如何用 Python 抓取 Google 财经数据
从 Google 财经抓取网络数据可能具有挑战性,原因有三:
- 它具有复杂的 HTML 结构
- 经常更新
- 它需要精确的 CSS 或 XPath 选择器
本指南将逐步向您展示如何使用 Python 克服这些挑战。您会发现本教程很容易理解,最后,您将拥有功能齐全的代码,可以从 Google 财经中提取所需的财务数据。
Google Finance 允许抓取数据吗?
是的,您通常可以抓取 Google 财经。Google 财经网站上的大多数数据都是公开的。但是,您应该尊重他们的服务条款,避免造成他们的服务器超负荷。
如何使用 Python 爬取 Google 财经数据
按照本分步教程学习如何使用 Python 为 Google Finance 创建网络抓取工具。
1. 设置和先决条件
开始之前,请确保你的开发环境已准备就绪:
- 安装 Python :从Python 官方网站下载并安装最新版本的 Python 。
- 选择 IDE:使用 PyCharm、Visual Studio Code 或 Jupyter Notebook 等 IDE 进行开发工作。
- 基础知识:确保您 了解 CSS 选择器 并能够熟练使用 浏览器 DevTools 检查页面元素。
接下来,使用 Poetry创建一个新项目:
poetry new google-finance-scraper该命令将生成以下项目结构:
google-finance-scraper/
├── pyproject.toml
├── README.md
├── google_finance_scraper/
│ └── __init__.py
└── tests/
└── __init__.py导航到项目目录并安装 Playwright:
cd google-finance-scraper
poetry add playwright
poetry run playwright installGoogle Finance 使用 JavaScript 动态加载内容。Playwright 可以呈现 JavaScript,因此适合从 Google Finance 抓取动态内容。
打开该 pyproject.toml 文件来检查你的项目的依赖项,其中应该包括:
[tool.poetry.dependencies]
python = "^3.12"
playwright = "^1.46.0"📌*注意:* 撰写本文时,的版本为 playwright , 1.46.0但可能会更改。请检查最新版本,并 pyproject.toml 在必要时更新您的。
最后,在文件夹中创建一个 main.py 文件 google_finance_scraper 来编写您的抓取逻辑。
更新后的项目结构应如下所示:
google-finance-scraper/
├── pyproject.toml
├── README.md
├── google_finance_scraper/
│ ├── __init__.py
│ └── main.py
└── tests/
└── __init__.py您的环境现已设置好,您可以开始编写 Python Playwright 代码来抓取 Google Finance 了。
2. 连接到目标 Google 财经页面
首先,让我们使用 Playwright 启动 Chromium 浏览器实例。虽然 Playwright 支持各种浏览器引擎,但在本教程中我们将使用 Chromium:
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=False) # Launch a Chromium browser
context = await browser.new_context()
page = await context.new_page()
if __name__ == "__main__":
asyncio.run(main())要运行此脚本,您需要 main() 在脚本末尾使用事件循环执行该函数。
接下来,导航到您要抓取的股票的 Google 财经页面。Google 财经股票页面的 URL 格式如下:
https://www.google.com/finance/quote/{ticker_symbol}股票 代码 是用于识别证券交易所上市公司的唯一代码,例如 AAPL Apple Inc. 或 TSLA Tesla, Inc.。股票代码发生变化时,URL 也会发生变化。因此,您应将其替换 {ticker_symbol} 为要抓取的特定股票代码。
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
# ...
ticker_symbol = "AAPL:NASDAQ" # Replace with the desired ticker symbol
google_finance_url = f"https://www.google.com/finance/quote/{ticker_symbol}"
await page.goto(google_finance_url) # Navigate to the Google Finance page
if __name__ == "__main__":
asyncio.run(main())以下是迄今为止的完整脚本:
import asyncio
