

构建大语言模型友好型API

原文较长,细度之后可以分为三方方面分别深入了解,让我们对大语言模型技术有一个全面的认识,从而对我们研究或定制大语言模型起到抛砖引玉的作用,感谢原博主的整理:
大家好,我是花哥,本文分为三个章节,深入浅出地解读大模型的技术,具体如下三个部分:
1、GPT、LLaMA、ChatGLM、Falcon等大语言模型的技术细节比较
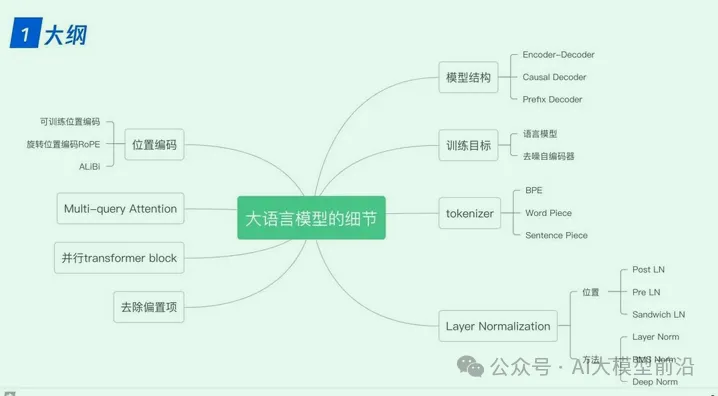
