GraphQL API手册:如何构建、测试、使用和记录
大家好!在本教程中,我们将深入研究 GraphQL API。
我最近写了这篇文章,解释了当今常见 API 类型之间的主要区别。本教程旨在向您展示如何完全实现 GraphQL API 的示例。
我们将介绍 Node 和 Apollo GraphQL 的基本设置和架构,使用 Supertest 进行单元测试,了解如何使用 Apollo 客户端从 React 前端应用程序使用 API,最后使用 Apollo 沙箱记录 API。
请记住,我们不会太深入地介绍每种技术的工作原理。此处的目标是为您提供一个关于GraphQL API工作原理的一般概述,包括其各个部分如何交互以及完整实现可能包含的内容。
什么是 GraphQL?
GraphQL,这款API查询语言和运行时,是由Facebook在2012年开发的。它在2015年向公众发布后,迅速获得了广泛的认可,成为了REST API的一个重要替代品。
GraphQL 最初由 Facebook 开发,旨在简化其移动应用程序的数据获取。他们需要一个方法,既能从服务器发送复杂的数据请求,又不会引发性能问题或造成数据过度获取。GraphQL 的诞生是出于解决这些问题的需要。
GraphQL 于 2015 年作为开源项目发布,此后在开发者社区中广受欢迎。现在,许多开发工具和框架都支持它,包括 Apollo、Prisma 和 Hasura。
主要特点:
- 强类型:GraphQL API 是强类型的,这意味着每个字段都有特定的数据类型。这使得在客户端和服务器端验证和处理数据变得更加容易。
- 查询语言:GraphQL 有自己的查询语言,允许客户端准确指定他们需要的数据。这减少了数据的过度获取并提高了性能。
- 单端点:GraphQL API 具有单个终端节点,这意味着客户端可以从单个请求中获取所需的所有数据。
- 声明:GraphQL API 是声明性的,这意味着客户端指定他们想要什么,而不是如何获得它。这允许更高效、更灵活的数据获取。
- 架构驱动:GraphQL API 是架构驱动的,这意味着架构定义了数据的结构以及可用的查询和更改。这使开发人员更容易理解和使用 API。
优点:
- 高效的数据获取:GraphQL API 允许客户端仅获取他们需要的数据,从而减少过度获取并提高性能。
- 强类型:GraphQL API 是强类型的,可以更轻松地验证和处理数据。
- 单端点:GraphQL API 具有单个终端节点,从而降低了 API 的复杂性并使其更易于使用。
- 架构驱动:GraphQL API 是架构驱动的,这使得开发人员更容易理解和使用 API。
缺点:
- 复杂性:与 REST API 相比,GraphQL API 的设置和使用可能更复杂。
- 缓存:由于 API 的灵活特性,使用 GraphQL API 进行缓存可能更具挑战性。
- 学习曲线:GraphQL 需要开发人员和客户都有一个学习曲线,因为它有自己的查询语言和数据获取方法。
最适合:
- 高效灵活的需求:GraphQL 非常适合构建需要高效灵活数据获取的应用程序,例如移动和 Web 应用程序。
- 复杂数据要求:在面临复杂数据需求和过度获取数据可能引发性能问题的情况下,GraphQL 显得尤为有用。
因此,概括地说,GraphQL 是一种 API 的查询语言和运行时,可提供高效灵活的数据获取功能。
虽然与 REST API 相比,它的设置和使用可能更复杂,但它提供了强类型数据、单一端点和架构驱动开发等优势。对于构建具有复杂数据要求的应用程序而言,GraphQL 非常适用,尤其是在高效数据获取至关重要的场景下。
核心 GraphQL 概念
在我们开始构建之前,您需要了解一些核心 GraphQL 概念,以便了解您在做什么以及代码将如何工作。
对象类型
在 GraphQL 中,对象类型是表示字段集合的复杂类型。对象类型用于定义可通过 GraphQL API 查询和更改的数据结构。
每个 Object Type 都有一个唯一的名称和一组字段,其中每个字段都有一个 name 和一个 type。字段的类型可以是标量类型(如 Int、String 或 Boolean)、其他 Object Type 或其他类型的列表。
如果您对 TypeScript 和接口有所了解,那么这可能会让您联想到某些相似之处或引起您的警觉。
以下是在社交媒体应用程序中表示 “User” 的 Object Type 示例:
type User {
id: ID!
name: String!
email: String!
friends: [User!]!
}该符号表示该字段为必填字段。!
在此示例中,“User” 对象类型有四个字段:“id”、“name”、“email”和“friends”。“id”字段的类型为 ID,它是 GraphQL 中的内置标量类型,表示唯一标识符。“name” 和 “email” 字段的类型为 String,“friends” 字段的类型为 “User” 对象列表。
下面是在库应用程序中表示 “Book” 的 Object Type 的另一个示例:
type Book {
id: ID!
title: String!
author: Author!
genre: String!
published: Int!
}在此示例中,“Book”对象类型有五个字段:“id”、“title”、“author”、“genre”和“published”。“id”字段的类型为 ID,“title”和“genre”字段的类型为 String,“published”字段的类型为 Int,“author”字段的类型为“Author”对象。
对象类型可用于定义从 GraphQL API 中的查询或更改返回的数据的结构。例如,返回用户列表的查询可能如下所示:
query {
users {
id
name
email
friends {
id
name
}
}
}在此查询中,“users”字段返回“User”对象的列表,查询指定要包含在响应中的字段。
查询
在 GraphQL 中,查询是来自服务器的特定数据的请求。查询指定客户端想要接收的数据的形状,服务器以相同的形状响应请求的数据。
GraphQL 中的查询遵循与预期接收的数据形状类似的结构。它由一组字段组成,这些字段对应于客户端要检索的数据的属性。每个字段还可以具有修改返回数据的参数。
以下是 GraphQL 中的简单查询示例:
query {
user(id: "1") {
name
email
age
}
}在此示例中,查询请求有关 ID 为“1”的用户的信息。查询中指定的字段是 “name”、“email” 和 “age”,它们对应于 user 对象的属性。
来自服务器的响应将与查询的形状相同,请求的数据将在相应的字段中返回:
{
"data": {
"user": {
"name": "John Doe",
"email": "johndoe@example.com",
"age": 25
}
}
}此处,服务器在 “name”、“email” 和 “age” 字段中返回了有关用户的请求数据。数据包含在 “data” 对象中,以将其与响应中可能包含的任何错误或其他元数据区分开来。
突变
在 GraphQL 中,更改用于在服务器上修改或创建数据。与查询类似,mutation 也用于指定发送到服务器和从服务器接收的数据的形状。它们之间的主要区别在于,查询仅用于读取数据,而 mutation 则既可以读取数据也可以写入数据。
以下是 GraphQL 中的简单更改示例:
mutation {
createUser(name: "Jane Doe", email: "janedoe@example.com", age: 30) {
id
name
email
age
}
}在此示例中,更改是在服务器上创建一个名为 “Jane Doe” 、电子邮件 “janedoe@example.com” 且年龄为 30 的新用户。更改中指定的字段是 “id”、“name”、“email” 和 “age”,它们对应于 user 对象的属性。
来自服务器的响应将与 mutation 的形状相同,新创建的用户数据将在相应的字段中返回:
{
"data": {
"createUser": {
"id": "123",
"name": "Jane Doe",
"email": "janedoe@example.com",
"age": 30
}
}
}在这里,服务器在 “id”、“name”、“email” 和 “age” 字段中返回了有关新创建用户的数据。
更改还可用于更新或删除服务器上的数据。下面是一个更新用户名的 mutation 示例:
mutation {
updateUser(id: "123", name: "Jane Smith") {
id
name
email
age
}
}在此示例中,更改将 ID 为“123”的用户更新为名称“Jane Smith”。更改中指定的字段与上一个示例中指定的字段相同。
来自服务器的响应将是更新的用户数据:
{
"data": {
"updateUser": {
"id": "123",
"name": "Jane Smith",
"email": "janedoe@example.com",
"age": 30
}
}
}GraphQL 中的突变设计为可组合的,这意味着可以将多个突变合并到一个请求中。这允许客户端使用单个网络往返执行复杂的操作。
解析器
在 GraphQL 中,解析程序是负责获取 GraphQL 架构中定义的特定字段的数据的函数。解析程序是架构和数据源之间的桥梁。resolver 函数接收四个参数:parent、args、context 和 info。
parent:当前字段的父对象。在嵌套查询中,它引用父字段的值。args:传递给当前字段的参数。它是一个对象,其中包含参数名称及其值的键值对。context:在特定请求的所有解析程序之间共享的对象。它包含有关请求的信息,例如当前经过身份验证的用户、数据库连接等。info:包含有关查询的信息,包括字段名称、别名和查询文档 AST。
以下是类型字段的解析程序函数示例:User posts
const resolvers = {