from playwright.async_api import async_playwright
async def main():
async with async_playwright() as playwright:
# Launch a Chromium browser
browser = await playwright.chromium.launch(headless=False)
context = await browser.new_context()
page = await context.new_page()
ticker_symbol = "AAPL:NASDAQ" # Replace with the desired ticker symbol
google_finance_url = f"https://www.google.com/finance/quote/{ticker_symbol}"
# Navigate to the Google Finance page
await page.goto(google_finance_url)
# Wait for a few seconds
await asyncio.sleep(3)
# Close the browser
await browser.close()
if __name__ == "__main__":
asyncio.run(main())当您运行此脚本时,它将打开 Google Finance 页面几秒钟后才终止。
太棒了!现在,您只需更改股票代码即可抓取您选择的任何股票的数据。
请注意,使用 UI ( headless=False) 启动浏览器非常适合测试和调试。如果您想节省资源并在后台运行浏览器,请切换到无头模式:
browser = await playwright.chromium.launch(headless=True)3. 检查页面以选择要抓取的元素
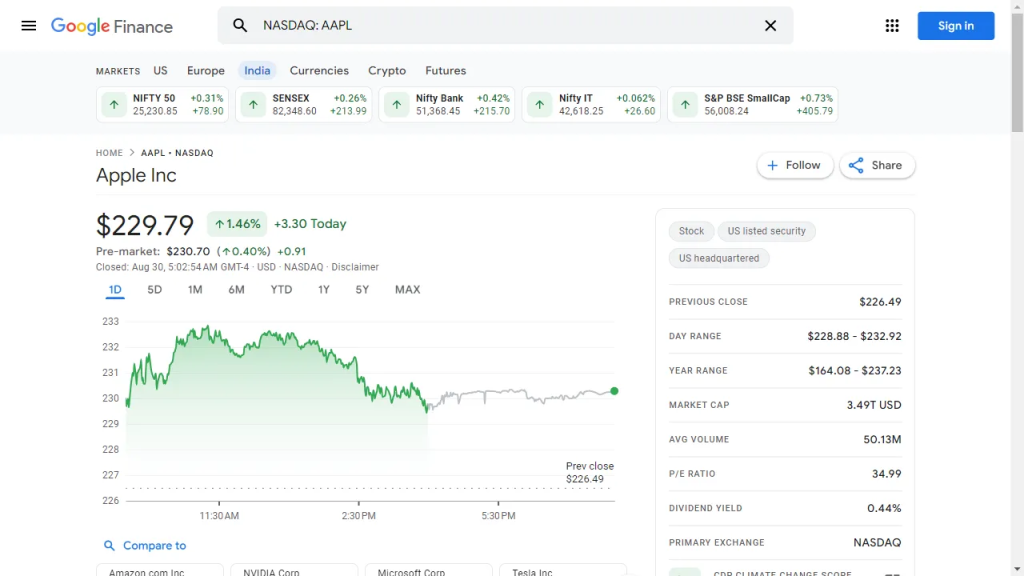
要有效地抓取数据,首先需要了解网页的 DOM 结构。假设您要提取常规市场价格(229.79 美元)、变化(+1.46)和变化百分比(+3.30%)。这些值都包含在一个 div 元素中。
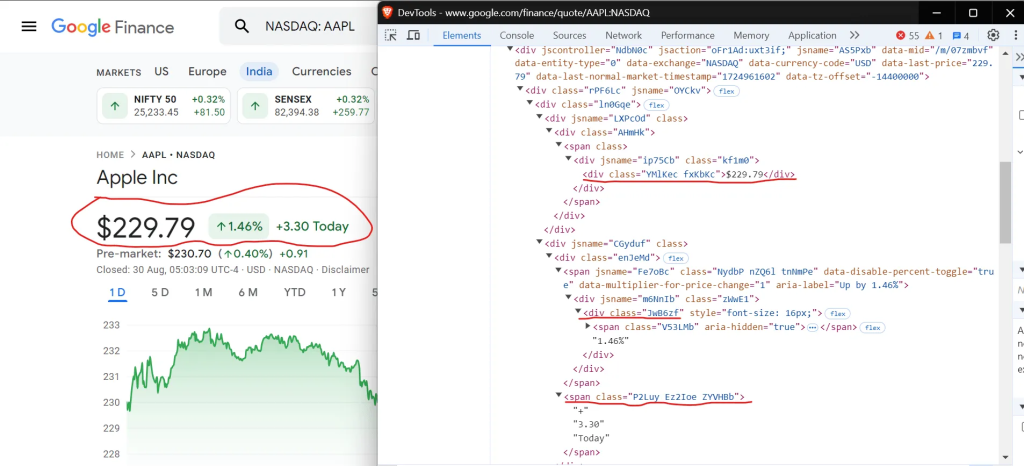
您可以使用选择器 从 Google Finance 中div.YMlKec.fxKbKc 提取价格、 div.enJeMd div.JwB6zf 百分比变化和 span.P2Luy.ZYVHBb 价值变化。
div.YMlKec.fxKbKc
div.enJeMd div.JwB6zf
span.P2Luy.ZYVHBb太棒了!接下来我们看看如何提取收盘时间,页面上显示为“06:02:19 UTC-4”。
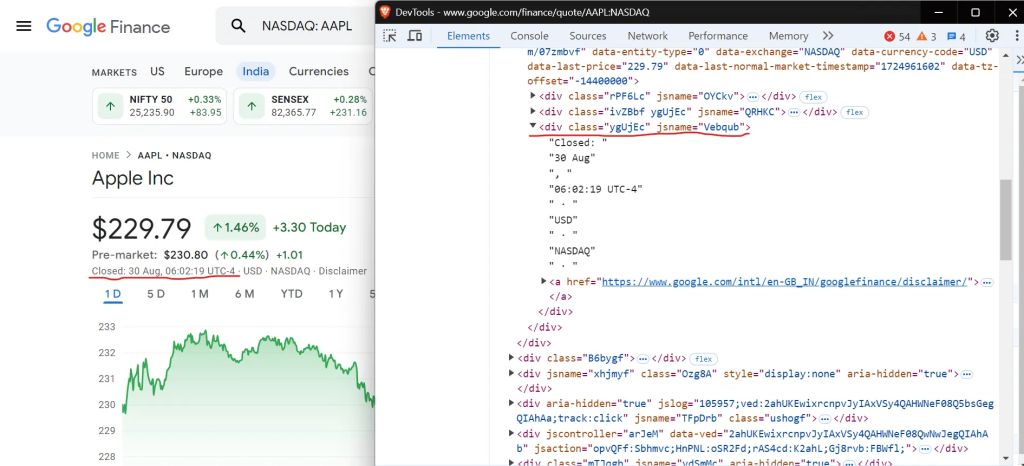
要选择收盘时间,请使用以下 CSS 选择器:
//div[contains(text(), "Closed:")]现在,让我们继续从表中提取关键的公司数据,如市值、前收盘价和交易量:
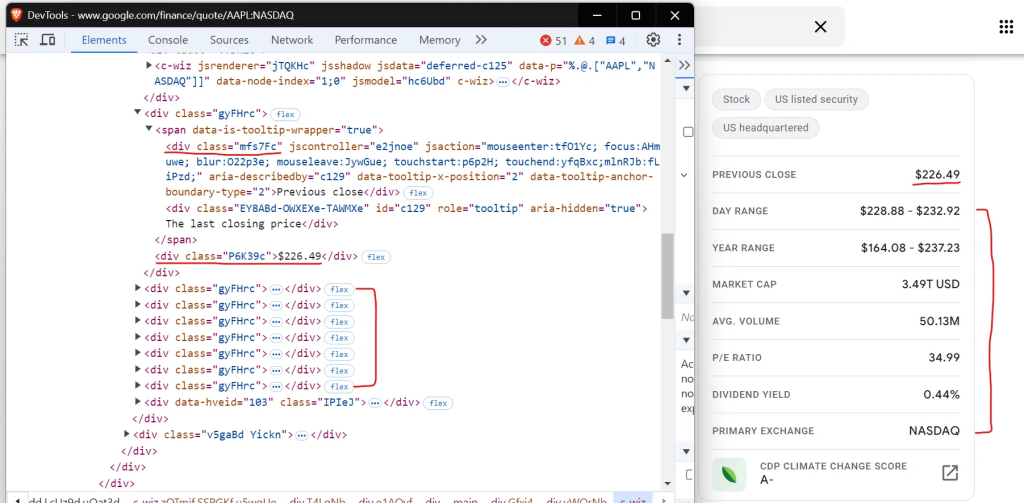
如您所见,数据在表格中是有结构的,多个 div 标签代表每个字段,从“前一收盘价”开始到“主要交易所”结束。
您可以使用选择器 从 Google Finance 表中.mfs7Fc 提取标签和 .P6K39c 相应的值。这些选择器根据元素的类名来定位元素,让您可以成对地检索和处理表的数据。
.mfs7Fc
.P6K39c4. 抓取股票数据
现在您已经确定了所需的元素,是时候编写 Playwright 脚本来从 Google Finance 中提取数据了。
让我们定义一个名为 的新函数 scrape_data 来处理抓取过程。此函数接受股票代码,导航到 Google 财经页面,并返回包含提取的财务数据的字典。
工作原理如下:
import asyncio
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright, ticker: str) -> dict:
financial_data = {
"ticker": ticker.split(":")[0],
"price": None,
"price_change_value": None,
"price_change_percentage": None,
"close_time": None,
"previous_close": None,
"day_range": None,
"year_range": None,
"market_cap": None,
"avg_volume": None,
"p/e_ratio": None,
"dividend_yield": None,
"primary_exchange": None,
}
try:
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context()
page = await context.new_page()
await page.goto(f"https://www.google.com/finance/quote/{ticker}")
price_element = await page.query_selector("div.YMlKec.fxKbKc")
