

DeepSeek Janus-Pro 应用代码与图片链接实践

百度在2023年推出的ERNIE-ViLG 2.0代表了中文文本到图像扩散模型领域的重大突破。这一模型不仅是中文领域的首个此类模型,还在文本和图像之间的关联性与图像生成的逼真度上达到了新的高度。ERNIE-ViLG 2.0的核心创新在于:
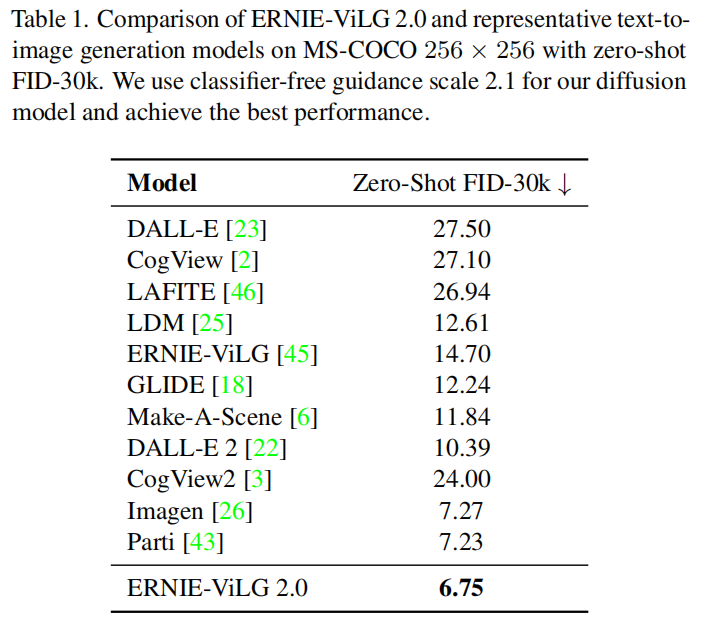
这些改进旨在解决先前模型在文本与图像交互时,目标函数贡献相同的问题,以及去噪步骤中缺乏差异化处理的问题。实验表明,ERNIE-ViLG 2.0在MS-COCO数据集上的表现超越了DALL-E 2和Stable Diffusion。
近年来,生成对抗网络(GAN)和基于Transformer的序列到序列模型在文本到图像生成领域取得了显著进展。ERNIE-ViLG、DALL-E、Cogview等模型纷纷涌现。最近,扩散模型如LDM、DALL-E 2和Imagen等进一步推动了该领域的发展。ERNIE-ViLG 2.0在此背景下应运而生,结合了扩散模型的优势和百度的技术积累,为中文文本到图像生成开辟了新路径。
在深入了解ERNIE-ViLG 2.0之前,我们需要掌握一些基础知识。扩散模型通过在图像中逐步增加噪声并逆向去噪来生成图像。在此过程中,目标函数和跨模态注意力机制在提升生成质量方面起到了关键作用。

