

文心一言写代码:代码生成力的探索

RAG(Retrieval-Augmented Generation,检索增强生成)是一种创新的文本生成方法,通过引入外部知识库来增强模型的生成能力。RAG 系统在生成文本时首先从知识库中检索相关信息,然后基于这些信息生成准确的回答。这一双重过程不仅提高了模型生成内容的准确性和可靠性,还能有效减少“幻觉”现象。
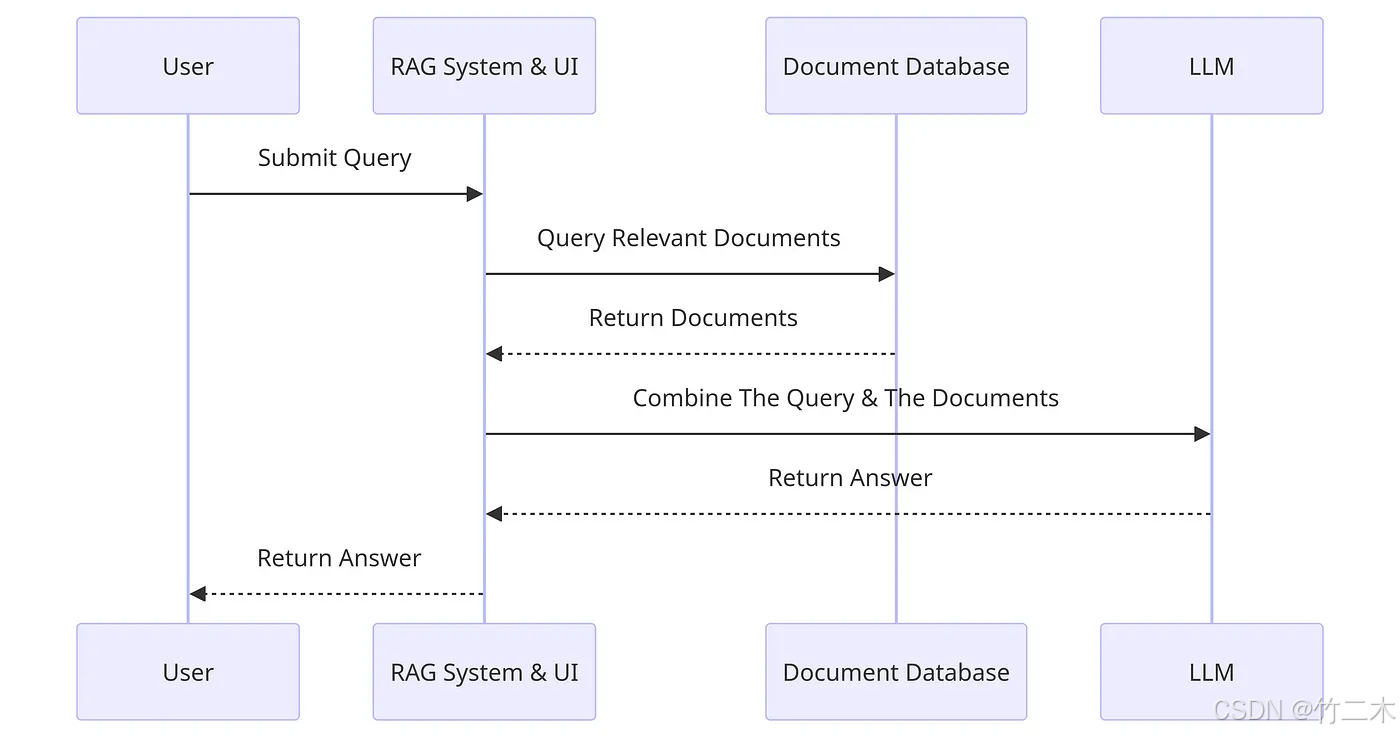
RAG 系统的核心在于如何高效地检索相关文档并生成高质量的文本。为了实现这一点,RAG 系统通常包括以下两个阶段:
在检索阶段,系统根据输入的问题从知识库中寻找相关信息。知识库可以是一个结构化的数据集,也可以是大量文档的集合。通过关键词匹配或向量相似度计算,RAG 系统能够快速找到与问题相关的文档。这一过程的准确性直接影响到生成阶段的效果。
在获取到相关文档后,RAG 系统将这些信息输入到大语言模型中,生成最终的回答。大语言模型通过结合用户问题和检索到的文档,生成符合逻辑且详细的回答。这一过程需要模型具备强大的理解和生成能力。
火山引擎提供的豆包(Doubao)模型是一种强大的大语言模型,适用于 RAG 系统的构建。通过火山引擎的云搜索服务与豆包模型的结合,可以搭建出高效的智能问答平台。
在火山引擎的平台上,首先需要配置云搜索服务。这一步骤包括创建 OpenSearch 实例,配置 CPU/内存比例,并启用语义嵌入模型。通过这些配置,可以确保系统具备高效的信息检索能力。
在完成云搜索服务的配置后,接下来是豆包模型的部署。在火山引擎方舟控制台中,可以创建模型推理接入点,选择适合的豆包模型版本,并获取 API Key。这些配置将用于后续的推理服务调用。
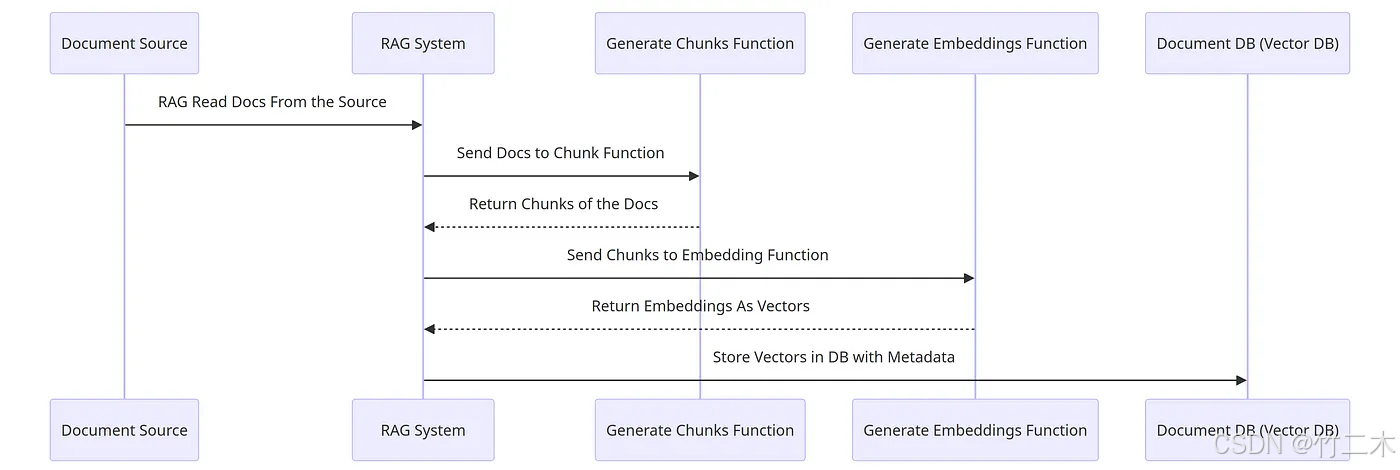
为了提高检索效率,RAG 系统通常会将文档转化为向量存储在知识库中。向量化的过程包括将文档分块、转换为向量,并存储到数据库中。
文档的分块可以根据段落、句子等粒度进行,分块后的文档块通过 Embedding 模型转化为向量。将这些向量存储在 Elasticsearch 等数据库中,可以大大提高检索效率和准确性。