User: {
posts: (parent, args, context, info) => {
return getPostsByUserId(parent.id);
},
},
};在此示例中,是具有字段的 GraphQL 对象类型。查询字段时,将使用父对象、传递的任何参数、上下文对象和查询信息调用解析程序函数。在此示例中,resolver 函数调用函数来获取当前用户的帖子。User posts posts User getPostsByUserId
解析程序还可用于更改以创建、更新或删除数据。以下是 mutation 的解析程序函数示例:createUser
const resolvers = {
Mutation: {
createUser: (parent, args, context, info) => {
const user = { name: args.name, email: args.email };
const createdUser = createUser(user);
return createdUser;
},
},
};在此示例中,是具有 mutation 字段的 GraphQL 对象类型。调用更改时,将使用父对象、传递的参数、上下文对象和查询信息调用解析程序函数。在此示例中,resolver 函数调用一个函数来创建具有给定名称和电子邮件的新用户,并返回新创建的用户。Mutation createUser createUser
模式
在 GraphQL 中,架构是一个蓝图,用于定义可在 API 中查询的数据的结构。它定义了可对这些类型执行的可用类型、字段和操作。
GraphQL 架构是用 GraphQL 架构定义语言 (SDL) 编写的,该语言使用简单的语法来定义 API 中可用的类型和字段。服务器端代码通常会定义架构,这个架构随后被用来验证和执行传入的查询。
以下是一个简单的 GraphQL 架构定义示例:
type Book {
id: ID!
title: String!
author: String!
published: Int!
}
type Query {
books: [Book!]!
book(id: ID!): Book
}
type Mutation {
addBook(title: String!, author: String!, published: Int!): Book!
updateBook(id: ID!, title: String, author: String, published: Int): Book
deleteBook(id: ID!): Book
}在此架构中,我们有三种类型: 、 和 。该类型有四个字段: 、 、 和 。该类型有两个字段: 和 ,分别可用于按 ID 检索书籍列表或特定书籍。该类型有三个字段: 、 、 和 ,可用于创建、更新或删除书籍。BookQueryMutation Book id title author published Query books book Mutation addBook updateBook delete Book
请注意,每个字段都有一个类型,可以是内置标量类型(如 或 ),也可以是自定义类型(如 .类型之后表示该字段不可为 null,这意味着它必须始终返回一个值(即,它不能为 null)。String Int Book!
TLDR 和与等效 REST 概念的比较
- 对象类型:在 GraphQL 中,对象类型用于定义可从 API 查询的数据,类似于在 REST API 中定义响应数据模型的方式。但是,与 REST 不同的是,在 REST 中,数据模型通常以不同的格式(例如 JSON 或 XML)定义,而 GraphQL 对象类型是使用与语言无关的单一语法定义的。
- 查询:在 GraphQL 中,查询用于从 API 获取数据,类似于 REST API 中的 HTTP GET 请求。但是,与 REST API 不同,REST API 可能需要多个请求才能获取嵌套数据,而 GraphQL 查询可用于在单个请求中获取嵌套数据。
- 突变:在 GraphQL 中,更改用于修改 API 中的数据,类似于 REST API 中的 HTTP POST、PUT 和 DELETE 请求。但是,与 REST API 不同的是,GraphQL 不需要不同的终端节点来执行不同的修改。相反,GraphQL 的更改(即 mutation)是通过单个终端节点执行的。
- 解析 器:在 GraphQL 中,解析程序用于指定如何获取查询或更改中特定字段的数据。解析程序类似于 REST API 中的控制器方法,用于从数据库获取数据并将其作为响应返回。
- 模式:在 GraphQL 中,架构用于定义可从 API 查询或更改的数据。它指定了可以请求的数据类型、如何查询这些数据以及允许哪些更改。在 REST API 中,架构通常使用 OpenAPI 或 Swagger 定义,它们指定 API 的终端节点、请求和响应类型以及其他元数据。
总体而言,GraphQL 和 REST API 在处理数据获取和修改的方式上有所不同。
REST API 依赖于多个终端节点和 HTTP 方法来获取和修改数据,而 GraphQL 使用单个终端节点和查询/更改来完成相同的操作。
与 REST API 相比,GraphQL 通过使用单个架构来定义整个 API 的数据模型,从而大大简化了数据模型的理解和维护工作。相比之下,REST API 往往需要使用多种文档格式来描述相同的数据模型,这不仅增加了复杂性,还可能导致不一致性和混淆。
如何使用 Node 和 Apollo GraphQL 构建 GraphQL API
我们的工具
Node.js 是一个开源、跨平台的后端 JavaScript 运行时环境,允许开发人员在 Web 浏览器之外执行 JavaScript 代码。它由 Ryan Dahl 于 2009 年创建,此后成为构建 Web 应用程序、API 和服务器的流行选择。
Node.js 提供了一种事件驱动的非阻塞 I/O 模型,使其轻量级且高效,使其能够以高性能处理大量数据。它还拥有一个庞大而活跃的社区,有许多库和模块可用于帮助开发人员更快、更轻松地构建他们的应用程序。
Apollo GraphQL 是用于构建 GraphQL API 的全栈平台。它提供的工具和库可简化构建、管理和使用 GraphQL API 的过程。
Apollo GraphQL 平台的核心是 Apollo Server,这是一种轻量级且灵活的服务器,可以轻松构建可扩展且高性能的 GraphQL API。Apollo Server 能够支持多种数据源,诸如数据库、REST API 以及其他服务,这使得它非常便于与现有的系统进行集成。
Apollo 还提供了许多客户端库,包括适用于 Web 和移动设备的 Apollo 客户端,这简化了使用 GraphQL API 的过程。Apollo Client 使查询和更改数据变得容易,并提供缓存、乐观 UI 和实时更新等高级功能。
除了 Apollo Server 和 Apollo Client,Apollo 还提供许多其他工具和服务,包括架构管理平台、GraphQL 分析服务以及一组用于构建和调试 GraphQL API 的开发人员工具。
如果您是 GraphQL 或 Apollo 本身的新手,我真的建议您查看他们的文档。在我看来,他们是最好的。
我们的架构
对于这个项目,我们将在代码库中遵循 layers 架构。层架构是将关注点和职责划分为不同的文件夹和文件,并且只允许某些文件夹和文件之间直接通信。
你的项目应该有多少个层,每个层应该有什么名称,以及它应该处理什么操作,这些都是讨论的问题。那么,让我们看看我认为对于我们的示例来说,什么是好方法。
我们的应用程序将有五个不同的层,它们将按以下方式排序:
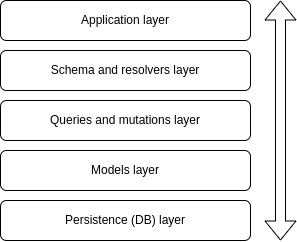
应用程序层
- 应用程序层将具有我们服务器的基本设置以及与 schema 和 resolvers(下一层)的连接。
- 架构和解析器层将具有我们数据的类型定义以及与我们的查询和更改(下一层)的连接。
- 查询和变更层将具有我们想要在每个查询和变更中执行的实际逻辑,以及与模型层的连接(下一层,您明白了……
- 模型层将保存与我们的 mock 数据库交互的逻辑。
- 最后,持久层是我们的数据库所在的位置。
要记住的重要一点是,在这些类型的架构中,各层之间有一个定义的通信流,必须遵循该流才能有意义。
这意味着请求首先必须经过第一层,然后是第二层,然后是第三层,依此类推。任何请求都不应该跳过层,因为这会扰乱架构的逻辑以及它给我们带来的组织和模块化的好处。
如果您想了解其他一些 API 架构选项,我推荐我前段时间写的这篇软件架构文章。
代码
在跳转到代码之前,我们先提一下我们实际要构建的内容。我们将执行基本的 CRUD 操作(创建、读取、更新和删除)。
我们使用的是与我关于完全实现 REST API 的文章中使用的完全相同的示例。如果您也有兴趣阅读这些内容,这应该有助于比较 REST 和 GraphQL 之间的概念,并了解它们的异同。;)
现在让我们开始这件事。创建一个新目录,跳入该目录,然后通过运行 .对于我们的 GraphQL 服务器,我们还需要两个依赖项,因此 run 和 too。npm init -ynpm i @apollo/servernpm i graphql
App.js
在项目的根目录中,创建一个文件并将以下代码放入其中:app.js
import { ApolloServer } from '@apollo/server'
import { startStandaloneServer } from '@apollo/server/standalone'
import { typeDefs, resolvers } from './pets/index.js'
// The ApolloServer constructor requires two parameters: your schema
// definition and your set of resolvers.
