

从零开始掌握Reddit获取API密钥与数据分析

全球人工智能语言模型的竞赛日益激烈,各大公司不断推出新一代的模型,力求在性能和应用上超越对手。在这个大背景下,Claude 3 系列模型的崛起无疑成为了业内的焦点。本文将深入探讨 Claude 3 模型的排名情况及其在 LMSYS Leaderboard 上的表现,帮助您更好地理解这一领域的最新动态。
Claude 3 系列模型由 Anthropic 公司开发,自推出以来迅速占领了市场份额。与其他模型相比,Claude 3 不仅在输出质量上表现出色,而且在响应速度上也更胜一筹。这也是 Claude 3 Opus 能够在 LMSYS Leaderboard 上超越其他模型的重要原因之一。
在最近的一次更新中,Claude 3 Opus 模型的综合评分超过了 GPT-4 Preview,自此成为榜单冠军。这一变化不仅打破了 GPT-4 长期占据榜首的局面,也标志着 Anthropic 在大语言模型技术上的一次重大突破。
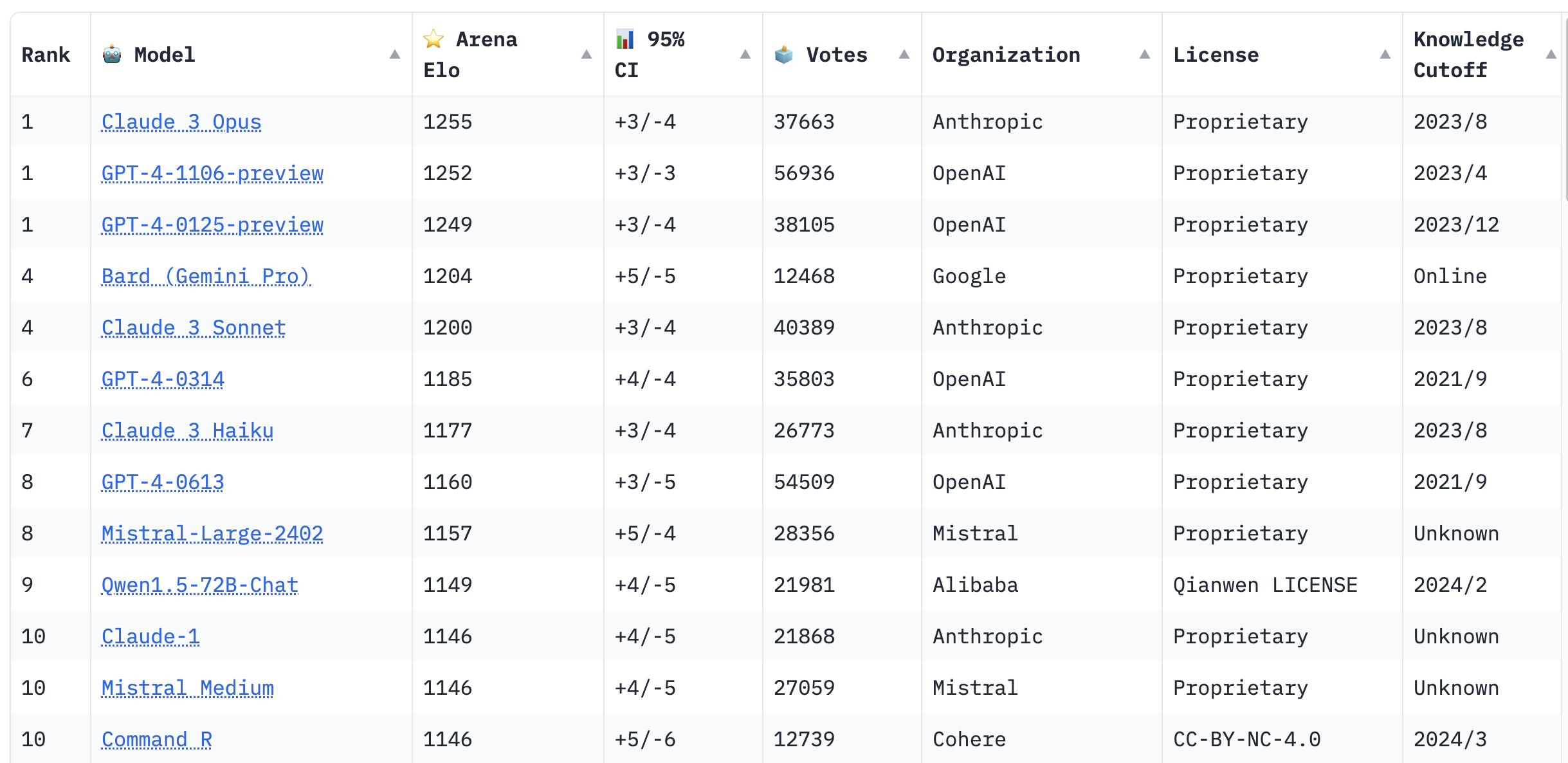
Claude 3 系列包含多个版本,按“智商”排名为 Haiku < Sonnet < Opus。每个版本都有其独特的优势和应用场景。例如,Haiku 在处理简单任务时表现优异,而 Opus 则在复杂任务中展现出色的理解能力。
LMSYS Leaderboard 是全球大语言模型比拼的平台。它采用了一种类似于国际象棋的 Elo 评分系统,通过用户交互的方式,评估各个模型的表现。用户在不知道模型身份的情况下,对生成的回答进行评分,从而确保评估的客观性和公正性。
该评分系统通过记录用户的选择和偏好,实时更新模型的排名。用户在平台上输入提示,系统随机选择两个模型生成回答,用户选择更优的回答后,系统根据用户的选择更新模型的 Elo 分数。这样,模型的排名不仅反映了其技术能力,也反映了用户的实际体验。