from langchain_elasticsearch import ElasticsearchStore
elastic_vector_search = ElasticsearchStore(
embedding=embeddings,
index_name="langchain_index",
es_url=ES_URL,
es_api_key=ES_API_KEY,
)一旦用户提交问题,RAG 系统将问题转化为向量,并在知识库中进行相似度检索。检索到的文档将与用户问题组合生成新的 prompt,输入到豆包模型中生成回答。
retriever = elastic_vector_search.as_retriever(
search_type="similarity_score_threshold",
search_kwargs={"score_threshold": 0.6, "k": 3}
)
retrieved_documents = retriever.invoke("新兴项目与突破")为了实现私有网络中的实例与公网的连接,需要配置 NAT 网关。通过 NAT 网关,系统可以安全地访问豆包模型的推理服务。
通过选择适合的模板代码,可以将语料导入至云搜索服务中。语料的管理和处理是智能问答系统构建的重要环节。
在完成配置后,可以启动 RAG 推理服务。在 VPC 环境的 ECS 中,通过调用 RAG 模型的信息验证推理任务,确保系统正常运行。
通过 API 网关,为 RAG 推理服务配置固定的公网域名,用户可以通过浏览器直接访问推理服务并进行问答咨询。这种配置提高了系统的可用性和用户体验。
答:可以通过优化知识库的结构,使用更高效的向量检索算法,以及不断更新知识库中的信息来提升检索效率。
答:豆包模型作为大语言模型,在 RAG 系统中负责生成阶段,通过结合检索到的文档和用户问题生成高质量的回答。
答:可以通过配置 NAT 网关、使用安全的 API Key 管理,以及监控系统访问日志来确保系统的安全性。
答:RAG 系统适用于需要高准确性和实时性的信息检索和回答生成的场景,如智能客服、在线教育、知识管理等。
答:通过使用高质量的知识库、提高检索算法的准确性,以及优化生成模型的训练数据,可以有效减少“幻觉”问题的发生。






