值等。
本文详细介绍了多层感知机的基本概念、优缺点、应用场景、建模时的注意事项、评价指标和实现方法,并通过代码示例深入解析了MLP的实现过程。希望通过本文,读者能够对MLP有一个全面而深入的理解。
最新文章
- 小红书AI文章风格转换:违禁词替换与内容优化技巧指南
- REST API 设计:过滤、排序和分页
- 认证与授权API对比:OAuth vs JWT
- 如何获取 Coze开放平台 API 密钥(分步指南)
- 首次构建 API 时的 10 个错误状态代码以及如何修复它们
- 当中医遇上AI:贝业斯如何革新中医诊断
- 如何使用OAuth作用域为您的API添加细粒度权限
- LLM API:2025年的应用场景、工具与最佳实践 – Orq.ai
- API密钥——什么是API Key 密钥?
- 华为 UCM 推理技术加持:2025 工业设备秒级监控高并发 API 零门槛实战
- 使用JSON注入攻击API
- 思维链提示工程实战:如何通过API构建复杂推理的AI提示词系统