PyTorch Transformer API源码解析
Transformer结构图初探
在分析Transformer的结构之前,我们需要了解其基本运行原理。下图展示了Transformer的整体结构,从输入到位置编码的详细步骤。
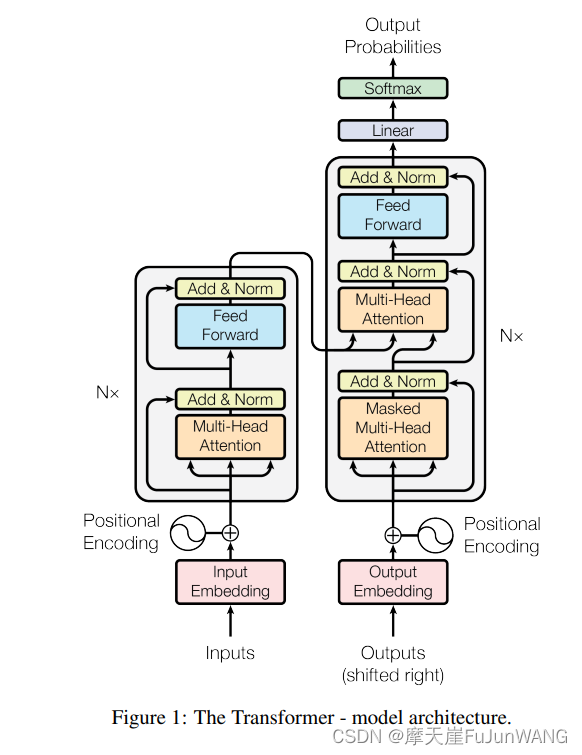
图中的结构主要分为两部分:编码器和解码器。编码器将输入序列转换为一组表示,该表示将传递给解码器生成输出序列。位置编码(Positional Encoding)是为了在序列中加入位置信息,因为Transformer不具备处理序列位置信息的能力。
PyTorch中对Transformer的调用
PyTorch提供了便捷的API来实现Transformer模型。其核心是将左侧的神经网络封装为一个TransformerEncoder类。该类需要两个关键参数:TransformerEncoderLayer和层数(num_layers)。
class Transformer(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_class,
dim_feedforward=512, num_head=2, num_layers=2, dropout=0.1, max_len=512, activation='relu'):
super(Transformer, self).__init__()
self.embedding_dim = embedding_dim
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.position_embedding = PositionalEncoding(embedding_dim, dropout, max_len)
encoder_layer = nn.TransformerEncoderLayer(hidden_dim, num_head, dim_feedforward, dropout, activation)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers)
self.output = nn.Linear(hidden_dim, num_class)
def forward(self, inputs, lengths):
inputs = torch.transpose(inputs, 0, 1)
hidden_states = self.embeddings(inputs)
hidden_states = self.position_embedding(hidden_states)
attention_mask = length_to_mask(lengths) == False
hidden_states = self.transformer(hidden_states, src_key_padding_mask=attention_mask).transpose(0, 1)
logits = self.output(hidden_states)
log_probs = F.log_softmax(logits, dim=-1)
return log_probsTransformerEncoder类详解
TransformerEncoder是一个由多个编码器层组成的堆栈。每个编码器层都由TransformerEncoderLayer类实例化,这个类具体实现了自注意力机制和前馈神经网络。
class TransformerEncoder(Module):
def __init__(self, encoder_layer, num_layers, norm=None):
super(TransformerEncoder, self).__init__()
self.layers = _get_clones(encoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
def forward(self, src: Tensor, mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
output = src
for mod in self.layers:
output = mod(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output该类主要通过克隆传入的编码器层并对其进行堆叠,实现了多层编码器的构建。每层的输入输出维度保持一致,这在后续的TransformerEncoderLayer中可以进一步验证。
TransformerEncoderLayer类深入
TransformerEncoderLayer由自注意力机制和前馈网络组成。其实现基于论文《Attention Is All You Need》,该论文首次提出了Transformer的概念。
class TransformerEncoderLayer(Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation=F.relu,
layer_norm_eps=1e-5, batch_first=False, norm_first=False,
device=None, dtype=None) -> None:
factory_kwargs = {'device': device, 'dtype': dtype}
super(TransformerEncoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first,
**factory_kwargs)
self.linear1 = Linear(d_model, dim_feedforward, **factory_kwargs)
self.dropout = Dropout(dropout)
self.linear2 = Linear(dim_feedforward, d_model, **factory_kwargs)
self.norm1 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.norm2 = LayerNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
self.dropout1 = Dropout(dropout)
self.dropout2 = Dropout(dropout)
def forward(self, src: Tensor, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
x = src
x = self.norm1(x + self._sa_block(x, src_mask, src_key_padding_mask))
x = self.norm2(x + self._ff_block(x))
return x
def _sa_block(self, x: Tensor, attn_mask: Optional[Tensor], key_padding_mask: Optional[Tensor]) -> Tensor:
x = self.self_attn(x, x, x, attn_mask=attn_mask, key_padding_mask=key_padding_mask, need_weights=False)[0]
return self.dropout1(x)
def _ff_block(self, x: Tensor) -> Tensor:
x = self.linear2(self.dropout(self.activation(self.linear1(x))))
return self.dropout2(x)在forward函数中,通过自注意力机制和前馈网络模块的运算,输入的张量经过两次加法运算后依旧保持了原始的维度,这也证明了TransformerEncoder中的层堆叠是维度一致的。
PyTorch中的激活函数
在activations.py文件中,我们可以看到PyTorch对几种常用激活函数的实现。这些激活函数在深度学习模型中用于引入非线性特性。
class PytorchGELUTanh(nn.Module):
def __init__(self):
super().__init__()
if version.parse(torch.__version__) =1.12.0 is required to use '
'PytorchGELUTanh. Please upgrade torch.'
)
def forward(self, input: Tensor) -> Tensor:
return nn.functional.gelu(input, approximate='tanh')
class NewGELUActivation(nn.Module):
def forward(self, input: Tensor) -> Tensor:
return 0.5 * input * (1.0 + torch.tanh(math.sqrt(2.0 / math.pi) * (input + 0.044715 * torch.pow(input, 3.0))))这些实现展示了激活函数的多样性和PyTorch在实现这些函数时对性能和准确度的权衡。
FAQ
什么是Transformer模型?
Transformer是一种用于处理序列数据的深度学习模型,具有很强的并行处理能力。其通过自注意力机制实现了对序列中每个元素的全局依赖建模。
PyTorch如何实现Transformer模型?
PyTorch通过nn.TransformerEncoder和nn.TransformerEncoderLayer等类提供了对Transformer模型的实现。这些类封装了自注意力机制和前馈网络的细节,使得用户可以专注于模型的高层搭建。
如何在PyTorch中使用自定义激活函数?
用户可以通过继承nn.Module类并实现forward方法来自定义激活函数。PyTorch提供了多种激活函数的实现作为参考。
为什么Transformer模型需要位置编码?
由于Transformer模型不具备处理输入序列中位置信息的能力,因此需要通过位置编码将位置信息显式地加入到输入中,以帮助模型学习序列中的顺序关系。
如何优化Transformer模型的性能?
可以通过调整模型的超参数(如层数、隐藏层维度、注意力头数等),优化数据预处理流程,以及利用GPU加速计算等方法来提高Transformer模型的性能。