

全网最详细的Spring入门教程

在现代深度学习技术中,LSTM(长短期记忆网络)算法是一种具有突出表现的时间序列处理方法。本文将详细介绍LSTM算法的原理、结构、应用及其在深度学习中的重要性。
循环神经网络(Recurrent Neural Network,RNN)是一种专门用来处理序列数据的神经网络模型。其独特的循环结构使其能够记忆前序数据的状态,因此非常适合处理时间序列任务。例如,在自然语言处理中,RNN能够根据上下文来预测下一个词。然而,传统的RNN在处理长序列时会遭遇梯度消失或梯度爆炸的问题。
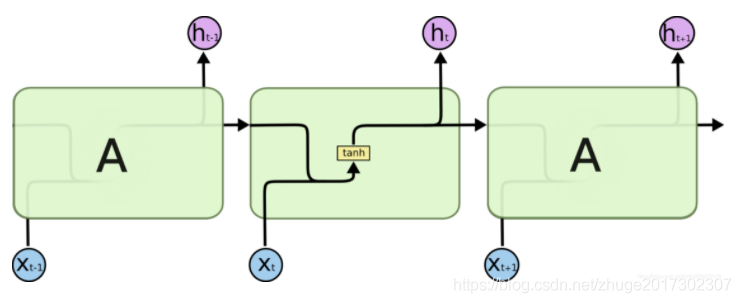
长短期记忆网络(LSTM)是一种经过设计改良的RNN,能够有效缓解长序列训练中的梯度消失问题。LSTM通过引入遗忘门、输入门和输出门来控制信息的流动,从而实现对重要信息的长期保留和不重要信息的遗忘。
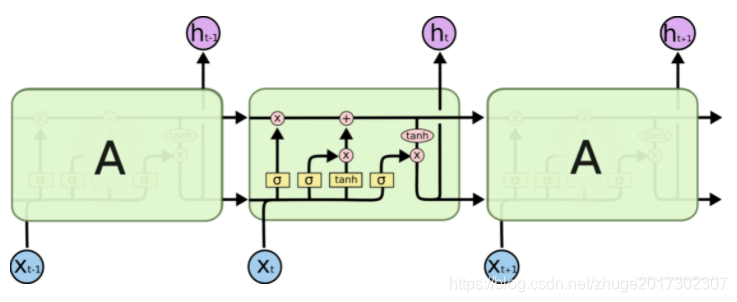
LSTM的核心在于其单元结构中增加了细胞状态(cell state),这一机制如同传送带,能够在时间序列中传递信息而不被轻易修改。
传统RNN使用sigmoid或tanh作为激活函数,这些函数在多层网络中容易导致梯度消失。具体来说,当输入值通过多个层的sigmoid函数时,其导数会逐渐趋近于零,导致网络无法学习到有用的长程依赖信息。
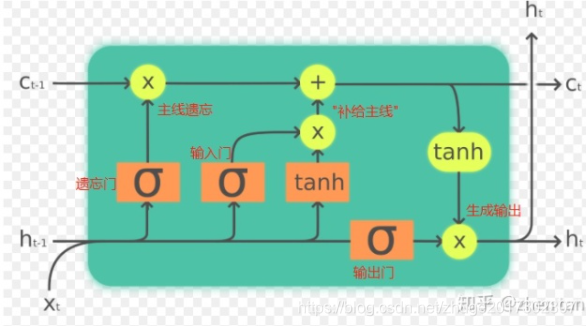
LSTM通过引入门控机制(即遗忘门、输入门和输出门)来控制信息的流动,使得网络可以在长时间序列中保持重要信息。遗忘门决定需要丢弃哪些信息,输入门决定新信息的存储,而输出门则决定输出哪些信息。
遗忘门通过sigmoid函数计算,输入为上一个时间步的输出和当前输入。输出值在0到1之间,表示需要保留信息的比例。
输入门同样通过sigmoid函数控制新信息的保存。输入门的输出决定了哪些新信息应该被加入到细胞状态中。
输出门决定了从细胞状态中输出哪些信息,通过sigmoid与tanh的结合来实现信息的筛选。
在一个LSTM单元中,计算公式如下:
遗忘门:
( f_t = sigma(Wf cdot [h{t-1}, x_t] + b_f) )
输入门:
( i_t = sigma(Wi cdot [h{t-1}, x_t] + b_i) )
( tilde{C}_t = tanh(WC cdot [h{t-1}, x_t] + b_C) )
细胞状态更新:
( C_t = ft cdot C{t-1} + i_t cdot tilde{C}_t )
输出门:
( o_t = sigma(Wo cdot [h{t-1}, x_t] + b_o) )
( h_t = o_t cdot tanh(C_t) )
GRU是LSTM的变种之一,简化了LSTM的结构,将输入门和遗忘门合并为一个更新门。其结构更为简单,计算量也较低。
窥视孔LSTM允许门限看到前一时刻的细胞状态,从而在门限计算时加入更多的上下文信息。
LSTM在自然语言处理、语音识别、时间序列预测等领域有着广泛应用。其在长时间序列数据处理上的优势,使得其在机器翻译、语音识别和视频分析等任务中取得了显著成效。
LSTM作为深度学习领域的重要算法,其在处理长时间依赖问题上的优越性使其成为时间序列处理的首选算法之一。通过对信息流动的精细控制,LSTM能够在长时间序列中保留重要信息,为复杂任务提供强大的支持。
问:LSTM与RNN有什么区别?
问:LSTM在哪些领域有应用?
问:GRU和LSTM的主要区别是什么?