if price_element:
price_text = await price_element.inner_text()
financial_data["price"] = price_text.replace(",", "")
percentage_element = await page.query_selector("div.enJeMd div.JwB6zf")
if percentage_element:
percentage_text = await percentage_element.inner_text()
financial_data["price_change_percentage"] = percentage_text.strip()
value_element = await page.query_selector("span.P2Luy.ZYVHBb")
if value_element:
value_text = await value_element.inner_text()
value_parts = value_text.split()
if value_parts:
financial_data["price_change_value"] = value_parts[0].replace(
"$", "")
close_time_element = await page.query_selector('//div[contains(text(), "Closed:")]')
if close_time_element:
close_time_text = await close_time_element.inner_text()
close_time = close_time_text.split(
"·")[0].replace("Closed:", "").strip()
clean_close_time = close_time.replace("\\u202f", " ")
financial_data["close_time"] = clean_close_time
label_elements = await page.query_selector_all(".mfs7Fc")
value_elements = await page.query_selector_all(".P6K39c")
for label_element, value_element in zip(label_elements, value_elements):
label = await label_element.inner_text()
value = await value_element.inner_text()
label = label.strip().lower().replace(" ", "_")
if label in financial_data:
financial_data[label] = value.strip()
except Exception as e:
print(f"An error occurred for {ticker}: {str(e)}")
finally:
await context.close()
await browser.close()
return financial_data代码首先导航到股票页面并使用和提取价格和市值等各种指标 query_selector, query_selector_all这是 Playwright 常用的方法,用于根据 CSS 选择器和 XPath 查询从元素中选择和获取数据。
之后,使用字典从元素中提取文本 inner_text() 并将其存储在字典中,其中每个键代表一个财务指标(例如价格、市值),每个值是相应的提取文本。最后,关闭浏览器会话以释放资源。
现在, main 通过迭代每个股票行情机并收集数据来定义协调整个过程的函数。
async def main():
# Define the ticker symbol
ticker = "AAPL"
# Append ":NASDAQ" to the ticker for the Google Finance URL
ticker = f"{ticker}:NASDAQ"
async with async_playwright() as playwright:
# Collect data for the ticker
data = await scrape_data(playwright, ticker)
print(data)
# Run the main function
if __name__ == "__main__":
asyncio.run(main())在抓取过程结束时,控制台中会打印以下数据:

5. 抓取多只股票
到目前为止,我们已经抓取了一只股票的数据。要从 Google Finance 一次收集多只股票的数据,我们可以修改脚本以接受股票代码作为命令行参数并处理每只股票。确保导入模块 sys。
import sys
async def main():
# Get ticker symbols from command line arguments
if len(sys.argv) < 2:
print("Please provide at least one ticker symbol as a command-line argument.")
