混淆矩阵:机器学习中的关键工具
在机器学习领域,混淆矩阵作为一种重要的可视化工具,广泛应用于监督学习的模型评价中。它不仅帮助我们理解模型的准确性,还能揭示分类错误的具体类型,为模型优化提供方向。本文将深入探讨混淆矩阵的结构、应用以及其衍生的各种性能指标。
什么是混淆矩阵
混淆矩阵,又称可能性矩阵或错误矩阵,是用于描述分类模型性能的表格。它展示了模型在一组测试数据上的预测结果与实际结果的对比。混淆矩阵通过每一行和每一列来表示实际类别和预测类别,矩阵中的每个元素代表具体的样本数量。
混淆矩阵的基本结构
混淆矩阵的每一列代表预测类别,每一行代表实际类别。例如,在二分类问题中,矩阵结构如下:
- True Positive (TP):真实为正,预测也为正。
- False Negative (FN):真实为正,预测为负。
- False Positive (FP):真实为负,预测为正。
- True Negative (TN):真实为负,预测也为负。
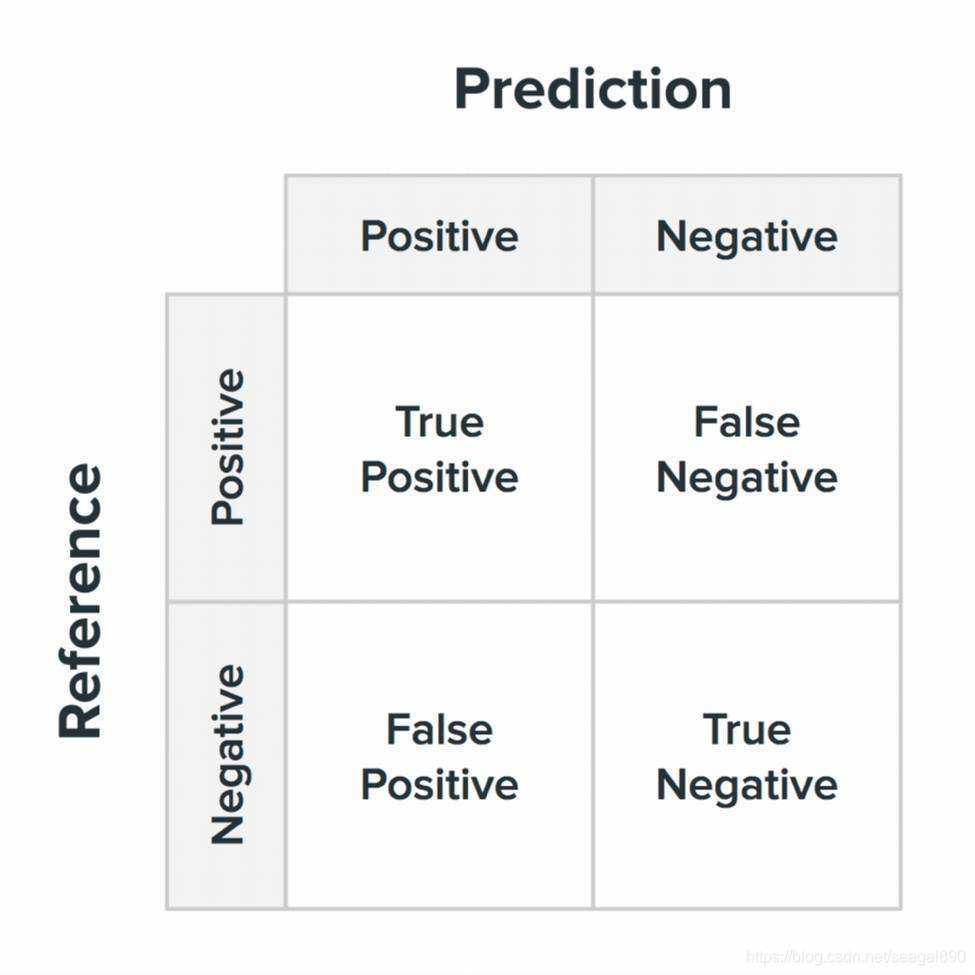
通过分析混淆矩阵,我们可以了解模型的分类错误类型,从而进行有针对性的优化。
混淆矩阵的应用
混淆矩阵可以用于多种类型的分类问题,不仅限于二分类。通过扩展矩阵的行和列,可以适用于多分类问题。以下是混淆矩阵在不同领域中的应用实例。
在图像识别中的应用
在图像识别中,混淆矩阵可用于评估模型对不同类别的识别准确性。例如,在一个包含三类的图像数据集中,混淆矩阵可以显示模型对每个类别的识别正确率和错误率。
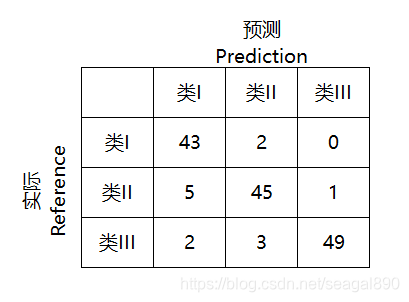
通过这样的矩阵,我们可以发现模型在哪些类别中存在混淆,从而调整数据集或改进模型的训练方式。
在医学诊断中的应用
在医学诊断中,混淆矩阵帮助评估诊断测试的有效性。例如,预测某种疾病的存在与否,混淆矩阵可以显示模型对患者真实病情的预测准确性。
从混淆矩阵到性能指标
混淆矩阵不仅可以直观地显示模型的分类结果,还可以计算出多种性能指标。这些指标对于全面评价模型性能至关重要。
精确率(Accuracy)
精确率是最常用的分类性能指标之一,计算公式为:
[ text{Accuracy} = frac{TP + TN}{TP + FP + TN + FN} ]
精确率表示模型预测正确的样本数量占总样本数量的比例。虽然直观,但在处理不平衡数据集时可能产生误导。
正确率(Precision)和召回率(Recall)
-
正确率(Precision):在模型预测为正的样本中,实际为正的比例。
[ text{Precision} = frac{TP}{TP + FP} ] -
召回率(Recall):在实际为正的样本中,模型预测为正的比例。
[ text{Recall} = frac{TP}{TP + FN} ]
这两个指标往往需要结合使用,以全面评估模型性能。
