学习率和梯度下降法的全面解析
机器学习和深度学习的发展离不开优化算法,而其中最基本且最为广泛使用的方法之一便是梯度下降法。本文将深入探讨梯度下降法的各类变体,以及学习率在这些方法中的作用和调节技巧。
梯度下降法的基本概念
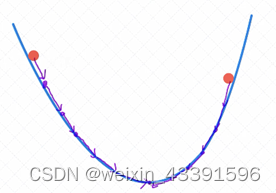
梯度下降法是一种用于寻找函数最小值的优化算法。其核心思想是通过计算目标函数的梯度,沿着梯度下降的方向更新参数,逐步逼近函数的最小值。可以将其类比为一个人从山顶寻找最短路径到山脚的过程,通过不断计算和估计坡度来决定下一步的行进方向和步长。
优点与缺点
梯度下降法在凸优化问题中能够保证找到全局最优解,而在非凸问题中,至少可以找到局部最优解。然而,该方法在处理大规模数据集时,每次迭代所需的计算量可能非常大,从而导致优化速度缓慢。
随机梯度下降法(SGD)
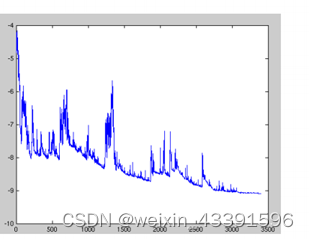
随机梯度下降法(SGD)是一种对经典梯度下降法的改进。与梯度下降法需要遍历所有样本不同,SGD每次仅使用一个样本来更新参数。这种方法极大地提高了计算效率,使得算法在处理大规模数据集时依旧保持较快的收敛速度。
优点与缺点
SGD速度较快,适用于需要频繁更新的场景,但其缺点是目标函数波动较大,可能导致收敛不稳定。因此,通常需要调整学习率以减小波动。
小批量梯度下降法
小批量梯度下降法(Mini-batch Gradient Descent)结合了梯度下降法和随机梯度下降法的优点。它通过在每次迭代中使用一个小批量的数据进行更新,兼顾了计算效率和更新稳定性。

批量大小的选择
批量大小的选择对模型的优化效果有显著影响。较大的批量大小可以减少梯度的方差,使得训练过程更稳定,而较小的批量大小则可以更快地更新参数。
学习率的重要性
学习率是梯度下降算法中的一个关键参数,决定了每次参数更新的步长。过大的学习率可能导致算法发散,而过小的学习率则可能导致收敛速度过慢。
学习率调整策略
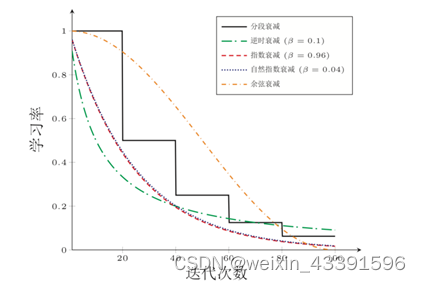
为了更好地控制收敛速度和精度,通常会使用学习率衰减策略,如逆时衰减、分段常数衰减、指数衰减等。这些策略可以根据迭代次数动态调整学习率,以平衡收敛速度和稳定性。
学习率衰减方法
-
逆时衰减(Inverse Time Decay)
- 通过与时间(迭代次数)的倒数成比例地减少学习率。
-
分段常数衰减(Piecewise Constant Decay)
- 在指定的迭代次数后,将学习率减少到原来的某个比例。
-
指数衰减(Exponential Decay)
- 学习率以指数形式随时间衰减。
周期性学习率调整
周期性学习率调整是一种在训练过程中动态调整学习率的方法,以帮助模型跳出局部最优解。常见的方法包括循环学习率和带热重启的随机梯度下降法(SGDR)。
循环学习率
通过在一定范围内周期性地增大和减小学习率,帮助模型摆脱局部极小值的困境。
带热重启的随机梯度下降法(SGDR)
在一定周期后重新初始化学习率,并从先前的参数继续优化。

传统梯度下降法的挑战
传统的梯度下降法面临许多挑战,如收敛速度慢、容易陷入局部最优解、所有参数使用相同的学习率等。为此,研究者提出了多种优化算法,如动量法、Nesterov加速梯度法(NAG)、Adagrad、Adadelta、RMSprop和Adam。
动量法与Nesterov加速梯度法
动量法通过结合上一次的梯度更新,减少目标函数的震荡,提高收敛速度。而NAG则在动量法的基础上,进一步优化了梯度预测。
Adam优化算法
Adam是一种结合了动量法和RMSprop的自适应学习率优化算法。它存储了过去梯度的指数衰减平均值,并通过偏差校正来提高收敛效率。
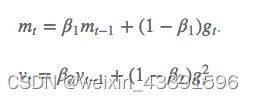
Adam的优点
Adam结合了动量法和RMSprop的优点,适用于稀疏数据,能够快速收敛,并在训练深度神经网络时表现尤为出色。
神经网络训练技巧
在神经网络的训练中,优化算法的选择至关重要。此外,还可以通过以下技巧提升训练效果:
-
随机洗牌数据:在每个epoch之前随机打乱训练数据,提高模型的泛化能力。
-
批量归一化(Batch Normalization):在网络的每一层之间进行归一化,减少对初始参数的依赖,并提高训练速度。
-
添加随机噪声到梯度:有助于模型跳出局部最优解。
FAQ
-
问:什么是梯度下降法?
- 答:梯度下降法是一种用于优化函数的算法,其通过计算目标函数的梯度,沿着梯度下降的方向更新参数,逐步逼近函数的最小值。
-
问:学习率在梯度下降法中有什么作用?
- 答:学习率决定了每次参数更新的步长,影响模型的收敛速度和稳定性。过大可能导致发散,过小可能导致收敛速度缓慢。
-
问:如何选择合适的优化算法?
- 答:选择优化算法应根据具体问题的特性。对于稀疏数据,推荐使用Adam、RMSprop等自适应学习率方法。
-
问:什么是动量法?
- 答:动量法通过结合上一次的梯度更新,减少目标函数的震荡,提高收敛速度。
-
问:如何实现学习率衰减?
- 答:可以通过逆时衰减、分段常数衰减或指数衰减等策略,根据迭代次数动态调整学习率。