sys.exit(1)
tickers = sys.argv[1:]
async with async_playwright() as playwright:
results = []
for ticker in tickers:
data = await scrape_data(playwright, f"{ticker}:NASDAQ")
results.append(data)
print(results)
# Run the main function
if __name__ == "__main__":
asyncio.run(main())要运行脚本,请将股票代码作为参数传递:
python google_finance_scraper/main.py aapl meta amzn这将抓取并显示 Apple、Meta 和 Amazon 的数据。

6. 避免被阻止
网站通常会使用速率限制、IP 阻止和分析浏览模式等技术来检测和阻止自动抓取。从网站抓取数据时,采用避免检测的策略至关重要。以下是一些有效的避免被发现的方法:
1. 请求之间的随机间隔
降低检测风险的一个简单方法是在请求之间引入随机延迟。这种简单的技术可以大大降低被识别为自动爬虫的可能性。
以下是如何在 Playwright 脚本中添加随机延迟的方法:
import asyncio
import random
from playwright.async_api import Playwright, async_playwright
async def scrape_data(playwright: Playwright, ticker: str):
browser = await playwright.chromium.launch()
context = await browser.new_context()
page = await context.new_page()
url = f"https://www.google.com/finance/quote/{ticker}"
await page.goto(url)
# Random delay to mimic human-like behavior
await asyncio.sleep(random.uniform(2, 5))
# Your scraping logic here...
await context.close()
await browser.close()
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright, "AAPL:NASDAQ")
if __name__ == "__main__":
asyncio.run(main())该脚本在请求之间引入了 2 到 5 秒的随机延迟,使得操作变得不那么可预测,并降低了被标记为机器人的可能性。
2. 设置和切换用户代理
网站通常使用 User-Agent 字符串来识别每个请求背后的浏览器和设备。通过轮换 User-Agent 字符串,您可以让您的抓取请求看起来来自不同的浏览器和设备,从而帮助您避免被检测到。
以下是在 Playwright 中实现 User-Agent 轮换的方法:
import asyncio
import random
from playwright.async_api import Playwright, async_playwright
user_agents = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0",
]
async def scrape_data(playwright: Playwright, ticker: str) -> None:
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context(user_agent=random.choice(user_agents))
page = await context.new_page()
url = f"https://www.google.com/finance/quote/{ticker}"
await page.goto(url)
# Your scraping logic goes here...
await context.close()
await browser.close()
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright, "AAPL:NASDAQ")
if __name__ == "__main__":
asyncio.run(main())此方法使用 User-Agent 字符串列表,并为每个请求随机选择一个。此技术有助于掩盖您的抓取工具的身份并降低被阻止的可能性。
📌*注意*:您可以参考 useragentstring.com 等网站来获取完整的 User-Agent 字符串列表。
3. 使用playwright-stealth
为了进一步最大限度地减少检测并增强您的抓取工作,您可以使用 playwright-stealth 库,它应用各种技术使您的抓取活动看起来像真实用户的活动。
首先,安装 playwright-stealth:
poetry add playwright-stealth如果遇到 ,很可能是因为 未安装该软件包。要解决此问题,还需要 ModuleNotFoundError 安装 :pkg_resources`setuptools`setuptools
poetry add setuptools然后,修改脚本:
import asyncio
from playwright.async_api import Playwright, async_playwright
from playwright_stealth import stealth_async
async def scrape_data(playwright: Playwright, ticker: str) -> None:
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context()
# Apply stealth techniques to avoid detection
await stealth_async(context)
page = await context.new_page()
url = f"https://www.google.com/finance/quote/{ticker}"
await page.goto(url)
# Your scraping logic here...
await context.close()
await browser.close()
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright, "AAPL:NASDAQ")
if __name__ == "__main__":
asyncio.run(main())这些技术可以帮助避免被阻止,但您可能仍会遇到问题。如果是这样,请尝试更高级的方法,例如使用代理、轮换 IP 地址或实施 CAPTCHA 求解器。
7. 将抓取的股票数据导出为 CSV
抓取到所需的股票数据后,下一步就是将其导出为 CSV 文件,以便于分析、与他人共享或导入到其他数据处理工具中。
将提取的数据保存到 CSV 文件的方法如下:
# ...
import csv
async def main() -> None:
# ...
async with async_playwright() as playwright:
# Collect data for all tickers
results = []
for ticker in tickers:
data = await scrape_data(playwright, ticker)
results.append(data)
# Define the CSV file name
csv_file = "financial_data.csv"
# Write data to CSV
with open(csv_file, mode="w", newline="") as file:
writer = csv.DictWriter(file, fieldnames=results[0].keys())
writer.writeheader()
writer.writerows(results)
if __name__ == "__main__":
asyncio.run(main())代码首先收集每个股票代码的数据。之后,它会创建一个名为的 CSV 文件 financial_data.csv。然后,它使用 Python 的 csv.DictWriter 方法写入数据,首先使用方法写入列标题 writeheader() ,然后使用方法添加每行数据 writerows() 。
8. 整合所有内容
让我们将所有内容整合到一个脚本中。这个最终代码片段包括从 Google Finance 抓取数据到将其导出到 CSV 文件的所有步骤。
import asyncio
import sys
import csv
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright, ticker: str) -> dict:
"""
Scrape financial data for a given stock ticker from Google Finance.
