

JSON 文件在线打开指南

OCR(Optical Character Recognition,光学字符识别)技术是计算机视觉领域的重要方向之一。它将图像中的文字转换为可编辑的电子文本,使得信息处理更加高效。OCR最初用于扫描文档的数字化,但随着技术的发展,其应用场景已扩展到自然场景文字识别(Scene Text Recognition,STR)中。
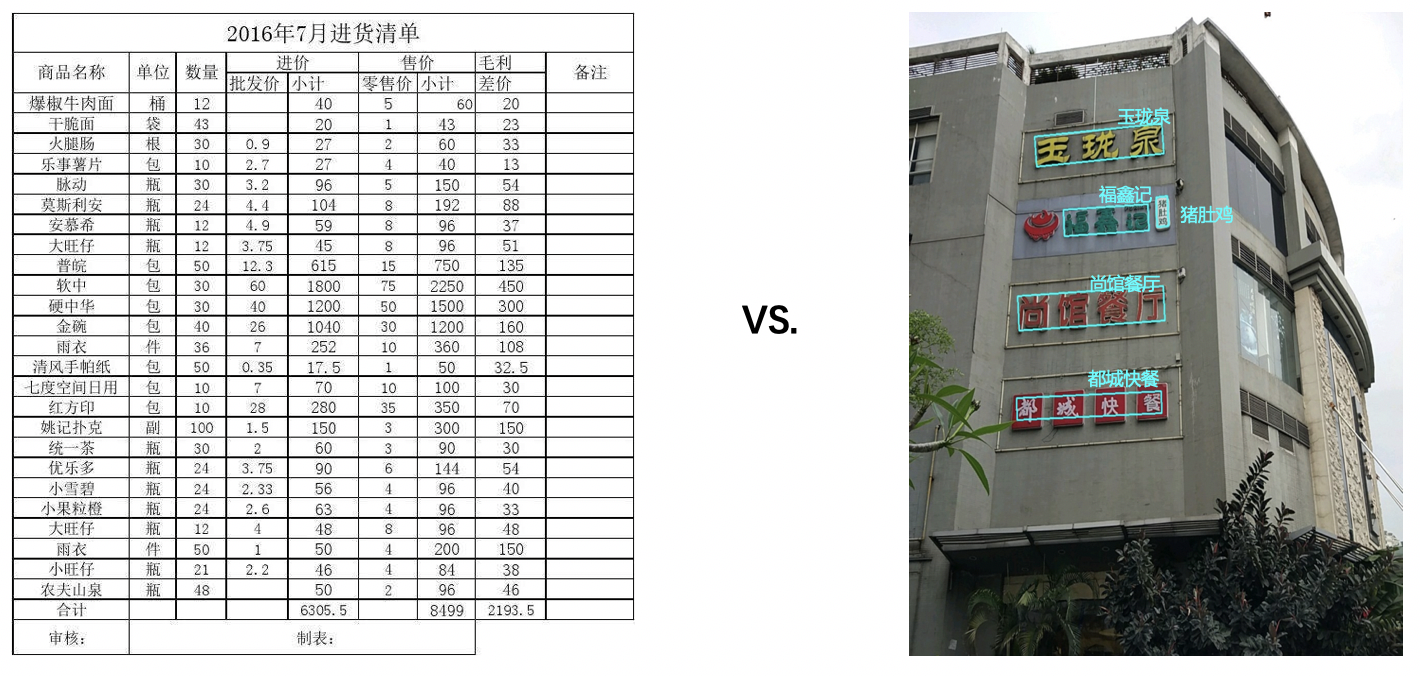
OCR技术广泛应用于车牌识别、银行卡信息识别和身份证信息识别等领域。其应用的共同特点是处理格式固定的文本,适合自动化识别,极大地减少了人力成本。
OCR技术面临算法和应用层面的挑战。算法层面需要解决背景复杂、字体多样化等问题;应用层面则要满足实时处理海量数据和在移动设备上快速识别的需求。
大型语言模型(LLM)通过语义理解、格式修复和多模态信息融合来提升OCR的识别能力。LLM可以在错误识别的情况下,根据上下文推断正确的文本,还能处理包含图像和文本的复杂内容。
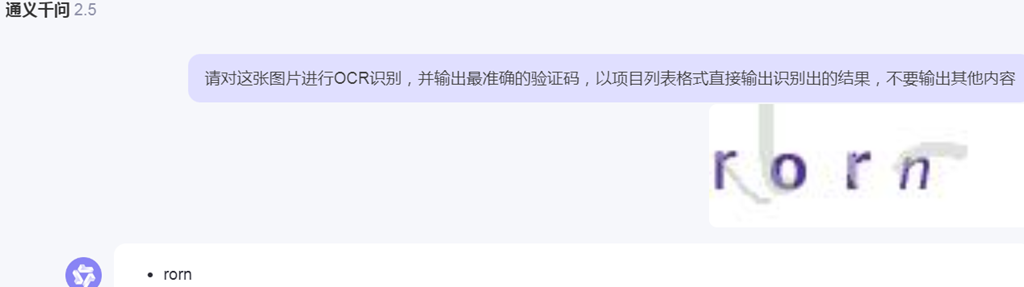
传统OCR技术已有几十年的发展,技术成熟且成本较低,适用于结构化文档。LLM则适合于处理复杂的非结构化文档,虽然成本较高,但在准确性和灵活性上有显著优势。
文本检测通过定位图像中的文字区域,是OCR技术的基础。当前主流的检测算法分为基于回归和基于分割两类。
这些方法借鉴目标检测算法,通过设定anchor点对文本框进行检测,但对不规则文本的效果较差。
引入了Mask-RCNN等技术,适用于各种文本形状,但后处理复杂。

