

实时航班追踪背后的技术:在线飞机追踪器的工作原理

在计算机科学中,图(Graph)是一种重要的数据结构,用于表示一组对象及其关系。图的存储方式通常有两种:邻接矩阵和邻接表。本文将深入探讨邻接表的实现及其在不同情况下的优势。
邻接表是一种结合数组和链表的图存储方式。其基本思想是为每个顶点建立一个链表,链表中存储与该顶点相连的所有顶点。
在邻接表中,顶点通常存储在一个一维数组中,而每个顶点的边信息则以链表的形式存储。链表中的每个节点表示一条边,包含目标顶点的索引和权重信息(如果有)。
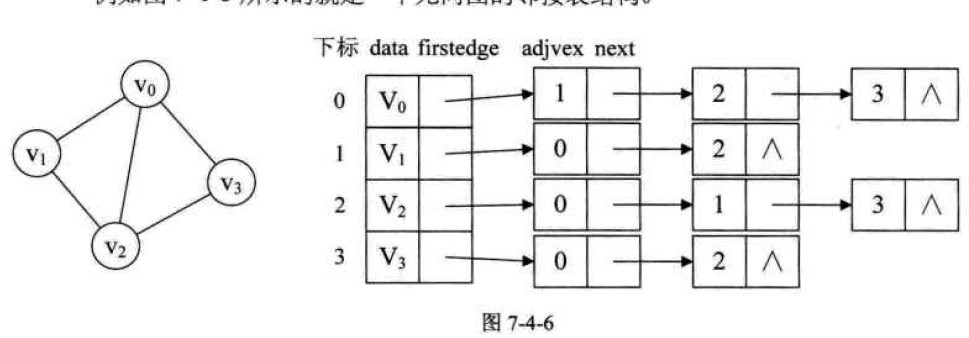
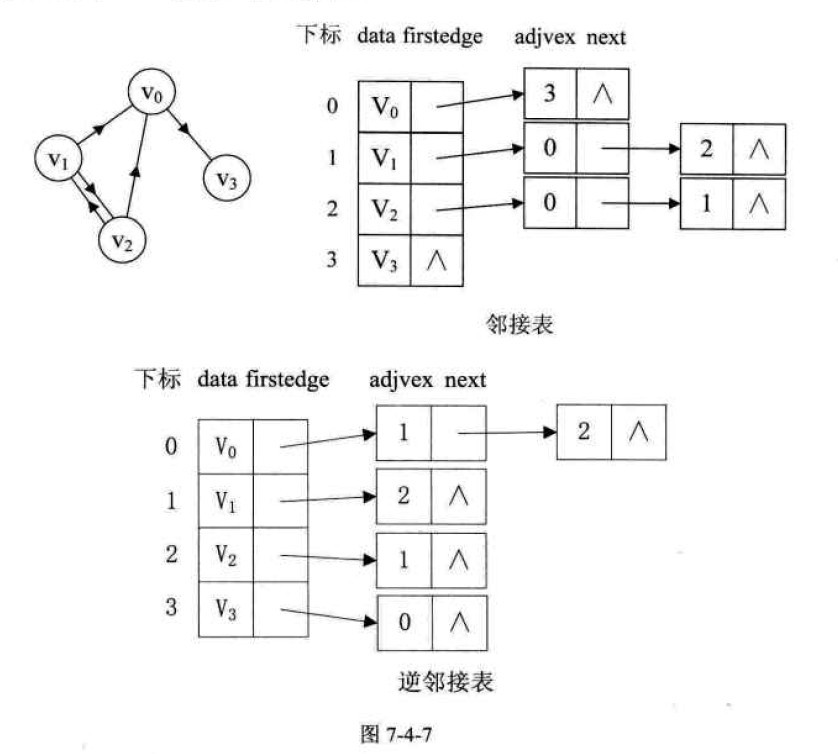
对于无向图,每条边在两个顶点的邻接表中都需要记录。而对于有向图,边仅在起始顶点的邻接表中记录。这样,可以有效地表示出度和入度。
实现邻接表需要以下几个步骤:
在实现邻接表时,我们首先需要定义数据结构。通常包括顶点节点和边节点。
typedef struct EdgeNode {
int adjvex; // 邻接点域, 存储该顶点对应的下标
EdgeType weight; // 权值
struct EdgeNode *next; // 指向下一个邻接点
} EdgeNode;
typedef struct VertexNode {
VertexType data; // 顶点信息
EdgeNode *firstedge; // 边表头指针
} VertexNode, AdjList[MAXVEX];图的创建涉及输入顶点和边的信息,并通过头插法将边节点插入到对应的顶点链表中。
void CreateALGraph(GraphAdjList *Gp) {
int i, j, k;
EdgeNode *pe;
cout << "输入顶点数和边数:" <> Gp->numNodes >> Gp->numEdges;
for (i = 0; i numNodes; i++) {
cout << "输入顶点信息:" <> Gp->adjList[i].data;
Gp->adjList[i].firstedge = NULL;
}
for (k = 0; k numEdges; k++) {
