AI聊天机器人手册:如何使用Redis、Python和GPT构建AI聊天机器人
在构建一个有效的全栈应用程序时,需要关注众多活动部件,并且需要做出许多对应用程序成功至关重要的决策。
例如,您将使用什么语言,您将在哪个平台上部署?您打算在服务器上部署容器化软件,还是使用无服务器功能来处理后端?您是否计划使用第三方 API 来处理应用程序的复杂部分,例如身份验证或付款?您在哪里存储数据?
除此之外,您还需要考虑用户界面、应用程序的设计和可用性等等。
这就是为什么构建复杂的大型应用程序需要依靠一个具备多功能的开发团队协作的原因。
学习如何开发全栈应用程序的最佳方法之一是构建涵盖端到端开发过程的项目。您将完成架构设计、API 服务开发、用户界面开发,最后部署您的应用程序。
因此,本教程将带您完成构建 AI 聊天机器人的过程,以帮助您深入了解这些概念。
我们将涵盖的一些主题包括:
- 如何使用 Python、FastAPI 和 WebSockets 构建 API
- 如何使用 Redis 构建实时系统
- 如何使用 React 构建聊天用户界面
重要提示:这是一个中间的全栈软件开发项目,需要一些基本的 Python 和 JavaScript 知识。
我已将项目仔细划分为多个部分,以确保您在不想编写完整应用程序时可以轻松选择对您重要的阶段。
您可以在 My Github 上下载完整的存储库 。
应用程序架构
草拟解决方案体系结构可以为您提供应用程序、您打算使用的工具以及组件如何相互通信的高级概述。
我使用 draw.io 在下面绘制了一个简单的架构:
 全栈式聊天机器人架构
全栈式聊天机器人架构
让我们更详细地了解一下架构的各个部分:
客户端/用户界面
我们将使用 React 版本 18 来构建用户界面。聊天 UI 将通过 WebSockets 与后端通信。
GPT-J-6B 和 Huggingface 推理 API
GPT-J-6B 是一种生成语言模型,它使用 60 亿个参数进行了训练,并在某些任务上与 OpenAI 的 GPT-3 密切合作。
我选择使用GPT-J-6B,因为它是开源模型,对于简单的用例来说,无需付费token。
Huggingface 还为我们提供了一个按需 API,几乎可以免费地连接这个模型。您可以阅读有关 GPT-J-6B 和 Hugging Face Inference API 的更多信息。
Redis
当我们向 GPT 发送提示时,我们需要一种方法来存储提示并轻松检索响应。我们将使用 Redis JSON 来存储聊天数据,并使用 Redis Streams 来处理与 huggingface 推理 API 的实时通信。
Redis 是一种基于内存的键值存储系统,它能够以极高的速度获取和存储类似于 JSON 格式的数据。在本教程中,我们将使用 Redis Enterprise 提供的托管免费 Redis 存储进行测试。
Web Sockets 和 Chat API
要在客户端和服务器之间实时发送消息,我们需要打开一个套接字连接。这是因为 HTTP 连接不足以确保客户端和服务器之间的实时双向通信。
我们将使用 FastAPI 作为聊天服务器,因为它提供了一个快速且现代的 Python 服务器供我们使用。
如何设置开发环境
您可以使用自己偏好的操作系统来构建这个应用程序——我当前是在MacOS环境下,使用Visual Studio Code进行开发。只需确保您的系统中已经安装了Python和Node.js。
要建立项目结构,请创建一个名为“全栈AI聊天机器人”的文件夹。然后在项目中创建两个子文件夹,分别名为“客户端”和“服务器”。服务器将包含后端代码,而客户端将包含前端代码。
接下来,在项目目录中,使用“git init”命令在项目文件夹的根目录中初始化一个 Git 存储库。然后使用 “touch .gitignore” 创建一个 .gitignore 文件:
git init
touch .gitignore在下一节中,我们将使用 FastAPI 和 Python 构建我们的聊天 Web 服务器。
如何使用 Python、FastAPI 和 WebSockets 构建聊天服务器
在本节中,我们将使用 FastAPI 构建聊天服务器来与用户通信。我们将使用 WebSockets 来确保客户端和服务器之间的双向通信,以便我们可以实时向用户发送响应。
如何设置 Python 环境
要启动我们的服务器,我们需要设置我们的 Python 环境。在 VS Code 中打开项目文件夹,然后打开终端。
从项目根目录进入服务器目录,并运行以下命令:
python3.8 -m venv env这将为我们的Python项目创建一个名为“env”的虚拟环境。要激活虚拟环境,请运行以下命令:
source env/bin/activate接下来,在 Python 环境中安装几个库。
pip install fastapi uuid uvicorn gunicorn WebSockets python-dotenv aioredis接下来,在终端中运行“touch .env”命令来创建一个环境文件。我们将在.env文件中定义应用程序变量和秘密变量。
添加应用程序环境变量,并将其设置为“development”,如下所示:export APP_ENV=development。接下来,我们将使用FastAPI服务器设置一个开发服务器。
FastAPI 服务器设置
在服务器目录的根目录中,创建一个名为 然后粘贴以下开发服务器代码的新文件:main.py
from fastapi import FastAPI, Requestimport uvicornimport os
from dotenv import load_dotenv
load_dotenv()
api = FastAPI()
@api.get("/test")
async def root():
return {"msg": "API is Online"}
if __name__ == "__main__":
if os.environ.get('APP_ENV') == "development":
uvicorn.run("main:api", host="0.0.0.0", port=3500,
workers=4, reload=True) else:
pass首先,我们导入FastAPI并将其初始化为api。然后我们从python-dotenv库中导入load_dotenv,并初始化它以加载.env文件中的变量,
然后,我们创建一个简单的测试路由来测试 API。测试路由将返回一个简单的 JSON 响应,告诉我们 API 已联机。
最后,我们通过使用uvicorn.run并提供所需的参数来设置开发服务器。API将在端口3500上运行。
最后,在终端中使用python main.py运行服务器。一旦你在终端上看到应用程序启动完成,在浏览器上导航到URL http://localhost:3500/test,你应该会得到一个这样的网页:
如何将路由添加到 API
在本节中,我们将为API添加路由。首先,创建一个名为“src”的新文件夹,这个文件夹将作为我们存放所有API代码的主要目录。
创建一个名为routes的子文件夹,cd到该文件夹中,创建一个名为chat.py的新文件,然后添加以下代码:
import os
from fastapi import APIRouter, FastAPI, WebSocket, Request
chat = APIRouter()
# @route POST /token
# @desc Route to generate chat token
# @access Public
@chat.post("/token")
async def token_generator(request: Request):
return None
# @route POST /refresh_token
# @desc Route to refresh token
# @access Public
@chat.post("/refresh_token")
async def refresh_token(request: Request):
return None
# @route Websocket /chat
# @desc Socket for chatbot
# @access Public
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket = WebSocket):
return None我们创建了三个终端节点:
/token将向用户颁发用于访问聊天会话的会话令牌。由于聊天应用程序将公开开放,我们不想担心身份验证,只需保持简单 – 但我们仍然需要一种方法来识别每个唯一的用户会话。/refresh_token如果连接丢失,将获取用户的会话历史记录,只要令牌仍处于活动状态且未过期。/chat将打开一个 WebSocket 来在客户端和服务器之间发送消息。
接下来,将聊天路由连接到我们的主API。首先,我们需要从src导入chat。在main.py文件中聊天。然后,我们将通过在初始化的FastAPI类上调用include_router方法并传递chat作为参数来包含路由器。
更新您的代码,如下所示:
from fastapi import FastAPI, Request
import uvicorn
