各种注意力机制的计算与应用详解
文章目录
在深度学习领域,注意力机制因其强大的信息处理能力而备受关注。本文将详细探讨各种注意力机制的计算过程及其应用,旨在帮助读者深入理解注意力机制的核心原理和实用价值。
Attention机制的引入与必要性
随着神经网络模型的复杂性增加,传统的前馈和循环神经网络在处理长距离依赖时表现出一定的局限性。注意力机制通过选择性地关注重要信息,显著提高了模型的性能。
计算能力的限制
即使前馈和循环神经网络具有强大的能力,计算资源的瓶颈仍然是限制其发展的重要因素。当模型需要记住大量信息时,计算需求和复杂度会急剧增加。注意力机制通过选择性注意,减少了不必要的计算,从而提升了效率。
优化算法的限制
循环神经网络虽然通过局部连接和权重共享等方法来简化计算,但其在长距离依赖问题上的表现欠佳。注意力机制可以模拟人类的注意力,提升信息“记忆”能力,使得模型能够更好地处理长距离依赖关系。
Attention机制的分类与变种
根据不同的注意力方向和重点,注意力机制可以被划分为多种类型。
聚焦式注意力
聚焦式注意力是一种自上而下、有意识的注意力形式,通常用于特定任务的目标聚焦。这种注意力机制在人工神经网络中应用广泛,能够主动筛选关键信息进行处理。
显著性注意力
显著性注意力是自下而上的被动注意力类型,通常由外部刺激触发。它不需要主动干预,适用于任务无关的场景,常常通过max-pooling和门控机制实现。
Attention机制的计算流程
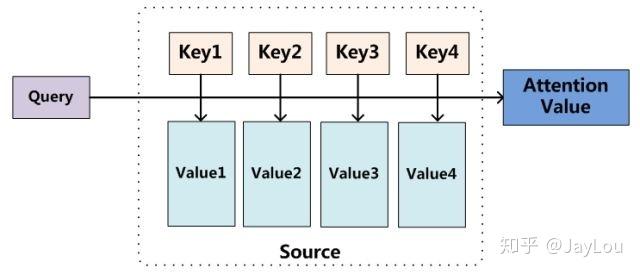
Attention机制的本质是一个寻址(addressing)过程,通过Query、Key和Value三者之间的相互作用实现。
信息输入
首先,将所有输入信息表示为向量X = [x1, · · · , xN]。
注意力分布计算
接着,通过计算Query与Key的相似度,生成注意力分布α。Key和Value通常是相同的,即X。
信息加权平均
最终,根据注意力分布α对输入信息X进行加权平均,得到输出。这种方式被称为软性注意力机制。
Attention机制的变种
Attention机制有多种变体,每种变体在不同的情境下展示出特有的优势。
硬性注意力
硬性注意力只关注特定位置的信息,其选择机制具有随机性,难以通过反向传播训练,需要强化学习方法。
键值对注意力
这种变体中,Key和Value不再相同,通过这种方式可以更精确地控制信息流动。
多头注意力
多头注意力通过多个并行的注意力机制捕捉不同方面的信息,增强了模型的表达能力。
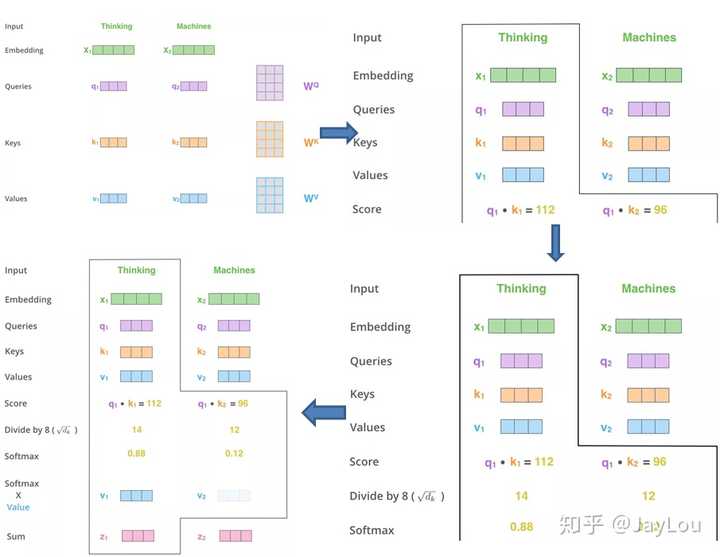
自注意力模型的优势
自注意力模型在处理长距离序列时尤为强大,能够动态生成不同连接的权重,适应变长序列。
卷积与循环网络的局限性
传统的卷积和循环网络在处理长距离依赖时存在局部编码问题,难以有效捕捉全局信息。
自注意力模型的计算流程
自注意力模型通过动态生成权重,实现了对变长序列的处理。这种模型利用Attention机制的动态特性,弥补了传统网络的不足。
Transformer架构详解
Transformer模型在NLP领域引发了革命,彻底改变了自然语言处理的方式。
Transformer的整体架构
Transformer由编码器和解码器组成,每个部分包含多个自注意力层和前馈神经网络。
编码器与解码器的区别
编码器负责将输入序列转换为特征表示,解码器则根据编码器的输出生成目标序列。
在GPT和BERT中的应用
Transformer在GPT和BERT等预训练模型中得到了广泛应用,通过改进提升了词向量的表达能力。
Encoder-Decoder与Self-Attention的区别
在Transformer中,Encoder-Decoder注意力和自注意力机制各自发挥着重要作用,前者侧重于源和目标序列的交互,后者则在捕捉序列的内部结构上表现优异。
结论
注意力机制的引入极大地提升了神经网络处理信息的能力,尤其是在长距离依赖和复杂任务中。通过理解和应用不同类型的注意力机制,研究人员可以设计出更高效、更精确的深度学习模型。
FAQ
-
问:注意力机制如何提升神经网络的效率?
- 答:注意力机制通过选择性关注重要信息,减少了不必要的计算,提高了神经网络的处理效率。
-
问:什么是多头注意力?
- 答:多头注意力是通过多个并行注意力机制捕捉不同信息,增强模型表达能力的技术。
-
问:自注意力模型为何适合处理长距离序列?
- 答:自注意力模型通过动态生成权重,能够适应变长序列,解决了传统网络的局部编码问题。