const server = new ApolloServer({
typeDefs,
resolvers
})
// Passing an ApolloServer instance to the startStandaloneServer function:
// 1. creates an Express app
// 2. installs your ApolloServer instance as middleware
// 3. prepares your app to handle incoming requests
const { url } = await startStandaloneServer(server, {
listen: { port: 4000 }
})
console.log(🚀 Server ready at: ${url})在这里,我们设置了我们的 Apollo 服务器,通过向它传递我们的 typeDefs 和解析器(我们稍后会解释它们),然后在端口 4000 中启动服务器。
接下来,在您的项目中创建以下文件夹结构:
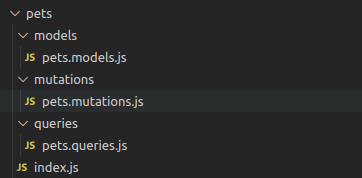
我们的文件夹结构
index.js
在文件中放置以下代码:index.js
import { addPet, editPet, deletePet } from './mutations/pets.mutations.js'
import { listPets, getPet } from './queries/pets.queries.js'
// A schema is a collection of type definitions (hence "typeDefs")
// that together define the "shape" of queries that are executed against your data.
export const typeDefs = `#graphql
# OBJECT TYPES
# This "Pet" type defines the queryable fields for every pet in our data source.
type Pet {
id: ID!
name: String!
type: String!
age: Int!
breed: String!
}
# INPUT TYPES
# Define the input objects for addPet and editPet mutations
input PetToEdit {
id: ID!
name: String!
type: String!
age: Int!
breed: String!
}
input PetToAdd {
name: String!
type: String!
age: Int!
breed: String!
}
# The "Query" type is special: it lists all of the available queries that
# clients can execute, along with the return type for each. In this
# case, the "pets" query returns an array of zero or more pets.
# QUERY TYPES
type Query {
pets: [Pet],
pet(id: ID!): Pet
}
# MUTATION TYPES
type Mutation {
addPet(petToAdd: PetToAdd!): Pet,
editPet(petToEdit: PetToEdit!): Pet,
deletePet(id: ID!): [Pet],
}
`
export const resolvers = {
// Resolvers for Queries
Query: {
pets: () => listPets(),
pet: (_, { id }) => getPet(id)
},
// Resolvers for Mutations
Mutation: {
addPet: (_, { petToAdd }) => addPet(petToAdd),
editPet: (_, { petToEdit }) => editPet(petToEdit),
deletePet: (_, { id }) => deletePet(id)
}
}这里我们有两个主要的东西:typeDefs 和 resolvers。
typeDefs 定义可在 API 中查询的数据的类型(在我们的例子中是对象),以及查询/更改的输入(在我们的例子中是 and)。pet PetToEdit PetToAdd
最后,它还定义了 API 的可用查询和更改,声明它们的名称以及它们的输入和返回值。在我们的例子中,我们有两个查询 ( 和 ) 和三个变化 ( 和 )。pets pet addPet editPet deletePet
Resolvers 包含我们的 queries 和 mutations 类型的实际实现。在这里,我们声明了每个 query 和 mutation,并指出每个 query 和 mutation 应该做什么。在我们的例子中,我们将它们与我们从 queries/mutations 层导入的 queries/mutation 链接起来
pets.queries.js
In your file drop this:pets.queries.js
import { getItem, listItems } from '../models/pets.models.js'
export const getPet = id => {
try {
const resp = getItem(id)
return resp
} catch (err) {
return err
}
}
export const listPets = () => {
try {
const resp = listItems()
return resp
} catch (err) {
return err
}
}如您所见,此文件非常简单。它声明文件中导入的函数,并将它们链接到 models 层中声明的函数。index.js
pets.mutations.js
我们的文件也是如此,但现在有了 mutations。pets.mutations.js
import { editItem, addItem, deleteItem } from '../models/pets.models.js'
export const addPet = petToAdd => {
try {
const resp = addItem(petToAdd)
return resp
} catch (err) {
return err
}
}
export const editPet = petToEdit => {
try {
const resp = editItem(petToEdit?.id, petToEdit)
return resp
} catch (err) {
return err
}
}
export const deletePet = id => {
try {
const resp = deleteItem(id)
return resp
} catch (err) {
return err
}
}pets.models.js
现在转到 models 文件夹并创建一个包含此代码的文件:pets.models.js
import db from '../../db/db.js'
export const getItem = id => {
try {
const pet = db?.pets?.filter(pet => pet?.id === parseInt(id))[0]
return pet
} catch (err) {
console.error('Error', err)
return err
}
}
export const listItems = () => {
try {
return db?.pets
} catch (err) {
console.error('Error', err)
return err
}
}
export const editItem = (id, data) => {
try {
const index = db.pets.findIndex(pet => pet.id === parseInt(id))
if (index === -1) throw new Error('Pet not found')
else {
data.id = parseInt(data.id)
db.pets[index] = data
return db.pets[index]
}
} catch (err) {
console.error('Error', err)
return err
}
}
export const addItem = data => {
try {
const newPet = { id: db.pets.length + 1, ...data }
db.pets.push(newPet)
return newPet
} catch (err) {
console.error('Error', err)
return err
}
}
export const deleteItem = id => {
try {
// delete item from db
const index = db.pets.findIndex(pet => pet.id === parseInt(id))
if (index === -1) throw new Error('Pet not found')
else {
db.pets.splice(index, 1)
return db.pets
}
} catch (err) {