import os
from dotenv import load_dotenv
from routes.chat import chat
load_dotenv()
api = FastAPI()
api.include_router(chat)
@api.get("/test")
async def root():
return {"msg": "API is Online"}
if __name__ == "__main__":
if os.environ.get('APP_ENV') == "development":
uvicorn.run("main:api", host="0.0.0.0", port=3500,
workers=4, reload=True)
else:
pass如何使用 UUID 生成聊天会话令牌
我们将使用uuid4生成用户令牌,并利用这个令牌为聊天终端节点创建动态路由。鉴于该终端节点是公开可访问的,因此关于JWT和身份验证的详细内容,我们在此就不做深入探讨了。
如果最初uuid未安装,请pip install uuid .接下来,在 chat.py 中,导入 UUID,并使用以下/token代码更新路由:
from fastapi import APIRouter, FastAPI, WebSocket, Request, BackgroundTasks, HTTPExceptionimport uuid
# @route POST /token
# @desc Route generating chat token
# @access Public
@chat.post("/token")
async def token_generator(name: str, request: Request):
if name == "":
raise HTTPException(status_code=400, detail={
"loc": "name", "msg": "Enter a valid name"})
token = str(uuid.uuid4())
data = {"name": name, "token": token}
return data在上面的代码中,客户端提供了他们的名称,这是必需的。我们快速检查以确保 name 字段不为空,然后使用 uuid4 生成一个 token。
会话数据是 name 和 token 的简单字典。最终,我们需要持久保存此会话数据并设置超时,但现在我们只需将其返回给客户端即可。
如何使用 Postman 测试 API
因为我们将测试 WebSocket 端点,所以我们需要使用像 Postman 这样的工具来允许这样做(因为 FastAPI 上的默认 swagger 文档不支持 WebSockets)。
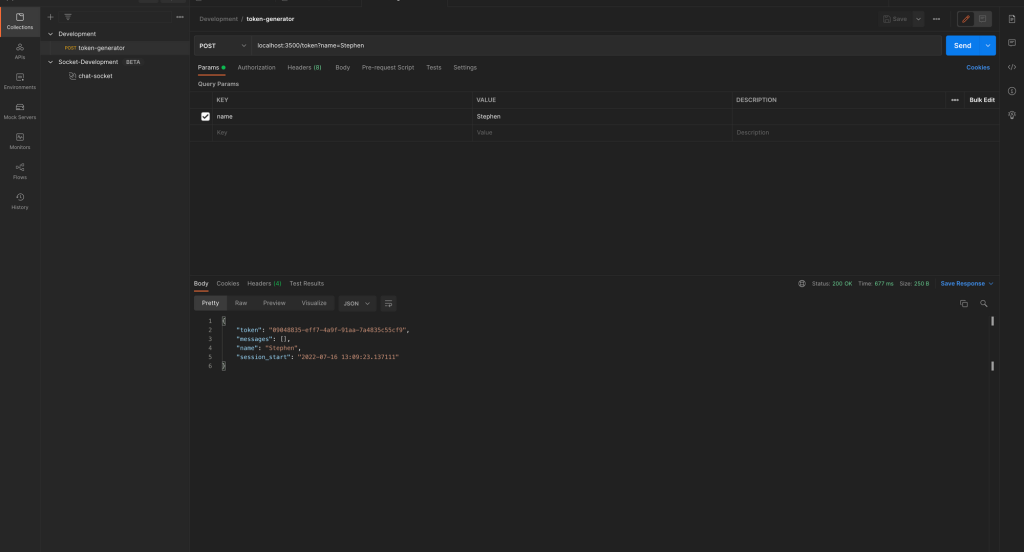
在Postman中,为您的开发环境创建一个集合,并向localhost:3500/token发送一个POST请求,指定名称作为查询参数并传递一个值。您应该得到如下所示的响应:
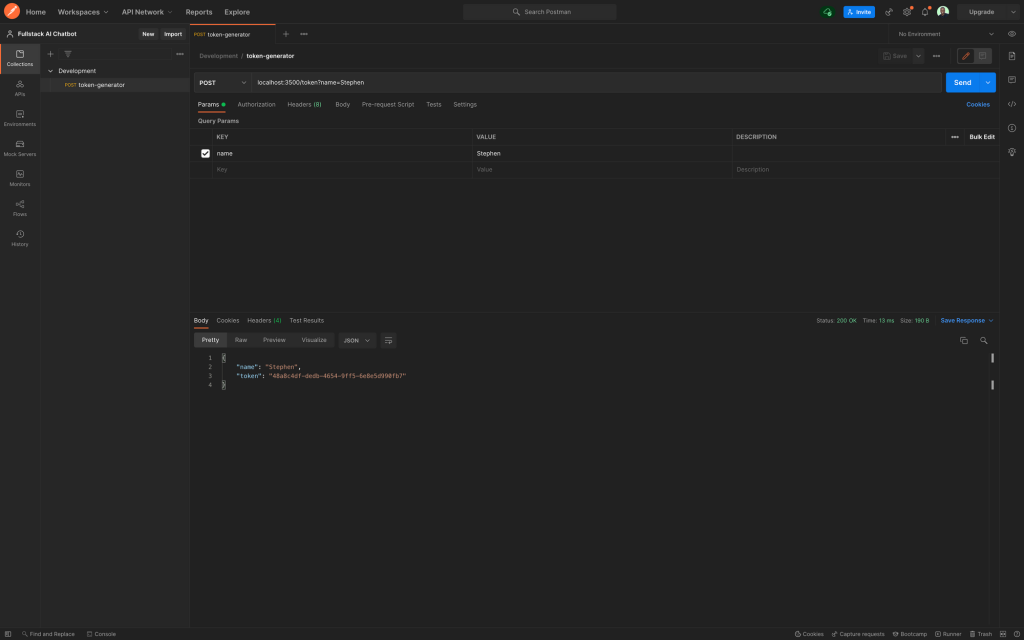
令牌生成器邮差
Websockets 和连接管理器
在src根目录下,创建一个名为socket的新文件夹,并添加一个名为connection.py的文件。在这个文件中,我们将定义控制到WebSockets的连接的类,以及所有连接和断开连接的助手方法。
在connection.py添加以下代码:
from fastapi import WebSocket
class ConnectionManager:
def __init__(self):
self.active_connections: List[WebSocket] = []
async def connect(self, websocket: WebSocket):
await websocket.accept()
self.active_connections.append(websocket)
def disconnect(self, websocket: WebSocket):
self.active_connections.remove(websocket)
async def send_personal_message(self, message: str, websocket: WebSocket):
await websocket.send_text(message)ConnectionManager类是用active_connections属性初始化的,该属性是一个活动连接列表。
然后,异步连接方法将接受WebSocket并将其添加到活动连接列表中,而disconnect方法将从活动连接列表中删除WebSocket。
最后,send_personal_message方法将接收消息和我们想要发送消息的Websocket,并异步发送消息。
WebSockets是一个相当广泛的主题,我们这里所讨论的只是冰山一角。但即便如此,所学的内容应该已经足够您创建多个连接,并能够异步地处理发送到这些连接的消息了。
你可以阅读更多关于 FastAPI Websockets 和 Sockets 编程 的内容。
要使用ConnectionManager,请在src.routes.chat.py中导入并初始化它,并用下面的代码更新/chat WebSocket路由:
from ..socket.connection import ConnectionManager
manager = ConnectionManager()
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket):
await manager.connect(websocket)
try:
while True:
data = await websocket.receive_text()
print(data)
await manager.send_personal_message(f"Response: Simulating response from the GPT service", websocket)
except WebSocketDisconnect:
manager.disconnect(websocket)在websocket_endpoint函数(它接受一个WebSocket)中,我们将新的WebSocket添加到连接管理器并运行一个while True循环,以确保套接字保持打开状态。除非套接字断开连接。
当连接打开时,我们使用websocket.receive_test()接收客户端发送的任何消息,并将它们打印到终端。
然后,我们现在将硬编码的响应发送回客户端。最终,从客户端收到的消息将发送到 AI 模型,而返回给客户端的响应则将是AI模型生成的回复。
在Postman中,我们可以通过创建一个新的WebSocket请求来测试这个端点,并连接到WebSocket端点localhost:3500/chat。
当您单击 connect 时,Messages 窗格将显示 API 客户端已连接到 URL,并且套接字已打开。
要对此进行测试,请向聊天服务器发送消息 “Hello Bot”,您应该会立即收到测试响应 “Response: Simulating response from the GPT service” ,如下所示:
FastAPI 中的依赖注入
为了能够区分两个不同的客户端会话并限制聊天会话,我们将使用定时令牌,作为查询参数传递给 WebSocket 连接。
在 socket 文件夹中,创建一个名为utils.py然后添加以下代码的文件:
from fastapi import WebSocket, status, Query
from typing import Optional
async def get_token(
websocket: WebSocket,
token: Optional[str] = Query(None),
):
if token is None or token == "":
await websocket.close(code=status.WS_1008_POLICY_VIOLATION)
return tokenget_token 函数接收 WebSocket 和令牌,然后检查令牌是 None 还是 null。
如果满足这种情况的话,该函数会返回策略冲突的状态,如果可用,该函数将仅返回令牌。我们稍后将通过额外的令牌验证来扩展此功能。
为了使用这个函数,我们将它注入到/chat路由中。FastAPI提供了一个Depends类来轻松地注入依赖项,因此我们不必修改装饰器。
将/chat路由更新为以下内容:
from ..socket.utils import get_token
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket, token: str = Depends(get_token)):
await manager.connect(websocket)
try:
while True:
data = await websocket.receive_text()
print(data)
