利用LlamaIndex构建RAG系统:引用文献与应用实例
在信息检索和生成任务中,RAG(Retrieval-Augmented Generation)系统逐渐成为一种趋势。本文将探讨如何通过LlamaIndex构建一个高效的文献与应用实例,以提升系统的性能与可靠性。
什么是RAG系统?
RAG代表内容生成的可追溯性。
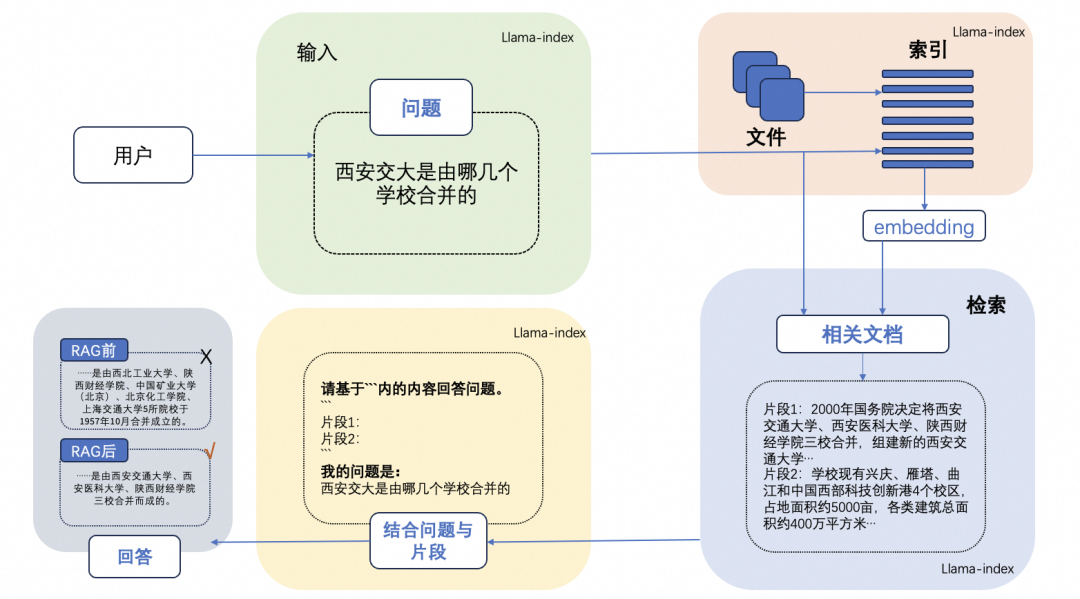
RAG系统的基本步骤
- 索引:将文档库分割成较短的Chunk,并通过编码器构建向量索引。
- 检索:根据问题和chunks的相似度检索相关文档片段。
- 生成:以检索到的上下文为条件,生成问题的回答。
LlamaIndex简介
LlamaIndex是一个基于LLM的应用程序的数据框架,支持上下文增强。它提供了必要的抽象,便于摄取、构建和访问私有或特定领域的数据,以实现更准确的文本生成。
数据连接器与结构
LlamaIndex的核心功能包括数据连接器、数据结构、高级检索/查询界面以及与其他框架的集成。通过这些功能,用户可以轻松地摄取和结构化数据,从而提高数据检索的效率和准确性。
构建LlamaIndex的步骤
数据摄取与索引
为了构建一个有效的RAG系统,首先需要摄取相关数据并建立索引。LlamaIndex支持多种数据格式和来源,如PDF、数据库和API等。
import os
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = GPTVectorStoreIndex.from_documents(documents)索引优化与检索
LlamaIndex支持向量存储索引、树索引、列表索引等多种数据结构形式,以满足不同的检索需求。通过对索引的优化,可以提高检索的准确性和效率。
RAG系统的痛点与解决方案
痛点1:内容缺失
当实际答案不在知识库中时,RAG 系统可能给出误导性答案。为此,建议优化数据源和改进提示方式。
痛点2:错过排名靠前的文档
为了解决这一问题,可以重新排名检索结果,或调整数据块大小和相似度排名超参数。
痛点3:脱离上下文
通过优化检索策略和微调嵌入模型,可以提高RAG系统的上下文整合能力。
实现实例:基于Qwen1.5的智能问答系统
Qwen1.5简介
Qwen1.5是一个中文LLM,提供了多种大小的基础和聊天模型,支持32K上下文。通过与LlamaIndex结合,可以实现强大的RAG功能。
加载Qwen1.5模型
from llama_index.llms.huggingface import HuggingFaceLLM
llm = HuggingFaceLLM(model_name='qwen/Qwen1.5-4B-Chat', device_map='auto')构建问答系统
通过LlamaIndex,用户可以轻松构建基于本地知识库的问答系统,实现高效的信息检索与生成。
query_engine = index.as_query_engine()
response = query_engine.query("西安交大是由哪几个学校合并的?")
print(response)结论
通过结合LlamaIndex和Qwen1.5,我们能够构建一个高效的RAG系统,实现准确、可靠的信息生成。这种方法不仅提升了生成内容的质量,也增强了系统的可用性和可扩展性。
FAQ
-
问:LlamaIndex如何提高检索的准确性?
- 答:LlamaIndex通过多种索引结构和数据连接器,支持高效的数据摄取和索引优化,从而提高检索的准确性。
-
问:RAG系统如何缓解幻觉问题?
- 答:RAG系统通过在生成答案之前检索相关信息,提供准确的上下文支持,从而有效缓解幻觉问题。
-
问:如何将Qwen1.5与LlamaIndex结合使用?
- 答:可以通过HuggingFaceLLM加载Qwen1.5模型,并结合LlamaIndex的索引与检索功能,构建智能问答系统。
通过本文的探讨,希望能够为读者提供关于RAG系统与LlamaIndex的深入理解,并激励更多人参与到该领域的开发与应用中。