Google语音识别技术详解与实践应用

卷积神经网络(Convolutional Neural Networks, CNN)作为深度学习领域的核心模型之一,不仅在图像识别、目标检测等领域取得了巨大成功,还在众多科学研究和工业应用中展现出其强大的功能和灵活性。本文将深入解析CNN的工作原理、结构设计及其在图像处理中的应用,并探讨如何优化CNN模型以适应不同的任务需求。
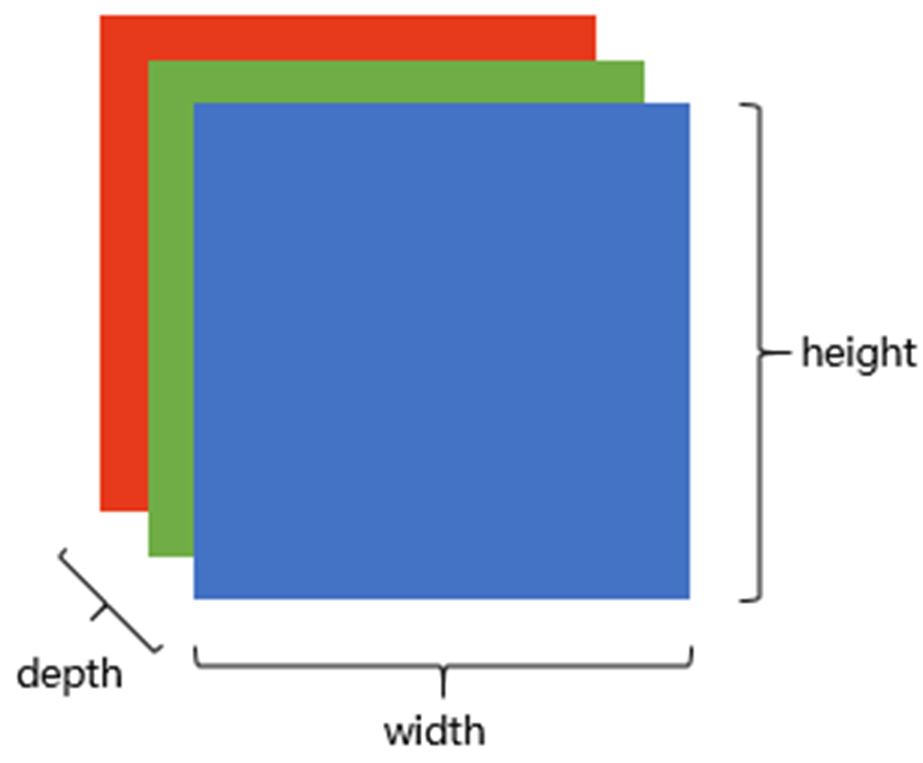
图像在计算机中的表示是通过一系列有序排列的数字来实现的,这些数字代表了像素的强度值,范围从0(最暗)到255(最亮)。