await manager.send_personal_message(f"Response: Simulating response from the GPT service", websocket)
except WebSocketDisconnect:
manager.disconnect(websocket)现在,当您尝试在 Postman 中连接到/chat终端节点时,您将收到 403 错误。目前,提供令牌作为查询参数,并为令牌提供任何值。然后您应该能够像以前一样进行连接,只是现在连接需要一个令牌。
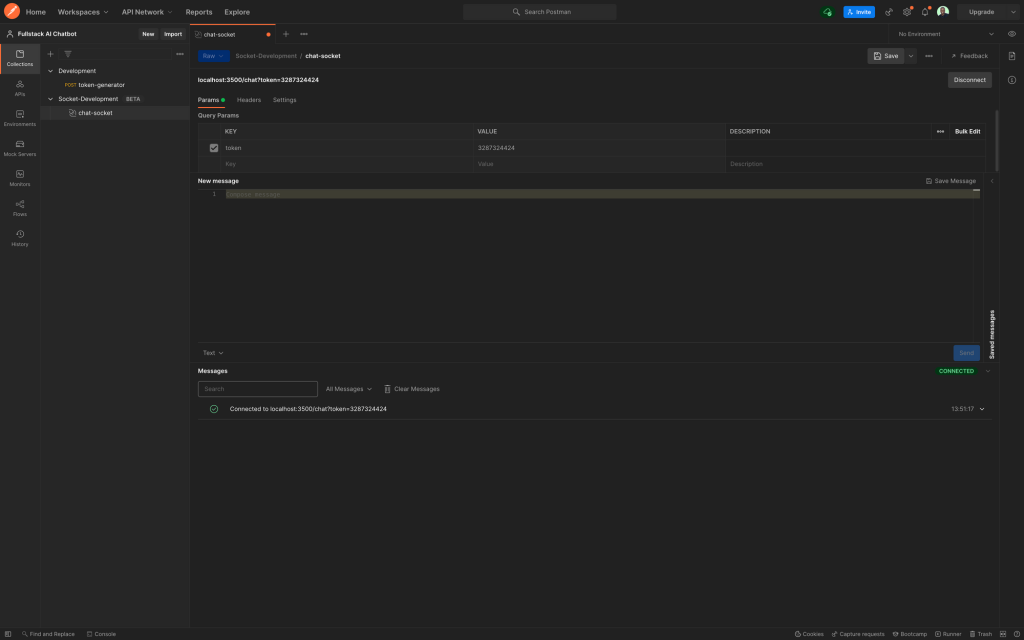
邮差聊天测试与令牌
恭喜你走到了这一步!您的chat.py文件现在应如下所示:
import os
from fastapi import APIRouter, FastAPI, WebSocket, WebSocketDisconnect, Request, Depends, HTTPException
import uuid
from ..socket.connection import ConnectionManager
from ..socket.utils import get_token
chat = APIRouter()
manager = ConnectionManager()
# @route POST /token
# @desc Route to generate chat token
# @access Public
@chat.post("/token")
async def token_generator(name: str, request: Request):
token = str(uuid.uuid4())
if name == "":
raise HTTPException(status_code=400, detail={
"loc": "name", "msg": "Enter a valid name"})
data = {"name": name, "token": token}
return data
# @route POST /refresh_token
# @desc Route to refresh token
# @access Public
@chat.post("/refresh_token")
async def refresh_token(request: Request):
return None
# @route Websocket /chat
# @desc Socket for chatbot
# @access Public
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket, token: str = Depends(get_token)):
await manager.connect(websocket)
try:
while True:
data = await websocket.receive_text()
print(data)
await manager.send_personal_message(f"Response: Simulating response from the GPT service", websocket)
except WebSocketDisconnect:
manager.disconnect(websocket)在本教程的下一部分,我们将重点介绍如何处理应用程序的状态以及在客户端和服务器之间传递数据。
如何使用 Redis 构建实时系统
我们的应用程序目前不存储任何状态,并且无法识别用户或存储和检索聊天数据。我们还会在聊天会话期间向客户端返回硬编码响应。
在本教程的这一部分中,我们将介绍以下内容:
- 如何在 Python 中连接到 Redis 集群并设置 Redis 客户端
- 如何使用 Redis JSON 存储和检索数据
- 如何将 Redis Streams 设置为 Web 服务器和工作线程环境之间的消息队列
Redis 和分布式消息收发队列
Redis 是一种开源内存数据存储,您可以将其用作数据库、缓存、消息代理和流式处理引擎。它支持多种数据结构,是具有实时功能的分布式应用程序的完美解决方案。
Redis Enterprise Cloud 是 Redis 提供的一项完全托管的云服务,可帮助我们无限大规模部署 Redis 集群,而无需担心基础设施。
在本教程中,我们将使用免费的 Redis Enterprise Cloud 实例。您可以在此处免费开始使用 Redis Cloud,并按照本教程设置 Redis 数据库和 Redis Insight,这是一个与 Redis 交互的 GUI。
一旦你的Redis数据库配置完成,请在项目的根目录下(注意,这个位置是在服务器文件夹的外部)新建一个名为“worker”的文件夹。
我们将我们的 worker 环境与 Web 服务器隔离开来,这样当客户端向我们的 WebSocket 发送消息时,Web 服务器就不必处理对第三方服务的请求。此外,还可以为其他用户释放资源。
这个工作程序服务通过Redis来处理与推理API的后端通信。
来自所有已连接客户端的请求将附加到消息队列(生产者),而 Worker 则使用消息,将请求发送到推理 API,并将响应附加到响应队列。
API 收到响应后,会将其发送回客户端。
在生产者和消费者之间的传输过程中,客户端可以发送多条消息,这些消息将排队并按顺序响应。
理想情况下,我们可以让这个 worker 在完全不同的服务器上运行,在它自己的环境中,但现在,我们将在本地机器上创建自己的 Python 环境。
您可能想知道 – 为什么我们需要worker?想象一下这样一个场景:Web 服务器还创建对第三方服务的请求。这意味着,在套接字连接期间等待第三方服务的响应时,服务器将被阻止,资源被占用,直到从 API 获得响应。
您可以在发送硬编码响应和发送新消息之前创建一个随机的sleep time.sleep(10)来进行试验。然后,您可以尝试在新的Postman会话中使用不同的令牌来建立连接。
您会注意到,在随机睡眠超时之前,聊天会话不会连接。
虽然我们可以在更注重生产的服务器设置中使用异步技术和工作线程池,但随着并发用户数量的增长,这也不够。
最终,我们希望通过使用 Redis 来代理我们的聊天 API 和第三方 API 之间的通信,从而避免占用 Web 服务器资源。
接下来打开一个新终端,cd 进入 worker 文件夹,并创建并激活一个新的 Python 虚拟环境,类似于我们在第 1 部分中所做的。
接下来,安装以下依赖项:
pip install aiohttp aioredis python-dotenv如何使用 Redis 客户端在 Python 中连接到 Redis 集群
我们将使用 aioredis 客户端与 Redis 数据库连接。我们还将使用 requests 库向 Huggingface 推理 API 发送请求。
创建两个文件.env和main.py。然后创建一个名为src的文件夹。另外,创建一个名为redis的文件夹,并添加一个名为config.py的新文件。
在.env文件中,添加以下代码,并确保使用 Redis 集群中提供的凭证更新字段。
export REDIS_URL=<REDIS URL PROVIDED IN REDIS CLOUD>
export REDIS_USER=<REDIS USER IN REDIS CLOUD>
export REDIS_PASSWORD=<DATABASE PASSWORD IN REDIS CLOUD>
export REDIS_HOST=<REDIS HOST IN REDIS CLOUD>
export REDIS_PORT=<REDIS PORT IN REDIS CLOUD>在 config.py 中添加下面的 Redis 类:
import os
from dotenv import load_dotenv
import aioredis
load_dotenv()
class Redis():
def __init__(self):
"""initialize connection """
self.REDIS_URL = os.environ['REDIS_URL']
self.REDIS_PASSWORD = os.environ['REDIS_PASSWORD']
self.REDIS_USER = os.environ['REDIS_USER']
self.connection_url = f"redis://{self.REDIS_USER}:{self.REDIS_PASSWORD}@{self.REDIS_URL}"
async def create_connection(self):
self.connection = aioredis.from_url(
self.connection_url, db=0)
return self.connection我们创建一个Redis对象,并从环境变量初始化所需的参数。然后我们创建一个异步方法create_connection来创建一个Redis连接,并返回从aioredis方法from_url获得的连接池。