console.error('Error', err)
return err
}
}这些是负责与我们的数据层(数据库)交互并将相应信息返回给我们的控制器的函数。
数据库
对于此示例,我们不会使用真实的数据库。相反,为了示例的目的,我们将仅使用一个简单的数组。尽管这样做意味着每次服务器重置时数据都会被重置,但它已经足够满足我们的演示需求。
在项目的根目录中,创建一个文件夹和一个文件,其中包含以下代码:db db.js
const db = {
pets: [
{
id: 1,
name: 'Rex',
type: 'dog',
age: 3,
breed: 'labrador',
},
{
id: 2,
name: 'Fido',
type: 'dog',
age: 1,
breed: 'poodle',
},
{
id: 3,
name: 'Mittens',
type: 'cat',
age: 2,
breed: 'tabby',
},
]
}
export default db如你所见,我们的对象包含一个属性,其值是一个对象数组,每个对象都是一个宠物。对于每只宠物,我们都会存储一个 ID、名称、类型、年龄和品种。dbpets
现在转到您的终端并运行 。您应该会看到以下消息,确认您的服务器处于活动状态: 。nodemon app.js🚀 Server ready at: [http://localhost:4000/](http://localhost:4000/)
如何使用 Supertest 测试 GraphQL API
现在我们的服务器已经启动并运行,让我们实现一个简单的测试套装来检查我们的查询和更改是否按预期运行。
如果您不熟悉自动化测试,我建议您阅读我前段时间写的这篇介绍性文章。
我们的工具
SuperTest 是一个 JavaScript 库,用于测试发出 HTTP 请求的 HTTP 服务器或 Web 应用程序。它为测试 HTTP 提供了高级抽象,允许开发人员发送 HTTP 请求并对收到的响应进行断言,从而更轻松地为 Web 应用程序编写自动化测试。
SuperTest 可与任何 JavaScript 测试框架(如 Mocha 或 Jest)配合使用,也可与任何 HTTP 服务器或 Web 应用程序框架(如 Express)一起使用。
SuperTest 建立在流行的测试库 Mocha 之上,并使用 Chai 断言库对收到的响应进行断言。它提供了一个易于使用的 API 来发出 HTTP 请求,包括对身份验证、标头和请求正文的支持。
SuperTest 还允许开发人员测试整个请求/响应周期,包括中间件和错误处理,使其成为测试 Web 应用程序的强大工具。
总体而言,对于希望为其 Web 应用程序编写自动化测试的开发人员来说,SuperTest 是一个有价值的工具。它有助于确保他们的应用程序能够正常运行,同时也能够避免他们对代码库所做的任何更改引入新的错误或问题。
代码
首先,我们需要安装一些依赖项。要保存终端命令,请转到您的文件并将您的部分替换为下面的代码。然后运行 .package.json devDependencies npm install
"devDependencies": {
"@babel/core": "^7.21.4",
"@babel/preset-env": "^7.21.4",
"babel-jest": "^29.5.0",
"jest": "^29.5.0",
"jest-babel": "^1.0.1",
"nodemon": "^2.0.22",
"supertest": "^6.3.3"
}在这里,我们将安装 and 库,这是我们运行测试所需的库,以及我们的项目需要的一些东西,以便正确识别哪些文件是测试文件。super test jest babel
仍在 您的 中,添加以下脚本:package.json
"scripts": {
"test": "jest"
},要以样板结束,请在项目的根目录中创建一个文件并将以下代码放入其中:babel.config.cjs
//babel.config.cjs
module.exports = {
presets: [
[
'@babel/preset-env',
{
targets: {
node: 'current',
},
},
],
],
};现在让我们编写一些实际测试!在 pets 文件夹中,创建一个包含以下代码的文件:pets.test.js
import request from 'supertest'
const graphQLEndpoint = 'http://localhost:4000/'
describe('Get all pets', () => {
const postData = {
query: `query Pets {
pets {
id
name
type
age
breed
}
}`
}
test('returns all pets', async () => {
request(graphQLEndpoint)
.post('?')
.send(postData)
.expect(200)
.end((error, response) => {
if (error) console.error(error)
const res = JSON.parse(response.text)
expect(res.data.pets).toEqual([
{
id: '1',
name: 'Rex',
type: 'dog',
age: 3,
breed: 'labrador'
},
{
id: '2',
name: 'Fido',
type: 'dog',
age: 1,
breed: 'poodle'
},
{
id: '3',
name: 'Mittens',
type: 'cat',
age: 2,
breed: 'tabby'
}
])
})
})
})
describe('Get pet detail', () => {
const postData = {
query: `query Pet {
pet(id: 1) {
id
name
type
age
breed
}
}`
}
test('Return pet detail information', async () => {
request(graphQLEndpoint)
.post('?')
.send(postData)
.expect(200)
.end((error, response) => {
if (error) console.error(error)
const res = JSON.parse(response.text)
expect(res.data.pet).toEqual({
id: '1',
name: 'Rex',
type: 'dog',
age: 3,
breed: 'labrador'
})
})
})
})
describe('Edit pet', () => {
const postData = {
query: `mutation EditPet($petToEdit: PetToEdit!) {
editPet(petToEdit: $petToEdit) {
id
name
type
age
breed
}
}`,
variables: {
petToEdit: {
id: 1,
name: 'Rexo',
type: 'dogo',
age: 4,
breed: 'doberman'
}
}
}
test('Updates pet and returns it', async () => {
request(graphQLEndpoint)
.post('?')
.send(postData)
.expect(200)
.end((error, response) => {
if (error) console.error(error)
const res = JSON.parse(response.text)
expect(res.data.editPet).toEqual({
id: '1',
name: 'Rexo',
type: 'dogo',
age: 4,
breed: 'doberman'
})
})
})
})
describe('Add pet', () => {
const postData = {
query: `mutation AddPet($petToAdd: PetToAdd!) {
addPet(petToAdd: $petToAdd) {
id
name
type
age
breed
}
}`,
variables: {
petToAdd: {
name: 'Salame',
type: 'cat',
age: 6,
breed: 'pinky'
}
}
}
test('Adds new pet and returns the added item', async () => {
request(graphQLEndpoint)
.post('?')
.send(postData)
.expect(200)
.end((error, response) => {
if (error) console.error(error)
const res = JSON.parse(response.text)
expect(res.data.addPet).toEqual({
id: '4',
name: 'Salame',
type: 'cat',
age: 6,
breed: 'pinky'
})
})
})
})
describe('Delete pet', () => {
const postData = {
query: `mutation DeletePet {
deletePet(id: 2) {
id,
name,
type,
age,
breed
}
}`
}
test('Deletes given pet and returns updated list', async () => {
request(graphQLEndpoint)
.post('?')