文本识别将检测出的文本区域转换为可编辑的文本。常见方法包括基于CTC和Sequence2Sequence的算法。
这些方法适用于印刷字体和扫描文本,通常采用CRNN等经典算法。
利用矫正模块和Attention机制处理弯曲、遮挡等复杂场景,提升识别准确性。

OCR技术在企业资质审查、银行信贷服务等领域展现出强大的应用潜力。通过自动化识别和数据提取,显著提升了信息处理的效率。
开发者在使用开源模型时面临选型难、不适用产业场景、训练部署困难等挑战,这需要一套完整的OCR开发套件来解决。
PaddleOCR是一个开源OCR开发套件,提供了多种前沿算法和预训练模型,支持多种部署方式,满足不同的应用需求。
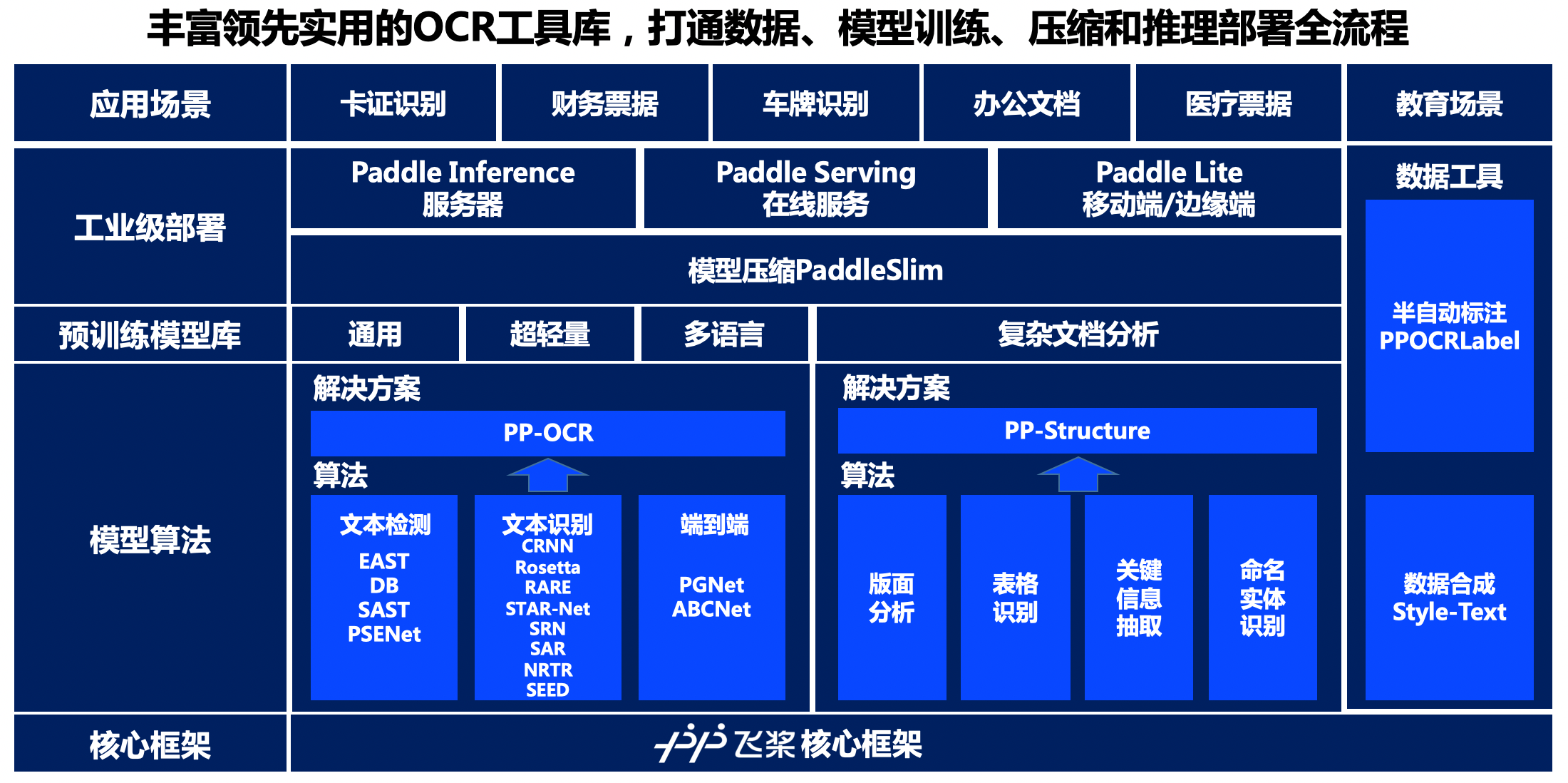
OCR技术将朝着更高精度、更广泛应用的方向发展。深度学习和多模态融合将提升识别能力,实时OCR技术将加快信息处理速度。
数据隐私、技术兼容性和标准化是OCR技术面临的主要挑战。通过加密技术和统一标准,可以提高安全性和兼容性,持续优化算法以提升准确性。
OCR技术不仅简化了数据处理流程,还推动了信息化发展。未来,随着技术的进步,OCR的应用将更加广泛,其在提升公共服务质量和效率方面的贡献将愈发显著。
问:OCR技术如何提高文本识别的准确性?
问:OCR技术在电子政务中有哪些应用?
问:使用OCR技术的主要挑战是什么?





