AI聊天无敏感词:技术原理与应用实践
在数字化时代,随着聊天机器人中的应用,以“智谱清言”的智能体“净言”为例,分析其技术原理、优势挑战,并展望未来的发展趋势。
AI敏感词屏蔽技术概述
AI敏感词屏蔽技术是基于机器学习算法,通过训练AI识别和过滤敏感词汇的一项技术。这种技术能够对海量的网络文本进行实时监测和处理,有效屏蔽涉及色情、暴力、政治等敏感内容的词汇,为网络环境的健康发展提供了有力保障。
技术实现基础
AI敏感词屏蔽技术的核心在于其自然语言处理能力和机器学习算法。通过对大量文本数据的学习和分析,AI能够逐渐掌握如何识别敏感词汇。这不仅包括直接的敏感词,还包括通过同义词、谐音词等形式出现的变体。
技术应用场景
AI敏感词屏蔽技术已被广泛应用于社交媒体、论坛、直播平台等多种网络空间。例如,新浪微博、抖音等平台就利用该技术实时监测用户发言,自动屏蔽违规内容,确保平台内容的健康和合规。
AI敏感词屏蔽技术的优势与挑战
AI敏感词屏蔽技术以其高效性和准确性,成为维护网络环境的重要工具。然而,技术的应用也面临着诸多挑战。
技术优势分析
高效性:AI技术能够实现24小时不间断的工作,大大提高了审核效率。
准确性:通过大量数据分析,AI能够更准确地识别出各种形式的敏感词汇。
技术挑战探讨
误判问题:由于语言的复杂性和多义性,AI在识别敏感词时可能会出现误判,影响用户正常交流。
词库更新问题:随着网络语言的不断更新和演变,AI需要不断更新和优化其词库和算法,以适应新的网络环境。
伦理法律挑战:在保护网络环境的同时,如何兼顾用户的言论自由和隐私权,是一个需要平衡的问题。
未来发展趋势与展望
随着技术的不断进步,AI敏感词屏蔽技术将更加智能化和个性化。
智能化发展
通过深度学习技术,AI能够更好地理解语境和语义,减少误判的情况。
个性化服务
通过用户画像和个性化推荐技术,AI能够根据用户的兴趣和需求,提供更加精准的内容过滤服务。
实际应用案例分析
“智谱清言”的智能体“净言”就是AI敏感词屏蔽技术的一个实际应用案例。
智能体介绍
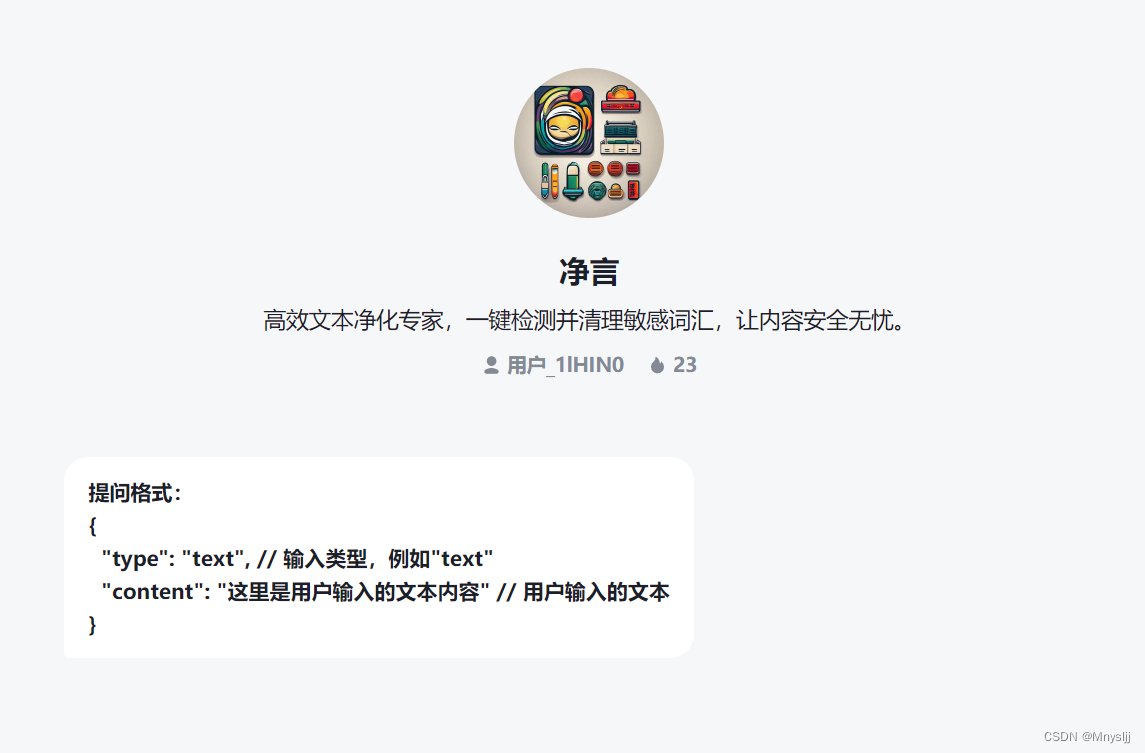
“净言”智能体通过对海量网络文本的分析,学习到了如何准确识别和屏蔽敏感内容的词汇。
技术响应格式
以下是“净言”智能体的输入和响应格式示例。
输入示例
{
"type": "text",
"content": "这里是用户输入的文本内容"
}响应示例
{
"status": "false",
"level": 0.0,
"user_message": "这里是用户输入的文本内容",
"details": {
"triggered_word": "",
"replaced_content": "这里是用户输入的文本内容"
}
}技术优势对比
直接使用敏感词库和AI敏感词过滤系统各有优势。
直接使用敏感词库
优势:实现简单,处理速度快,易于理解。
局限性:无法识别语境,难以应对变体,更新维护困难。
使用AI敏感词过滤系统
优势:语境理解能力,识别变体能力,持续学习和优化,减少人工干预。
局限性:技术复杂性,计算资源需求,伦理和法律问题。
总结与建议
直接使用敏感词库适合对实时性要求高、计算资源有限、且对误判容忍度较高的场景。而AI敏感词过滤系统则适用于对准确性要求高、能够提供足够计算资源、且需要减少人工干预的场景。
AI聊天无敏感词的技术实现
在AI聊天机器人的开发中,避免敏感信息的传播是一个重要课题。
传统做法与代码实现
传统的敏感词过滤方法主要依靠匹配算法,但这种方法在面对大模型时显得力不从心。
原理与算法
经典的算法包括KMP、字典树、AC自动机等,但这些方法在处理大模型时存在局限性。
代码实现示例