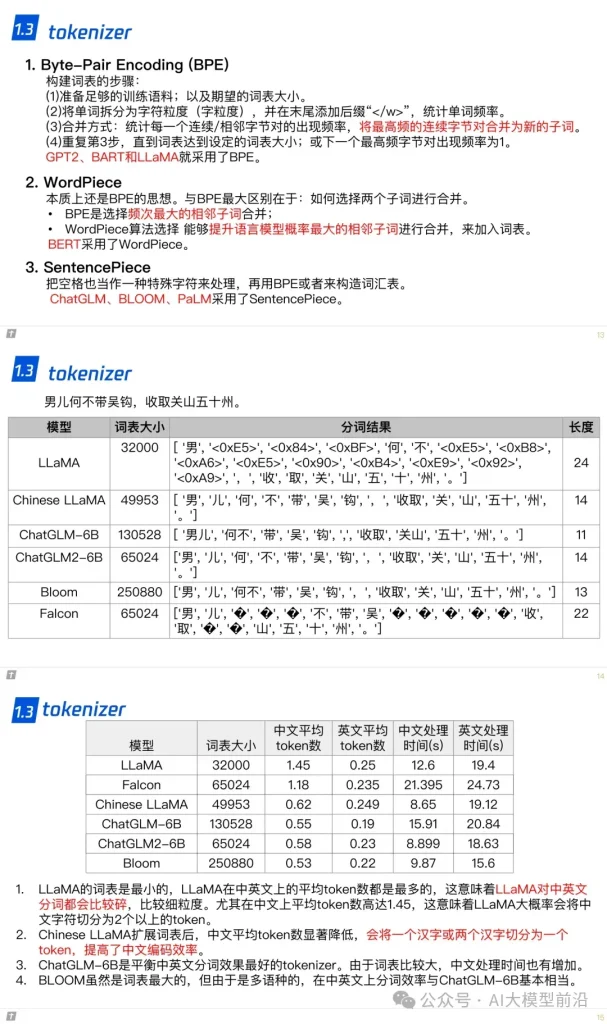
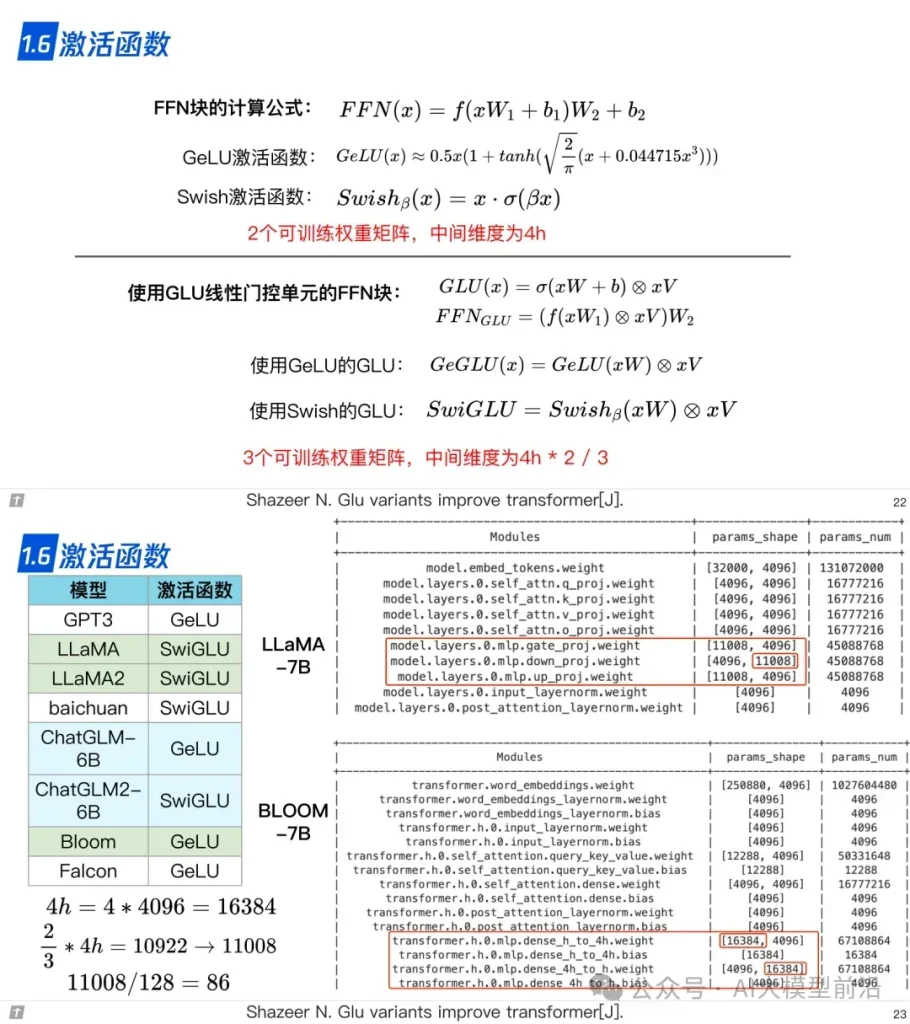
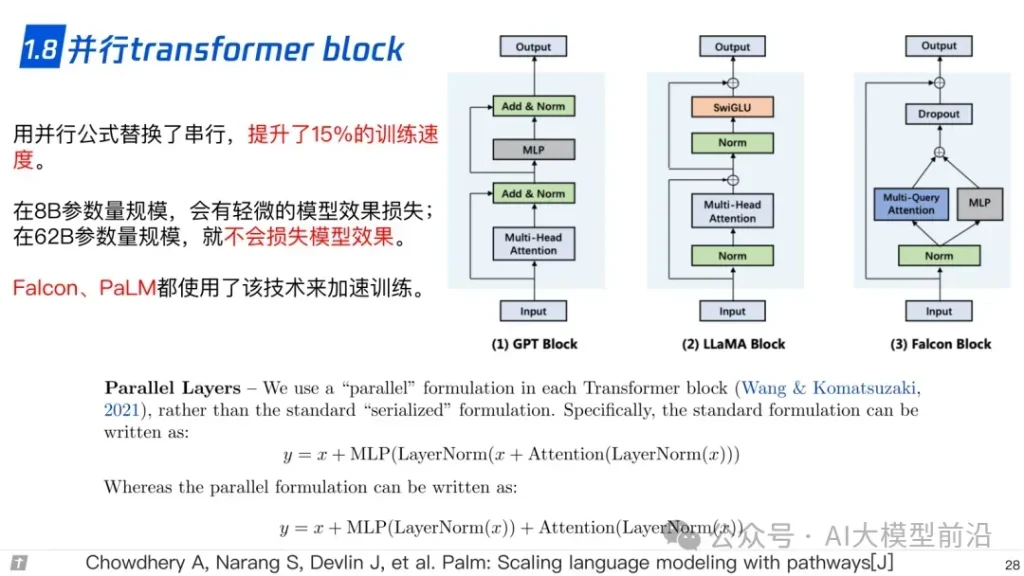
在深入研究LLaMA、ChatGLM和Falcon等大语言模型时,我们不难发现它们在技术实现上有着诸多共通之处与独特差异。