使用大语言模型 Cohere API 构建文本分类器的三种方法
有了 LLM,只需少量示例就能快速建立文本分类器。 但您可能需要更多的选项,以及对速度和可定制性的更大控制。 本文将帮助您选择最适合您的任务的选项。
在文本分类领域,开发人员和团队在构建基于人工智能的分类系统时,正在利用大型语言模型(LLM)。 这有别于自己从零开始构建系统,因为后者首先要求团队具备机器学习和工程方面的专业知识,其次需要大量标注的训练数据才能构建出可行的解决方案。
有了 LLM,您无需准备成千上万个训练数据点,只需少量示例即可开始运行,这就是所谓的 “少量分类”(稍后将详细介绍)。 试想一下,收集和构建训练数据集的相关成本、时间和精力将骤然减少。 这意味着更多的团队现在可以考虑部署自己的文本分类系统,而在此之前,他们是不会考虑这样做的。
尽管如此,您可能还是希望对如何训练分类器,尤其是如何从模型中获得最佳性能有一定程度的控制。 例如,如果您碰巧拥有一个大型数据集,您就会希望在训练分类器时充分利用该数据集。 我们希望通过 Cohere API 为开发人员提供这种灵活性。
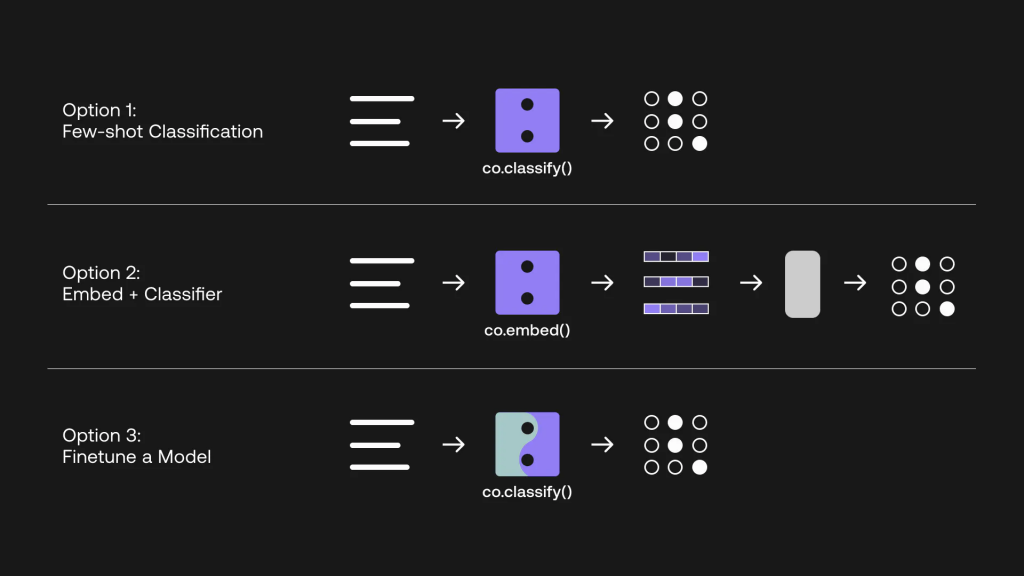
本文将介绍使用 Cohere API 构建文本分类器的三种不同方案。 最后,您将能够评估哪种方案最适合您的目标。
Figure 1您可以根据需要选择最合适的选项
以下是三个选项的概述:
- 使用分类终点进行少量分类
- 使用嵌入式端点构建自己的分类器
- 微调模型

Figure 2使用 Cohere API 构建文本分类器的三种方法
本文展示了一个 Python 笔记本的片段,你可以在下面找到完整版本。
准备数据集
在演示中,我们将以航空公司旅行信息系统 (ATIS) 意图分类数据集的一个子集为例[资料来源]。 该数据集由进入航空公司旅行查询系统的查询组成。 下面是几个示例数据点:
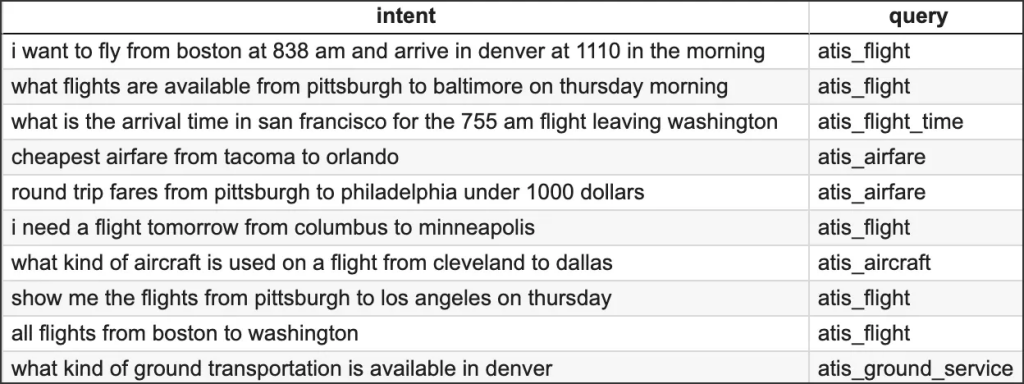
Figure 3几个示例数据
我们的目标是训练分类器,使其能够从以下八个类别中预测新客户咨询的类别:
atis_flight
atis_airfare
atis_airline
atis_ground_service
atis_abbreviation
atis_quantity
atis_aircraft
atis_flight_time为了便于演示,我们将只选取数据集中的一小部分: 总共 1000 个数据点。 首先,我们需要创建一个用于构建分类器的训练数据集和一个用于测试分类器性能的测试数据集。 我们将分别使用 800 和 200 个数据点来创建这两个数据集。
# Load the dataset to a dataframe
df = pd.read_csv("atis_subset.csv")
# Split the dataset into training and test portions
X, y = df["query"], df["intent"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=200, random_state=21)为了准备接下来的章节,让我们来设置 Cohere 的 Python SDK 客户端。