接下来,我们通过运行以下代码在 main.py 中测试 Redis 连接。这将创建一个新的 Redis 连接池,设置一个简单的键 “key”,并为其分配一个字符串 “value”。
from src.redis.config import Redis
import asyncio
async def main():
redis = Redis()
redis = await redis.create_connection()
print(redis)
await redis.set("key", "value")
if __name__ == "__main__":
asyncio.run(main())现在打开 Redis Insight(如果您按照教程下载并安装它)您应该会看到如下内容:
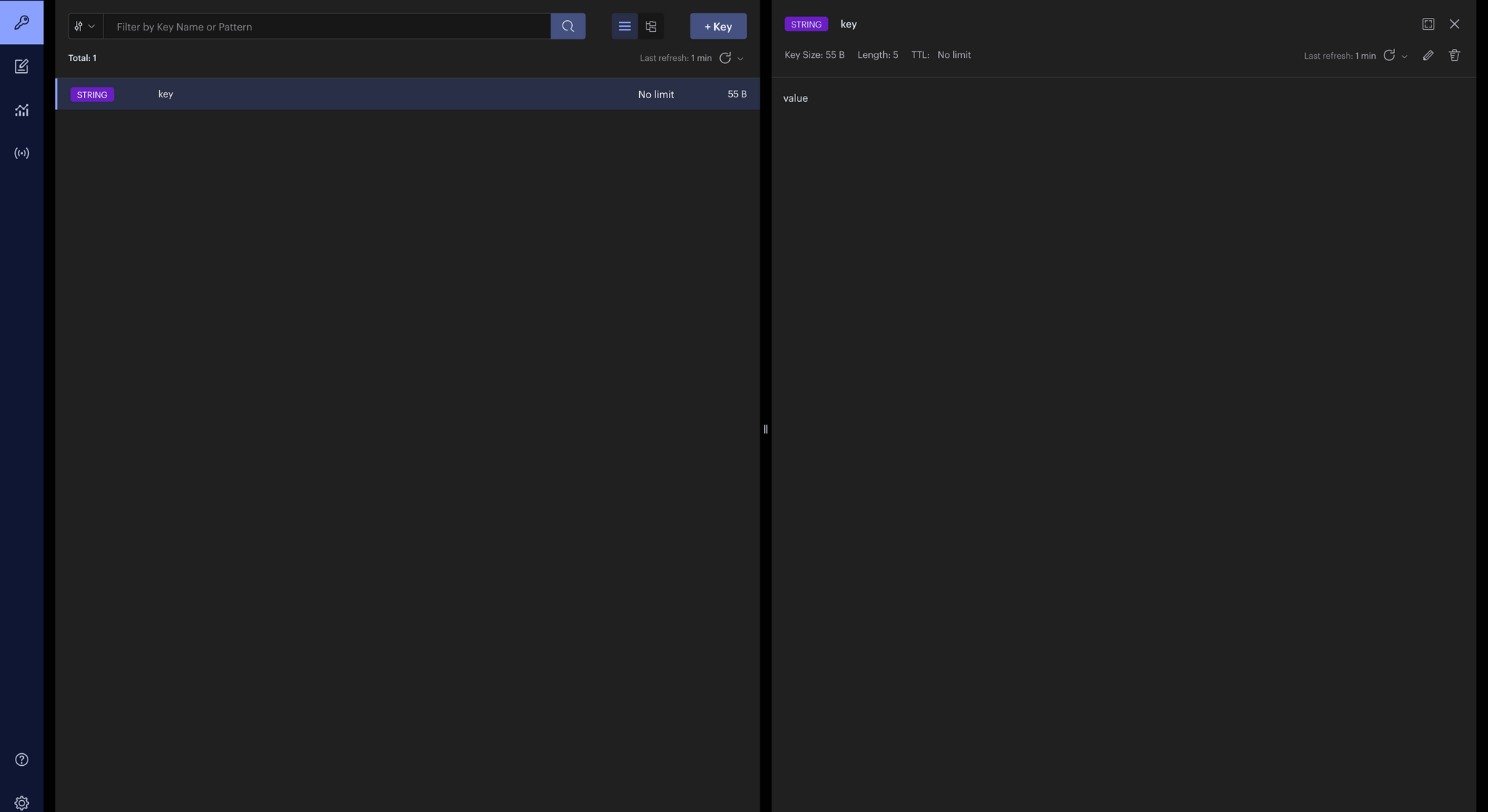 Redis Insight 测试
Redis Insight 测试
如何使用 Redis Streams
现在我们已经设置了 worker 环境,我们可以在 Web 服务器上创建一个 producer,并在 worker 上创建一个 consumer。
首先,让我们在服务器上再次创建Redis类。在服务器上。SRC创建一个名为redis的文件夹,并添加config.py和producer.py两个文件。
在 config.py中,添加以下代码,就像我们对 worker 环境所做的那样:
import os
from dotenv import load_dotenv
import aioredis
load_dotenv()
class Redis():
def __init__(self):
"""initialize connection """
self.REDIS_URL = os.environ['REDIS_URL']
self.REDIS_PASSWORD = os.environ['REDIS_PASSWORD']
self.REDIS_USER = os.environ['REDIS_USER']
self.connection_url = f"redis://{self.REDIS_USER}:{self.REDIS_PASSWORD}@{self.REDIS_URL}"
async def create_connection(self):
self.connection = aioredis.from_url(
self.connection_url, db=0)
return self.connection在 .env 文件中,还要添加 Redis 凭证:
export REDIS_URL=<REDIS URL PROVIDED IN REDIS CLOUD>
export REDIS_USER=<REDIS USER IN REDIS CLOUD>
export REDIS_PASSWORD=<DATABASE PASSWORD IN REDIS CLOUD>
export REDIS_HOST=<REDIS HOST IN REDIS CLOUD>
export REDIS_PORT=<REDIS PORT IN REDIS CLOUD>最后,在 server.src.redis.producer.py添加 the following code:
from .config import Redis
class Producer:
def __init__(self, redis_client):
self.redis_client = redis_client
async def add_to_stream(self, data: dict, stream_channel):
try:
msg_id = await self.redis_client.xadd(name=stream_channel, id="*", fields=data)
print(f"Message id {msg_id} added to {stream_channel} stream")
return msg_id
except Exception as e:
print(f"Error sending msg to stream => {e}")我们创建了一个使用 Redis 客户端初始化的 Producer 类。我们使用此客户端通过add_to_stream该方法将数据添加到流中,该方法采用数据和 Redis 通道名称。
用于向流通道添加数据的 Redis 命令是xadd,它在 aioredis 中同时具有高级和低级函数。
接下来,要运行我们新创建的 Producer,请更新 chat.py和WebSocket /chat终端节点,如下所示。请注意更新后的通道名称 :message_channel
from ..redis.producer import Producer
from ..redis.config import Redis
chat = APIRouter()
manager = ConnectionManager()
redis = Redis()
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket, token: str = Depends(get_token)):
await manager.connect(websocket)
redis_client = await redis.create_connection()
producer = Producer(redis_client)
try:
while True:
data = await websocket.receive_text()
print(data)
stream_data = {}
stream_data[token] = data
await producer.add_to_stream(stream_data, "message_channel")
await manager.send_personal_message(f"Response: Simulating response from the GPT service", websocket)
except WebSocketDisconnect:
manager.disconnect(websocket)接下来,在 Postman 中,创建一个连接并发送任意数量的消息,这些消息显示 Hello.您应该将流消息打印到终端,如下所示:

终端信道消息测试
在 Redis Insight 中,您将看到一个新创建的队列mesage_channel和一个带时间戳的队列,其中填充了从客户端发送的消息。此带时间戳的队列对于保持消息的顺序非常重要。
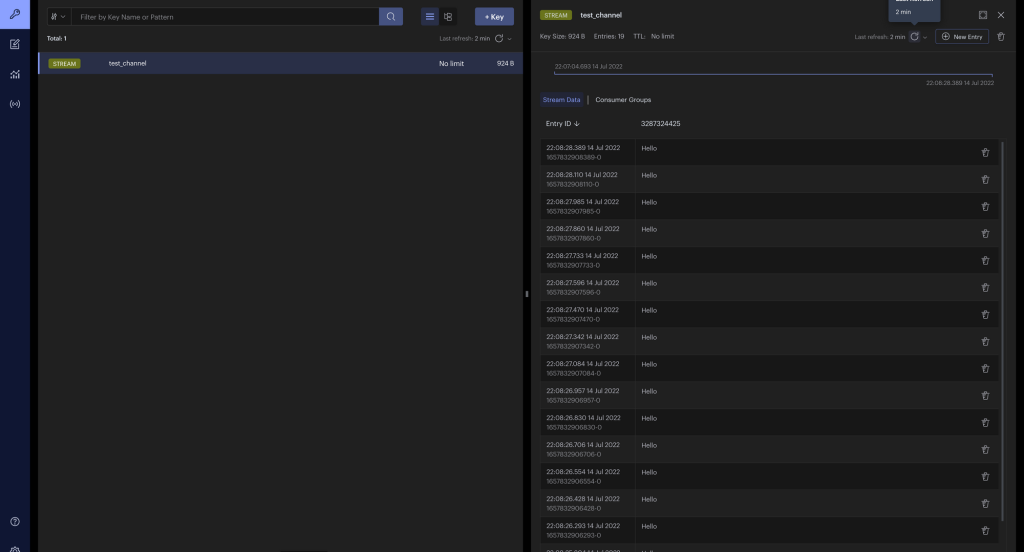
Redis洞察频道
如何对聊天数据进行建模
接下来,我们将为聊天消息创建一个模型。回想一下,我们通过 WebSockets 发送文本数据,但我们的聊天数据需要包含更多的信息,而不仅仅是文本。我们需要在发送聊天消息时为其加上时间戳,并为每条消息分配一个唯一的ID,同时收集关于聊天会话的相关数据,最后以JSON格式存储这些数据。
我们可以将这些 JSON 数据存储在 Redis 中,这样就不会在连接丢失后丢失聊天记录,因为我们的 WebSocket 不存储状态。
在server.src中创建名为schema的新文件夹。然后创建一个名为chat.py in server.src.schema中添加 the following code 的文件:
from datetime import datetime
from pydantic import BaseModel
from typing import List, Optional
import uuid
class Message(BaseModel):
id = uuid.uuid4()
msg: str
timestamp = str(datetime.now())
class Chat(BaseModel):
token: str
messages: List[Message]
name: str
session_start = str(datetime.now())我们使用Pydantic的BaseModel类对聊天数据建模。Chat类将保存单个Chat会话的数据。它将存储令牌、用户名以及使用datetime.now()为聊天会话开始时间自动生成的时间戳。
在这个聊天会话中发送和接收的消息存储在一个Message类中,该类使用uid4动态地创建一个聊天id。初始化Message类时需要提供的唯一数据是消息文本。
如何使用 Redis JSON
为了使用 Redis JSON 的能力来存储我们的聊天记录,我们需要安装 Redis labs 提供的 rejson。
在终端,cd到服务器并使用pip install rejson安装rejson。然后更新server.src.redis.config.py中的Redis类,使其包含create_rejson_connection方法:
import os
from dotenv import load_dotenv
import aioredis
from rejson import Client
load_dotenv()
class Redis():
def __init__(self):
