

AI视频剪辑工具:解锁创作的无限可能

在使用应用程序时,遇到加载时间过长的“死亡旋转轮”现象时关闭应用程序的情况有多少次?在当今的数字经济中,许多组织依赖应用程序作为主要收入来源,性能不佳或死循环可能导致用户流失或收入损失。几乎所有现代应用程序都依赖 API 作为跨分布式系统、第三方服务和微服务架构的神经系统。在满足快速发布周期和频繁 API 更新的需求的同时,IT 团队还必须确保 API 满足服务水平目标(SLO)和性能要求,并主动缓解问题。
当数千甚至数百万用户向 API 发出多个请求时,仅依靠综合监控工具(依赖于采样或有限的 API 可用性信息)不足以进行精确诊断或提供有用的取证。同时,全面监控每一个方面会增加开销并延长平均诊断时间。因此,API 监控对于运营团队来说至关重要,是确保所有 API 按预期运行和执行的艺术与科学的结合。如果担心监控盲点或开销,可以参考以下关键实践,以消除对 sev1 警报的担忧。
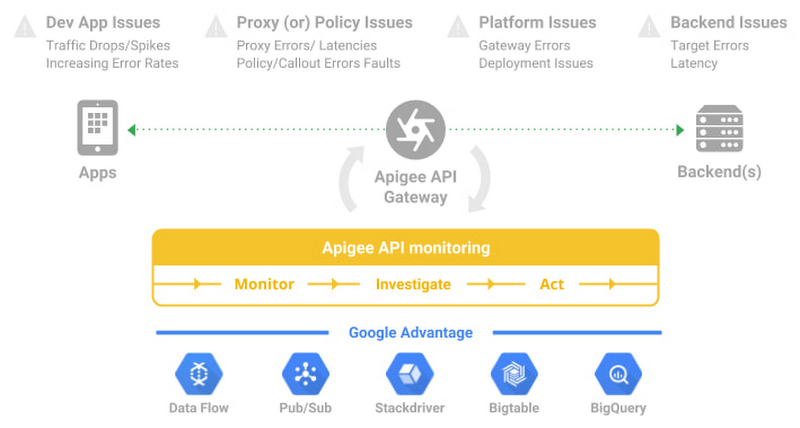
向值班工程师询问关键服务,他们通常会提到由于警报优先级设置不当而带来的额外开销。例如,假设一个分布式应用程序拥有 20 个 API。即使为这些 API 设置了跨延迟、错误和流量的基本警报监视器,最终也需要监控和维护 60 个警报定义,这是一项庞大的任务。为了在避免监控盲点和防止警报疲劳之间取得平衡,运营团队必须对所有事件有清晰的了解,并优先为支持关键流量的事件配置警报。
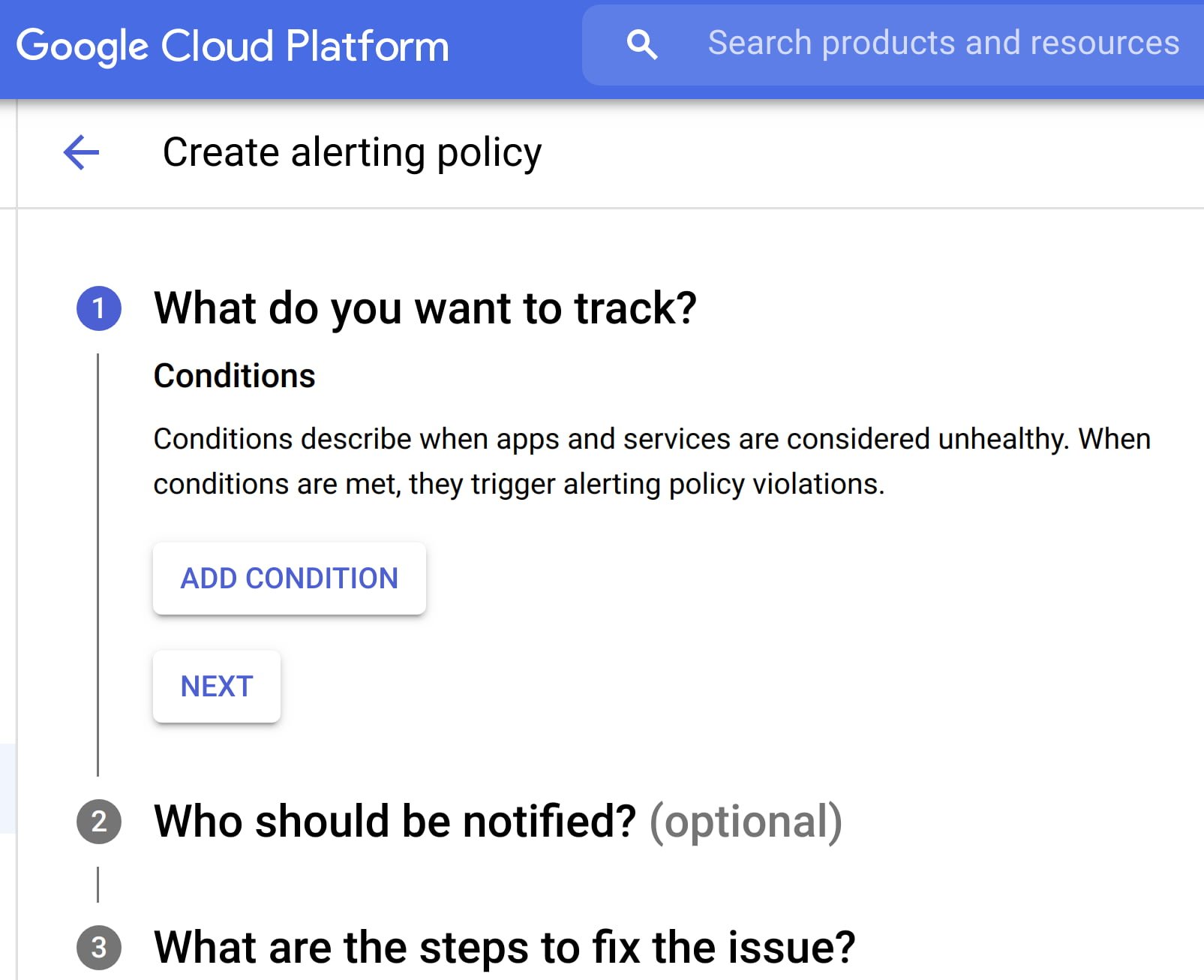