.send(postData)
.expect(200)
.end((error, response) => {
if (error) console.error(error)
const res = JSON.parse(response.text)
expect(res.data.deletePet).toEqual([
{
id: '1',
name: 'Rexo',
type: 'dogo',
age: 4,
breed: 'doberman'
},
{
id: '3',
name: 'Mittens',
type: 'cat',
age: 2,
breed: 'tabby'
},
{
id: '4',
name: 'Salame',
type: 'cat',
age: 6,
breed: 'pinky'
}
])
})
})
})这是我们的 GraphQL API 的测试套件。它使用该库向 API 端点 () 发出 HTTP 请求,并验证 API 是否正确响应各种查询和更改。supertest http://localhost:4000/
该代码有五个不同的测试用例:
Get all pets:此测试查询所有宠物的 API,并验证响应是否与预期的宠物列表匹配。Get pet detail:此测试查询 API 以获取特定宠物的详细信息,并验证响应是否与该宠物的预期详细信息匹配。Edit pet:此测试执行更改以编辑特定宠物的详细信息,并验证响应是否与该宠物的预期编辑详细信息匹配。Add pet:此测试执行更改以添加新宠物,并验证响应是否与新添加的宠物的预期详细信息匹配。Delete pet:此测试执行更改以删除特定宠物,并验证响应是否与删除后的预期宠物列表匹配。
每个测试用例都包含一个对象,该对象包含要发送到 API 终端节点的 GraphQL 查询或更改以及任何必要的变量。postData
实际的 HTTP 请求是使用库中的函数发出的,该函数将 POST 请求发送到 API 终端节点,并在请求正文中包含对象。然后,响应被解析为 JSON,测试用例使用 Jest 测试框架中的函数验证响应是否与预期结果匹配。request supertest postData expect
现在转到您的终端,运行 ,您应该会看到所有测试都通过了:npm test
> jest
PASS pets/pets.test.js
Get all pets
✓ returns all pets (15 ms)
Get pet detail
✓ Return pet detail information (2 ms)
Edit pet
✓ Updates pet and returns it (1 ms)
Add pet
✓ Adds new pet and returns the added item (1 ms)
Delete pet
✓ Deletes given pet and returns updated list (1 ms)
Test Suites: 1 passed, 1 total
Tests: 5 passed, 5 total
Snapshots: 0 total
Time: 0.607 s, estimated 1 s
Ran all test suites.如何在前端 React 应用程序上使用 GraphQL API
现在我们知道我们的服务器正在运行并按预期运行。让我们看一些更实际的示例,了解前端应用程序如何使用我们的 API。
在这个例子中,我们将使用 React 应用程序和 Apollo 客户端来发送和处理我们的请求。
我们的工具
React 是一个流行的 JavaScript 库,用于构建用户界面。它允许开发人员创建可重用的 UI 组件,并有效地更新和呈现它们以响应应用程序状态的变化。
关于 Apollo 客户端,我们已经介绍了它。
旁注 – 我们在这里选择使用 Apollo 客户端,是因为它是一个非常流行的工具,而且让前端和后端使用相同的库集是很有意义的。如果你对从前端 React 应用程序使用 GraphQL API 的其他可能方式感兴趣,Reed Barger 有一篇关于这个主题的非常酷的文章。
代码
让我们通过运行并按照终端提示来创建我们的 React 应用程序。完成后,运行 (我们将使用它来在我们的应用程序中设置基本路由)。yarn create viteyarn add react-router-dom
App.jsx
将此代码放入您的文件中:App.jsx
import { Suspense, lazy, useState } from 'react'
import { BrowserRouter as Router, Routes, Route } from 'react-router-dom'
import './App.css'
const PetList = lazy(() => import('./pages/PetList'))
const PetDetail = lazy(() => import('./pages/PetDetail'))
const EditPet = lazy(() => import('./pages/EditPet'))
const AddPet = lazy(() => import('./pages/AddPet'))
function App() {
const [petToEdit, setPetToEdit] = useState(null)
return (
<div className='App'>
<Router>
<h1>Pet shelter</h1>
<Routes>
<Route
path='/'
element={
<Suspense fallback={<></>}>
<PetList />
</Suspense>
}
/>
<Route
path='/:petId'
element={
<Suspense fallback={<></>}>
<PetDetail setPetToEdit={setPetToEdit} />
</Suspense>
}
/>
<Route
path='/:petId/edit'
element={
<Suspense fallback={<></>}>
<EditPet petToEdit={petToEdit} />
</Suspense>
}
/>
<Route
path='/add'
element={
<Suspense fallback={<></>}>
<AddPet />
</Suspense>
}
/>
</Routes>
</Router>
</div>
)
}
export default App在这里,我们只定义我们的路由。我们的应用程序中将有 4 个主要路由,每个路由对应不同的视图:
- 一个用于查看整个宠物列表。
- 一个用于查看单个宠物的详细信息。
- 一个用于编辑单个宠物。
- 一个用于将新宠物添加到列表中。
此外,我们还有一个用于添加新宠物的按钮和一个 state,该 state 将存储我们要编辑的宠物的信息。
接下来,创建一个包含这些文件的目录:pages
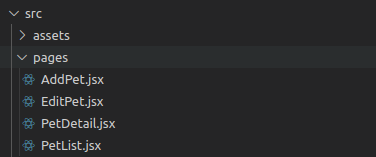
文件夹结构
main.js
在跳转到我们的页面之前,我们必须设置 Apollo 客户端库。运行 并安装必要的依赖项。yarn add @apollo/clientyarn add graphql
转到文件并将以下代码放入其中:main.js
import React from 'react'
import ReactDOM from 'react-dom/client'
import App from './App'
import './index.css'
import { ApolloClient, InMemoryCache, ApolloProvider } from '@apollo/client'
const client = new ApolloClient({
uri: 'http://localhost:4000/',
cache: new InMemoryCache(),
})
ReactDOM.createRoot(document.getElementById('root')).render(
<ApolloProvider client={client}>
<App />
</ApolloProvider>
)在这里,我们初始化 ,向其构造函数传递一个带有 and 字段的配置对象:ApolloClienturicache
uri指定 GraphQL 服务器的 URL。cache是 的一个实例,Apollo Client 在获取查询结果后使用它来缓存查询结果。InMemoryCache
然后我们用 ApolloProvider 包装我们的组件。这允许我们组件树中的任何组件使用 Apollo 客户端提供的钩子,就像 React Context 一样。;)App
更改和查询
在项目的根目录中,创建以下文件夹结构:

文件夹结构
在这两个文件中,我们将声明将用于查询和更改的请求正文。我喜欢将其分成不同的文件,因为它可以清楚地看到我们在应用程序中拥有的不同类型请求,并且它还使我们组件的代码更简洁。
在文件中拖放以下内容:queries.js
import { gql } from '@apollo/client'
export const GET_PETS = gql`
query Pets {
pets {
id
name
type
breed
}
}
`
export const GET_PET = gql`
query Pet($petId: ID!) {
pet(id: $petId) {
id
name
type
age
breed
}
}
`在文件中拖放以下内容:mutations.js
import { gql } from '@apollo/client'
export const DELETE_PET = gql`
mutation DeletePet($deletePetId: ID!) {
deletePet(id: $deletePetId) {
id
}
}
`
export const ADD_PET = gql`
mutation AddPet($petToAdd: PetToAdd!) {
addPet(petToAdd: $petToAdd) {
id
name
type
age
breed
}
}
`
export const EDIT_PET = gql`
mutation EditPet($petToEdit: PetToEdit!) {
editPet(petToEdit: $petToEdit) {
id
name
type
age
breed
}
}
`如您所见,查询和更改的语法非常相似。请求正文以 GraphQL 查询语言编写,用于定义可从 GraphQL API 请求的数据的结构和数据类型。
- GraphQL 查询语法:
export const GET_PETS = gql`
query Pets {
pets {
id
name
type
breed
}
}
`此查询已命名,它从字段请求数据。字段 、 、 和 是从 API 返回的每个对象中请求的。Pets pets id name type breed Pet
在 GraphQL 中,查询始终以关键字开头,后跟查询名称(如果提供)。请求的字段括在大括号中,可以嵌套以请求相关字段中的数据。query
- GraphQL 突变语法:
export const ADD_PET = gql`
mutation AddPet($petToAdd: PetToAdd!) {
addPet(petToAdd: $petToAdd) {
id
name
type
age
breed
}
}
`此更改已命名,并发送一个新对象,以通过更改添加到 API。该变量定义为 类型的必需输入 。执行 mutation 时,input 变量将作为参数传递给 mutation。然后,更改返回新创建的对象的 、 和 字段。AddPet Pet addPet $petToAdd PetToAdd addPet id name type age breed Pet
在 GraphQL 中,更改始终以关键字开头,后跟更改的名称(如果提供)。更改响应中请求的字段也用大括号括起来。mutation
请注意,GraphQL 中的查询和更改都可以接受变量作为输入,这些变量使用特殊语法 () 在查询或更改正文中定义。这些变量可以在执行查询或更改时传入,从而允许更多动态和可重用的查询和更改。$variableName: variableType!