Args:
playwright (Playwright): The Playwright instance.
ticker (str): The stock ticker symbol.
Returns:
dict: A dictionary containing the scraped financial data.
"""
financial_data = {
"ticker": ticker.split(":")[0],
"price": None,
"price_change_value": None,
"price_change_percentage": None,
"close_time": None,
"previous_close": None,
"day_range": None,
"year_range": None,
"market_cap": None,
"avg_volume": None,
"p/e_ratio": None,
"dividend_yield": None,
"primary_exchange": None,
}
try:
# Launch the browser and navigate to the Google Finance page for the ticker
browser = await playwright.chromium.launch(headless=True)
context = await browser.new_context()
page = await context.new_page()
await page.goto(f"https://www.google.com/finance/quote/{ticker}")
# Scrape current price
price_element = await page.query_selector("div.YMlKec.fxKbKc")
if price_element:
price_text = await price_element.inner_text()
financial_data["price"] = price_text.replace(",", "")
# Scrape price change percentage
percentage_element = await page.query_selector("div.enJeMd div.JwB6zf")
if percentage_element:
percentage_text = await percentage_element.inner_text()
financial_data["price_change_percentage"] = percentage_text.strip()
# Scrape price change value
value_element = await page.query_selector("span.P2Luy.ZYVHBb")
if value_element:
value_text = await value_element.inner_text()
value_parts = value_text.split()
if value_parts:
financial_data["price_change_value"] = value_parts[0].replace(
"$", "")
# Scrape close time
close_time_element = await page.query_selector('//div[contains(text(), "Closed:")]')
if close_time_element:
close_time_text = await close_time_element.inner_text()
close_time = close_time_text.split(
"·")[0].replace("Closed:", "").strip()
clean_close_time = close_time.replace("\\u202f", " ")
financial_data["close_time"] = clean_close_time
# Scrape additional financial data
label_elements = await page.query_selector_all(".mfs7Fc")
value_elements = await page.query_selector_all(".P6K39c")
for label_element, value_element in zip(label_elements, value_elements):
label = await label_element.inner_text()
value = await value_element.inner_text()
label = label.strip().lower().replace(" ", "_")
if label in financial_data:
financial_data[label] = value.strip()
except Exception as e:
print(f"An error occurred for {ticker}: {str(e)}")
finally:
# Ensure browser is closed even if an exception occurs
await context.close()
await browser.close()
return financial_data
async def main():
"""
