

哈佛 Translation Company 推薦:如何选择最佳翻译服务

本文详细介绍了如何使用Google的最新AI模型Gemini Pro进行跨平台应用构建。Gemini Pro作为Google迄今为止最强大的AI模型,提供了强大的API支持和多种编程语言的SDK,帮助开发者快速集成AI功能。本文还介绍了如何通过Python和Gemini Pro API进行文本和图像处理,提供了从获取API密钥到实际应用的完整流程。
GeminiPro是Google最新推出的强大AI模型,旨在提供卓越的性能和广泛的应用机会。其设计使其在处理各种任务时表现出色,超越了同等规模的其他模型。GeminiPro的32K文本上下文窗口让它在文本生成和处理方面具有显著优势。
GeminiPro支持全球180多个国家和地区的38种语言,使其成为开发者和企业的理想选择。无论您在哪个国家或地区,GeminiPro都能帮助您实现AI驱动的创新。
GeminiPro不仅支持文本输入,还可以通过GeminiPro Vision多模态接口接受图像输入。这一功能使得它在图像处理和生成方面也表现卓越。

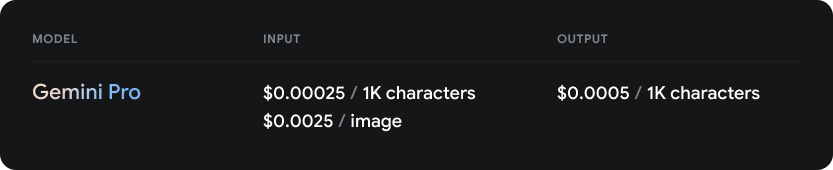
目前,GeminiPro API可以在一定限制内免费使用,这为开发者提供了使用该强大工具的机会。未来,它将以每1,000个字符或每张图像计费的方式进行收费。
在正式收费之前,用户可以通过Google AI Studio免费试用GeminiPro和GeminiPro Vision,每分钟最多进行60次请求。这一配额足以满足大多数应用的基本需求。
得益于Google在TPU方面的投资,GeminiPro能够以更高的效率提供服务,这使得其在同类产品中具有显著的竞争优势。
要开始使用GeminiPro API,您需要安装google-generativeai包,以下是安装命令:
pip install -q -U google-generativeai将您的API密钥保存在安全的地方,并通过Python脚本加载它。以下是代码示例:
import yaml
with open('gemini_key.yml', 'r') as file:
api_creds = yaml.safe_load(file)
GOOGLE_API_KEY = api_creds['gemini_key']使用您的API密钥配置并建立与GeminiPro的连接:
import google.generativeai as genai
genai.configure(api_key=GOOGLE_API_KEY)
model = genai.GenerativeModel('gemini-pro')首先,您需要在Google AI Studio注册并使用您的Google帐户登录。登录后,您可以开始获取API密钥。
在Google AI Studio中,您可以创建并获取API密钥。确保将其保存在安全的地方,并避免在公共平台上泄露。
请将API密钥存储在安全的地方,并在使用时通过代码安全加载,避免直接在代码中明文显示。
您可以使用Python向GeminiPro发送文本请求并接收响应。以下是一个简单的示例:
response = model.generate_content("Explain Generative AI with 3 bullet points")
print(response.text)GeminiPro可以检测并处理多种语言的输入,您可以利用这一特性进行跨语言的文本处理。
通过API接收的响应可以用于各种应用场景,如自动化客服、内容生成等。
首先,您需要加载要处理的图像。可以使用PIL库来加载本地图像文件。
import PIL.Image
img = PIL.Image.open('cat_pc.jpg')
img.show()使用GeminiPro Vision API,您可以将图像和文本作为输入发送,以生成复杂的输出。
odel = genai.GenerativeModel('gemini-pro-vision')
prompt = """
Describe the given picture first based on what you see.
Then create a short story based on your understanding of the picture.
Output should have both the description and the short story as two separate items
with relevant headings
"""
response = model.generate_content(contents=[prompt, img])
print(response.text)GeminiPro Vision能够理解并生成与图像相关的文本内容,使其在生成式AI领域中表现出色。
通过API,您可以创建支持多轮对话的聊天接口,为用户提供交互式体验。
GeminiPro能够高效处理用户的多轮输入,并生成相关的响应,支持复杂的用户交互。
您可以将GeminiPro集成到现有应用中,以增强其交互性和智能性,为用户提供更优质的服务体验。

google-generativeai包。接着,您需要在Google AI Studio注册并获取API密钥。然后,通过Python脚本加载该密钥,并使用它配置和建立与GeminiPro的连接。





