所有文章 >
API对比报告 >
2025年十大全球AI大模型评测榜单:DeepSeek、通义千问、Claude 3.7 Sonnet
2025年十大全球AI大模型评测榜单:DeepSeek、通义千问、Claude 3.7 Sonnet
随着AI技术的快速迭代,2025年全球大模型市场呈现“多模态突破、垂直领域深化、开源生态繁荣”三大趋势。本文综合技术性能、应用场景、生态支持等维度,对当前最具影响力的十大AI大模型进行深度评测。
一、评测维度与标准
- 核心技术:参数规模、多模态能力、推理效率
- 应用场景:通用任务适配性、垂直领域专精度(如编程、设计、交互)
- 生态支持:开源程度、API成本、中文语境优化
- 安全伦理:内容合规性、隐私保护机制
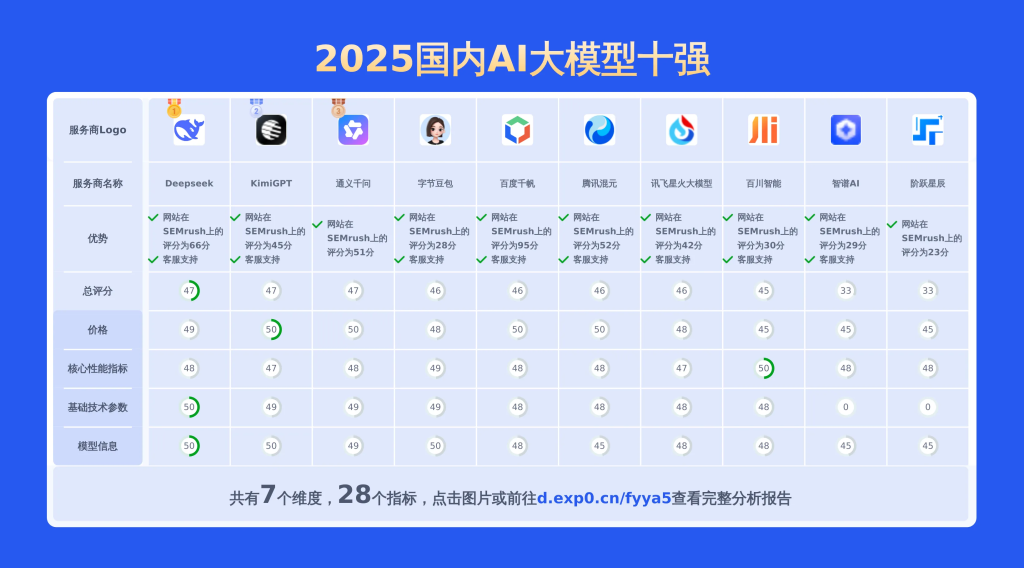
除了上面的对比维度,幂简集成还倾力打造了一份全面的对比表格,深度剖析了国内主流AI大模型的关键性能指标、API产品特性以及价格等核心要素。如果想全面了解各个AI大模型指标数据,点击查阅完整报表,以获取更全面、更深入的洞察!
二、2025全球AI大模型Top10
- 核心技术:混合架构(8个子模型协同),支持32768 tokens长上下文,推理成本较GPT-4降低40%
- 优势领域:复杂逻辑推理、跨学科知识融合、实时视频交互
- 典型应用:科研分析、金融预测、动态内容生成
- 局限性:API价格仍高于同类产品,中文语义理解弱于国产模型
- 突破点:编程领域断层领先,HumanEval评测得分91.2,支持10万token长文档解析
- 亮点功能:代码调试实时纠错、安全伦理约束内置
- 适用场景:软件工程、自动化测试、合规性文档
- 多模态标杆:原生支持文本/图像/音频/视频联合训练,百万级上下文窗口
- 技术亮点:电路图解析、工业设计图纸生成、跨模态检索
- 应用案例:智能制造、教育课件自动生成、影视后期
- 国产最优:综合性能逼近GPT-4.5,推理速度提升3倍,128k token中文长文本处理
- 开源贡献:连续开源五大核心代码库,推动国产AI工具链生态
- 场景适配:政务文档分析、芯片数据手册解读、金融研报生成
- 中文霸主:MMLU中文评测第一,情感识别准确率达92%
- 特色功能:文言文互译、地方方言交互、商业文案AI优化
- 行业渗透:电商直播脚本、文旅数字人、医疗问诊辅助
- 性价比之王:单位token成本比GPT-4低60%,支持实时网页翻译
- 技术突破:多语言混合输入、阿拉伯语/俄语小语种优化
- 企业服务:跨境贸易合同审核、多语言客服系统搭建
- 开源首选:700亿参数全量开源,支持4096 tokens上下文
- 生态优势:HuggingFace社区插件超2000个,硬件兼容性强
- 开发者场景:学术研究、轻量化模型二次训练
- 长文本专家:单次输入支持75000字,学术论文摘要生成准确率提升35%
- 创新功能:法律条文对比、专利侵权风险扫描
- 用户群体:法律从业者、科研机构、内容创作者
- 交互体验标杆:全语音实时对话支持,拟人化情绪表达
- 教育专精:数学题分步讲解、实验报告结构化生成
- 硬件联动:无缝对接学习机、会议系统、车载设备
- 图像生成王者:4K分辨率生成速度提升2.5倍,支持中文文字精准嵌入
- 商业应用:电商广告图定制、工业设计原型渲染
- 伦理机制:内置NSFW内容过滤,版权素材自动识别
三、趋势观察
- 端云协同:Gemini 2.0与DeepSeek R2均推出轻量化端侧模型,降低本地部署门槛。
- 工具链整合:OpenAI发布Agent API,实现网页搜索/文件检索/代码执行三工具融合。
- 垂直赛道竞争:编程(Claude)、教育(星火)、制造(Gemini)领域出现明显技术代差。
四、总结
2025年全球AI大模型领域呈现出技术突破与生态重构的双重变革。以GPT-4.5、Claude 3.7 Sonnet为代表的通用型模型持续突破长文本理解与多模态协同能力,而Gemini 2.0、DeepSeek R2等模型则通过原生多模态架构与开源生态建设推动行业应用落地。值得关注的是,中美技术代差逐步缩小,国产模型在中文语境优化与垂直领域(如政务、教育、制造)形成差异化竞争力,DeepSeek通过开源五大核心代码库构建起全球开发者协作网络,而通义千问、文心一言等模型已在跨境贸易、医疗问诊等场景实现深度渗透。
如果想查看各个AI大模型更详细参数评测数据,可以点击查看幂简集成提供的大模型对比指标数据。
相关文章推荐
我们有何不同?
API服务商零注册
多API并行试用
数据驱动选型,提升决策效率
查看全部API→









