

Google语音识别技术详解与实践应用

本文深入探讨了Attention机制的原理、应用及其在现代深度学习模型中的重要性。我们将从Attention机制的基本概念出发,逐步深入到其在自然语言处理和图像处理中的应用,并探讨Self-Attention的特殊形式及其在Transformer模型中的核心作用。
Attention机制,又称为注意力机制,其核心思想是模拟人类在处理信息时的注意力分配方式,即对重要信息给予更多的关注,而忽略那些不太重要的信息。在机器学习和深度学习领域,这种机制能够帮助模型识别并集中学习数据中的关键特征。
根据应用场景的不同,Attention机制可以分为两大类:空间注意力(应用于图像处理)和时间注意力(应用于自然语言处理)。空间注意力关注于图像中的关键视觉区域,而时间注意力则关注于序列数据中的关键时间点或序列元素。
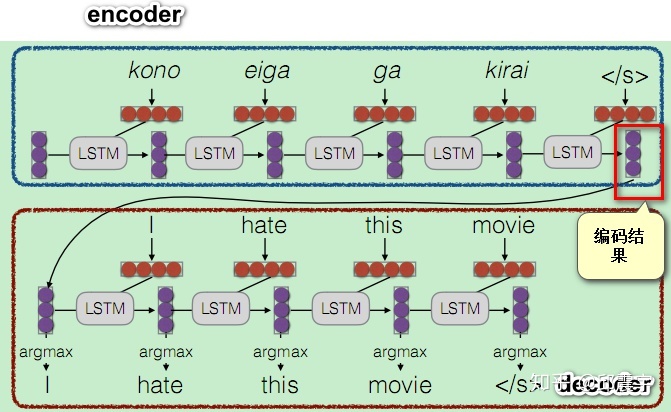
在传统的序列到序列(Seq2Seq)模型中,编码器将输入序列编码成一个固定长度的上下文向量。当输入序列较长时,这个上下文向量难以保留所有重要信息,从而限制了模型的理解能力。Attention机制通过引入对不同序列元素的不同关注度,有效解决了这一问题。
在情感分析等应用中,某些词汇(如“hate”)对模型的预测具有决定性影响。Attention机制能够使得模型在处理这类关键词汇时给予更多的关注,从而提高模型的准确性和鲁棒性。
以Seq2Seq模型为例,我们详细介绍了Attention机制的工作原理。首先,模型将输入序列中的每个单词编码成一个向量。在解码阶段,模型通过计算当前时间步的输入隐状态与之前所有单词隐状态的注意力权重,得到加权后的上下文向量,并用于预测下一个单词。
encoded_vectors = [encode(word1), encode(word2), ..., encode(wordN)]
context_vector = weighted_sum(encoded_vectors)
predicted_word = decode(context_vector)我们进一步深入到Attention机制的数学表达和公式,详细解释了如何计算注意力权重以及如何利用这些权重来更新上下文向量。
Self-Attention机制与传统Attention机制的主要区别在于,Self-Attention不仅考虑了序列中不同元素之间的关系,还考虑了单个元素内部的关系。这种机制在Transformer模型中得到了广泛的应用,有效提升了模型处理长距离依赖的能力。
我们详细介绍了Self-Attention的计算步骤,包括如何将输入序列转换为查询(Q)、键(K)和值(V)向量,如何计算注意力分数,以及如何利用这些分数来更新上下文向量。
Q = WQX
K = WKX
V = WVX
scores = QK^T / sqrt(d_k)
attention_weights = softmax(scores)
context_vector = attention_weights * V通过对比Self-Attention和传统Attention机制处理的结果,我们分析了Self-Attention机制的有效性。Self-Attention通过考虑词与词之间的相似度,能够更有效地捕捉序列中的长距离依赖关系。
Transformer模型完全基于Attention机制构建,没有使用传统的循环神经网络结构。我们详细介绍了Transformer模型的Encoder和Decoder结构,以及它们是如何利用Self-Attention和Cross-Attention机制来处理序列数据的。
Encoder由多个相同的层组成,每层包括多头Self-Attention和位置前馈网络。Decoder同样包含多个层,除了Encoder中的两个子层外,还增加了一个Encoder-Decoder Attention层。这些层通过残差连接和Layer Normalization来提高模型的训练稳定性和效果。
我们提供了Attention机制的代码实现,包括多头Attention的线性投影、分数计算、权重归一化等步骤,帮助读者更好地理解Attention机制的内部工作原理。
Q, K, V = linear_projections(queries, keys, values)
attention_scores = Q @ K.T / sqrt(d_k)
attention_weights = softmax(attention_scores)
context_vector = attention_weights @ V问:Attention机制如何帮助模型处理长距离依赖?
答:Attention机制通过计算序列中每个元素对当前元素的关注度,使得模型能够直接关注到与当前元素相关的任意位置的元素,从而有效地处理长距离依赖。
问:Self-Attention与传统Attention的主要区别是什么?
答:Self-Attention不仅考虑了序列中不同元素之间的关系,还考虑了单个元素内部的关系,这使得它能够更全面地捕捉序列中的信息。
问:Transformer模型为什么完全基于Attention机制构建?
答:Transformer模型基于Attention机制构建,因为它能够有效处理长距离依赖,并且允许并行计算,提高了模型的训练效率。
问:如何理解多头Attention机制?
答:多头Attention机制通过在不同的表示子空间上并行地应用Attention,使得模型能够从不同的视角捕捉序列中的信息,提高了模型的表达能力。
问:为什么Transformer模型中要使用残差连接和Layer Normalization?
答:残差连接和Layer Normalization有助于防止训练过程中的梯度消失问题,提高模型的训练稳定性,使得模型可以构建得更深而不影响性能。






