交叉验证在机器学习中的应用与实现
交叉验证在机器学习中的应用与实现
交叉验证(Cross Validation)是机器学习中一种重要的模型评估方法。它通过将数据集切割成较小的子集,帮助我们选择最优模型并避免过拟合现象。交叉验证不仅可以评估模型的泛化能力,还能在数据不充足的情况下有效利用样本数据。本文将详细介绍交叉验证的原理、常用方法及其应用场景。
交叉验证的基本概念
交叉验证用于评估模型在独立于训练数据的数据集上的表现。基本思想是将数据集分成多个子集,其中一个子集用于测试,剩余的子集用于训练。通过多次重复这个过程并计算平均误差,我们可以得到模型的稳定性能估计。交叉验证的关键在于样本的合理切分与组合,以保证训练集和测试集的代表性。
常见的交叉验证方法
简单交叉验证
简单交叉验证是最基础的交叉验证方法。它将数据集随机分成两部分:训练集和测试集。通常情况下,70%的数据用于训练,30%的数据用于测试。这个过程会重复多次,每次随机划分数据,并计算模型的平均误差。
K折交叉验证
K折交叉验证(K-fold Cross Validation)是简单交叉验证的扩展方法。它将数据集分成K个大小相等的子集。在每次训练中,选择K-1个子集作为训练集,剩余的一个子集作为测试集。这个过程重复K次,每个子集轮流作为测试集,最后取各次测试结果的平均值作为模型的性能指标。
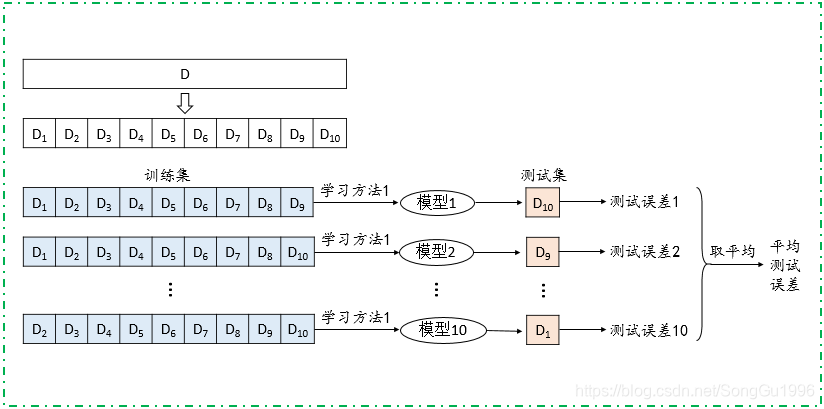
留一交叉验证
留一交叉验证(Leave-One-Out Cross Validation, LOOCV)是一种极端的K折交叉验证,当K等于数据样本总数时,称为留一交叉验证。每次从数据集中选择一个样本作为测试集,剩余样本作为训练集。由于其计算成本高,通常仅用于样本量非常小的情况。
交叉验证的特殊方法
自助法(Bootstrapping)
自助法是一种用于样本量较少时的交叉验证方法。它通过有放回的抽样从数据集中创建多个训练集。每个训练集的大小与原始数据集相同,但可能包含重复样本。未被选中的样本用于测试集。这种方法具有一定的估计偏差,但在样本量极少的情况下仍具有实用性。
交叉验证在模型选择中的应用
交叉验证不仅用于评估模型性能,还用于选择最优模型。通过比较不同模型在交叉验证中的平均测试误差,可以选择误差最小的模型作为最终模型。这在多项式回归、支持向量机(SVM)等需要参数优化的算法中尤为重要。
多项式回归中的应用
在多项式回归中,确定多项式的阶数是一个关键问题。阶数过高可能导致过拟合,而阶数过低则可能欠拟合。通过交叉验证,我们可以测试不同阶数的多项式模型,并选择交叉验证误差最小的模型。
支持向量机中的应用
在支持向量机中,参数C和核函数的选择会显著影响模型性能。通过交叉验证,我们可以评估不同参数组合的效果,选择最优参数来提高模型的泛化能力。
实现交叉验证的代码示例
在Python中,使用scikit-learn库可以方便地实现交叉验证。以下是一个简单的K折交叉验证的代码示例:
from sklearn.model_selection import KFold
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
import numpy as np
X = np.array([...])
y = np.array([...])
kf = KFold(n_splits=10, shuffle=True, random_state=42)
model = LinearRegression()
errors = []
for train_index, test_index in kf.split(X):
X_train, X_test = X[train_index], X[test_index]
y_train, y_test = y[train_index], y[test_index]
model.fit(X_train, y_train)
predictions = model.predict(X_test)
error = mean_squared_error(y_test, predictions)
errors.append(error)
average_error = np.mean(errors)
print(f"Average cross-validation error: {average_error}")交叉验证的优缺点
交叉验证的优点在于其能够充分利用数据,并提供对模型性能的稳健估计。但是,交叉验证也存在一些缺点,如计算成本较高、对大数据集的处理可能较慢等。为了提高效率,可以使用并行计算或选择合适的折数K。
交叉验证中的注意事项
在使用交叉验证时,需注意避免数据泄漏,即在预处理步骤中应仅使用训练集的数据,避免测试集的信息泄漏到训练过程中。此外,交叉验证结果的稳定性取决于数据集的随机划分,因此有时需要多次重复交叉验证以获得更可靠的估计。
常见问题解答(FAQ)
-
问:交叉验证适用于哪些场景?
- 答:交叉验证适用于模型评估、参数优化、避免过拟合等场景,尤其在数据量有限的情况下效果显著。
-
问:如何选择合适的K值进行K折交叉验证?
- 答:常用的K值为10,因为经验研究表明10折交叉验证可以提供较好的误差估计。选择K值时也需考虑计算成本和数据集大小。
-
问:是否可以将交叉验证中的最佳模型直接用于预测?
- 答:不建议直接使用交叉验证中测试误差最小的一折对应的模型,而应该用全部数据集重新训练一个模型。
-
问:交叉验证的计算成本如何降低?
- 答:可以通过减少K值、使用并行计算或选择简单模型来降低计算成本。
-
问:自助法在什么情况下使用效果更好?
- 答:自助法适用于样本量极少的情况,因为它可以在有限数据上提供多样化的训练集。
通过交叉验证,我们可以有效提高模型的泛化能力,选择出最优的模型参数,从而在实际应用中实现更高的预测精度。