在灰度图中,这些数值直接对应于像素的亮度;而在彩色图中,通常采用RGB颜色模型,即通过红、绿、蓝三种颜色的光以不同的比例组合来产生丰富多彩的图像。
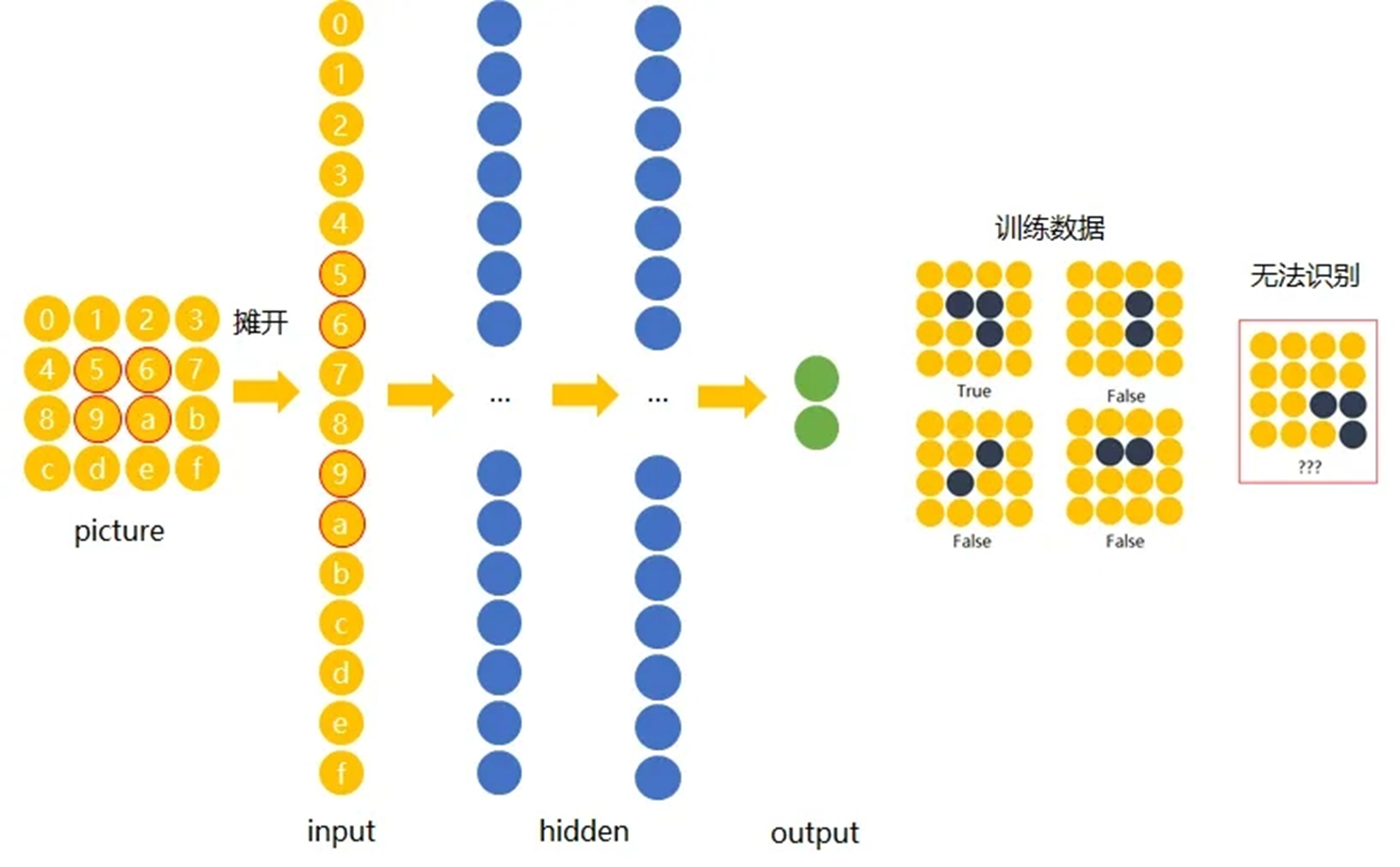
在传统神经网络中,由于缺乏对图像空间结构的感知能力,往往难以识别出图像中的具体物体,尤其是当物体位置发生变化时。而CNN通过模拟人类视觉系统的处理机制,能有效捕捉图像中的局部特征,并实现对物体的平移不变性识别。
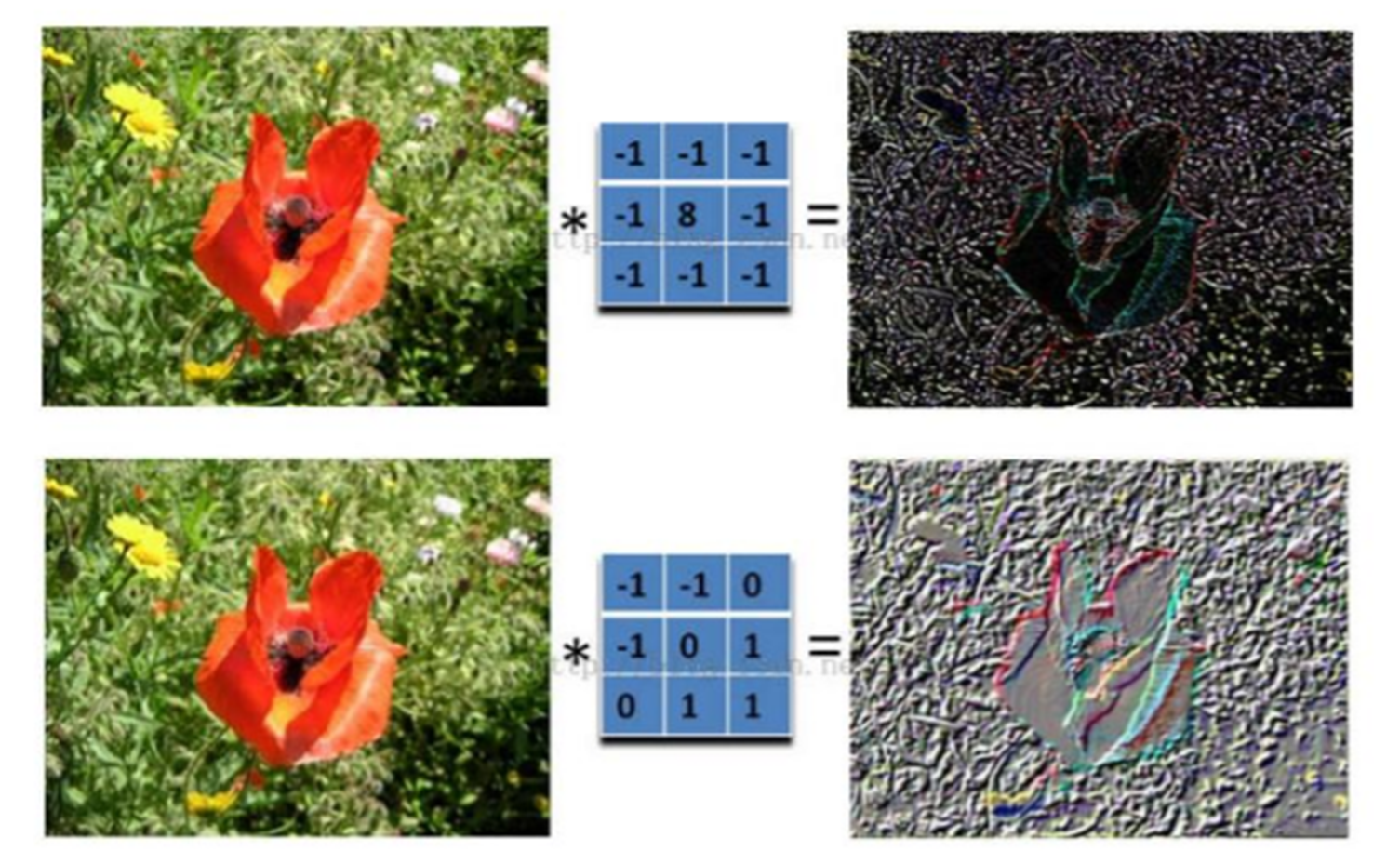
卷积操作是CNN中的核心,通过一个小窗口(卷积核)在图像上的滑动,实现对图像局部区域的特征提取。这个卷积核包含了一系列权重,通过与图像的逐元素相乘和累加,达到特征提取的效果。

