

API开发中的日志记录价值

本文深入探讨了如何将SQL查询转化为REST API,并结合Redis来提升应用性能。通过Redis缓存机制,我们能够有效降低数据库负载并提高响应速度,尤其是在高并发场景下表现尤为突出。文章详细介绍了从SQL到REST API的转换过程,并提供了使用Python和Flask框架实现这一过程的示例代码。同时,文章还涵盖了Redis在不同数据结构中的应用场景,为开发者提供了丰富的实践参考。
Redis提供了一系列全局命令来管理键,例如keys *用于查看所有键,dbsize用于获取键总数,exists key用于检查键是否存在。通过这些命令,用户可以方便地管理和控制Redis数据库中的数据结构。
Redis支持多种数据结构类型,包括字符串、哈希、列表、集合和有序集合。通过type key命令,用户可以获取键所对应的数据结构类型。每种数据结构都有其独特的应用场景和底层实现。
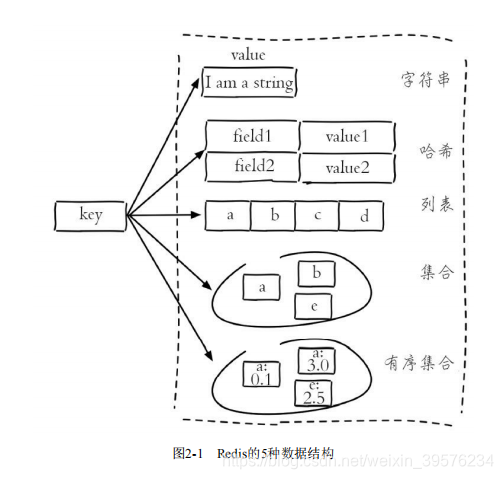
每种数据结构在Redis中都有多种内部编码实现,Redis会根据实际情况选择最优的实现方式,例如,字符串类型可以是int、embstr或raw,这使得Redis在不同场景下具有更好的性能和内存效率。
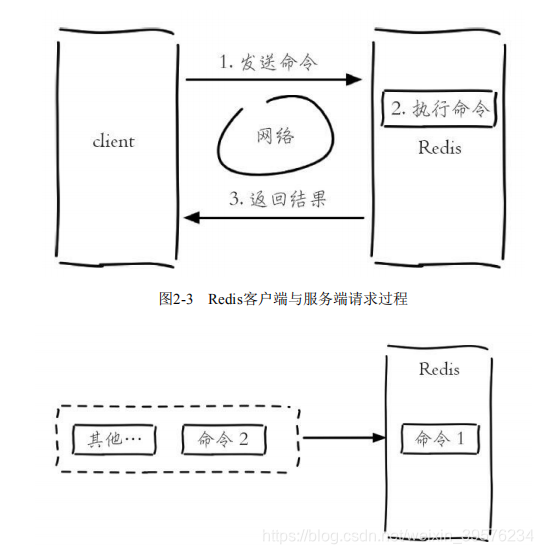
Redis采用单线程架构,但仍能实现高性能。这是因为Redis将所有数据存储在内存中,内存访问速度极快。此外,Redis使用非阻塞I/O和高效的事件处理模型,避免了线程切换带来的性能损耗。
Redis的高效性主要依赖于其内存访问特性。内存响应时间通常只有100纳秒左右,这使得Redis能够快速处理大量请求,从而在高并发场景下保持良好的性能表现。
Redis采用epoll作为I/O多路复用技术,配合其自身的事件处理模型,将网络I/O中的连接、读写、关闭等操作转换为事件进行处理,进一步提高了响应效率。
字符串是Redis最基本的数据结构,几乎所有其他数据结构都是在其基础上构建的。字符串类型既可以存储简单文本,也可以存储复杂数据,如JSON或二进制数据,最大支持512MB。
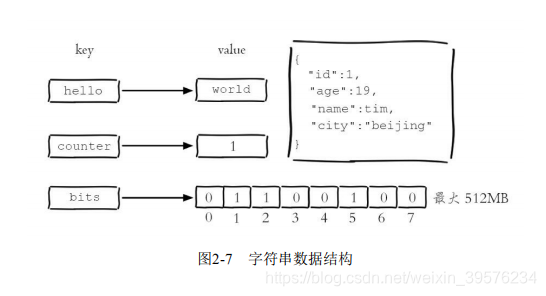
Redis的字符串类型常用于缓存场景,显著提高数据查询速度。例如,在一个Web应用中,Redis可以作为缓存层,减少对后端数据库的直接访问,从而提高系统的响应速度。
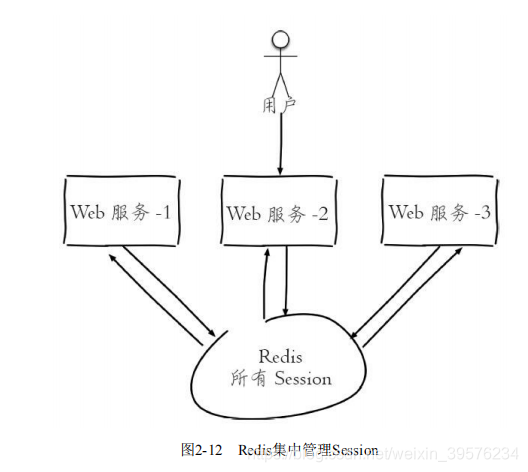