在定义新的警报条件时,应注重质量而非数量,每个新条件都应具备紧急性、可操作性,并且能够主动或立即对用户可见。每个警报条件还应包含需要用户积极参与的智能机制,而不仅仅依赖于自动化响应。Apigee 的 API 监控功能允许根据指标或日志创建警报条件,同时提供可操作的信息(例如状态代码、速率等)和详细的诊断手册。
在当今的多层系统中,一个团队遇到的症状(“出了什么问题?”)可能是另一个下游系统的原因(“为什么会这样?”)。即使某些事件不适合作为可操作的警报,故障仍需向下游系统广播信息,以减轻上游依赖性的影响。在这种情况下,投资于自动化警报、将多个事件分组到通知渠道以及事件跟踪是必要的。例如,Apigee 允许将警报通知集成和分组到 Slack、PagerDuty、Webhooks 等渠道。
现代生产系统不断演进,当前罕见的警报可能会变得频繁且可自动化。类似于工单积压管理,定期审查警报策略以识别新情况,并使用新的阈值、优先级和关联性来优化现有警报是必要的。Advanced API Ops 等控制工具利用人工智能(AI)和机器学习(ML)技术,检测与随机波动不同的异常流量,帮助定义更加准确的警报条件。
根据谷歌的《站点可靠性工程》一书,通过构建仪表板来实现有效诊断的案例表明,这些仪表板能够回答有关每项服务的基本问题,通常包括四种黄金信号中的某种形式——延迟、流量、错误和饱和度。然而,仅捕捉不同粒度级别的这些黄金指标可能会迅速堆积。与所有软件系统一样,监控可能成为一个无尽的复杂深渊,难以更改且维护成本高昂。在同一本书中,创建功能良好的独立系统的最有效方法是收集和聚合基本指标,并与警报和仪表板配合使用。