import cohere
co = cohere.Client(“api_key”)方案 1 – 使用分类终点进行少量分类
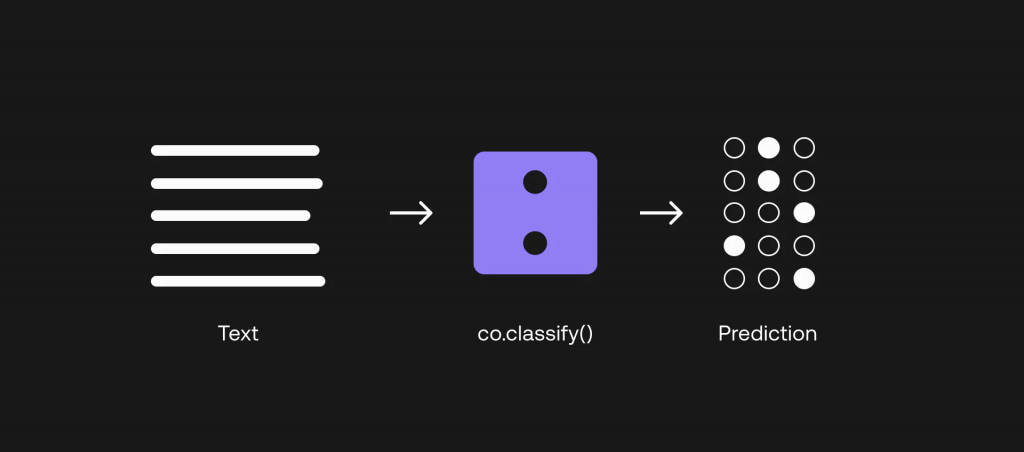
对于 LLM,我们的一个选择是通过少量分类来建立分类器。 这里的 “少量 “指的是,我们只需为每个类别提供少量示例,分类器就能正常工作。 之所以能做到这一点,是因为 LLM 是一个非常庞大的模型,已经用大量文本数据进行了预训练,捕捉到了语言的深层语境。 现在需要做的是,向模型提示我们需要它执行的特定任务,这就是我们现在要做的。
让我们来看看如何做到这一点。 在 Cohere 的分类终端中,”训练 “数据集被称为示例。 每个类的示例数最少为 2 个,每个示例包括一个文本(在我们的例子中为查询)和一个标签(在我们的例子中为标签)。query label
让我们为每个类别创建 6个示例,这样总共就有 48个示例。 我们不需要之前创建的所有训练数据点,因为其他两个选项都需要这些数据点。
# Set the number of examples per category
EX_PER_CAT = 6
# Create list of examples containing texts and labels - sample from the dataset
ex_texts, ex_labels = [], []
for intent in intents:
y_temp = y_train[y_train == intent]
sample_indexes = y_temp.sample(n=EX_PER_CAT, random_state=42).index
ex_texts += X_train[sample_indexes].tolist()
ex_labels += y_train[sample_indexes].tolist()现在我们已经准备好了示例,可以通过 Python SDK 构建分类器。 首先,我们使用 Example 模块按照 SDK 要求的格式整理示例。 接下来,我们通过 co.classify() 方法调用 Classify 端点。 代码如下 Example co.classify()
# Collate the examples via the Example module
from cohere.responses.classify import Example
examples = list()
for txt, lbl in zip(ex_texts,ex_labels):
examples.append(Example(txt,lbl))
# Classification function
def classify_text(texts, examples):
classifications = co.classify(
inputs=texts,
examples=examples
)