"""initialize connection """
self.REDIS_URL = os.environ['REDIS_URL']
self.REDIS_PASSWORD = os.environ['REDIS_PASSWORD']
self.REDIS_USER = os.environ['REDIS_USER']
self.connection_url = f"redis://{self.REDIS_USER}:{self.REDIS_PASSWORD}@{self.REDIS_URL}"
self.REDIS_HOST = os.environ['REDIS_HOST']
self.REDIS_PORT = os.environ['REDIS_PORT']
async def create_connection(self):
self.connection = aioredis.from_url(
self.connection_url, db=0)
return self.connection
def create_rejson_connection(self):
self.redisJson = Client(host=self.REDIS_HOST,
port=self.REDIS_PORT, decode_responses=True, username=self.REDIS_USER, password=self.REDIS_PASSWORD)
return self.redisJson我们正在添加create_rejson_connection方法,通过rejson Client连接到Redis。这为我们提供了在Redis中创建和操作JSON数据的方法,这在aioredis中是不可用的。
接下来,在server.src.routes.chat.py中,我们可以更新/token端点来创建一个新的Chat实例,并将会话数据存储在Redis JSON中,如下所示:
@chat.post("/token")
async def token_generator(name: str, request: Request):
token = str(uuid.uuid4())
if name == "":
raise HTTPException(status_code=400, detail={
"loc": "name", "msg": "Enter a valid name"})
# Create new chat session
json_client = redis.create_rejson_connection()
chat_session = Chat(
token=token,
messages=[],
name=name
)
# Store chat session in redis JSON with the token as key
json_client.jsonset(str(token), Path.rootPath(), chat_session.dict())
# Set a timeout for redis data
redis_client = await redis.create_connection()
await redis_client.expire(str(token), 3600)
return chat_session.dict()注意:因为这是一个演示应用程序,所以我不想在 Redis 中存储聊天数据太久。因此,我使用 aioredis 客户端在令牌上添加了 60 分钟的超时(rejson 不实施超时)。这意味着 60 分钟后,聊天会话数据将丢失。
这一步是必要的,因为我们没有对用户进行身份验证,并且我们希望在特定的时间段后能够清除聊天数据。不过,这个步骤是可选的,您可以根据自己的需求选择是否包含它。
接下来,在 Postman 中,当您发送 POST 请求以创建新令牌时,您将获得如下所示的结构化响应。您还可以检查 Redis Insight,查看与令牌一起存储为 JSON 键的聊天数据,以及以值形式存储的数据。
令牌生成器更新
如何更新 Token 依赖项
现在我们已经生成并存储了一个令牌,现在是更新/chat WebSocket中的get_token依赖项的好时机了。我们这样做是为了在开始聊天会话之前检查有效的令牌。
在server.src.socket.utils.py中更新get_token函数来检查是否在Redis实例中存在token。如果是,则返回令牌,这意味着套接字连接是有效的。如果它不存在,我们关闭连接。
/token创建的令牌将在60分钟后停止存在。因此,如果在尝试开始聊天时生成错误响应,我们可以在前端使用一些简单的逻辑来重定向用户以生成新的令牌。
from ..redis.config import Redis
async def get_token(
websocket: WebSocket,
token: Optional[str] = Query(None),
):
if token is None or token == "":
await websocket.close(code=status.WS_1008_POLICY_VIOLATION)
redis_client = await redis.create_connection()
isexists = await redis_client.exists(token)
if isexists == 1:
return token
else:
await websocket.close(code=status.WS_1008_POLICY_VIOLATION, reason="Session not authenticated or expired token")要测试依赖关系,请使用我们一直在使用的随机令牌连接到聊天会话,您应该会收到 403 错误。(请注意,您必须在 Redis Insight 中手动删除令牌。)
现在复制发送post请求到/token端点时生成的令牌(或创建一个新请求),并将其作为值粘贴到/chat WebSocket所需的令牌查询参数中。然后连接。你应该能成功连接。
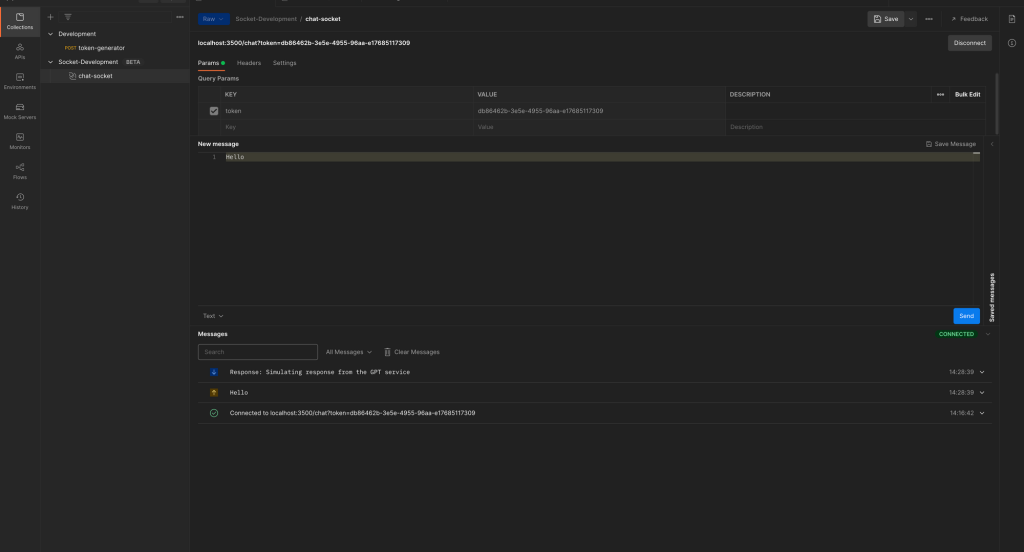
带令牌的聊天会话
综上所述,您的 chat.py 应如下所示。
import os
from fastapi import APIRouter, FastAPI, WebSocket, WebSocketDisconnect, Request, Depends
import uuid
from ..socket.connection import ConnectionManager
from ..socket.utils import get_token
import time
from ..redis.producer import Producer
from ..redis.config import Redis
from ..schema.chat import Chat
from rejson import Path
chat = APIRouter()
manager = ConnectionManager()
redis = Redis()
# @route POST /token
# @desc Route to generate chat token
# @access Public
@chat.post("/token")
async def token_generator(name: str, request: Request):
token = str(uuid.uuid4())
if name == "":
raise HTTPException(status_code=400, detail={
"loc": "name", "msg": "Enter a valid name"})
# Create nee chat session
json_client = redis.create_rejson_connection()
chat_session = Chat(
token=token,
messages=[],
name=name
)
print(chat_session.dict())
# Store chat session in redis JSON with the token as key
json_client.jsonset(str(token), Path.rootPath(), chat_session.dict())
# Set a timeout for redis data
redis_client = await redis.create_connection()
await redis_client.expire(str(token), 3600)
return chat_session.dict()
# @route POST /refresh_token
# @desc Route to refresh token
# @access Public
@chat.post("/refresh_token")
async def refresh_token(request: Request):
return None