Main function to scrape financial data for multiple stock tickers and save to CSV.
"""
# Get ticker symbols from command line arguments
if len(sys.argv) < 2:
print("Please provide at least one ticker symbol as a command-line argument.")
sys.exit(1)
tickers = sys.argv[1:]
async with async_playwright() as playwright:
results = []
for ticker in tickers:
data = await scrape_data(playwright, f"{ticker}:NASDAQ")
results.append(data)
# Define CSV file name
csv_file = "financial_data.csv"
# Write data to CSV
with open(csv_file, mode="w", newline="") as file:
writer = csv.DictWriter(file, fieldnames=results[0].keys())
writer.writeheader()
writer.writerows(results)
print(f"Data exported to {csv_file}")
# Run the main function
if __name__ == "__main__":
asyncio.run(main())您可以通过提供一个或多个股票代码作为命令行参数从终端运行脚本。
python google_finance_scraper/main.py AAPL META AMZN TSLA运行脚本后, financial_data.csv 将在同一目录中创建名为的 CSV 文件。此文件将以有组织的方式包含所有数据。CSV 文件将如下所示:

9.将代码部署到 Apify
准备好抓取工具后,就可以使用Apify将其部署到云端 。这样您就可以按计划运行抓取工具并利用 Apify 的强大功能。对于此任务,我们将使用 Python Playwright 模板 进行快速设置。在 Apify 上,抓取工具称为 Actors。
首先从 Apify Python 模板库克隆 Playwright + Chrome模板。
首先,您需要 安装 Apify CLI,它将帮助您管理 Actor。在 macOS 或 Linux 上,您可以使用 Homebrew 执行此操作:
brew install apify-cli或者通过 NPM:
npm -g install apify-cli安装 CLI 后,使用 Python Playwright + Chrome 模板创建一个新的 Actor:
apify create gf-scraper -t python-playwright此命令将在您的目录中设置一个项目 gf-scraper 。它会安装所有必要的依赖项并提供一些样板代码来帮助您入门。
导航到新项目文件夹并使用您喜欢的代码编辑器将其打开。在此示例中,我使用的是 VS Code:
cd gf-scraper
code .该模板附带功能齐全的抓取工具。您可以通过运行命令来测试它, apify run 以查看其运行情况。结果将保存在 中 storage/datasets。
接下来,修改代码 src/main.py 以使其适合抓取 Google Finance。
修改后的代码如下:
from playwright.async_api import async_playwright
from apify import Actor
async def extract_stock_data(page, ticker):
financial_data = {
"ticker": ticker.split(":")[0],
"price": None,
"price_change_value": None,
"price_change_percentage": None,
"close_time": None,
"previous_close": None,
"day_range": None,
"year_range": None,
"market_cap": None,
"avg_volume": None,
"p/e_ratio": None,
"dividend_yield": None,
"primary_exchange": None,
}
# Scrape current price
price_element = await page.query_selector("div.YMlKec.fxKbKc")
if price_element:
price_text = await price_element.inner_text()
financial_data["price"] = price_text.replace(",", "")
# Scrape price change percentage
percentage_element = await page.query_selector("div.enJeMd div.JwB6zf")
if percentage_element:
percentage_text = await percentage_element.inner_text()
financial_data["price_change_percentage"] = percentage_text.strip()