cout << "输入边(vi,vj)的顶点序号i,j:" <> i >> j;
pe = (EdgeNode *)malloc(sizeof(EdgeNode));
pe->adjvex = j;
pe->next = Gp->adjList[i].firstedge;
Gp->adjList[i].firstedge = pe;
}
}打印邻接表可以帮助我们验证数据结构是否正确。
void PrintGraph(GraphAdjList *Gp) {
for (int i = 0; i numNodes; i++) {
cout <adjList[i].data <adjList[i].firstedge;
while (p) {
cout <adjvex <next;
}
cout << endl;
}
}由于邻接表的空间效率,它非常适合用于存储稀疏图,即边的数量远小于顶点数量平方的图。
邻接表在网络路由、社交网络等图表示中有广泛应用,因为这些网络通常是稀疏的。
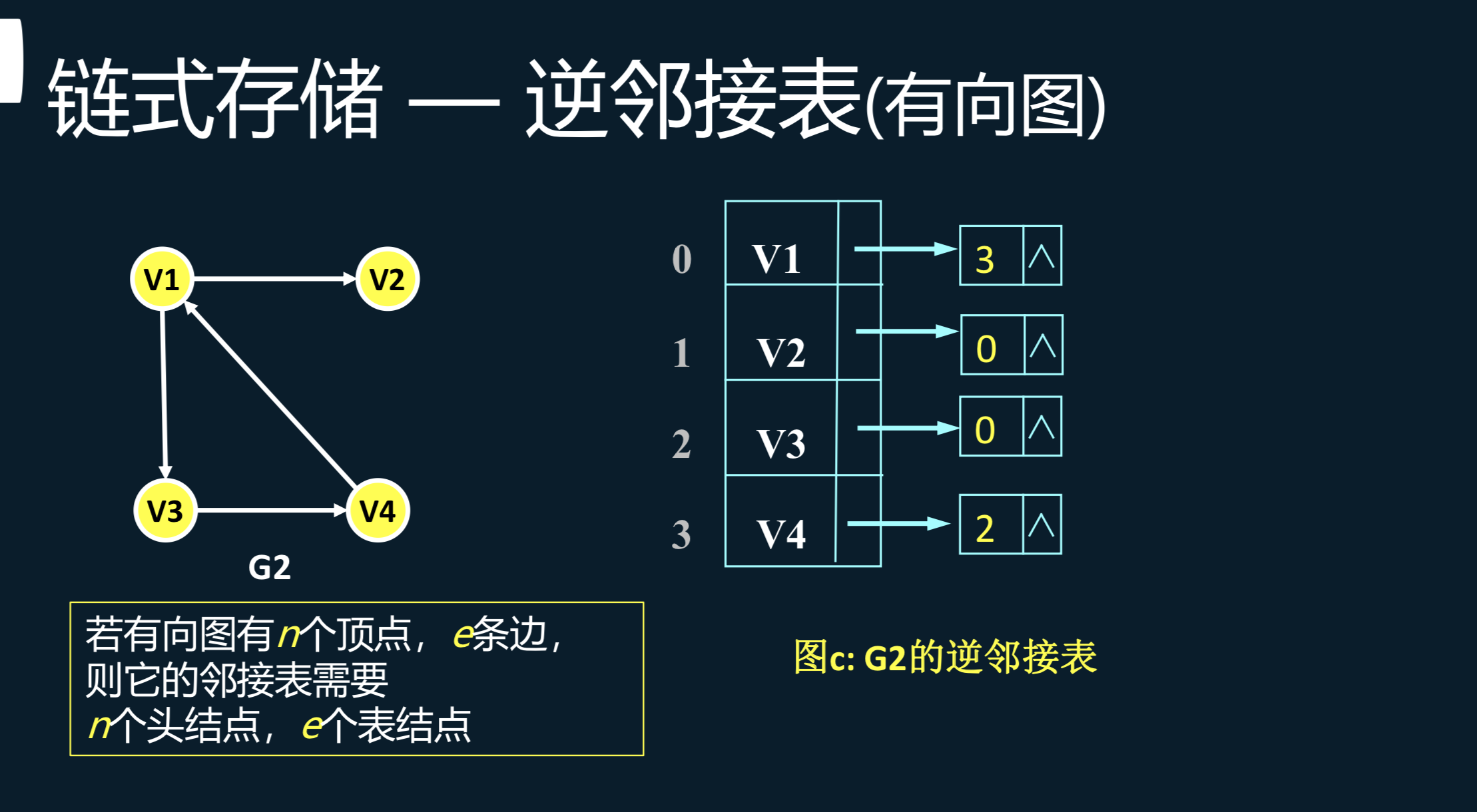
逆邻接表是邻接表的变体,记录每个顶点的入度边信息,适用于某些需要快速访问入度信息的算法。
以下是邻接表的Java实现,展示了顶点和边的结构。
class ArcNode {
int adjVex;//存放相邻结点的序号
ArcNode nextArc;//下一个边结点
int weight;//权重
public ArcNode() {
adjVex = 0;
weight = 0;
nextArc = null;
}
}
class VNode {//顶点结点
T data;//存储顶点的名称或其他相关信息
ArcNode firstArc;//指向顶点Vi的第一个边结点
public VNode() {
data = null;
firstArc = null;
}
}邻接表是一种高效的图存储方式,特别适合用于处理稀疏图。通过结合数组和链表,邻接表实现了空间和时间的有效平衡。在实际应用中,根据图的稀疏程度和操作需求选择合适的存储方式。
问:什么是邻接表?
问:邻接表相比邻接矩阵有什么优势?
问:如何判断两顶点是否邻接?