# @route Websocket /chat
# @desc Socket for chat bot
# @access Public
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket, token: str = Depends(get_token)):
await manager.connect(websocket)
redis_client = await redis.create_connection()
producer = Producer(redis_client)
json_client = redis.create_rejson_connection()
try:
while True:
data = await websocket.receive_text()
stream_data = {}
stream_data[token] = data
await producer.add_to_stream(stream_data, "message_channel")
await manager.send_personal_message(f"Response: Simulating response from the GPT service", websocket)
except WebSocketDisconnect:
manager.disconnect(websocket)干得好,走到这一步!在下一节中,我们将重点介绍与 AI 模型通信以及处理客户端、服务器、worker 和外部 API 之间的数据传输。
如何使用 AI 模型为聊天机器人添加智能
在本节中,我们将重点介绍如何构建一个包装器来与 transformer 模型通信,以对话格式将提示从用户发送到 API,以及接收和转换聊天应用程序的响应。
如何开始使用 Huggingface
我们不会在 Hugginface 上构建或部署任何语言模型。相反,我们的重点将放在利用Huggingface的加速推理API来连接预先训练好的模型上。
我们将使用的模型是 EleutherAI 提供的 GPT-J-6B 模型。这是一个生成语言模型,使用 60 亿个参数进行了训练。
Huggingface 为我们提供了一个按需受限的 API 来连接这个模型,它几乎是免费的。
要开始使用 Huggingface,请创建一个免费帐户。在您的设置中,生成新的访问令牌。对于最多 30k 个令牌,Huggingface 免费提供对推理 API 的访问。
您可以在这里监控API的使用情况。请务必确保这个令牌的安全,切勿将其公开。
注意:我们将使用 HTTP 连接与 API 通信,因为我们使用的是免费帐户。但是 PRO Huggingface 帐户支持使用 WebSockets 进行流式处理,请参阅并行性和批处理作业。
这有助于显著缩短模型和聊天应用程序之间的响应时间,我希望在后续文章中介绍这种方法。
如何与语言模型交互
首先,我们将 Huggingface 连接凭证添加到工作程序目录中的 .env 文件中。
export HUGGINFACE_INFERENCE_TOKEN=<HUGGINGFACE ACCESS TOKEN>
export MODEL_URL=https://api-inference.huggingface.co/models/EleutherAI/gpt-j-6B接下来,在worker.src 创建一个名为model的文件夹,然后添加一个文件gptj.py。然后添加下面的GPT类:
import os
from dotenv import load_dotenv
import requests
import json
load_dotenv()
class GPT:
def __init__(self):
self.url = os.environ.get('MODEL_URL')
self.headers = {
"Authorization": f"Bearer {os.environ.get('HUGGINFACE_INFERENCE_TOKEN')}"}
self.payload = {
"inputs": "",
"parameters": {
"return_full_text": False,
"use_cache": True,
"max_new_tokens": 25
}
}
def query(self, input: str) -> list:
self.payload["inputs"] = input
data = json.dumps(self.payload)
response = requests.request(
"POST", self.url, headers=self.headers, data=data)
print(json.loads(response.content.decode("utf-8")))
return json.loads(response.content.decode("utf-8"))
if __name__ == "__main__":
GPT().query("Will artificial intelligence help humanity conquer the universe?")GPT类是用Huggingface模型url、身份验证header和预定义的payload初始化的。但是有效负载输入是一个动态字段,由查询方法提供,并在我们向Huggingface端点发送请求之前更新
最后,我们通过直接在GPT类的实例上运行查询方法来测试这一点。在终端中,运行python src/model/gptj.py,你应该得到这样的响应(只是要记住,你的响应肯定与此不同):
[{'generated_text': ' (AI) could solve all the problems on this planet? I am of the opinion that in the short term artificial intelligence is much better than human beings, but in the long and distant future human beings will surpass artificial intelligence.\n\nIn the distant'}]接下来,我们向 input 添加一些调整,通过更改 input 的格式,使与模型的交互更具对话性。
GPT像这样更新类:
class GPT:
def __init__(self):
self.url = os.environ.get('MODEL_URL')
self.headers = {
"Authorization": f"Bearer {os.environ.get('HUGGINFACE_INFERENCE_TOKEN')}"}
self.payload = {
"inputs": "",
"parameters": {
"return_full_text": False,
"use_cache": False,
"max_new_tokens": 25
}
}
def query(self, input: str) -> list:
self.payload["inputs"] = f"Human: {input} Bot:"
data = json.dumps(self.payload)
response = requests.request(
"POST", self.url, headers=self.headers, data=data)
data = json.loads(response.content.decode("utf-8"))
text = data[0]['generated_text']
res = str(text.split("Human:")[0]).strip("\n").strip()
return res
if __name__ == "__main__":
GPT().query("Will artificial intelligence help humanity conquer the universe?")我们使用字符串文本f"Human: {input} Bot:"更新了输入。人工输入被放置在字符串中,机器人提供响应。这种输入格式将 GPT-J6B 变成了对话模型。您可能会注意到的其他变化包括
- use_cache:如果您希望模型在输入相同时创建新响应,则可以将其设为 False。我建议在生产中将其保留为 True,以防止如果用户不断向机器人发送相同的消息,则会耗尽您的免费令牌。使用 cache 实际上不会从模型加载新的响应。
- return_full_text: 为 False,因为我们不需要返回输入——我们已经有它了。当我们收到响应时,我们从响应中去除 “Bot:” 和前导/尾随空格,只返回响应文本。
如何模拟 AI 模型的短期记忆
对于我们发送到模型的每个新输入,模型无法记住对话历史记录。如果我们想在对话中保留上下文,这一点很重要。
但请记住,随着我们发送到模型的 Token 数量增加,处理成本会变得更高,响应时间也会更长。
因此,我们需要探索一种有效方法来检索短期历史记录,并将其发送给模型进行处理我们还需要弄清楚一个最佳点 – 我们想要检索多少历史数据并将其发送到模型?