特异性(Specificity)和灵敏度(Sensitivity)
-
特异性(Specificity):模型识别为负类的样本数量占总负类样本数量的比值。
[ text{Specificity} = frac{TN}{TN + FP} ] -
灵敏度(Sensitivity):与召回率相同,表示模型识别为正类的样本数量占总正类样本数量的比值。
高级性能指标
在某些应用场景中,仅依靠基础指标不足以全面描述模型性能,因此需要引入高级指标。
F1分数
F1分数是正确率和召回率的调和平均数,常用于评估二分类模型的精确度:
[ text{F1 Score} = 2 times frac{text{Precision} times text{Recall}}{text{Precision} + text{Recall}} ]
F1分数在Precision和Recall之间取得平衡,适用于需要同时考虑这两个指标的场景。
AUC和ROC曲线
AUC即ROC曲线下的面积,是评估模型分类性能的重要指标。ROC曲线展示了不同阈值下的TPR和FPR关系。

AUC值越接近1,模型性能越好。通过这种方式可以有效比较不同模型的分类能力。
混淆矩阵在不平衡数据中的挑战
处理不平衡数据是混淆矩阵应用中的一大挑战。在这种情况下,准确率可能会误导我们对模型性能的判断。为了应对这种情况,F1分数、AUC等指标显得尤为重要。
实例分析:混淆矩阵在实际项目中的应用
为了更好地理解混淆矩阵的实际应用,我们以一个信用卡欺诈检测项目为例。该项目中,欺诈交易(正类)数量远少于正常交易(负类)。
数据准备与模型训练
在数据准备阶段,我们应用过采样技术平衡数据集。模型训练使用逻辑回归,并通过交叉验证评估模型的稳定性。
使用混淆矩阵评估模型
在预测结果中,我们通过混淆矩阵评估模型的准确性,识别出高风险交易。此时,F1分数和AUC指标帮助我们更好地理解模型性能。
结论
混淆矩阵是机器学习中不可或缺的工具,帮助我们直观地理解模型的预测能力和错误类型。通过结合使用精确率、召回率、F1分数和AUC等指标,我们可以更全面地评估模型性能,尤其是在不平衡数据集的情况下。未来的研究中,如何更有效地利用混淆矩阵进行模型优化将是一个重要方向。
FAQ
-
问:混淆矩阵在多分类问题中如何应用?
- 答:在多分类问题中,混淆矩阵的行和列会相应增加,每个类别都有对应的行和列,矩阵中每个单元格表示一种具体的分类情况。
-
问:为什么AUC指标重要?
- 答:AUC指标考虑了所有可能的分类阈值,能够全面评估模型的分类性能,特别是在处理不平衡数据集时,AUC的稳定性和可靠性更高。
-
问:如何在Python中生成混淆矩阵?
- 答:在Python中,可以使用sklearn库中的confusion_matrix函数来生成混淆矩阵,并结合matplotlib库进行可视化展示。