# Scrape price change value
value_element = await page.query_selector("span.P2Luy.ZYVHBb")
if value_element:
value_text = await value_element.inner_text()
value_parts = value_text.split()
if value_parts:
financial_data["price_change_value"] = value_parts[0].replace(
"$", "")
# Scrape close time
close_time_element = await page.query_selector('//div[contains(text(), "Closed:")]')
if close_time_element:
close_time_text = await close_time_element.inner_text()
close_time = close_time_text.split(
"·")[0].replace("Closed:", "").strip()
clean_close_time = close_time.replace("\\u202f", " ")
financial_data["close_time"] = clean_close_time
# Scrape additional financial data
label_elements = await page.query_selector_all(".mfs7Fc")
value_elements = await page.query_selector_all(".P6K39c")
for label_element, value_element in zip(label_elements, value_elements):
label = await label_element.inner_text()
value = await value_element.inner_text()
label = label.strip().lower().replace(" ", "_")
if label in financial_data:
financial_data[label] = value.strip()
return financial_data
async def main() -> None:
"""
Main function to run the Apify Actor and extract stock data using Playwright.
Reads input configuration from the Actor, enqueues URLs for scraping,
launches Playwright to process requests, and extracts stock data.
"""
async with Actor:
# Retrieve input parameters
actor_input = await Actor.get_input() or {}
start_urls = actor_input.get("start_urls", [])
tickers = actor_input.get("tickers", [])
if not start_urls:
Actor.log.info(
"No start URLs specified in actor input. Exiting...")
await Actor.exit()
base_url = start_urls[0].get("url", "")
# Enqueue requests for each ticker
default_queue = await Actor.open_request_queue()
for ticker in tickers:
url = f"{base_url}{ticker}:NASDAQ"
await default_queue.add_request(url)
# Launch Playwright and open a new browser context
Actor.log.info("Launching Playwright...")
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=Actor.config.headless)
context = await browser.new_context()
# Process requests from the queue
while request := await default_queue.fetch_next_request():
url = (
request.url
) # Use attribute access instead of dictionary-style access
Actor.log.info(f"Scraping {url} ...")
try:
# Open the URL in a new Playwright page
page = await context.new_page()
await page.goto(url, wait_until="domcontentloaded")
# Extract the ticker symbol from the URL
ticker = url.rsplit("/", 1)[-1]
data = await extract_stock_data(page, ticker)