return [c.predictions[0] for c in classifications]现在分类器已经准备就绪,我们可以对 100 个数据点进行测试,并得到类别预测结果。
# Create batches of texts and classify them
BATCH_SIZE = 90 # The API accepts a maximum of 96 inputs
y_pred = []
for i in range(0, len(X_test), BATCH_SIZE):
batch_texts = X_test[i:i+BATCH_SIZE].tolist()
y_pred.extend(classify_text(batch_texts, examples))我们将使用准确率和 F1 分数来评估分类器的测试数据集(有关如何评估分类器的更多信息,请点击此处)。Accuracy F1-score
# Compute metrics on the test dataset
accuracy = accuracy_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred, average='weighted')我们获得了 83.00% 的准确率和 84.66% 的 F1 分数。 考虑到我们只为每个类别提供了六个示例,这一结果令人印象深刻。 但肯定还有改进的余地。Accuracy F1-score
方案 2 – 使用嵌入式端点创建自己的分类器
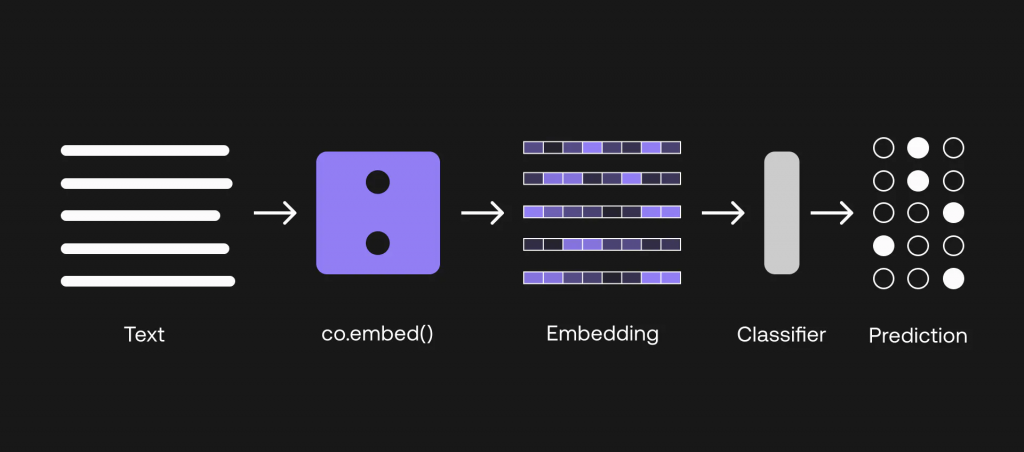
Figure 4使用嵌入式端点构建自己的分类器
虽然我们在上一节中取得了不错的结果,但有时我们需要更多。 要知道,我们在演示中只使用了一小部分数据,而在现实世界中,这将更具挑战性。 因此,我们仍然需要找到改进的方法。
比方说,你实际上掌握了相当数量的训练数据集。 在剩下的两个选项中,我们将研究如何利用这些数据点来构建一个性能可能更好的分类器。
在本节中,我们将讨论选项 2,即如何利用嵌入式端点建立分类器。 请注意,本节确实需要对机器学习有一点了解才能建立模型。
这一次,我们将使用之前准备的全部 800 个训练数据点。 第一步是将训练输入和测试输入(即航空公司查询)转化为嵌入。
嵌入式到底是什么? 您可以在本文中了解更多相关信息,但总的来说,它是一组数字,代表了一段文本的含义,捕捉了其上下文和语义。 在我们的案例中,我们使用的是中型模型,该模型生成的嵌入式大小为 2096。 因此,对于我们输入的每个文本,都会得到一个由 2096 个数字组成的嵌入,如下所示:medium
[0.20641953, 0.35582256, 0.6058123, -0.058944624, 0.8949609, 1.2956009, 1.2408538, -0.89241934, -0.56218493, -0.5521631, -0.11521566, 0.9081634, 1.662983, -0.9293592, -2.3170912, 1.177852, 0.35577637, ... ]为此,我们通过 co.embed() 方法调用嵌入端点,选择分类作为输入_类型参数。 然后,我们将嵌入转化为一个数组,下一步就需要用到这个数组了。 它看起来如下:co.embed() classification input_type
