非线性数据的深度解析与应用
作者:zhilong · 2025-01-23 · 阅读时间:5分钟
非线性数据在现代数据分析和机器学习中扮演着至关重要的角色。理解非线性数据的特性及其处理方法,对于提升模型的预测能力和准确性至关重要。本篇文章将深入探讨非线性数据的概念、特征、应用以及如何通过不同的方法对其进行处理。
非线性数据的概念与特征
非线性数据是指数据集的特征与标签之间的关系无法用简单的线性方程来描述。这种数据倾向于复杂的模式,可能需要高阶多项式或其他非线性函数来进行拟合。通常情况下,非线性数据在可视化时呈现出弯曲或波动的趋势,而不是一条直线。为了更好地理解非线性数据,我们可以借助散点图来进行直观的展示。
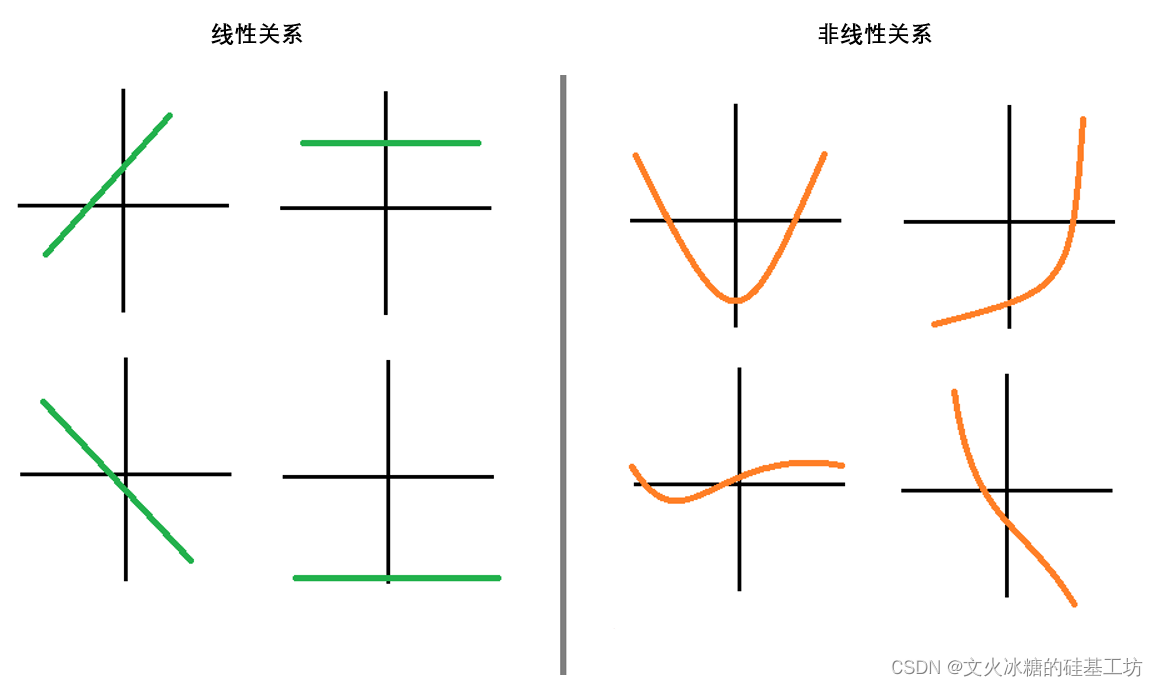
非线性数据的特征
- 复杂性:非线性数据通常表现出复杂的模式和交互性,难以用简单的线性模型来解释。
- 多样性:特征之间的关系可能涉及高阶多项式、指数函数和对数函数等多种形式。
- 可变性:数据在不同的特征空间中可能呈现出不同的非线性特征。
线性与非线性数据的区别
线性数据和非线性数据的区别在于它们的模型拟合方式。线性数据可以使用简单的直线方程进行拟合,而非线性数据则需要更复杂的方程或模型。为了准确捕捉非线性数据的模式,需要考虑使用多项式回归或其他非线性回归方法。
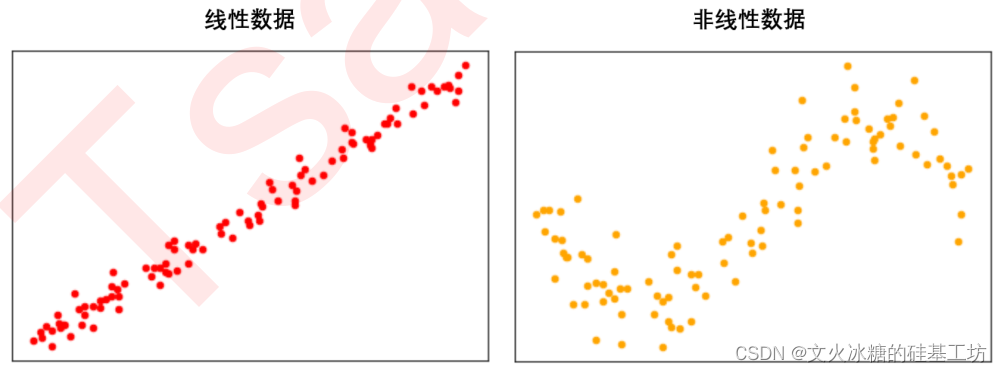
如何识别线性与非线性数据
- 绘制散点图:通过散点图可以直观地观察数据的分布情况。若数据点大致沿直线分布,则可能是线性关系;若呈曲线或不规则分布,则可能是非线性关系。
- 计算相关性:通过计算特征与标签之间的相关系数,可以初步判断其线性或非线性特征。
非线性数据的处理方法
处理非线性数据时,通常有两种主要方法:
特征转换与非线性模型
-