在应用中,Redis字符串类型常用于计数操作,如视频播放次数。此外,Redis还可用于共享Session数据,解决分布式系统中用户登录信息一致性的问题。
哈希类型在Redis中是一个键值对集合,适合存储对象的属性信息。哈希的存储方式使其在更新和读取时更为高效,尤其适合用户数据的缓存。
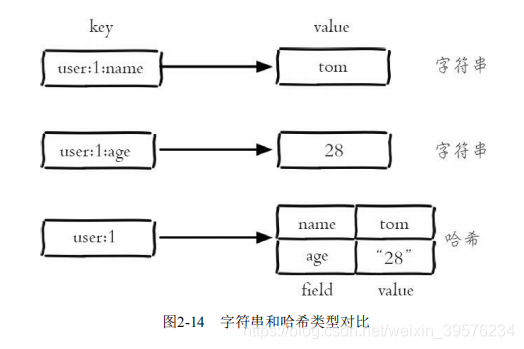
哈希类型的内部编码有ziplist和hashtable两种。ziplist适用于小规模数据,能有效减少内存使用;而hashtable则适用于大规模数据,提供O(1)的读写性能。
在用户数据缓存场景中,哈希类型提供了直观且高效的存储方式,使得用户属性的读取和更新更加便捷,同时减轻了数据库的负担。
列表类型用于存储有序字符串集合,可以作为栈、队列使用。其灵活的操作方式使其在实现消息队列等功能时非常实用。
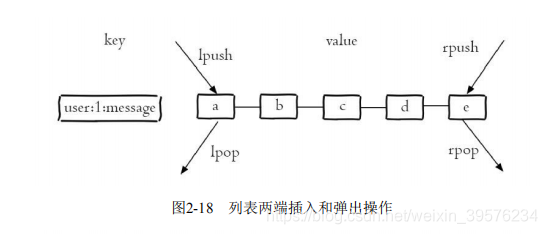
列表类型有ziplist和linkedlist两种编码方式。ziplist用于小规模列表,具有高内存效率;linkedlist则用于大规模列表,提供更优的性能。
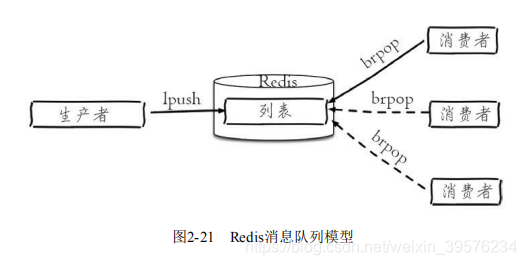
通过Redis的lpush和brpop命令组合,可以实现阻塞队列,支持负载均衡和高可用性,是消息队列系统的理想选择。
集合类型用于存储唯一的字符串集合,不允许重复,适合用来管理标签、分类数据等。这种特性使得集合在去重和并集、交集、差集操作中非常有用。
集合有intset和hashtable两种编码方式。intset用于整数集合,减少内存使用;hashtable用于其他情况,提供高效的操作能力。
在标签管理场景中,集合类型帮助我们高效存储和处理用户兴趣标签,支持快速的交集和并集操作,提升用户体验。
有序集合保留了集合的唯一性特征,并给每个元素分配一个分数,按分数排序,适合实现排行榜系统等功能。
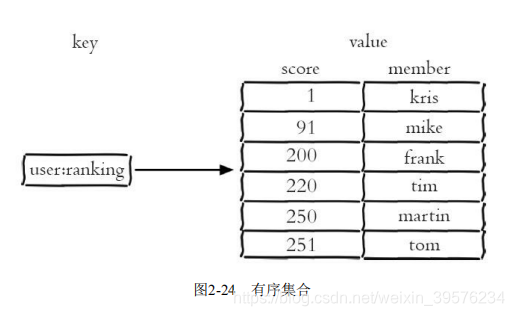
有序集合的内部编码有ziplist和skiplist。ziplist用于小规模数据,节省内存;skiplist用于大规模数据,提供快速的读写能力。
在排行榜应用中,有序集合根据分数排序,支持快速的排名和范围查询操作,非常适合用于展示视频播放排行榜等功能。
type key命令,用户可以获取键所对应的数据结构类型。ziplist和hashtable,根据数据规模和需求选择最合适的实现方式。