# Get embeddings
def embed_text(text):
output = co.embed(
model='embed-english-v3.0',
input_type="classification",
texts=text)
return output.embeddings
# Embed and prepare the inputs
X_train_emb = np.array(embed_text(X_train.tolist()))
X_test_emb = np.array(embed_text(X_test.tolist()))下一步,我们将使用这些嵌入作为输入建立一个分类模型。 我们将使用支持向量机(SVM)算法,利用 scikit-learn 库中的实现。 该方法称为 SVC,您可以在此阅读相关信息。SVC
下面展示的是我们的实现片段(完整版在笔记本中)。 总之,我们将训练数据集拟合到模型中,然后使用这个训练有素的模型来预测测试数据集的类别。
# Initialize the model
svm_classifier = SVC(class_weight='balanced')
# Fit the training dataset to the model
svm_classifier.fit(X_train_emb, y_train_le)
# Generate classification predictions on the test dataset
y_pred_le = svm_classifier.predict(X_test_emb)我们现在要做的是将嵌入作为特征来训练机器学习模型。 然后,该模型将学习包含输入文本语义信息的特征与提供每个输入文本所属类别信息的标签之间的映射。features features labels
我们将再次使用准确率和 F1 分数来评估分类器在该测试数据集上的表现。 这次,我们获得了 91.50% 的准确率和 91.01% 的 F1 分数。AccuracyF1 score AccuracyF1 score
这比以前的方法有所改进。 但我们还能做得更好吗?
方案 3–微调模型
Figure 5通过分类端点微调模型
使用 Cohere API 进行微调是一个强大的概念,原因就在这里。 在上一节中,我们使用 Embed 端点的输出建立了一个分类器,但请注意,我们使用的仍然是一个基准模型。 但通过微调,你实际上可以改变模型本身,并根据你的任务进行定制。
这就意味着,你所得到的是一个经过微调的自定义模型,它在特定任务中表现出色,并有可能优于我们所见过的前两种方法。 这就是我们本节要做的。
数据点越多越好,但作为一个例子,我们将使用之前准备的 800 个训练数据点对模型进行微调。
本文档包含如何微调表示模型的分步指南,表示模型与嵌入端点背后的模型是同一种模型。 因此,本文将不涉及微调步骤,并假设您已经准备好了微调模型。
