

应用程序开发中不可或缺的开放API

原文较长,经过细致分析,我们可以从三个不同的角度深入探讨,以全面理解大型语言模型技术。这将有助于启发我们在研究或定制大型语言模型方面的思考。对原博主的精心整理表示感激:
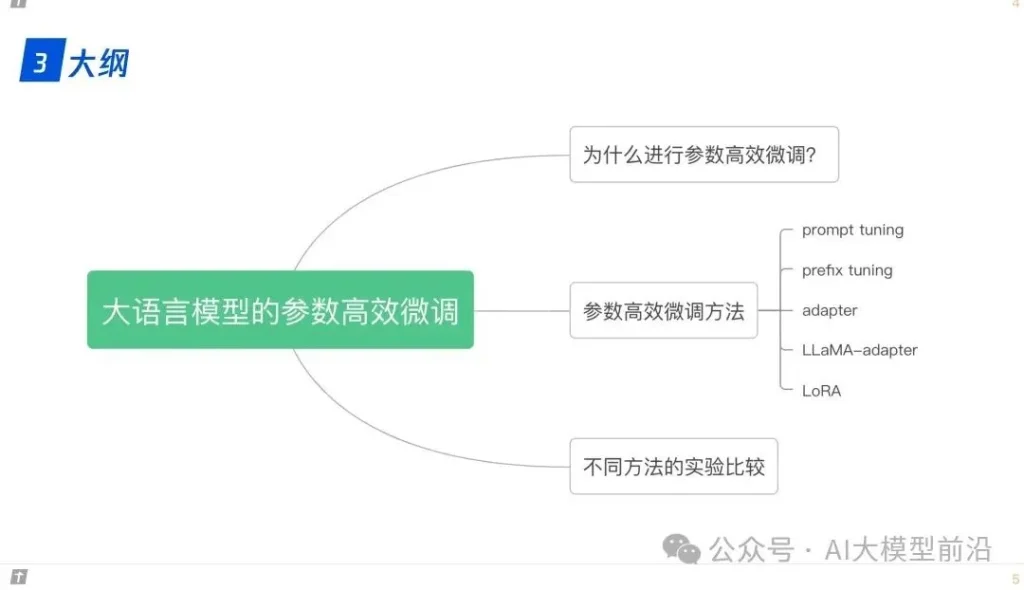
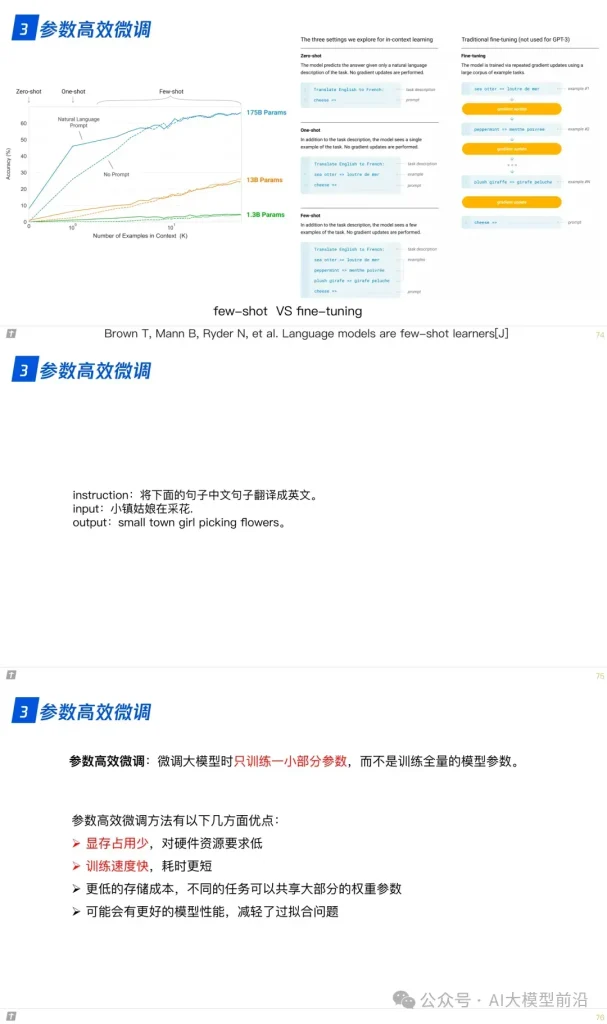