Claude 3 系列的崛起对 OpenAI 的 GPT-4 形成了强有力的挑战。Anthropic 宣称 Claude 3 在多个方面已全面超越 GPT-4,这一观点得到了许多用户的认可。特别是在上下文处理能力上,Claude 3 提供了更大的 token 窗口,满足了特定用户的需求。
Claude 3 模型的上下文长度默认是 200,000 token,而对于有特定需求的用户,可以定制到 1,000,000 token。这一特性能让 Claude 3 在处理长文本时表现得更加游刃有余,而 GPT-4 的上下文能力则相对有限。

在 LMSYS Leaderboard 的前十名中,来自中国的 Qwen1.5-72B-Chat 模型引起了广泛关注。该模型由阿里巴巴开发,凭借其在语言理解、推理和数学方面的强大能力,成功跻身排行榜第九名。
Qwen1.5-72B-Chat 是基于 Transformer 架构的大语言模型,涵盖了多种数据类型的超大规模预训练。该模型不仅在中文处理上表现优越,在多语言环境中也展现了强劲的竞争力。这为其在国际市场上的布局提供了坚实的基础。

随着 Claude 3 的崛起和 Qwen1.5-72B-Chat 的进入市场,大语言模型的竞争格局正在发生变化。未来的发展将更多地关注实用性和高效性,各大公司也将不断优化模型的性能以满足日益增长的市场需求。
在模型优化方面,代码的优化是提升模型性能的重要手段之一。以下是一个简单的 Python 代码示例,用于展示如何处理大数据集:
import pandas as pd
def process_large_dataset(file_path):
data = pd.read_csv(file_path, chunksize=10000)
for chunk in data:
# 数据处理逻辑
print(chunk.head())通过对 Claude 3 和其他大语言模型的深入分析,我们可以看到,人工智能领域正在经历一场前所未有的变革。Claude 3 的成功不仅反映了技术的进步,也展示了新兴力量在全球市场中的潜力。未来,随着技术的不断演进,我们期待看到更多创新和突破。
问:Claude 3 模型的主要优势是什么?
问:LMSYS Leaderboard 如何确保评估的公平性?
问:Qwen1.5-72B-Chat 在国际市场上有哪些竞争力?
问:GPT-4 相比 Claude 3 的劣势在哪里?
问:未来大语言模型的发展趋势是什么?