要处理聊天记录,我们需要回退到我们的 JSON 数据库。我们将使用token来获取上次聊天数据,然后在收到响应时,将响应附加到 JSON 数据库。
更新worker.src.redis.config.py以包含create_rejson_connection该方法。此外,使用身份验证数据更新 .env 文件,并确保已安装 rejson。
您的worker.src.redis.config.py应如下所示:
import os
from dotenv import load_dotenv
import aioredis
from rejson import Client
load_dotenv()
class Redis():
def __init__(self):
"""initialize connection """
self.REDIS_URL = os.environ['REDIS_URL']
self.REDIS_PASSWORD = os.environ['REDIS_PASSWORD']
self.REDIS_USER = os.environ['REDIS_USER']
self.connection_url = f"redis://{self.REDIS_USER}:{self.REDIS_PASSWORD}@{self.REDIS_URL}"
self.REDIS_HOST = os.environ['REDIS_HOST']
self.REDIS_PORT = os.environ['REDIS_PORT']
async def create_connection(self):
self.connection = aioredis.from_url(
self.connection_url, db=0)
return self.connection
def create_rejson_connection(self):
self.redisJson = Client(host=self.REDIS_HOST,
port=self.REDIS_PORT, decode_responses=True, username=self.REDIS_USER, password=self.REDIS_PASSWORD)
return self.redisJson虽然您的 .env 文件应如下所示:
export REDIS_URL=<REDIS URL PROVIDED IN REDIS CLOUD>
export REDIS_USER=<REDIS USER IN REDIS CLOUD>
export REDIS_PASSWORD=<DATABASE PASSWORD IN REDIS CLOUD>
export REDIS_HOST=<REDIS HOST IN REDIS CLOUD>
export REDIS_PORT=<REDIS PORT IN REDIS CLOUD>
export HUGGINFACE_INFERENCE_TOKEN=<HUGGINGFACE ACCESS TOKEN>
export MODEL_URL=https://api-inference.huggingface.co/models/EleutherAI/gpt-j-6B接下来,在worker.src.redis 创建一个新的文件命名为cache.py并添加以下代码:
from .config import Redis
from rejson import Path
class Cache:
def __init__(self, json_client):
self.json_client = json_client
async def get_chat_history(self, token: str):
data = self.json_client.jsonget(
str(token), Path.rootPath())
return data缓存是用一个json客户端初始化的,get_chat_history方法接受一个令牌,从Redis获取该令牌的聊天历史。确保从json中导入了Path对象。
接下来,使用以下worker.main.py更新 :
from src.redis.config import Redis
import asyncio
from src.model.gptj import GPT
from src.redis.cache import Cache
redis = Redis()
async def main():
json_client = redis.create_rejson_connection()
data = await Cache(json_client).get_chat_history(token="18196e23-763b-4808-ae84-064348a0daff")
print(data)
if __name__ == "__main__":
asyncio.run(main())我在Postman中硬编码了一个从以前的测试中创建的样例令牌。如果没有创建令牌,只需向/token发送一个新请求并复制令牌,然后在终端中运行python main.py。您应该看到终端中的数据如下所示:
{'token': '18196e23-763b-4808-ae84-064348a0daff', 'messages': [], 'name': 'Stephen', 'session_start': '2022-07-16 13:20:01.092109'}接下来,我们需要在我们的缓存类中添加一个add_message_to_cache方法,该方法将特定令牌的消息添加到Redis。
async def add_message_to_cache(self, token: str, message_data: dict):
self.json_client.jsonarrappend(
str(token), Path('.messages'), message_data)rejson 提供的jsonarrappend方法将新消息附加到 message 数组中。
请注意,要访问 message 数组,我们需要提供 .messagesPath 的参数。如果您的消息数据具有不同/嵌套结构,只需提供要将新数据追加到的数组的路径。
要测试此方法,请使用以下代码更新 main.py 文件中的 main 函数:
async def main():
json_client = redis.create_rejson_connection()
await Cache(json_client).add_message_to_cache(token="18196e23-763b-4808-ae84-064348a0daff", message_data={
"id": "1",
"msg": "Hello",
"timestamp": "2022-07-16 13:20:01.092109"
})
data = await Cache(json_client).get_chat_history(token="18196e23-763b-4808-ae84-064348a0daff")
print(data)我们正在向缓存发送硬编码消息,并从缓存中获取聊天记录。当您在终端的 worker 目录中运行python main.py时,您应该在终端中打印出类似这样的东西,并将消息添加到 message 数组中。
{'token': '18196e23-763b-4808-ae84-064348a0daff', 'messages': [{'id': '1', 'msg': 'Hello', 'timestamp': '2022-07-16 13:20:01.092109'}], 'name': 'Stephen', 'session_start': '2022-07-16 13:20:01.092109'}最后,我们需要更新 main 函数以将消息数据发送到 GPT 模型,并使用客户端和模型之间发送的最后 4 条消息更新输入。
首先,让我们使用add_message_to_cache新参数 “source” 更新我们的函数,该参数将告诉我们消息是人类还是机器人。然后,我们可以使用此 arg 将 “Human:” 或 “Bot:” 标签添加到数据中,然后再将其存储到缓存中。
更新 add_message_to_cacheCache 类中的方法,如下所示:
async def add_message_to_cache(self, token: str, source: str, message_data: dict):
if source == "human":
message_data['msg'] = "Human: " + (message_data['msg'])
elif source == "bot":
message_data['msg'] = "Bot: " + (message_data['msg'])
self.json_client.jsonarrappend(
str(token), Path('.messages'), message_data)然后更新 worker 目录中 main.py 中的 main 函数,并运行python main.py以查看 Redis 数据库中的新结果。
async def main():
json_client = redis.create_rejson_connection()
await Cache(json_client).add_message_to_cache(token="18196e23-763b-4808-ae84-064348a0daff", source="human", message_data={
"id": "1",
"msg": "Hello",
"timestamp": "2022-07-16 13:20:01.092109"
})
data = await Cache(json_client).get_chat_history(token="18196e23-763b-4808-ae84-064348a0daff")
print(data)接下来,我们需要更新 main 函数以将新消息添加到缓存中,从缓存中读取前 4 条消息,然后使用 query 方法对模型进行 API 调用。它将具有一个有效负载,该负载由最后 4 条消息的复合字符串组成。
您可以随时调整要提取的历史记录中消息的数量,但在我看来,为了演示目的,选择4条消息是一个相当合适的数字。
在worker.src中,创建一个新的文件夹架构。然后创建一个名为chat.py并将我们的消息架构粘贴到 chat.py 中的新文件,如下所示:
from datetime import datetime
from pydantic import BaseModel
from typing import List, Optional
import uuid
class Message(BaseModel):
id = str(uuid.uuid4())
msg: str
timestamp = str(datetime.now())接下来,更新 main.py 文件,如下所示:
async def main():
json_client = redis.create_rejson_connection()
await Cache(json_client).add_message_to_cache(token="18196e23-763b-4808-ae84-064348a0daff", source="human", message_data={
"id": "3",
"msg": "I would like to go to the moon to, would you take me?",
"timestamp": "2022-07-16 13:20:01.092109"
})
data = await Cache(json_client).get_chat_history(token="18196e23-763b-4808-ae84-064348a0daff")
print(data)
message_data = data['messages'][-4:]
input = ["" + i['msg'] for i in message_data]
input = " ".join(input)
res = GPT().query(input=input)
msg = Message(
msg=res
)
print(msg)
await Cache(json_client).add_message_to_cache(token="18196e23-763b-4808-ae84-064348a0daff", source="bot", message_data=msg.dict())在上面的代码中,我们将新的消息数据添加到缓存中。此消息最终将来自消息队列。接下来,我们从缓存中获取聊天记录,其中现在将包含我们添加的最新数据。
请注意,我们使用相同的硬编码令牌添加到缓存并从缓存中获取,暂时只是为了测试这一点。
接下来,我们修剪缓存数据并仅提取最后 4 项。然后我们通过提取列表中的 msg 并将其连接到空字符串来合并输入数据。
最后,我们为机器人响应创建一个新的 Message 实例,并将响应添加到缓存中,将源指定为 “bot”
接下来,运行几次,每次运行python main.py时根据需要更改人工消息和 id。您应该与模型进行完整的对话输入和输出。
打开 Redis Insight,您应该会看到类似于以下内容的内容:
从 Message Queue 流式传输使用者和实时数据拉取
接下来,我们要创建一个使用者并更新我们的worker.main.py 去连接消息队列。我们希望它能够实时提取令牌数据,因为我们目前正在对令牌和消息输入进行硬编码。
在worker.src.redis中创建名为stream.py的新文件。使用以下代码添加一个StreamConsumer类:
class StreamConsumer:
def __init__(self, redis_client):
self.redis_client = redis_client
async def consume_stream(self, count: int, block: int, stream_channel):
response = await self.redis_client.xread(
streams={stream_channel: '0-0'}, count=count, block=block)
return response
async def delete_message(self, stream_channel, message_id):
await self.redis_client.xdel(stream_channel, message_id)StreamConsumer类是用Redis客户端初始化的。consume_stream方法使用aioredis提供的xread方法从消息通道的队列中提取一条新消息。
接下来,用while循环更新worker.main.py文件,以保持与消息通道的连接处于活动状态,如下所示:
from src.redis.config import Redis
import asyncio
from src.model.gptj import GPT
from src.redis.cache import Cache
from src.redis.config import Redis
from src.redis.stream import StreamConsumer
import os
from src.schema.chat import Message
redis = Redis()
async def main():
json_client = redis.create_rejson_connection()
redis_client = await redis.create_connection()
consumer = StreamConsumer(redis_client)
cache = Cache(json_client)
print("Stream consumer started")
print("Stream waiting for new messages")
while True:
response = await consumer.consume_stream(stream_channel="message_channel", count=1, block=0)
if response:
for stream, messages in response:
# Get message from stream, and extract token, message data and message id
for message in messages:
message_id = message[0]
token = [k.decode('utf-8')
for k, v in message[1].items()][0]
message = [v.decode('utf-8')
for k, v in message[1].items()][0]
print(token)
# Create a new message instance and add to cache, specifying the source as human
msg = Message(msg=message)
await cache.add_message_to_cache(token=token, source="human", message_data=msg.dict())
# Get chat history from cache
data = await cache.get_chat_history(token=token)
# Clean message input and send to query
message_data = data['messages'][-4:]
input = ["" + i['msg'] for i in message_data]
input = " ".join(input)
res = GPT().query(input=input)
msg = Message(
msg=res
)
print(msg)
await cache.add_message_to_cache(token=token, source="bot", message_data=msg.dict())
# Delete messaage from queue after it has been processed
await consumer.delete_message(stream_channel="message_channel", message_id=message_id)
if __name__ == "__main__":
asyncio.run(main())这是一个相当大的更新,所以让我们一步一步来:
我们使用while True循环,以便 worker 可以在线侦听队列中的消息。
接下来,我们通过调用consume_stream方法等待来自message_channel的新消息。如果队列中有消息,则提取message_id、令牌和消息。然后我们创建Message类的新实例,将消息添加到缓存中,然后获取最后4条消息。我们将其设置为GPT模型查询方法的输入。
获得响应后,使用add_message_to_cache方法将响应添加到缓存中,然后从队列中删除消息。
如何使用 AI 响应更新 Chat 客户端
到目前为止,我们正在从客户端向 message_channel 发送聊天消息(由查询 AI 模型的工作程序接收)以获取响应。
接下来,我们需要将此响应发送给客户端。只要套接字连接仍处于打开状态,客户端就应该能够接收响应。
如果连接已关闭,则客户端始终可以使用refresh_token终端节点从聊天历史记录中获取响应。
在worker.src.redis创建一个名为producer.py的新文件Producer中,并添加一个类似于我们在聊天 Web 服务器上的类:
class Producer:
def __init__(self, redis_client):
self.redis_client = redis_client
async def add_to_stream(self, data: dict, stream_channel) -> bool:
msg_id = await self.redis_client.xadd(name=stream_channel, id="*", fields=data)
print(f"Message id {msg_id} added to {stream_channel} stream")
return msg_id接下来,在main.py文件中,更新 main 函数以初始化创建者,创建流数据,并使用add_to_stream方法将响应发送到 response_channel
from src.redis.config import Redis
import asyncio
from src.model.gptj import GPT
from src.redis.cache import Cache
from src.redis.config import Redis
from src.redis.stream import StreamConsumer
import os
from src.schema.chat import Message
from src.redis.producer import Producer
redis = Redis()
async def main():
json_client = redis.create_rejson_connection()
redis_client = await redis.create_connection()
consumer = StreamConsumer(redis_client)
cache = Cache(json_client)
producer = Producer(redis_client)
print("Stream consumer started")
print("Stream waiting for new messages")
while True:
response = await consumer.consume_stream(stream_channel="message_channel", count=1, block=0)
if response:
for stream, messages in response:
# Get message from stream, and extract token, message data and message id
for message in messages:
message_id = message[0]
token = [k.decode('utf-8')
for k, v in message[1].items()][0]
message = [v.decode('utf-8')
for k, v in message[1].items()][0]
# Create a new message instance and add to cache, specifying the source as human
msg = Message(msg=message)
await cache.add_message_to_cache(token=token, source="human", message_data=msg.dict())
# Get chat history from cache
data = await cache.get_chat_history(token=token)
# Clean message input and send to query
message_data = data['messages'][-4:]
input = ["" + i['msg'] for i in message_data]
input = " ".join(input)
res = GPT().query(input=input)
msg = Message(
msg=res
)
stream_data = {}
stream_data[str(token)] = str(msg.dict())
await producer.add_to_stream(stream_data, "response_channel")
await cache.add_message_to_cache(token=token, source="bot", message_data=msg.dict())
# Delete messaage from queue after it has been processed
await consumer.delete_message(stream_channel="message_channel", message_id=message_id)
if __name__ == "__main__":
asyncio.run(main())接下来,我们需要让客户端知道我们何时收到来自 socket 终端节点/chat中 worker 的响应。我们通过监听响应流来实现这一点。在这里,我们无需包含while循环,因为只要连接保持开启状态,套接字就会持续进行监听。
请注意,我们还需要通过添加逻辑来检查连接的令牌是否等于响应中的令牌,从而检查响应是针对哪个客户端的。然后,我们在读取响应队列中的消息后将其删除。
在server.src.redis中创建一个名为 stream.py 的新文件并添加我们的StreamConsumer类,如下所示:
from .config import Redis
class StreamConsumer:
def __init__(self, redis_client):
self.redis_client = redis_client
async def consume_stream(self, count: int, block: int, stream_channel):
response = await self.redis_client.xread(
streams={stream_channel: '0-0'}, count=count, block=block)
return response
async def delete_message(self, stream_channel, message_id):
await self.redis_client.xdel(stream_channel, message_id)接下来,更新/chat套接字端点,如下所示:
from ..redis.stream import StreamConsumer
@chat.websocket("/chat")
async def websocket_endpoint(websocket: WebSocket, token: str = Depends(get_token)):
await manager.connect(websocket)
redis_client = await redis.create_connection()
producer = Producer(redis_client)
json_client = redis.create_rejson_connection()
consumer = StreamConsumer(redis_client)
try:
while True:
data = await websocket.receive_text()
stream_data = {}
stream_data[str(token)] = str(data)
await producer.add_to_stream(stream_data, "message_channel")
response = await consumer.consume_stream(stream_channel="response_channel", block=0)
print(response)
for stream, messages in response:
for message in messages:
response_token = [k.decode('utf-8')
for k, v in message[1].items()][0]
if token == response_token:
response_message = [v.decode('utf-8')
for k, v in message[1].items()][0]
print(message[0].decode('utf-8'))
print(token)
print(response_token)
await manager.send_personal_message(response_message, websocket)
await consumer.delete_message(stream_channel="response_channel", message_id=message[0].decode('utf-8'))
except WebSocketDisconnect:
manager.disconnect(websocket)刷新令牌
最后,我们需要更新终端节点/refresh_token,以使用我们的Cache类从 Redis 数据库获取聊天记录。
在 server.src.redis中,添加一个cache.py文件并添加以下代码:
from rejson import Path
class Cache:
def __init__(self, json_client):
self.json_client = json_client
async def get_chat_history(self, token: str):
data = self.json_client.jsonget(
str(token), Path.rootPath())
return data接下来,在server.src.routes.chat.py中导入缓存类并更新/token端点如下:
from ..redis.cache import Cache
@chat.get("/refresh_token")
async def refresh_token(request: Request, token: str):
json_client = redis.create_rejson_connection()
cache = Cache(json_client)
data = await cache.get_chat_history(token)
if data == None:
raise HTTPException(
status_code=400, detail="Session expired or does not exist")
else:
return data现在,当我们使用任何令牌向/refresh_token终端节点发送 GET 请求时,终端节点将从 Redis 数据库获取数据。
如果 Token 未超时,则数据将发送给用户。或者,如果未找到令牌,它将发送 400 响应。
如何在 Postman 中测试与多个客户端的聊天
最后,我们将通过在 Postman 中创建多个聊天会话、在 Postman 中连接多个客户端以及在客户端上与机器人聊天来测试聊天系统。
最后,我们将尝试获取客户的聊天记录,并希望得到适当的回应。
回顾
让我们快速回顾一下我们使用聊天系统取得的成就。聊天客户端为与客户端的每个聊天会话创建一个令牌。此令牌用于标识每个客户端,连接到或 Web 服务器的客户端发送的每条消息都在 Redis 通道 (message_chanel) 中排队,由令牌标识。
我们的 worker environment 从这个通道读取数据。它不知道客户端是谁(除了它是一个唯一的令牌),并使用队列中的消息向 Huggingface 推理 API 发送请求。
当它收到响应时,响应将添加到响应渠道中,并更新聊天历史记录。侦听 response_channel 的客户端在收到带有其令牌的响应后立即将响应发送到客户端。
如果套接字仍处于打开状态,则发送此响应。如果套接字已关闭,我们确定响应被保留,因为响应已添加到聊天历史记录中。即使发生了页面刷新或连接中断,客户端仍然能够获取到历史记录。
恭喜你走到了这一步!您已经能够构建一个有效的聊天系统。
在后续文章中,我将重点介绍如何为客户端构建聊天用户界面、创建单元和功能测试、使用 WebSockets 和异步请求微调我们的工作线程环境以加快响应时间,并最终在 AWS 上部署聊天应用程序。
原文链接:https://www.freecodecamp.org/news/how-to-build-an-ai-chatbot-with-redis-python-and-gpt/