在进行卷积操作时,卷积核会覆盖图像的局部区域,并将该区域内的像素值与卷积核的权重进行逐元素相乘,然后求和得到输出特征图的一个元素。这个过程会随着卷积核的滑动而不断重复,最终生成完整的特征图。
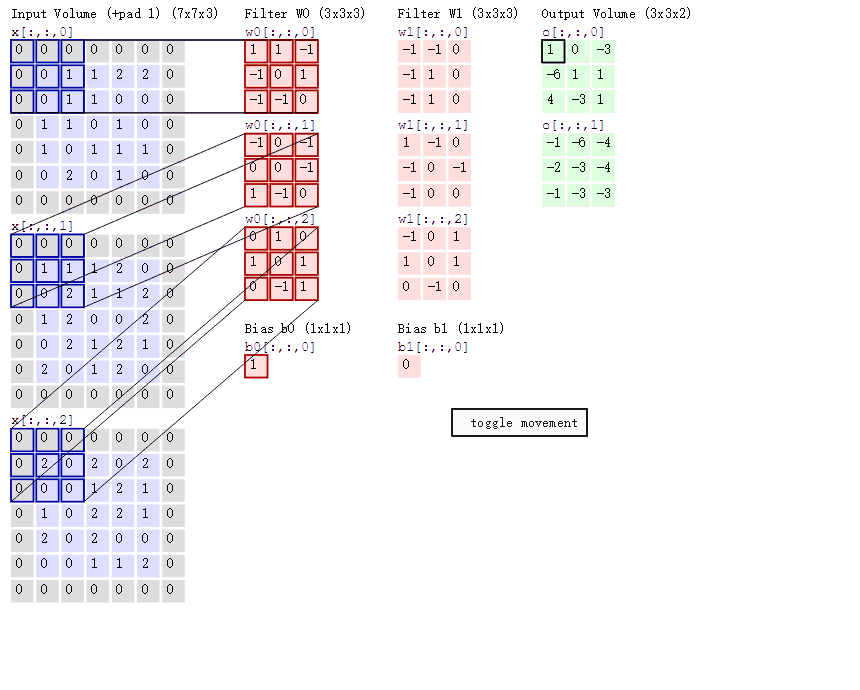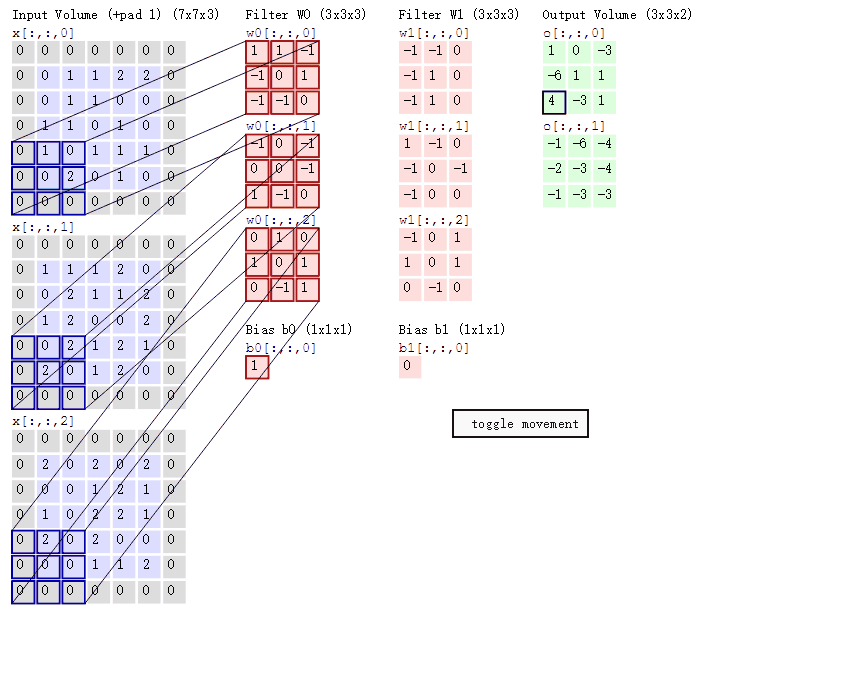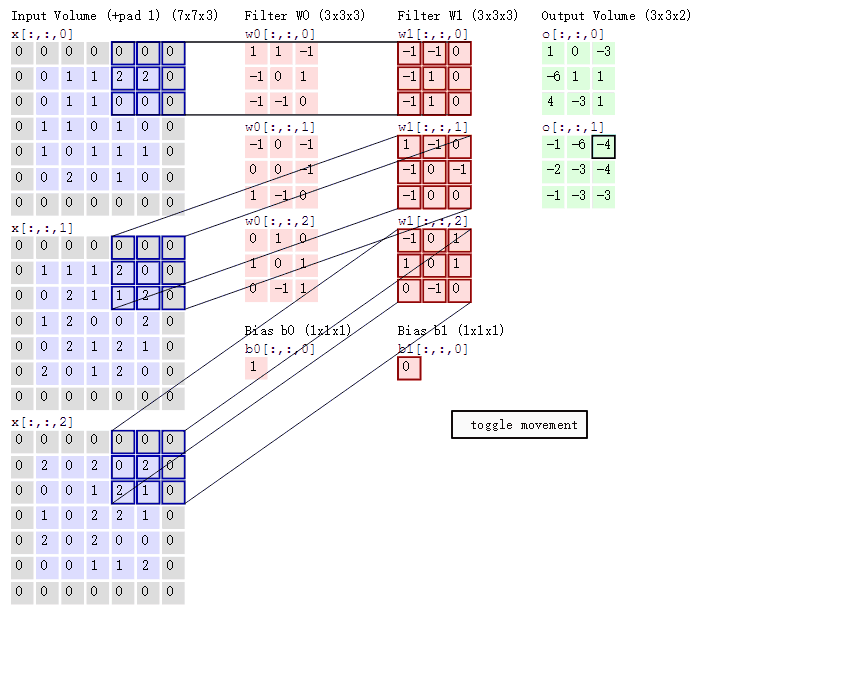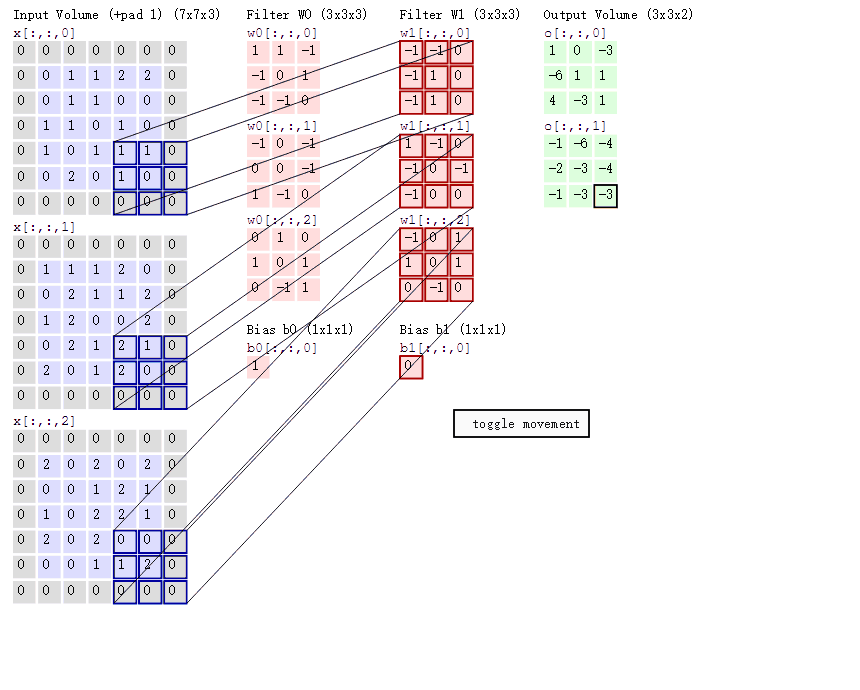
