

哈佛 Translation Company 推薦:如何选择最佳翻译服务

开发基于YOLOv6的教室人员检测与计数系统是优化教学资源和提升教学效率的重要手段。这篇文章将详细探讨YOLOv6算法的训练准确率查看方法,同时对比YOLOv5、YOLOv7和YOLOv8的性能,提供相关代码块和图片链接,帮助您更好地理解和应用这些模型。
YOLOv6是YOLO(You Only Look Once)系列中的一个版本,其特点是在目标检测速度和准确性之间取得了很好的平衡。YOLOv6利用了改进的网络架构和优化的损失函数,使得在处理复杂场景时表现出色。与其前辈YOLOv5相比,YOLOv6在小目标检测和遮挡场景下的表现尤为突出。
YOLOv6的架构采用了CSPDarknet53作为骨干网络,结合了空间金字塔池化(SPP)和路径聚合网络(PAN),增强了模型对不同尺度对象的检测能力。此外,YOLOv6在训练过程中引入了多尺度预测和IOU损失,进一步提升了小目标检测的效果。
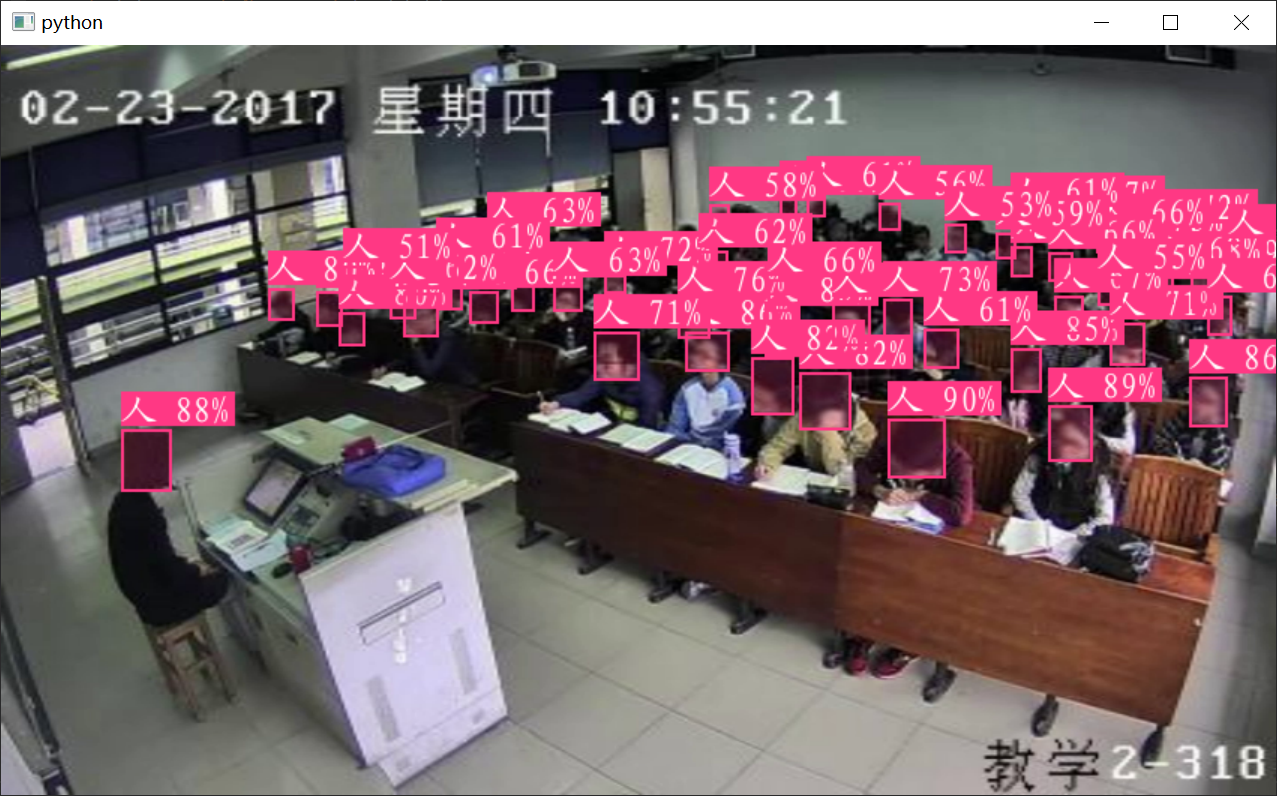
在进行YOLOv6训练之前,准备一个高质量的数据集是至关重要的。我们的数据集专门为教室人员检测设计,包含8557张图像,分为训练集、验证集和测试集。通过自动定向处理,我们确保了所有图像的方向一致。

数据集的预处理包括自动调整图像分辨率至416×416像素。这一标准化处理虽然可能导致形状畸变,但在实时检测中,提高了处理效率。特别是在教室这种场景,模型需要适应多变环境,预处理步骤的标准化是保证检测稳定性的关键。
我们的系统界面采用PySide6库进行开发,提供了一个直观的用户操作环境。界面设计以用户友好为目标,包括注册登录功能、图片和视频输入支持,以及实时检测结果显示。
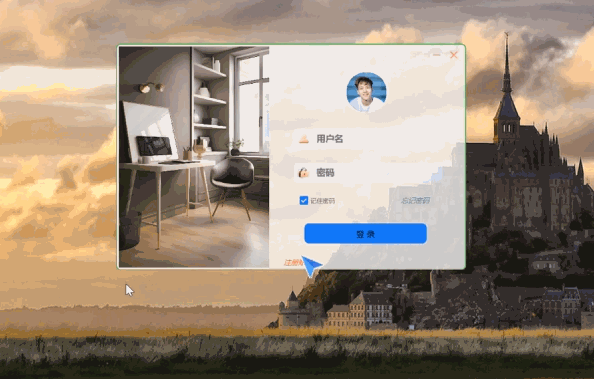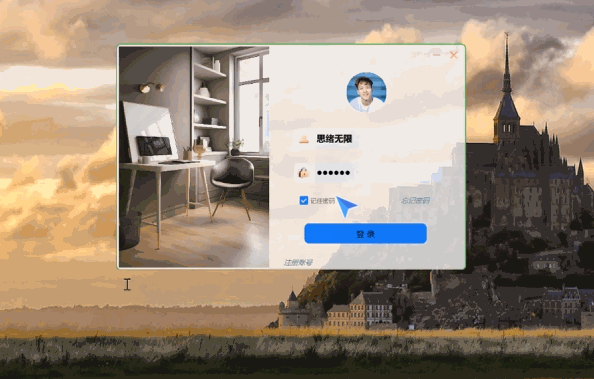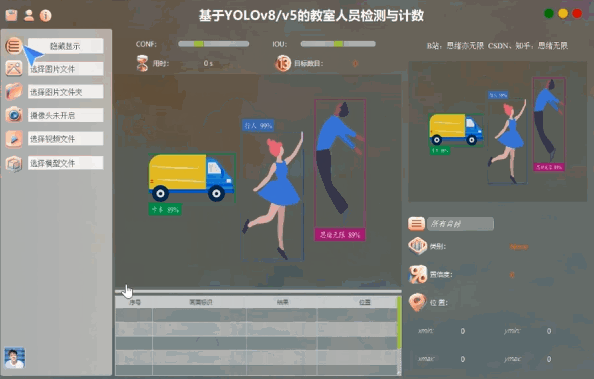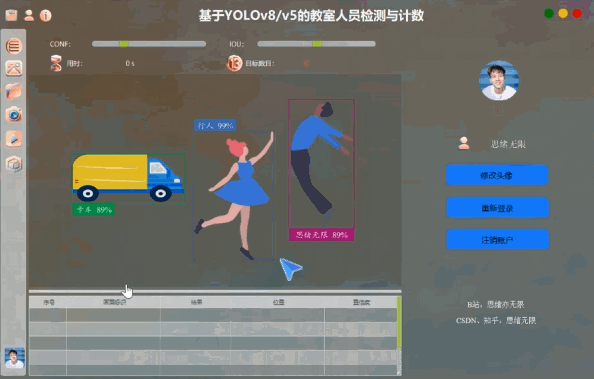