特征转换:例如,通过将特征平方增大其复杂性,使得数据在新的特征空间中呈现线性。
import numpy as np X = np.array([-1+(1-(-1))*(i/10) for i in range(10)]).reshape(-1,1) X2 = X**2 -
使用非线性模型:例如,决策树模型通过节点划分数据空间,适合处理非线性数据。
非线性数据在机器学习中的应用
非线性数据在语音识别和金融预测。
应用实例
- 图像识别:卷积神经网络(CNN)是处理非线性数据的经典模型,能够有效识别图片中的复杂模式。
- 金融预测:非线性回归模型可以用于预测股票市场走势,捕捉市场中的非线性变化。
非线性问题的解决思路
解决非线性问题的关键在于选择合适的模型和特征转换方法。通过对数据的深入分析和理解,可以选择适当的模型和技术来处理非线性数据。
解决步骤
- 数据预处理:对数据进行清洗和标准化,确保数据质量。
- 模型选择:根据数据特征选择合适的非线性模型。
- 特征工程:进行特征转换,增强模型的拟合能力。
结论
处理非线性数据是现代数据科学和机器学习中的重要课题。通过适当的特征转换和模型选择,可以实现对非线性数据的有效分析和预测。在实际应用中,需要根据具体问题灵活应用各种技术和工具,以获得最佳结果。
FAQ
-
问:什么是非线性数据?
- 答:非线性数据是指特征与标签之间的关系不能用简单的线性方程来描述,通常需要复杂的函数或模型进行拟合。
-
问:如何判断数据是否为非线性?
- 答:可以通过绘制散点图观察数据分布,或通过计算特征与标签之间的相关系数来判断。
-
问:处理非线性数据的方法有哪些?
- 答:主要有两种方法:特征转换和使用非线性模型,如决策树和神经网络。
热门推荐
一个账号试用1000+ API
助力AI无缝链接物理世界 · 无需多次注册
3000+提示词助力AI大模型
和专业工程师共享工作效率翻倍的秘密