在卷积操作中,有几个关键参数需要设置:步长(stride)、卷积核的数量(depth)和零填充(zero-padding)。这些参数直接影响了输出特征图的大小和特性。
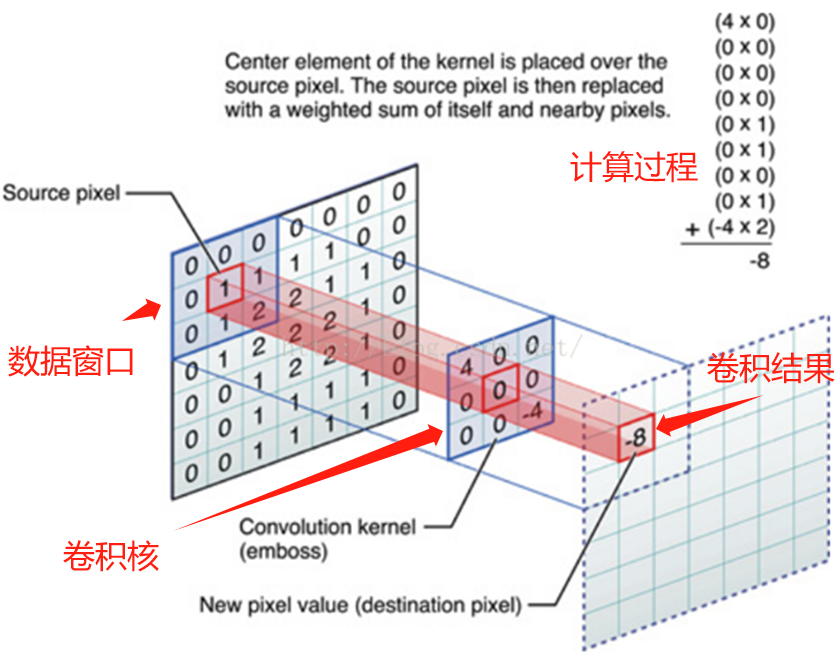
数据填充(zero-padding)是卷积操作中的一个关键技术,它通过在图像边缘添加零值,使得卷积核能够覆盖到图像的边缘区域,同时保持输出特征图的大小不变。这对于保留图像的边缘信息和空间结构至关重要。
input_image =
[[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12],
