Transformer论文原文深度解读与应用
Transformer模型的起源与背景
在深度学习领域,Transformer的出现不仅简化了模型结构,还极大地提高了训练效率和模型性能。
传统模型的局限性
在Transformer出现之前,RNN、LSTM和GRU等递归网络是序列建模的主流。然而,这些模型存在难以并行化、信息丢失和内存开销大的问题。由于它们是一步一步计算的,每一步都依赖前一状态,这导致了序列过长时处理效率低下。Transformer通过注意力机制解决了这些问题。

Transformer的架构设计
Transformer的架构由编码器和解码器两个部分组成。编码器将输入序列转换为中间表示,解码器则从中间表示生成输出序列。每个编码器和解码器都由多个层组成,每一层包括多头自注意力机制和前馈神经网络。
编码器与解码器的细节
编码器的每一层由两个子层组成:多头自注意力机制和前馈神经网络。解码器在编码器的基础上增加了一个用于获取编码器输出的注意力层。每个子层后都附有残差连接和归一化操作,确保信息流在网络中顺畅传递。

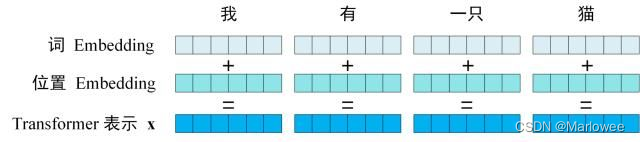
输入表示与位置编码
Transformer的输入由单词嵌入和位置嵌入相加而成。单词嵌入可以通过预训练获得,位置嵌入则用于保留序列的位置信息。位置编码的设计让模型可以处理任意长度的序列,并保持对相对位置的敏感性。
注意力机制的核心
Transformer的核心是注意力机制,尤其是自注意力。注意力机制可以看作是从输入到输出的全局依赖建模,允许模型在不使用循环结构的情况下捕获序列间的依赖关系。
自注意力机制的计算
自注意力机制通过对输入序列的每个位置计算查询、键和值,然后通过点积计算注意力权重,最后加权求和得到输出。这个过程不仅提高了并行计算能力,还使得模型能够捕获长程依赖关系。
out = self.fc_out(out)
return outclass SelfAttention(torch.nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = torch.nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = torch.nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = torch.nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = torch.nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.nn.functional.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out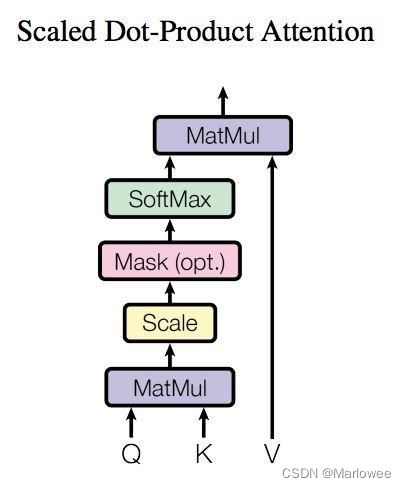
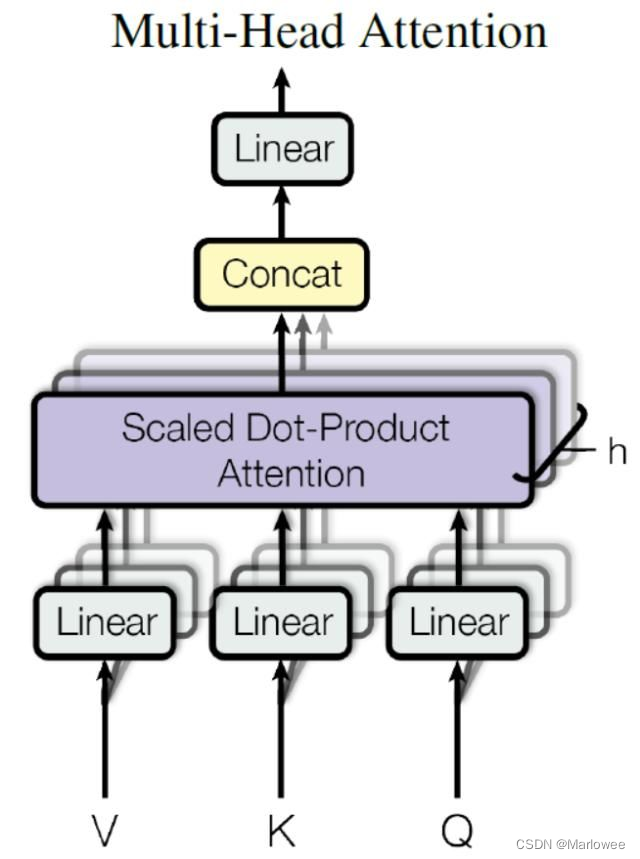
多头注意力机制
多头注意力机制是自注意力的扩展。通过并行计算多个注意力头,模型可以关注到不同的特征子空间,从而增强信息提取能力。每个头的输出经过拼接和线性变换,最终得到多头注意力的结果。
Transformer在机器翻译中的应用
Transformer在机器翻译任务中取得了显著的成功,其优越的并行性和高效的训练使得它在大规模数据集上表现出色。尤其是在WMT2014英语到德语和英语到法语的翻译任务中,Transformer模型创造了新的基准。
实验结果与分析
在WMT2014英语-德语翻译任务中,Transformer的BLEU评分达到28.4,超过了之前所有的模型。在WMT2014英语-法语任务中,Transformer的BLEU得分为41.0,同样领先于其他模型。
Transformer的未来与扩展
Transformer不仅在NLP领域表现出色,其模型架构的灵活性使得它在其他任务中也有广泛应用的潜力。未来,Transformer有望在图像、音频和视频处理等领域中发挥更大的作用。
FAQ
-
问:Transformer模型与传统RNN相比有何优势?
- 答:Transformer模型通过注意力机制实现了更高的并行性和效率,避免了RNN中的长距离依赖问题。
-
问:什么是多头注意力机制?
- 答:多头注意力机制是通过多个注意力头并行计算来增强模型的特征提取能力。
-
问:Transformer能应用于哪些领域?
- 答:Transformer不仅在NLP中表现出色,还可以应用于计算机视觉、图像处理、音频分析等领域。
-
问:为什么Transformer在机器翻译中表现优异?
- 答:Transformer的并行计算能力和高效的注意力机制使其在大规模翻译任务中表现出色。
-
问:如何提升Transformer的训练效率?
- 答:通过优化超参数、使用更高性能的硬件和改进数据预处理流程可以提升Transformer的训练效率。
最新文章
- 小红书AI文章风格转换:违禁词替换与内容优化技巧指南
- REST API 设计:过滤、排序和分页
- 认证与授权API对比:OAuth vs JWT
- 如何获取 Coze开放平台 API 密钥(分步指南)
- 首次构建 API 时的 10 个错误状态代码以及如何修复它们
- 当中医遇上AI:贝业斯如何革新中医诊断
- 如何使用OAuth作用域为您的API添加细粒度权限
- LLM API:2025年的应用场景、工具与最佳实践 – Orq.ai
- API密钥——什么是API Key 密钥?
- 华为 UCM 推理技术加持:2025 工业设备秒级监控高并发 API 零门槛实战
- 使用JSON注入攻击API
- 思维链提示工程实战:如何通过API构建复杂推理的AI提示词系统