PetList.jsx
让我们从负责渲染整个 pets 列表的文件开始:
import { Link } from 'react-router-dom'
import { useQuery } from '@apollo/client'
import { GET_PETS } from '../api/queries'
function PetList() {
const { loading, error, data } = useQuery(GET_PETS)
return (
<>
<h2>Pet List</h2>
<Link to='/add'>
<button>Add new pet</button>
</Link>
{loading && <p>Loading...</p>}
{error && <p>Error: {error.message}</p>}
{data?.pets?.map(pet => {
return (
<div key={pet?.id}>
<p>
{pet?.name} - {pet?.type} - {pet?.breed}
</p>
<Link to={/${pet?.id}}>
<button>Pet detail</button>
</Link>
</div>
)
})}
</>
)
}
export default PetList此代码定义了一个名为 React 函数组件,该组件使用库提供的钩子从 GraphQL API 获取宠物列表。用于获取宠物的查询在名为 的单独文件中定义,该文件导出名为 的 GraphQL 查询。PetList useQuery @apollo/client queries.js GET_PETS
钩子返回一个具有三个属性的对象:、 和 。这些属性从对象中解构出来,用于根据 API 请求的状态有条件地呈现不同的 UI 元素。useQuery loading error data
如果为 true,则屏幕上会显示一条加载消息。如果已定义,则会显示一条错误消息,其中包含 API 返回的特定错误消息。如果已定义并包含一个数组,则每个数组都显示在 div 中,其中包含其 、 和 。每个 pet div 还包含一个链接,用于查看有关宠物的更多详细信息。loading error data pets pet name type breed
钩子的工作原理是执行查询并将结果作为具有 、 和 属性的对象返回。当组件首次呈现时,在执行查询时为 true。如果查询成功,则为 false 并填充结果。如果查询遇到错误,则填充特定的错误消息。useQuery GET_PETS loading error data loading loading data error
如您所见,使用 Apollo 客户端管理请求真的很好而且很简单。它提供的钩子为我们节省了相当多的代码,通常用于执行请求、存储响应和处理错误。
请记住,要调用我们的服务器,我们必须通过在服务器项目终端中运行来启动并运行它。nodemon app.js
为了表明这里没有奇怪的魔术,如果我们转到浏览器,打开开发工具并转到网络选项卡,我们可以看到我们的应用程序正在向我们的服务器端点发出 POST 请求。payload 是我们的 String 形式的请求正文。
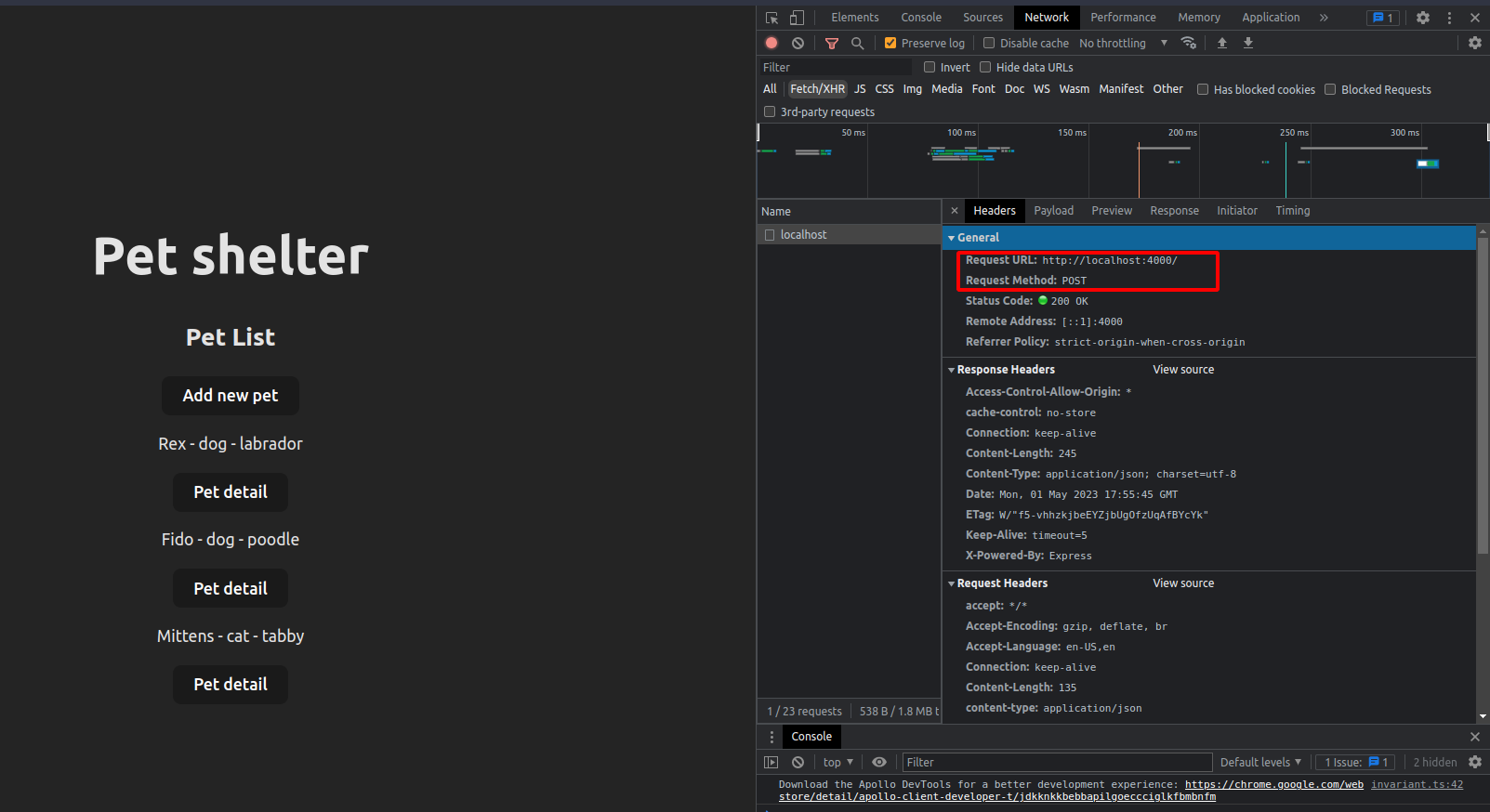
POST 请求

请求正文
这意味着,如果我们愿意,我们也可以通过使用 fetch 来使用我们的 GraphQL API,如下所示:
import { Link } from 'react-router-dom'
import { useEffect, useState } from 'react'
function PetList() {
const [pets, setPets] = useState([])
const getPets = () => {
fetch('http://localhost:4000/', {
method: 'POST',
headers: {
'Content-Type': 'application/json'
},
body: JSON.stringify({
query: `
query Pets {
pets {
id
name
type
breed
}
}
`
})
})
.then(response => response.json())
.then(data => setPets(data?.data?.pets))
.catch(error => console.error(error))
}
useEffect(() => {
getPets()
}, [])
return (
<>
<h2>Pet List</h2>
<Link to='/add'>
<button>Add new pet</button>
</Link>
{pets?.map(pet => {
return (
<div key={pet?.id}>
<p>
{pet?.name} - {pet?.type} - {pet?.breed}
</p>
<Link to={/${pet?.id}}>
<button>Pet detail</button>
</Link>
</div>
)
})}
</>
)
}
export default PetList如果您再次检查您的 network 选项卡,您应该仍然会看到相同的 POST 请求和 some 请求正文。
当然,这种方法不是很实用,因为它需要更多的代码行来执行相同的操作。但重要的是要明白,像 Apollo 这样的库主要是为我们提供了一个声明式的 API,以此来简化和优化我们的代码使用。然而,在这一切便利的背后,实际上我们仍然是在处理常规的 HTTP 请求。
PetDetail.jsx
现在让我们转到文件:PetDetail.jsx
import { useEffect } from 'react'
import { useParams, Link } from 'react-router-dom'
import { useQuery, useMutation } from '@apollo/client'
import { GET_PET } from '../api/queries'
import { DELETE_PET } from '../api/mutations'
function PetDetail({ setPetToEdit }) {
const { petId } = useParams()
const { loading, error, data } = useQuery(GET_PET, {
variables: { petId }
})
useEffect(() => {
if (data && data?.pet) setPetToEdit(data?.pet)
}, [data])
const [deletePet, { loading: deleteLoading, error: deleteError, data: deleteData }] = useMutation(DELETE_PET, {
variables: { deletePetId: petId }
})
useEffect(() => {