用户可以通过图形界面选择不同的输入源,如图片、视频或实时摄像头,系统会自动处理输入并显示检测结果。此外,用户界面还支持一键切换YOLOv8/v5模型,满足不同检测需求。
在YOLOv6的训练过程中,我们使用PyTorch框架,并通过配置YOLOv6模型的超参数来优化训练效果。以下是YOLOv6训练中重要的超参数及其设置:
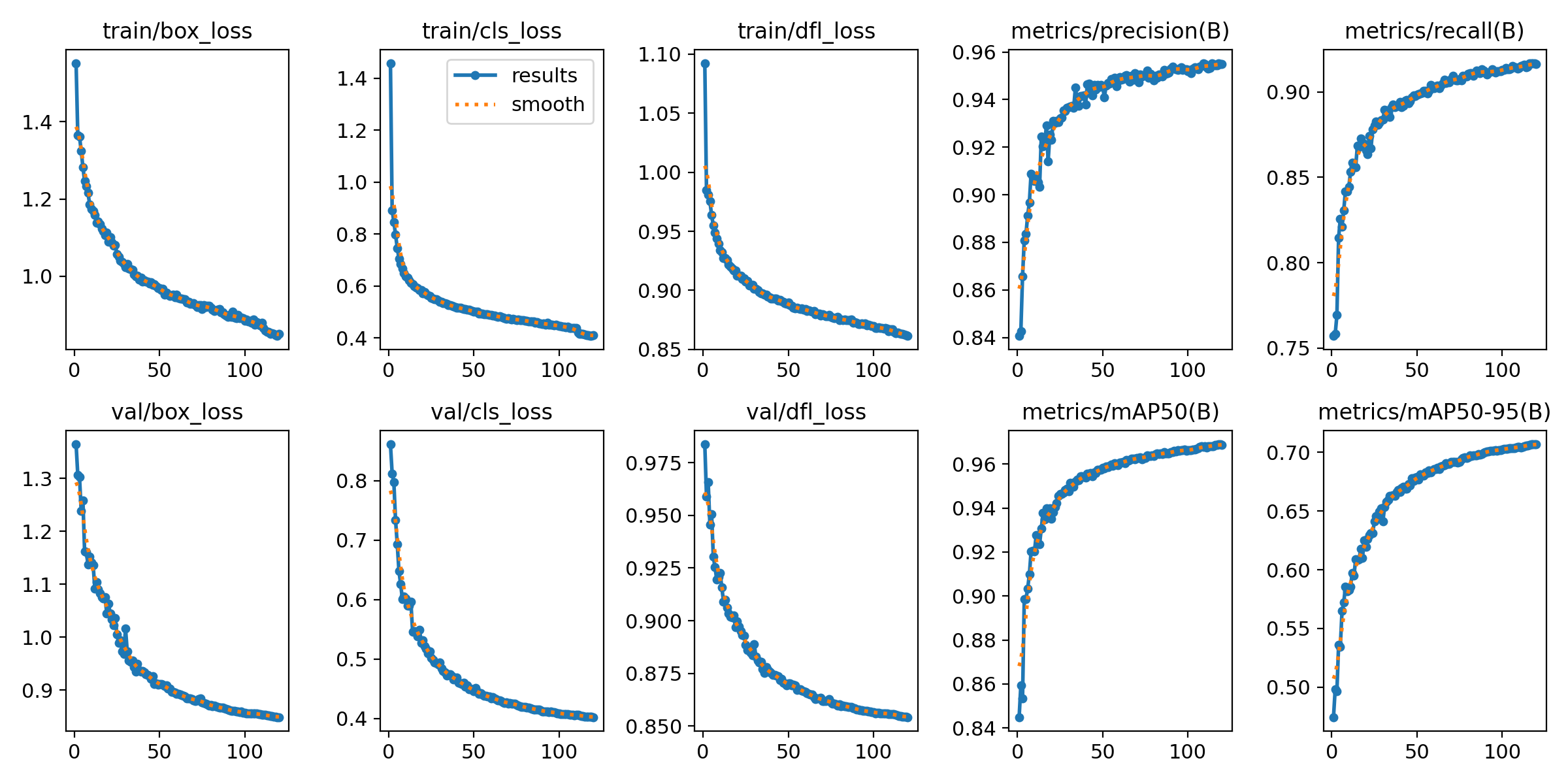
在训练过程中,损失函数的变化是判断模型学习效果的重要依据。通过分析“train/box_loss”、“train/cls_loss”和“train/obj_loss”,可以看到模型在训练过程中逐渐学习并改善其对数据的理解。
在这部分,我们对比了YOLO系列模型在相同数据集上的性能。通过mAP和F1-Score两个指标,分析了各版本的优缺点。YOLOv6在小目标检测上的优势使其在复杂场景中表现尤为出色。