以下是使用字节树方法实现敏感词过滤的代码示例。
pub struct Node{
key: u8,
data: Option,
next: Vec
}
pub trait AsBytes{
fn as_byte(&self) -> &[u8];
}impl ByteMap{
pub fn new()->Self{
ByteMap{root:Node::default(0)}
}
// 其他函数实现
}AI相关思考
在AI聊天机器人中,除了传统的敏感词过滤方法,还可以考虑使用分词、语法纠正、机器学习等方法来提高过滤的准确性。
分词技术
分词技术可以帮助我们更准确地识别和处理敏感词。
import jieba
import re
input = "我来-到北京a清华大*学"
input = re.sub(r'[-a*]','',input)seg_list = jieba.cut(input, cut_all=True)
print("Full Mode: " + "/ ".join(seg_list))语法纠正
对于汉语中的词序颠倒等问题,可以通过语法纠正后再进行敏感词过滤。
机器学习与NLP
利用机器学习算法和自然语言处理技术,可以对文本进行分类,识别是否存在敏感词。
集成方案
在实际工程中,通常需要将多种方法集成在一起使用,以达到最佳的过滤效果。
AI大模型的安全与学习
在AI大模型的应用中,除了敏感词过滤,还需要关注模型的安全性和学习问题。
大模型安全
解决AI大模型安全问题的最好方法是从源头上防止模型产生有害信息。
如何学习AI大模型
在学习和应用AI大模型时,可以通过系统的设计、提示词工程、平台应用开发等多个阶段来提高自己的能力。
学习路线图
以下是AI大模型学习的一个路线图。
第一阶段:大模型系统设计
第二阶段:大模型提示词工程
第三阶段:大模型平台应用开发
学习资源
为了帮助大家更好地学习AI大模型,我分享了一些重要的学习资源,包括思维导图、书籍手册、视频教程等。

总结与展望
通过学习AI大模型,我们可以获得全栈工程实现的能力,解决实际项目需求,并提高编码能力。
FAQ
问:AI敏感词屏蔽技术如何提高准确性?
答:通过集成多种技术,如分词、语法纠正、机器学习等,可以提高AI敏感词屏蔽技术的准确性。
问:AI大模型学习资源有哪些?
答:AI大模型的学习资源包括思维导图、书籍手册、视频教程等,可以帮助我们系统地学习AI大模型。
问:如何防止AI大模型产生有害信息?
答:最好的方法是从源头上防止模型产生有害信息,这需要在模型训练和应用阶段都进行严格的控制和审核。
热门API
- 1. AI文本生成
- 2. AI图片生成_文生图
- 3. AI图片生成_图生图
- 4. AI图像编辑
- 5. AI视频生成_文生视频
- 6. AI视频生成_图生视频
- 7. AI语音合成_文生语音
- 8. AI文本生成(中国)
最新文章
- 跨链桥节点混合云 API:5 天扩容方案
- 绕过API,直接部署数据库 – Fly.io
- B站微服务API管理
- API与端点:差异化细分
- 使用 Clerk 与 Express 实现 API 请求身份验证的完整指南
- 翼支付是什么?如何让支付更智能
- API性能:响应时间 vs 吞吐量,哪个更重要?
- 1inch与Blockaid合作完成Shield API开发 – 博客
- 通过 Python 使用 AI真实头发生长 API 实现个性化发型设计
- 金融科技API:揭秘金融领域快速增长的秘密
- DEX 撮合引擎多云灰度发布 API:6 天实战经验
- Spring Boot + GraphQL API 实战:使用 React 和 Auth0 构建安全数据平台