if (deleteData && deleteData?.deletePet) window.location.href = '/'
}, [deleteData])
return (
<div style={{ display: 'flex', flexDirection: 'column', justifyContent: 'center', aligniItems: 'center' }}>
<h2>Pet Detail</h2>
<Link to='/'>
<button>Back to list</button>
</Link>
{(loading || deleteLoading) && <p>Loading...</p>}
{error && <p>Error: {error.message}</p>}
{deleteError && <p>deleteError: {deleteError.message}</p>}
{data?.pet && (
<>
<p>Pet name: {data?.pet?.name}</p>
<p>Pet type: {data?.pet?.type}</p>
<p>Pet age: {data?.pet?.age}</p>
<p>Pet breed: {data?.pet?.breed}</p>
<div style={{ display: 'flex', justifyContent: 'center', aligniItems: 'center' }}>
<Link to={/${data?.pet?.id}/edit}>
<button style={{ marginRight: 10 }}>Edit pet</button>
</Link>
<button style={{ marginLeft: 10 }} onClick={() => deletePet()}>
Delete pet
</button>
</div>
</>
)}
</div>
)
}
export default PetDetail此组件通过执行查询来加载 pet 的详细信息,其方式与上一个组件非常相似。
此外,它还执行删除 pet register 所需的 mutation。你可以看到,为此我们使用了 hook。它与 非常相似,但除了值之外,它还提供了一个函数,用于在给定事件后执行我们的查询。useMutation useQuery loading, error and data
你可以看到,对于这个 mutation 钩子,我们传递了一个对象作为第二个参数,其中包含这个 mutation 需要的变量。在本例中,它是我们要删除的宠物登记册的 ID。
const [deletePet, { loading: deleteLoading, error: deleteError, data: deleteData }] = useMutation(DELETE_PET, {
variables: { deletePetId: petId }
})请记住,当我们声明我们的 mutation 时,我们已经声明了这个 mutation 将使用的变量。mutations.js
export const DELETE_PET = gql`
mutation DeletePet($deletePetId: ID!) {
deletePet(id: $deletePetId) {
id
}
}
`AddPet.jsx
这是负责将新宠物添加到我们的注册中的文件:
import React, { useState, useEffect } from 'react'
import { Link } from 'react-router-dom'
import { useMutation } from '@apollo/client'
import { ADD_PET } from '../api/mutations'
function AddPet() {
const [petName, setPetName] = useState()
const [petType, setPetType] = useState()
const [petAge, setPetAge] = useState()
const [petBreed, setPetBreed] = useState()
const [addPet, { loading, error, data }] = useMutation(ADD_PET, {
variables: {
petToAdd: {
name: petName,
type: petType,
age: parseInt(petAge),
breed: petBreed
}
}
})
useEffect(() => {
if (data && data?.addPet) window.location.href = /${data?.addPet?.id}
}, [data])
return (
<div style={{ display: 'flex', flexDirection: 'column', justifyContent: 'center', aligniItems: 'center' }}>
<h2>Add Pet</h2>
<Link to='/'>
<button>Back to list</button>
</Link>
{loading || error ? (
<>
{loading && <p>Loading...</p>}
{error && <p>Error: {error.message}</p>}
</>
) : (
<>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet name</label>
<input type='text' value={petName} onChange={e => setPetName(e.target.value)} />
</div>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet type</label>
<input type='text' value={petType} onChange={e => setPetType(e.target.value)} />
</div>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet age</label>
<input type='text' value={petAge} onChange={e => setPetAge(e.target.value)} />
</div>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet breed</label>
<input type='text' value={petBreed} onChange={e => setPetBreed(e.target.value)} />
</div>
<button
style={{ marginTop: 30 }}
disabled={!petName || !petType || !petAge || !petBreed}