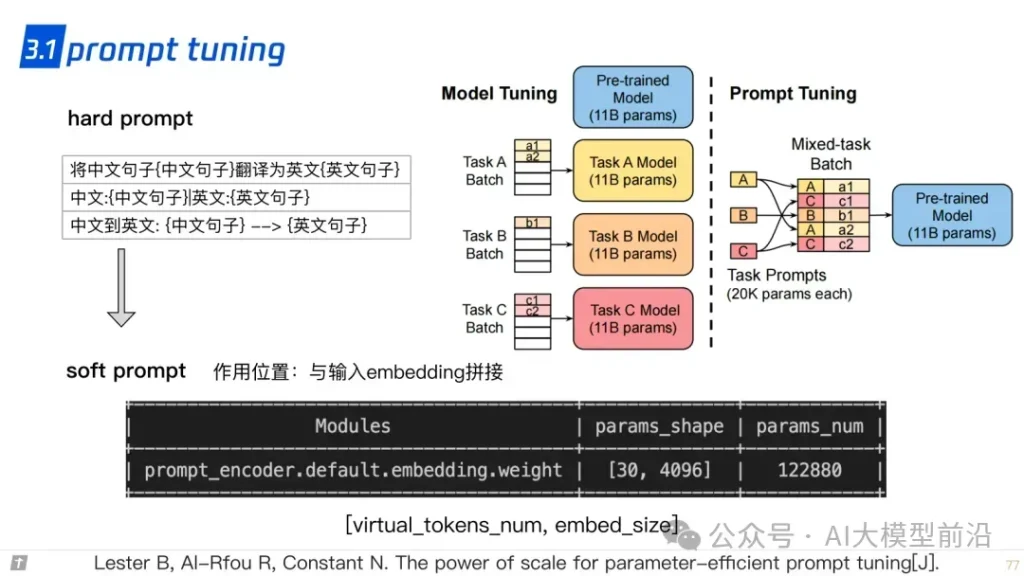
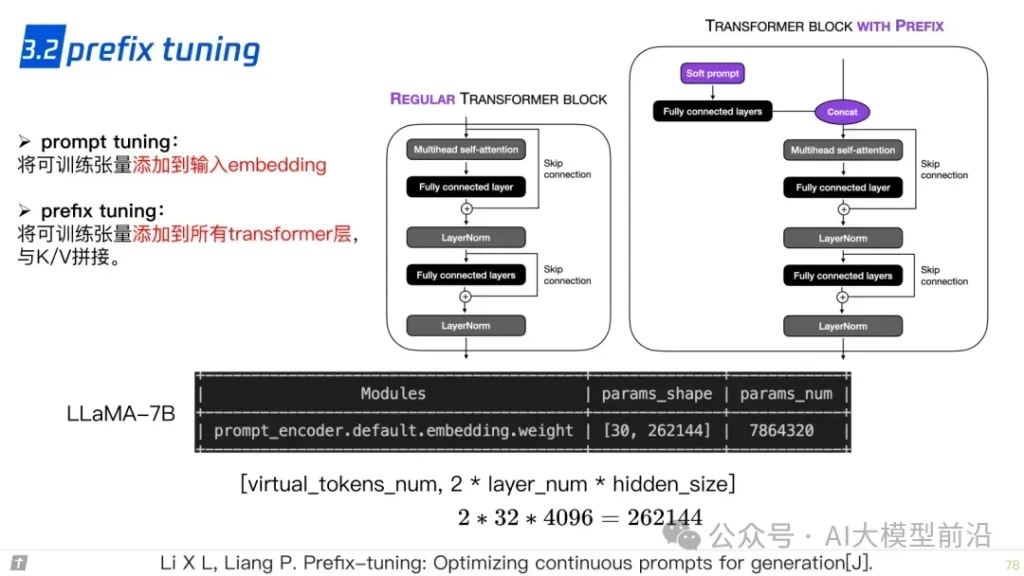
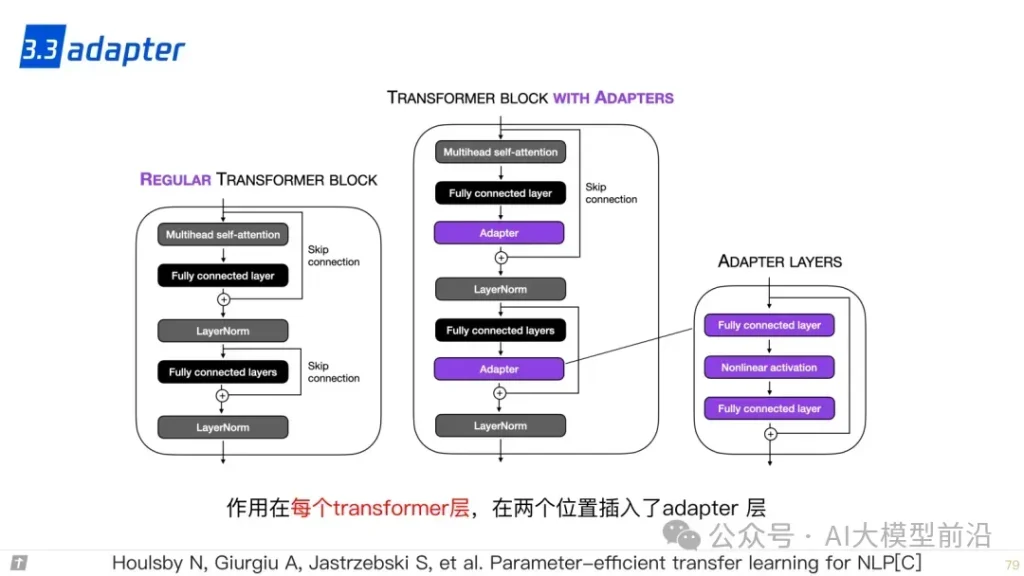
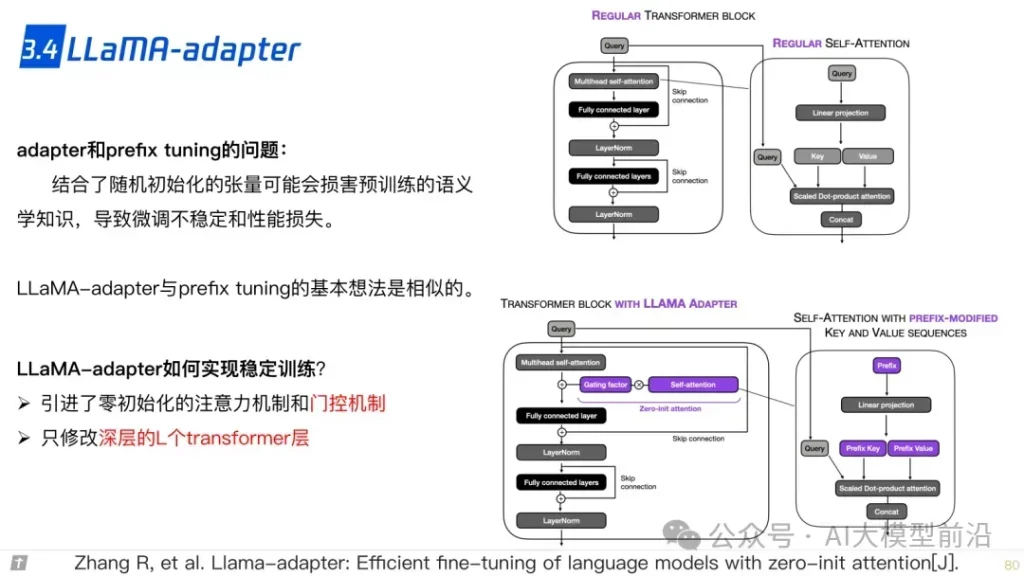