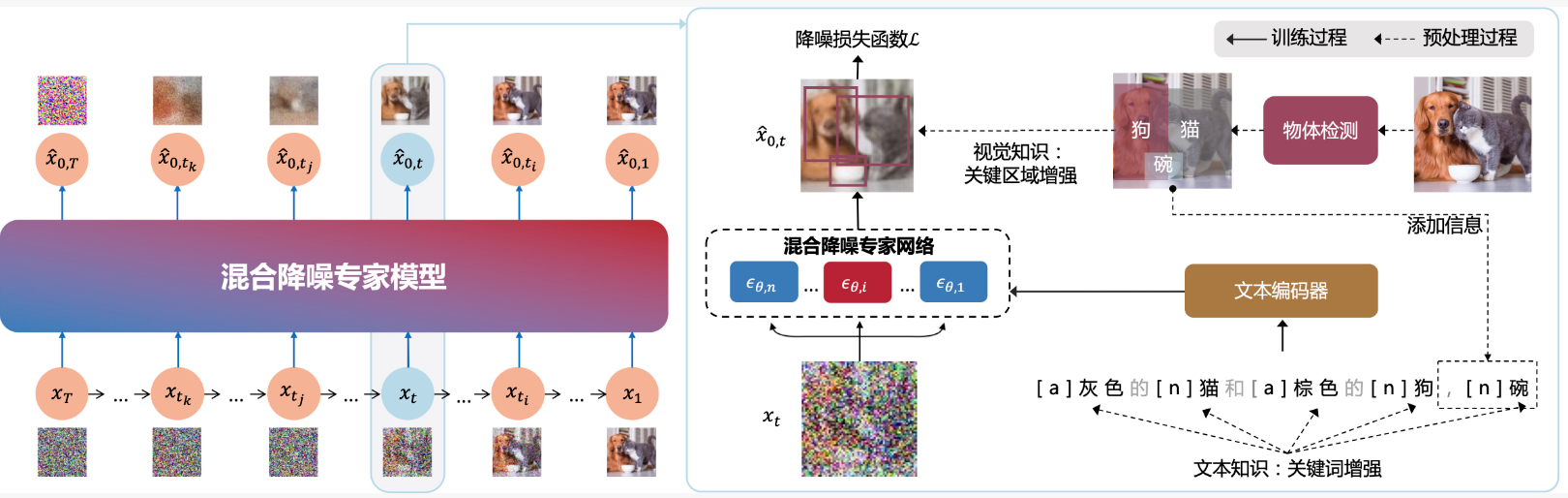
ERNIE-ViLG 2.0通过现有的词性标注工具提取输入文本的词性信息,并将其增加到输入序列中。例如,形容词“灰色的”被标注为a,名词“猫”被标注为n。在注意力层中,模型对这些词性信息赋予更高的权重,从而实现更精准的文本到图像转换。
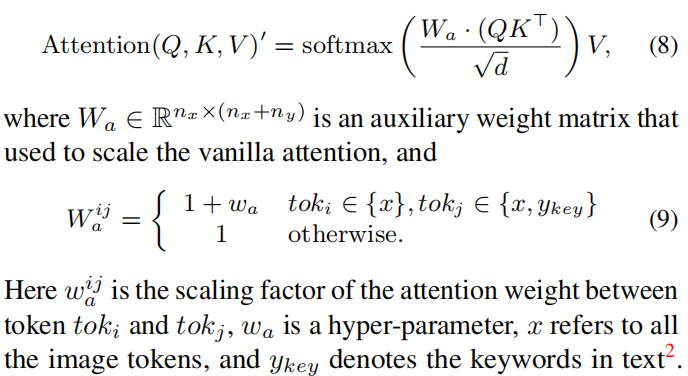
在图像处理方面,ERNIE-ViLG 2.0通过物体检测技术识别图像中的关键元素,并在训练样本的50%中应用物体检测。这些信息被用于调整目标函数的权重,使模型在生成图像时能够更好地聚焦于重要的物体。
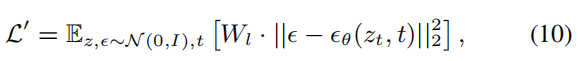
ERNIE-ViLG 2.0在去噪过程中采用了混合降噪专家技术。每个去噪步骤中的U-Net参数不同,以适应不同阶段的去噪需求,但文本编码部分则是共享的。这种方法使得模型能够在不同的去噪阶段应用最适合的网络参数,从而显著提高图像质量。

ERNIE-ViLG 2.0包含24B(240亿)参数,其中包括1.3B的文本编码器和10个2.2B的混合降噪专家(U-Net)。训练数据由1.70亿对图片-文本数据组成,训练使用320个Tesla A100 GPUs,历时18天。

实验表明,ERNIE-ViLG 2.0在MS-COCO数据集上的表现优于DALL-E 2和Stable Diffusion。此外,在人为评估中,ERNIE-ViLG 2.0的输出图像在细节和真实性上也更胜一筹。
ERNIE-ViLG 2.0能够生成高质量的图像,这些图像在逼真度和细节上达到了新的高度。

ERNIE Bot SDK是由文心&飞桨官方提供的Python开发工具包,简称EB SDK。它提供了便捷的Python接口,能够调用文心一言大模型,完成文本创作、通用对话、语义向量、AI作图等任务。
使用pip快速安装EB SDK,本文以0.4.0版本为例:
!pip install erniebot==0.4.0调用文心一言大模型是一项收费服务,因此需进行认证鉴权。我们可以通过api_type和access_token参数设置后端和访问令牌(access token)。
import erniebot
erniebot.api_type = 'aistudio'
erniebot.access_token = '{YOUR-ACCESS-TOKEN}'文心一言大模型具备强大的多轮对话能力。用户可以发送多轮消息,模型会根据上下文给出合理的回答。此外,语义向量功能将文本转化为数值表示的向量形式,用于文本检索和知识挖掘。
ERNIE-ViLG 2.0是百度推出的中文文本到图像扩散模型,结合了细粒度文本和图像知识以增强生成质量。
该模型在不同去噪步骤中使用不同的U-Net架构,并整合了细粒度文本和图像知识。
用户可以通过安装EB SDK进行多轮对话、生成语义向量以及AI作图,需进行认证鉴权。
在MS-COCO数据集上的表现优于DALL-E 2和Stable Diffusion,并在细节和真实性上更胜一筹。
可用于广告创意、图像生成、虚拟角色创建等多个领域。






