激活函数:深度学习中的关键角色
激活函数在深度学习中扮演着至关重要的角色,它决定了神经网络的输出和学习能力。本文将深入探讨常见的激活函数及其应用场景,帮助您更好地理解和选择合适的激活函数。
什么是激活函数?
激活函数是一种添加到神经网络中的非线性变换函数,旨在帮助网络学习数据中的复杂模式。其核心功能是将输入信号进行变换,以便更好地模拟复杂的非线性关系。通过激活函数,神经元能够在不同的输入下产生不同的输出,从而模拟生物神经元的激励过程。人工神经元的工作原理如同一个处理单元,接受输入进行加权求和,然后通过激活函数进行非线性变换,最后输出信号。
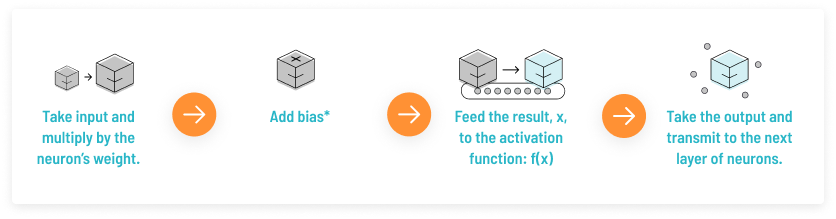
激活函数的用途
在神经网络中,每个神经元的激活函数决定了其在给定输入下的输出。激活函数的非线性特性使神经网络可以逼近复杂的非线性函数,从而提高模型的表达能力。如果没有激活函数,神经网络将退化为线性模型,无法充分利用多层结构带来的表达能力。
非线性特性的引入
通过引入非线性特性,激活函数使得神经网络能够逼近任意复杂的函数,这一特性使得深度学习在图像识别、语音识别等领域取得了显著的效果。
防止梯度消失
某些激活函数如ReLU通过避免梯度消失问题,提高了反向传播过程中梯度的有效传递,使得模型训练更加高效。
常见的激活函数
在深度学习中,常用的激活函数包括Sigmoid、Tanh、ReLU及其变种。每种激活函数都有其独特的性质和应用场景。
Sigmoid 激活函数
Sigmoid函数是经典的S形曲线激活函数,其输出范围在0到1之间,通常用于输出概率值的模型中。其公式为:
[ f(z) = frac{1}{1 + e^{-z}} ]

Sigmoid的优缺点
- 优点: Sigmoid函数适用于输出概率值的模型,具有平滑的梯度。
- 缺点: 易导致梯度消失,输出值不是以0为中心,计算开销大。
Tanh 激活函数
Tanh函数是双曲正切函数,其输出范围为-1到1,相较于Sigmoid函数,其以0为中心,权重更新更有效。其公式为:
[ f(x) = frac{e^x – e^{-x}}{e^x + e^{-x}} ]
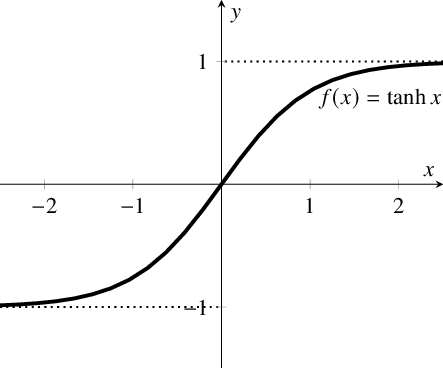
Tanh的优缺点
- 优点: 输出以0为中心,适合隐藏层。
- 缺点: 存在梯度消失问题。
ReLU 激活函数
ReLU(Rectified Linear Unit)是目前最流行的激活函数之一,其公式为:
[ f(x) = max(0, x) ]

ReLU的优缺点
- 优点: 计算速度快,解决了梯度消失问题。
- 缺点: 存在Dead ReLU问题,即当输入为负时,梯度为0,导致神经元可能不再激活。
Leaky ReLU
Leaky ReLU是一种改进的ReLU,旨在解决Dead ReLU问题。其公式为:
[ f(x) = begin{cases} x, & x ge 0 ax, & x < 0 end{cases} ]
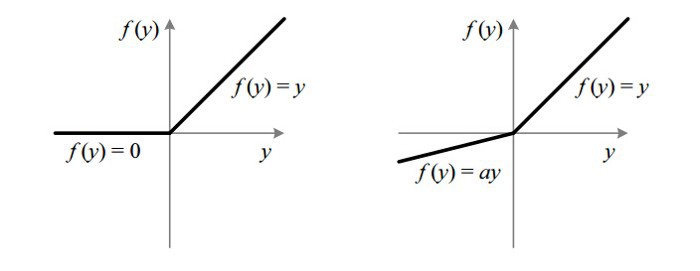
Leaky ReLU的优缺点
- 优点: 通过小于1的斜率处理负输入,解决了Dead ReLU问题。
- 缺点: 需要选择合适的斜率参数。
ELU 激活函数
ELU(Exponential Linear Unit)通过引入负值区域的非线性变换来解决ReLU的问题。其公式为:
[ f(x) = begin{cases} x, & x ge 0 a(e^x – 1), & x < 0 end{cases} ]
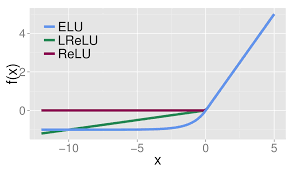
ELU的优缺点
- 优点: 输出接近0,避免了Dead ReLU问题。
- 缺点: 计算开销较大。
PReLU 和 Softplus
PReLU(Parametric ReLU)和Softplus是其他两种常见的激活函数,分别对ReLU进行参数化和平滑化处理。
如何选择合适的激活函数?
选择激活函数时,需要根据具体任务和模型结构进行调整。以下是一些经验建议:
- 对于大多数任务,推荐优先尝试ReLU及其变种,如Leaky ReLU、PReLU等。
- 对于需要输出概率的模型,使用Sigmoid或Softmax。
- 对于需要快速收敛的模型,使用Tanh或ELU。
结论
激活函数是神经网络的核心组件,其选择直接影响到模型的性能和训练效果。通过理解不同激活函数的特性和应用场景,可以更好地设计和优化深度学习模型。
FAQ
-
问:什么是激活函数的Dead ReLU问题?
- 答:Dead ReLU问题是指当ReLU激活函数的输入为负时,输出为零,导致梯度为零,神经元无法更新。
-
问:如何解决激活函数的梯度消失问题?
- 答:可以通过选择ReLU或其变种(如Leaky ReLU、ELU)来避免梯度消失问题。
-
问:为什么ReLU常用于深度学习?
- 答:ReLU计算简单,能够有效缓解梯度消失问题,使得深度学习模型训练更高效。