| 模型 | mAP | F1-Score |
|---|---|---|
| YOLOv5nu | 0.966 | 0.93 |
| YOLOv6n | 0.933 | 0.89 |
| YOLOv7-tiny | 0.969 | 0.94 |
| YOLOv8n | 0.969 | 0.94 |
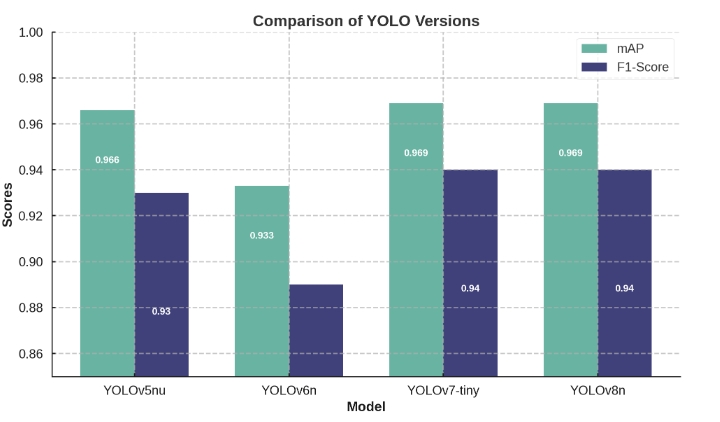
YOLOv7-tiny和YOLOv8n在性能上接近,显示了YOLO系列的持续进步。随着版本升级,模型的检测能力不断提升,特别是在精确率和召回率上的优化。
在实现教室人员检测时,我们采用了模块化的系统设计思路,使得系统在界面层、处理层和控制层之间的协作更加紧密。处理层使用YOLOv8Detector类进行目标检测,界面层提供用户友好的操作界面,控制层负责协调用户界面和处理器的交互。
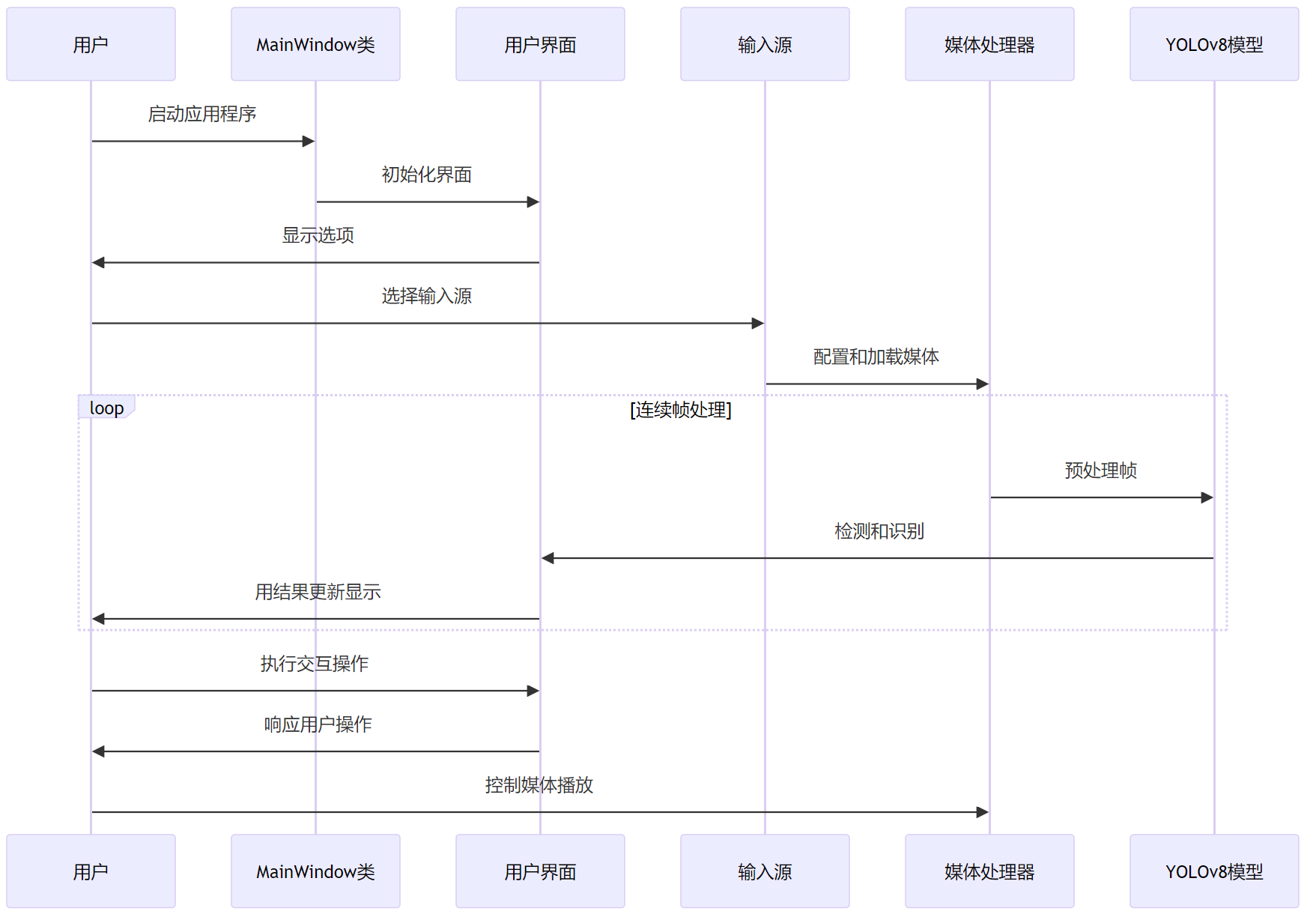
系统通过一系列槽函数和信号机制实现不同组件间的数据传递和事件触发,确保用户操作的实时响应。用户可以通过界面观看实时视频流和检测结果,并进行参数调整以优化检测性能。
系统的用户管理功能基于SQLite数据库和PySide6界面构建,确保用户数据的安全存储和便捷管理。用户可以通过注册界面创建账户,设置密码并上传头像。账户管理功能包括密码修改、头像调整和账户注销,提升了系统的安全性和用户体验。

完整的代码和资源包已上传至博主的面包多平台,读者可通过以下链接获取:
本文详细介绍了基于YOLOv6的教室人员检测与计数系统。通过合理的架构设计和用户友好的界面,系统实现了高效的人员检测。未来,我们计划增加更多预训练模型,优化界面设计,增强系统的个性化功能,以更好地满足用户需求。
问:YOLOv6的主要优势是什么?
问:如何选择合适的YOLO版本?
问:如何提高YOLOv6的检测准确率?
问:系统支持哪些输入源?
问:如何获取完整的代码资源?