# Push the extracted data to Apify
await Actor.push_data(data)
except Exception as e:
Actor.log.exception(
f"Error extracting data from {url}: {e}")
finally:
# Ensure the page is closed and the request is marked as handled
await page.close()
await default_queue.mark_request_as_handled(request)在运行代码之前,更新 目录input_schema.json 中的文件 .actor/ 以包含 Google Finance 报价页面 URL 并添加一个 tickers 字段。
这是更新后的 input_schema.json 文件:
{
"title": "Python Playwright Scraper",
"type": "object",
"schemaVersion": 1,
"properties": {
"start_urls": {
"title": "Start URLs",
"type": "array",
"description": "URLs to start with",
"prefill": [
{
"url": "https://www.google.com/finance/quote/"
}
],
"editor": "requestListSources"
},
"tickers": {
"title": "Tickers",
"type": "array",
"description": "List of stock ticker symbols to scrape data for",
"items": {
"type": "string"
},
"prefill": [
"AAPL",
"GOOGL",
"AMZN"
],
"editor": "stringList"
},
"max_depth": {
"title": "Maximum depth",
"type": "integer",
"description": "Depth to which to scrape to",
"default": 1
}
},
"required": [
"start_urls",
"tickers"
]
}此外, input.json 通过将 URL 更改为 Google Finance 页面来更新文件,以防止执行期间发生冲突,或者您可以直接删除此文件。
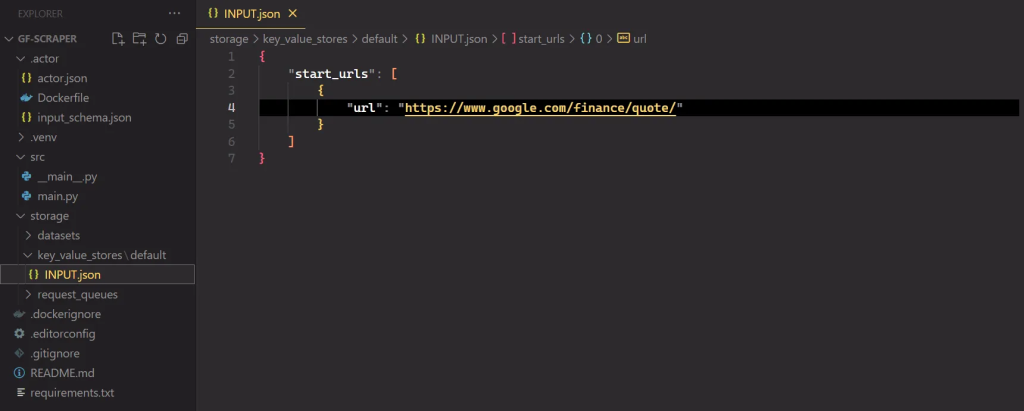
要运行你的 Actor,请在终端中运行以下命令:
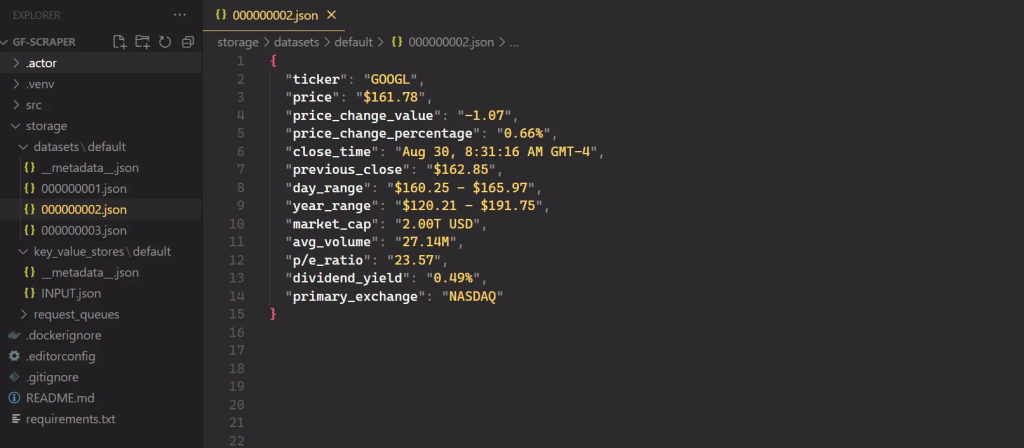
apify run抓取的结果将保存在 中 storage/datasets,其中每个股票代码都有自己的 JSON 文件,如下所示:
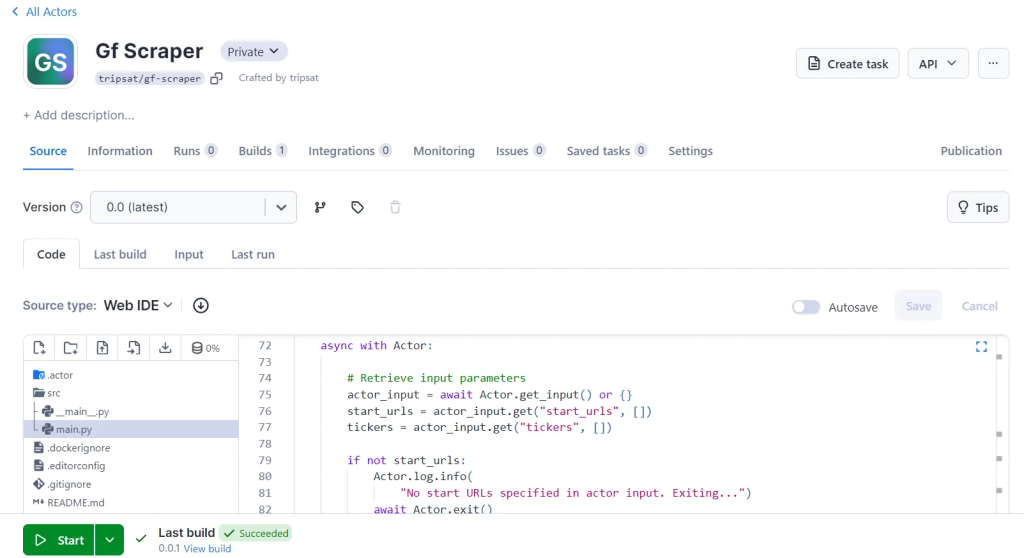
要部署您的 Actor,请先 创建一个 Apify 帐户 (如果您还没有)。然后,从 Apify 控制台的 “设置 → 集成”下获取您的 API 令牌,最后使用以下命令使用您的令牌登录:
apify login -t YOUR_APIFY_TOKEN最后,将您的 Actor 推送到 Apify:
apify push片刻之后,你的 Actor 应该会出现在 Apify 控制台的 Actors → My actors下。
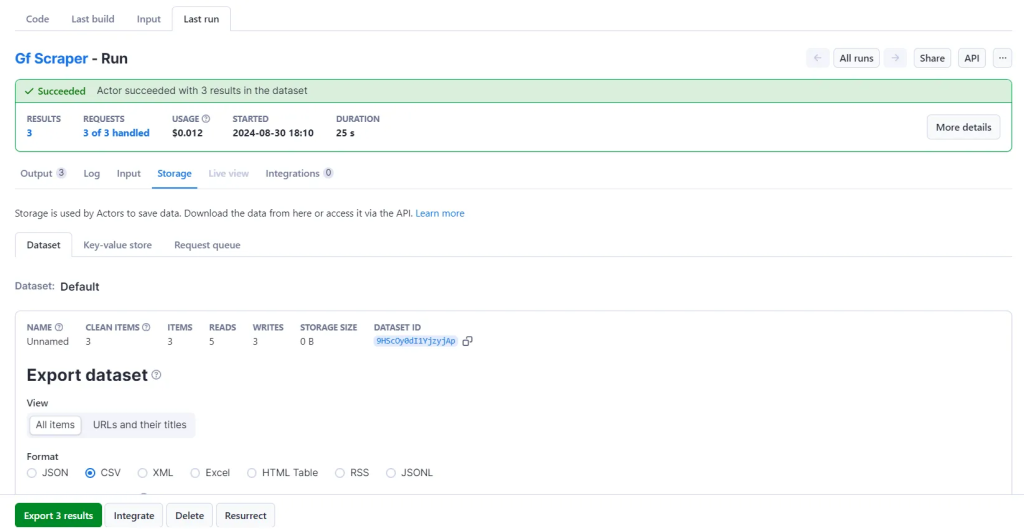
您的抓取工具现已准备好在 Apify 平台上运行。点击“开始”按钮即可开始。运行完成后,您可以从“存储”选项卡预览和下载各种格式的数据。
额外好处: 在 Apify 上运行抓取工具的一个主要优势是可以为同一个 Actor 保存不同的配置并设置自动调度。让我们为我们的 Playwright Actor 设置这个。
在Actor页面上,点击 创建空任务。

接下来,单击 “操作” ,然后 单击“计划”。
最后,选择你希望 Actor 运行的频率并点击 “创建”。
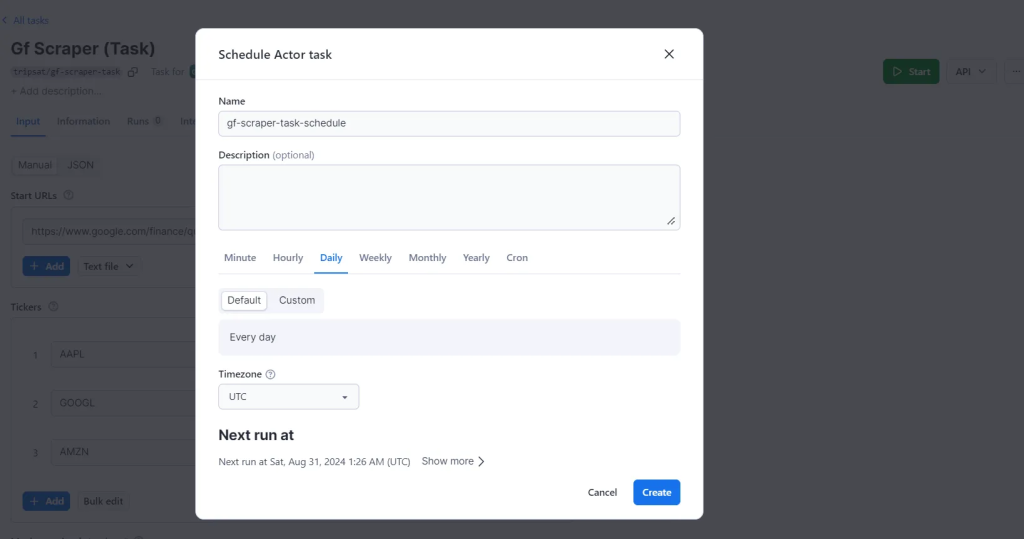
完美!您的 Actor 现已设置为在您指定的时间自动运行。您可以在Apify 平台的“计划”选项卡中查看和管理所有计划的运行。
要开始在 Apify 平台上使用 Python 进行抓取,您可以使用 Python 代码模板。这些模板适用于流行的库,例如 Requests、Beautiful Soup、Scrapy、Playwright 和 Selenium。使用这些模板,您可以快速构建用于各种 Web 抓取任务的抓取工具。
使用代码模板快速构建抓取工具
Google Finance 有 API 吗?
不, Google Finance 没有公开的 API。虽然它曾经有一个,但它在 2012 年被弃用了。从那时起,Google 就没有发布新的公开 API 来通过 Google Finance 访问财务数据。
结论
您已经学会了如何使用 Playwright 与 Google Finance 进行交互并提取有价值的财务数据。您还探索了避免被阻止的方法,并构建了一个代码解决方案,您只需传递股票代码(一个或多个),所有所需数据都会存储在一个 CSV 文件中。此外,您现在对如何使用 Apify 平台 及其 Actor 框架 来构建可扩展的 Web 抓取工具以及安排抓取工具在最方便的时间运行有了深入的了解。
文章来源:https://blog.apify.com/scrape-google-finance-python/#does-google-finance-allow-scraping