对于运行大型 API 程序并由专门团队进行监控的组织,可以利用 API 管理解决方案中的现成监控仪表板(例如 Apigee 的 API 监控)来收集有关 API 的实时见解,包括 API 性能、可用性、延迟和错误。在其他情况下,可以使用云监控等解决方案,这些解决方案提供整个应用程序堆栈的可见性,并通过丰富的查询语言对各个指标、事件和元数据进行可视化,便于快速分析。利用单一系统对应用程序堆栈进行监控不仅提供了上下文中的可观察性,还减少了在不同系统之间导航所需的时间。Apigee 客户可以默认使用 Cloud Monitoring,也可以通过 Cloud Monitoring API 与其他系统集成。
即使在收集和汇总指标之后,拥有有影响力的数据可视化以快速了解问题并在诊断过程中识别相关性也至关重要。在数据可视化中,关注过多的仪表板会导致学习曲线陡峭,并增加每次诊断的平均时间。例如,Apigee API Monitoring 提供以下标准可视化,以平衡简单性和效率:
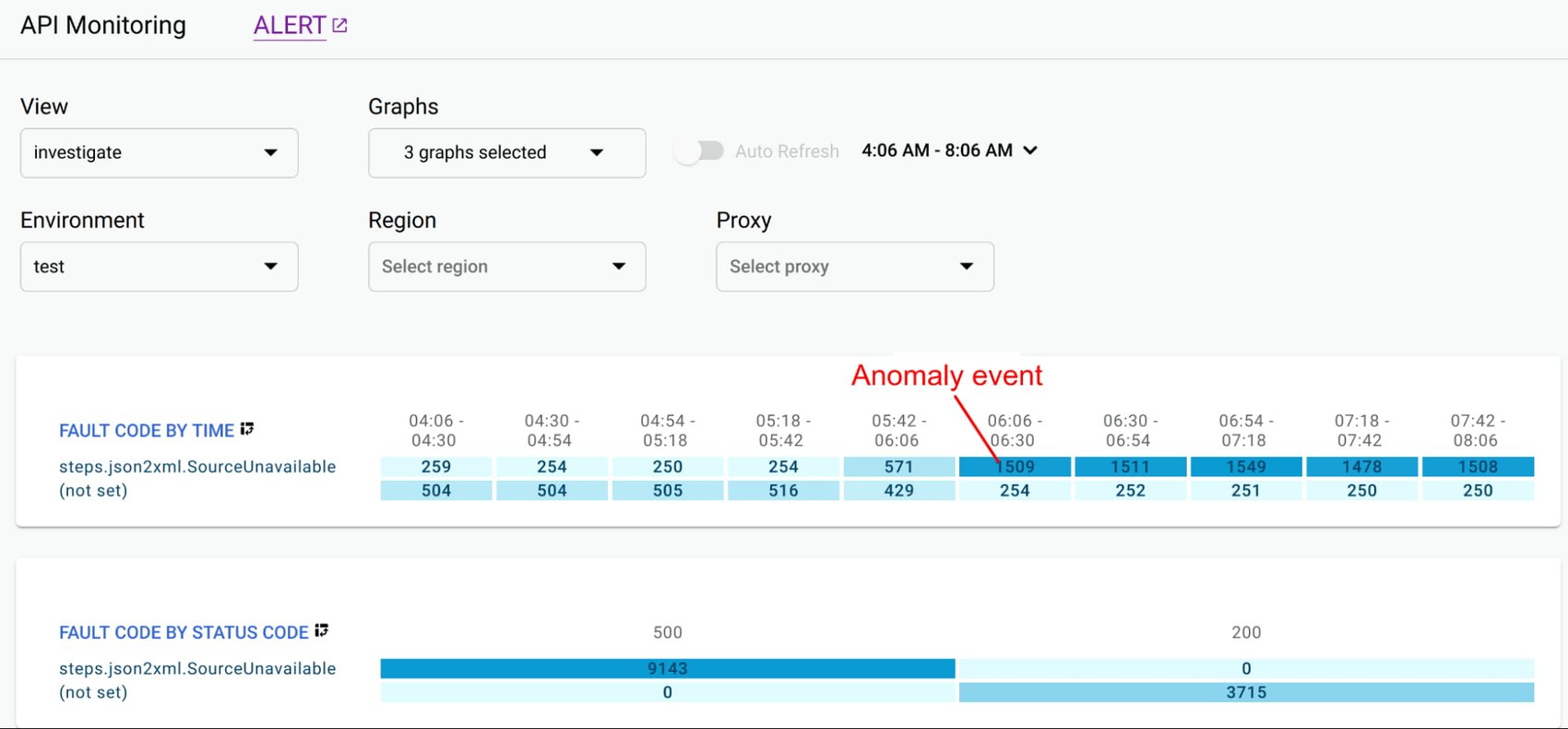
这些可视化工具使运营团队能够迅速识别和隔离问题区域,提高诊断效率,确保 API 的稳定运行和高性能。
现代应用程序开发加速了云、容器、API、微服务架构、DevOps、SRE 等技术和实践的采用。虽然这提升了发布速度,但也增加了应用程序堆栈的复杂性和故障点。例如,客户请求的缓慢响应可能涉及多个团队管理和监控的微服务,这些团队可能未能单独观察到任何性能问题。缺乏请求的端到端上下文视图,几乎无法隔离高延迟点。
在这种情况下,分布式跟踪成为 DevOps、运营和 SRE 获取服务运行状况、缺陷根本原因或分布式系统性能瓶颈等问题答案的最佳方式。组织应投资使用 OpenCensus 和 Zipkin 等开源标准来检测分布式应用程序。利用 Cloud Trace 等工具,这些工具具有广泛的平台、语言和环境支持,能够轻松从任何来源(开放仪器或专有代理)获取数据。