当你对表示模型进行微调时,在幕后发生的事情是,模型会将同一类别的示例拉近,反之,将不同类别的示例拉远。 它是通过学习输入(即嵌入)和输出(标签)之间的关系,捕捉数据中的模式来做到这一点的。
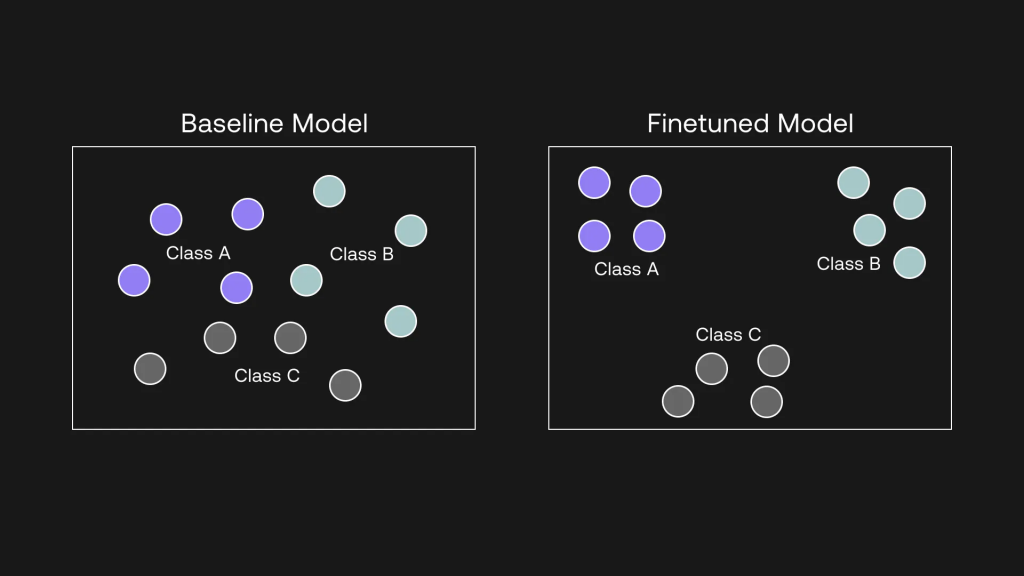
Figure 6微调将相似的例子拉近,将不相似的例子推远
对模型进行微调后,可从 Playground 或直接从 Cohere 控制面板获取模型 UUID。
要使用这个经过微调的模型,可以通过我们之前使用的 co.classify() 方法调用相同的分类端点。 调用端点的方法是一样的,只是在参数中输入的是微调模型 UUID,而不是基准版本。 下面是代码片段,如你所见,只需几行代码。co.classify()
# Classification function
def classify_text_finetune(texts, examples):
classifications = co.classify(
model='eeba7d8c-61bd-42cd-a6b5-e31db27403cc-ft',
inputs=texts,
examples=examples
)
return [c.predictions[0] for c in classifications]
# Create batches of texts and classify them
BATCH_SIZE = 90 # The API accepts a maximum of 96 inputs
y_pred = []
for i in range(0, len(X_test), BATCH_SIZE):
batch_texts = X_test[i:i+BATCH_SIZE].tolist()
y_pred.extend(classify_text_finetune(batch_texts, examples))请注意,由于模型已通过训练数据集进行了微调,因此现在调用 “分类 “端点无需再像第一个选项那样输入示例。 现在整个实现过程更加简洁。
重要的是,这也意味着,对于不太熟悉机器学习的开发人员来说,处理嵌入式的所有复杂性都已消除。 现在一切都发生在后台,你需要知道的只有两个步骤,仅此而已。
- 微调模型
- 使用分类端点调用微调模型。
这一次,我们获得了 94.50% 的准确率和 94.53% 的 F1 分数。 这是一个明显的提升!
回顾:
我希望这些示例能让您了解不同选项之间的比较。 我们看到了少镜头分类如何消除了建立训练数据集的需要,也看到了微调如何带来最佳性能。 当然,在不同的数据集和任务下,情况并不总是如此,但大体上,这是你所期望的模式。
最重要的是,在使用分类端点时,您的控制水平非常重要。
如果您的训练数据有限,但又需要以最小的代价快速建立文本分类器,那么 “少量尝试 “选项可以帮助您实现这一目标,并获得可观的性能。
如果最大限度地提高性能是最重要的,那么您可以建立一个数据集,并在此基础上对模型进行微调,而无需处理复杂的机器学习问题。
最后,如果你确实想亲自动手学习机器学习,并想自己决定最适合你的任务的分类算法,你可以选择嵌入选项。