例如,这些模型在tokenizer(分词器)的选择上,可能会根据模型的特性和应用场景来定制;位置编码(Positional Encoding)的实现方式也各具特色,对模型性能的影响不容忽视。此外,Layer Normalization(层归一化)和激活函数(Activation Function)的选择与运用,都直接影响到模型的训练速度和准确性。
2、大语言模型的分布式训练技术概览
3、大语言模型的参数高效微调技术探索
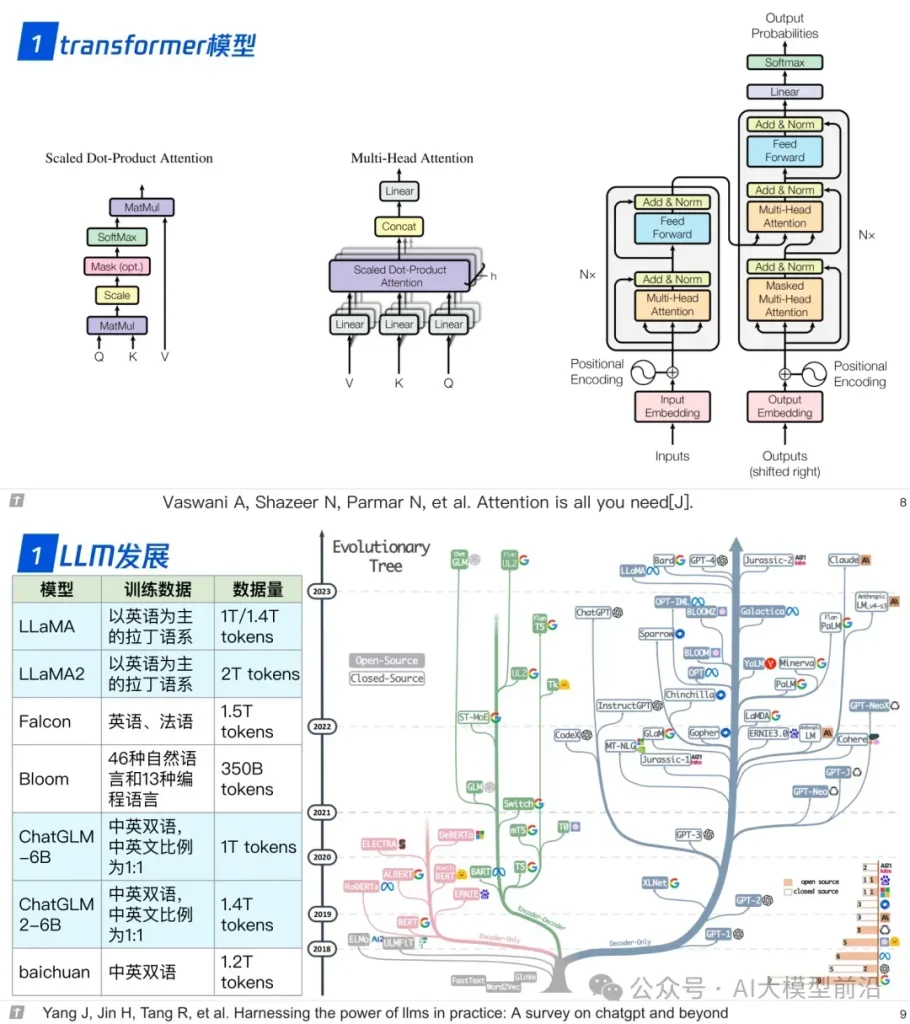
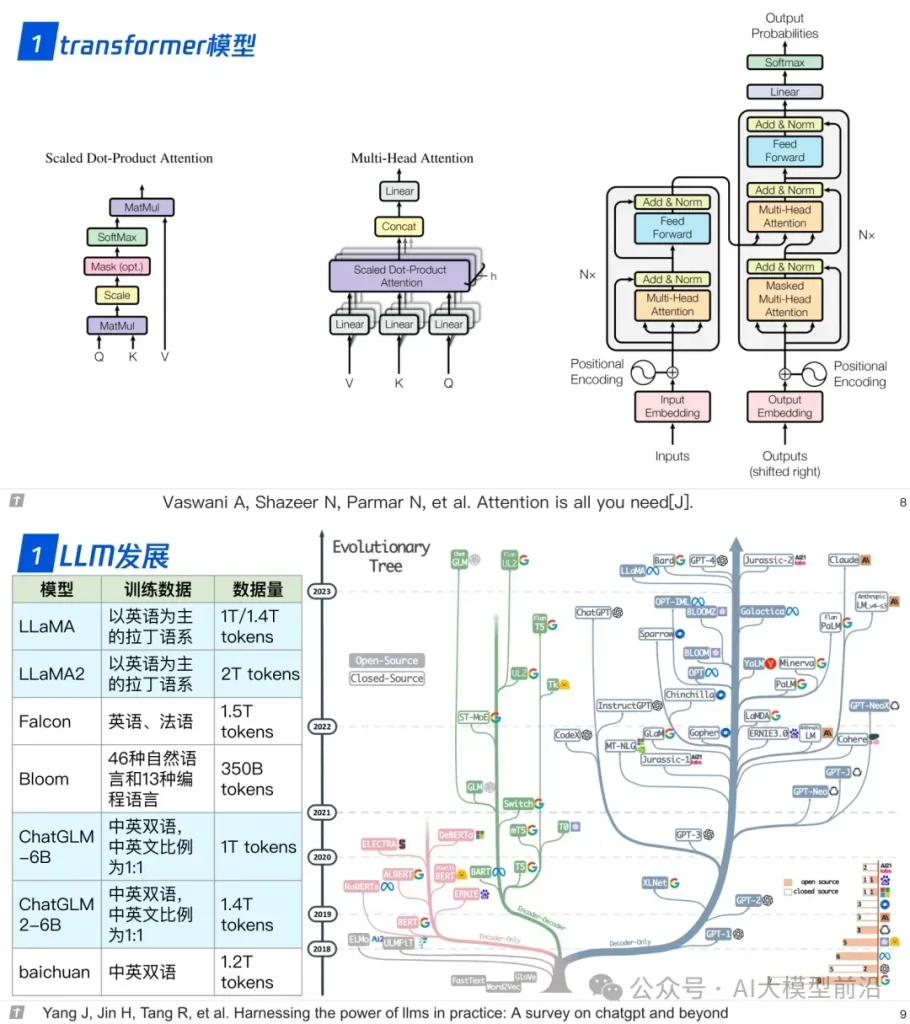







理解大语言模型,可以从‘LLM的架构、LLL的训练、LLL的微调’三个方面进行,也可以针对需求重点理解一部分。例如,训练+微调,可以读后两篇,只做微调,读最后一篇。

原文转自: 微信公众号@AI大模型前沿