onClick={() => addPet()}
>
Add pet
</button>
</>
)}
</div>
)
}
export default AddPet这里我们有一个组件,它加载一个表单来添加新的宠物,并在发送数据时执行更改。它接受新的 pet info 作为参数,就像 mutation 接受 pet id 一样。deletePet
编辑Pet.jsx
最后,负责编辑宠物登记册的文件:
import React, { useState, useEffect } from 'react'
import { Link } from 'react-router-dom'
import { useMutation } from '@apollo/client'
import { EDIT_PET } from '../api/mutations'
function EditPet({ petToEdit }) {
const [petName, setPetName] = useState(petToEdit?.name)
const [petType, setPetType] = useState(petToEdit?.type)
const [petAge, setPetAge] = useState(petToEdit?.age)
const [petBreed, setPetBreed] = useState(petToEdit?.breed)
const [editPet, { loading, error, data }] = useMutation(EDIT_PET, {
variables: {
petToEdit: {
id: parseInt(petToEdit.id),
name: petName,
type: petType,
age: parseInt(petAge),
breed: petBreed
}
}
})
useEffect(() => {
if (data && data?.editPet?.id) window.location.href = /${data?.editPet?.id}
}, [data])
return (
<div style={{ display: 'flex', flexDirection: 'column', justifyContent: 'center', aligniItems: 'center' }}>
<h2>Edit Pet</h2>
<Link to='/'>
<button>Back to list</button>
</Link>
{loading || error ? (
<>
{loading && <p>Loading...</p>}
{error && <p>Error: {error.message}</p>}
</>
) : (
<>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet name</label>
<input type='text' value={petName} onChange={e => setPetName(e.target.value)} />
</div>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet type</label>
<input type='text' value={petType} onChange={e => setPetType(e.target.value)} />
</div>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet age</label>
<input type='text' value={petAge} onChange={e => setPetAge(e.target.value)} />
</div>
<div style={{ display: 'flex', flexDirection: 'column', margin: 20 }}>
<label>Pet breed</label>
<input type='text' value={petBreed} onChange={e => setPetBreed(e.target.value)} />
</div>
<button
style={{ marginTop: 30 }}
disabled={!petName || !petType || !petAge || !petBreed}
onClick={() => editPet()}
>
Save changes
</button>
</>
)}
</div>
)
}
export default EditPet最后,我们有一个组件,用于通过表单编辑宠物登记册。它在发送数据时执行 mutation,并作为参数接受新的 pet 信息。
就是这样!我们在前端应用程序中使用了所有的 API 查询和更改。
如何使用 Apollo Sandbox 记录 GraphQL API
Apollo 最酷的功能之一是它带有一个内置沙箱,您可以使用它来测试和记录您的 API。
Apollo Sandbox 是一个基于 Web 的 GraphQL IDE,它提供了一个用于测试 GraphQL 查询、更改和订阅的沙盒环境。它是 Apollo 提供的免费在线工具,允许您与 GraphQL API 交互并探索其架构、数据和功能。
以下是 Apollo Sandbox 的一些主要功能:
- 查询编辑器:功能丰富的 GraphQL 查询编辑器,提供语法突出显示、自动完成、验证和错误突出显示。
- Schema Explorer:一个图形界面,允许您浏览 GraphQL 架构并查看其类型、字段和关系。
- 模拟:Apollo Sandbox 允许您根据架构轻松生成模拟数据,这对于测试查询和更改非常有用,而无需连接到真实数据源。
- 协作:您可以与他人共享您的沙盒、协作处理查询并查看实时更改。
- 文档:您可以将文档添加到您的架构和查询结果中,以帮助其他人了解您的 API。
要使用我们的沙盒,只需在 http://localhost:4000/ 打开浏览器即可。您应该看到如下内容:
阿波罗沙箱
在这里,您可以查看 API 数据架构和可用的更改和查询,还可以执行它们并查看 API 的响应方式。例如,通过执行查询,我们可以在右侧面板上看到该响应。pets
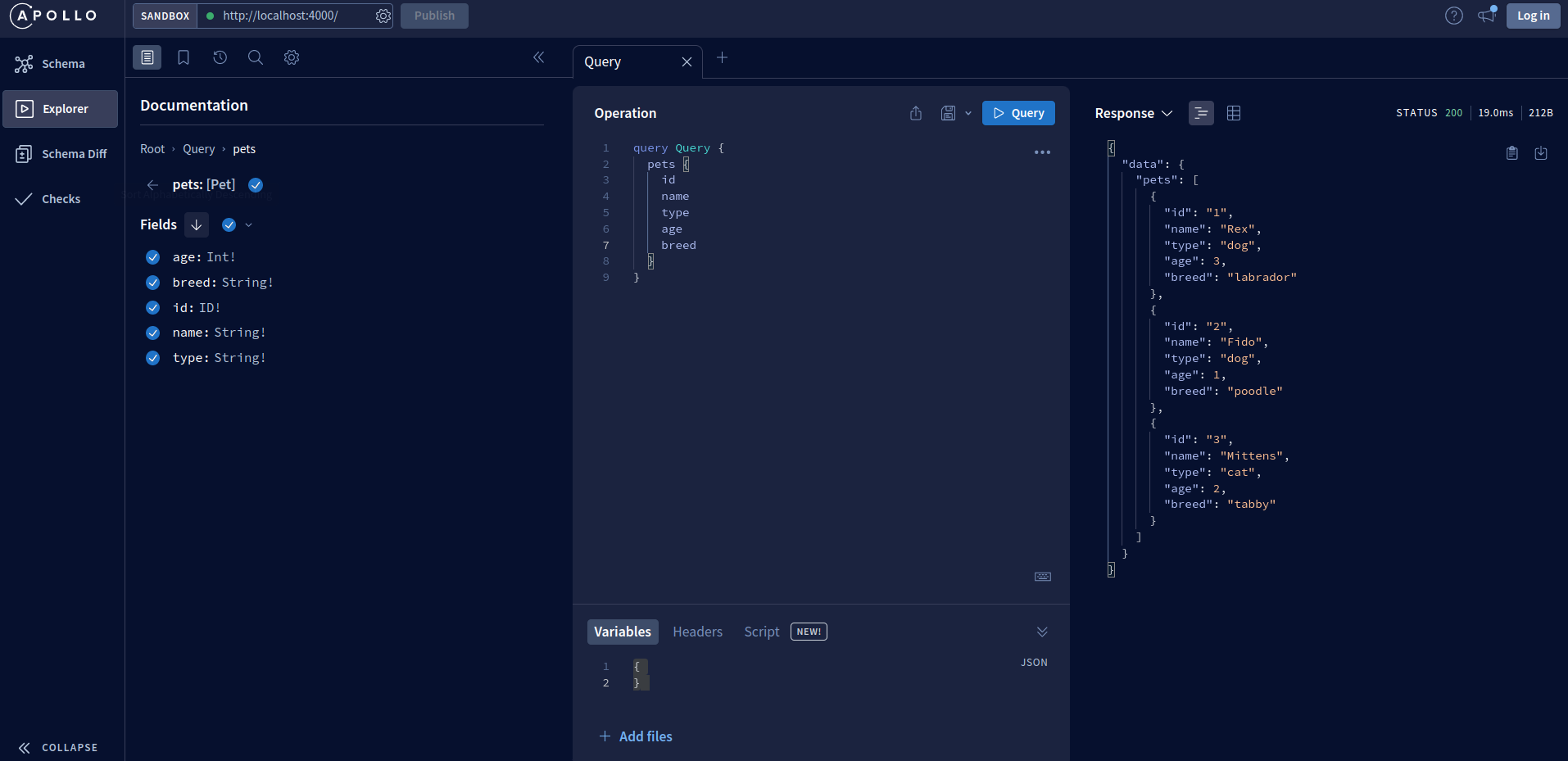
执行查询
如果您跳到 schema 部分,您可以在我们的 API 中看到可用查询、更改对象和输入类型的完整详细信息。
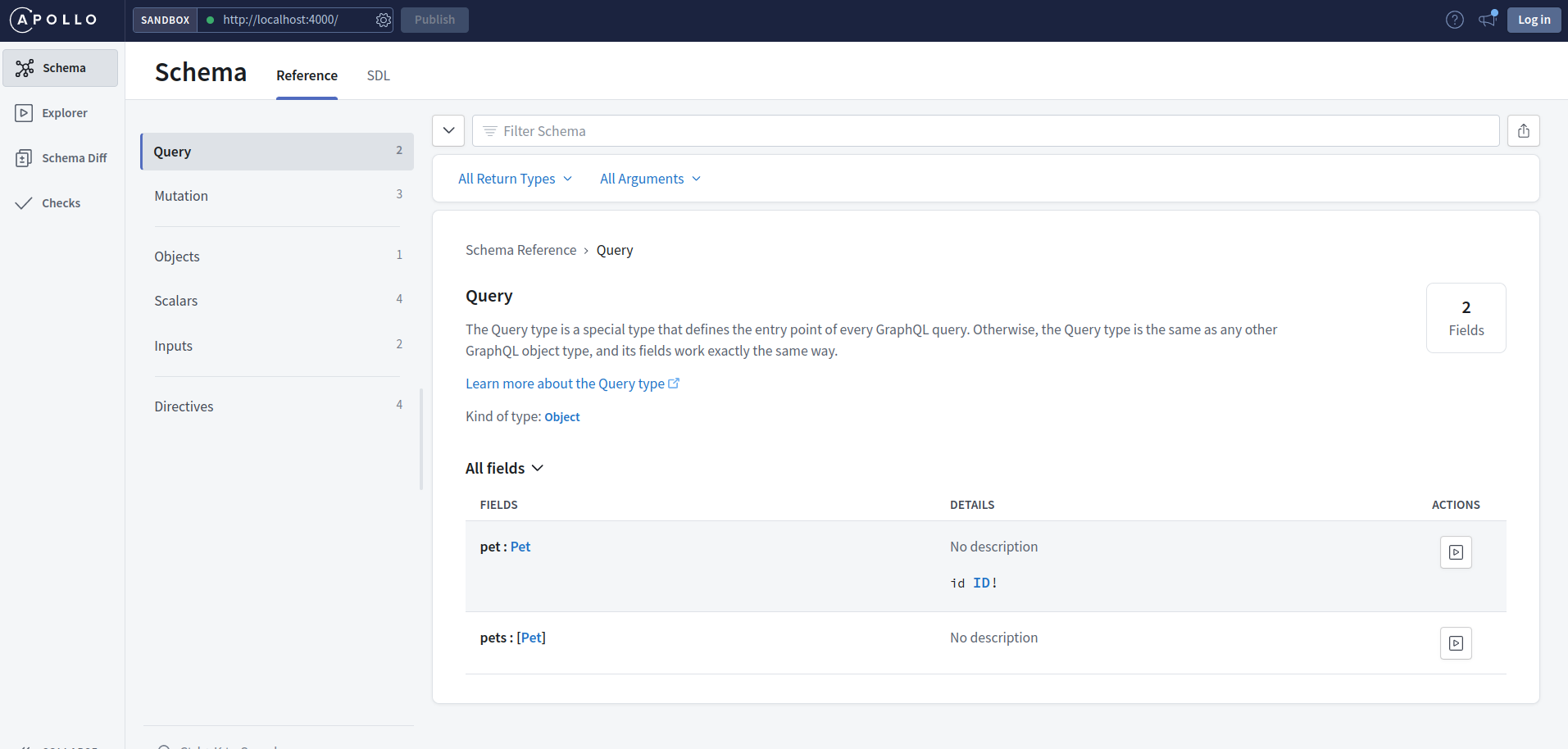
schema 部分
Apollo sandbox 是一个很棒的工具,既可以用作我们 API 的自我文档,也可以用作出色的开发和测试工具。
结束语
好吧,大家一如既往,我希望你喜欢这篇文章并学到一些新东西。
如果你愿意,你也可以在 LinkedIn 或 Twitter 上关注我。下期见!
原文链接:https://www.freecodecamp.org/news/building-consuming-and-documenting-a-graphql-api/