[13, 14, 15, 16]]
padded_image =
[[0, 0, 0, 0, 0, 0],
[0, 1, 2, 3, 4, 0],
[0, 5, 6, 7, 8, 0],
[0, 9, 10, 11, 12, 0],
[0, 13, 14, 15, 16, 0],
[0, 0, 0, 0, 0, 0]]CNN的输入层接收原始图像数据,并将其转换为模型可以处理的数值形式。这一层面通常包含三个颜色通道(RGB),形成一个二维矩阵。
卷积层通过对输入图像进行卷积操作,提取图像的局部特征。随后,激活函数(如ReLU)被应用于卷积结果,引入非线性,使网络能够学习更复杂的特征。
池化层通过减小特征图的尺寸来降低计算复杂度,同时保留最重要的特征信息。常见的池化操作包括最大池化(Max Pooling)和平均池化(Mean Pooling)。
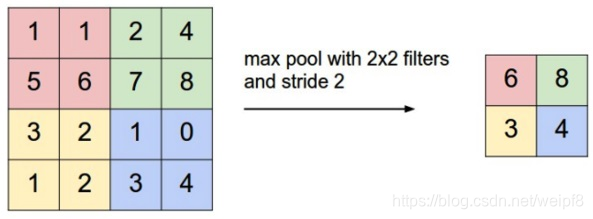
通过多层卷积和池化层的堆叠,CNN能够逐渐提取出更高级别的特征,从而识别出图像中的复杂模式和结构。
在特征提取之后,全连接层将这些特征映射到最终的输出,如分类标签或回归值。全连接层的设计和训练是CNN模型性能的关键。
CNN通过卷积操作能够捕捉到图像中的边缘、纹理等特征,为后续的图像识别和分类提供基础。下面展示了一些经过卷积操作后的图像样例。