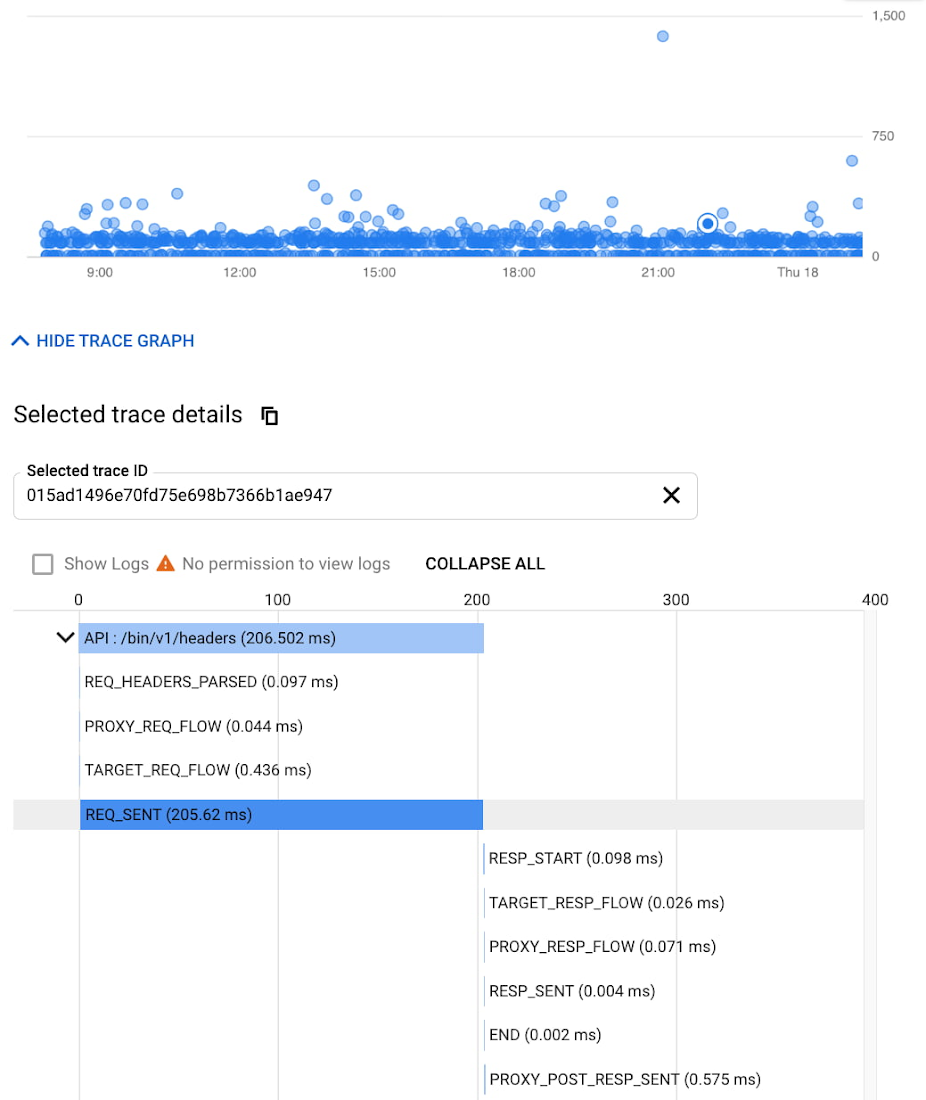
尽管分布式跟踪有助于缩小问题范围至特定服务,但在某些情况下,可能需要进一步的上下文来查明根本原因。例如,即使已将性能问题的根源隔离到 API 代理,识别正在执行的多个策略中的正确瓶颈仍然繁琐。Apigee 的调试工具能够放大 API 代理流程,深入探查每个步骤的详细信息,包括策略执行、性能问题和路由等内部细节。
一旦请求跨越多个微服务,分布式跟踪和调试工具便成为监控策略的关键要素。当分布式系统中的每个服务都生成跟踪数据时,数据量迅速增长,导致经典的“大海捞针”问题。在这种情况下,正确提出问题并在基于头部的采样(随机选择分析的跟踪)与基于尾部的采样(观察所有跟踪信息并对异常延迟或错误的跟踪进行采样)之间进行选择,变得至关重要,具体取决于应用程序的复杂性。
分布式跟踪不仅提供了全面的请求路径视图,还能够帮助识别跨服务的性能瓶颈和错误源。通过整合分布式跟踪,运营团队能够更快速地定位和解决问题,确保应用程序的高可用性和卓越性能。
Apigee 的 API 监控功能(基于系统内部公开的指标)与现有的监控基础架构配合使用,能够缩短平均诊断时间并提升应用程序的弹性。具体而言,运营团队可以利用以下功能:
使用 Apigee 的 API 监控,可以通过全面的控制保持高应用程序弹性,从而缩短诊断和解决问题的平均时间。
原文链接:3 best practices to reduce application downtime with Google Cloud’s API monitoring tools