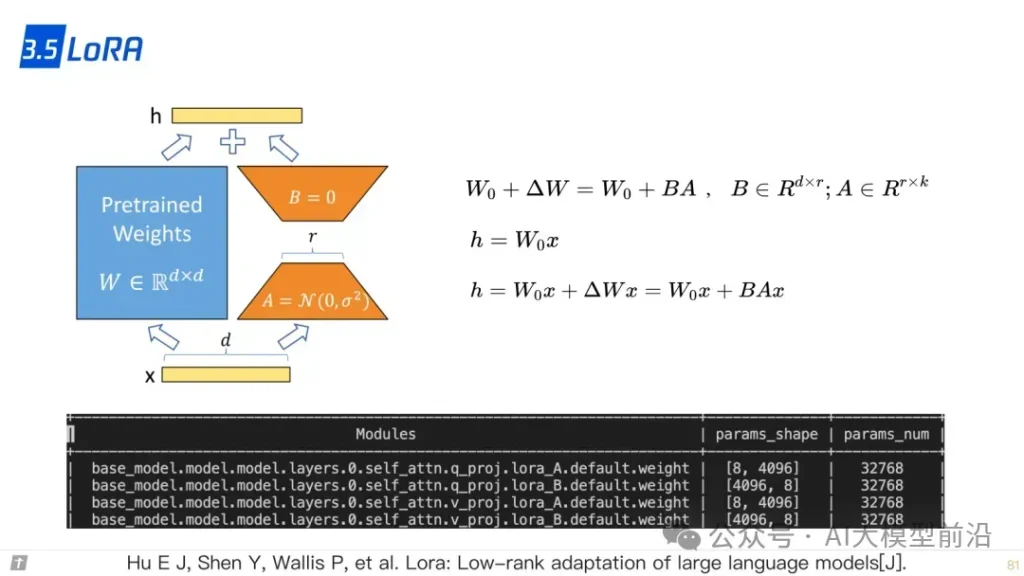
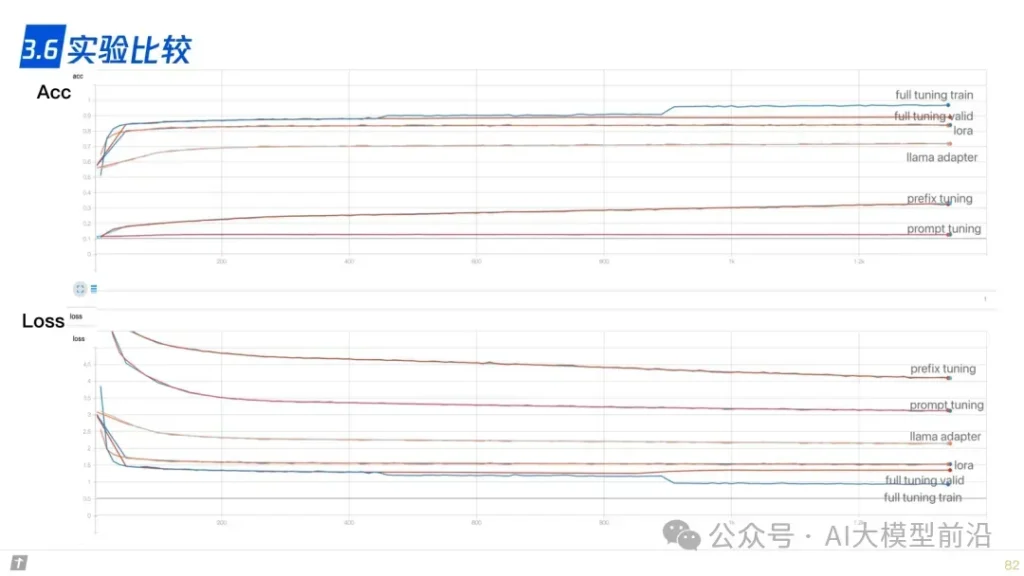
在微调大语言模型时,参数的高效利用成为关键。Prompt Tuning、Prefix Tuning和Adapter等方法,通过调整模型的部分参数而非全部,实现了高效的模型定制。LLaMA-Adapter和LoRA等技术则进一步优化了这一过程,使模型能够更快地适应新的任务和领域,同时保持较高的性能。
理解大语言模型,可以从‘LLM的架构、LLL的训练、LLL的微调’三个方面进行,也可以针对需求重点理解一部分。例如,训练+微调,可以读后两篇,只做微调,读最后一篇。

原文转自 微信公众号@AI大模型前沿












