

全面指南:API测试定义、测试方法与高效实践技巧

目录
一、视觉AI技术概况
二、感知理解系列技术
三、景点生成编辑技术
四、大模型系列技术
五、达摩院视觉AI开放服务
视觉技术是 AI 里应用最广,任务最多,技术方面非常复杂,发展非常快的一个AI的主要子方向。对人的各种信息的获取来说,视觉或者光线是信息获取最大的一个比例,在相关的 AI 技术中,视觉AI是人工智能的主要组成部分。今天分享的内容主要目录有几大块:
一块是视觉 AI 技术的一个概况,以及它的一个大体的分类体系。
同时会就其中的三个最重要的组成部分来讲解,最主要的第一个是感知理解类的,对世界的感知/识别/整治可能这一系列最基础的技术,也是视觉技术发展最早的技术。
偏视觉生成以及编辑相关的技术分成两大块,一个就是经典的,第二块就是相对于现在 AIGC 领域发展得非常快的大模型相关的系列技术。
另外,达摩院在视觉 AI 提供了若干种类的服务,不管是学术界、学生还是工业界,都可以直接来使用。
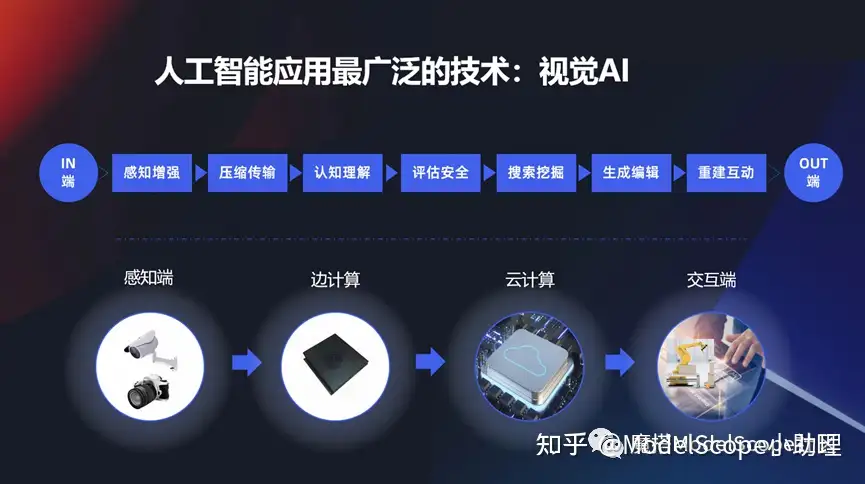
视觉AI
视觉应用特别广泛:从感知增强,感知到视觉最初的一个信息,然后到怎么把这些信息传输出去,对这些信息的一个认知和理解,它安全性、搜索,还有生成、编辑重建、 3D 重建以及互动这一系列的技术。它实际上在感知端,云计算,或者交互端,它是无处不在的,这些也是它存在的非常广泛的一个原因。
视觉AI 在各个场景的应用
比如说我们在手淘就可能会用到其中的一个图像搜索(一个视觉相关的技术),这是当前在视觉搜索领域最大的搜索引擎基础。当然也会在特别大的城市级别例如数字平行世界,这上面也有非常多的视觉相关的核心技术,同时也包括像医疗,养猪或者生产安全等等这一系列上面都会用到各种各样的感知、理解类的视觉技术。

当然还有很多大类,例如生产编辑类的技术,比如说早期的时候做的像 鹿班banner 的生成,或者服装设计、包装设计,视频的编辑、短视频生产等等,这上面用到了一系列的偏生产类的视觉技术,大家也能够感知到它在各个地方都有网上的一个应用。
“人”的一天中用到的视觉技术

用另外一个视角,比如说我们一个人一天当中从起床,到工作,到去玩或者社交等等一系列的动作中,其实也有很多能够用到视觉技术的地方。比如要打卡时要用自己的照片生成一个卡牌,从图片中抠出人像,然后要通过打卡机或考勤机识别是谁。或者除了识别人脸以外还需要识别有什么一系列的动作?比如说做一些仰卧起坐,俯卧撑等等这一系列的。
或者有时可能照片不是那么清晰,老照片做一些画质的提升或者美化或者变成数字人等等,这些都是在生活当中与视觉技术相关的。
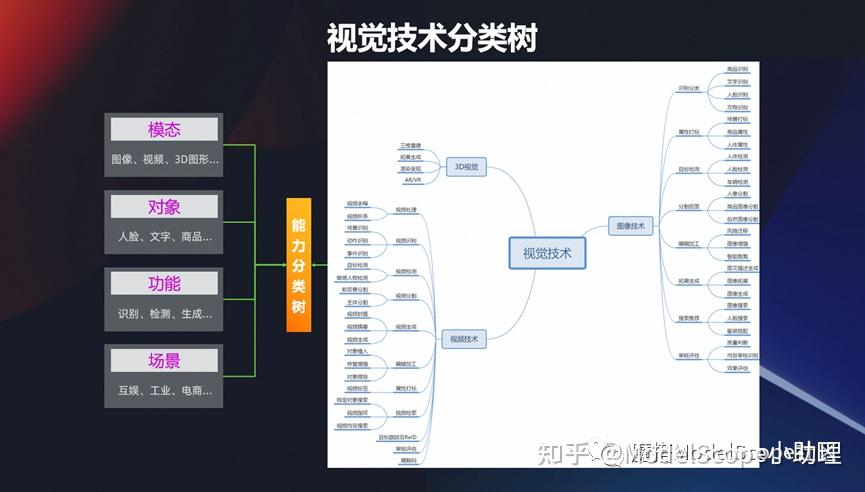
视觉技术分类树
前面是一些示例,是从行业/人类生活碰到的视觉技术,接下来我们也可以从这几个维度去分享,视觉一般有这么几种模态:
最早研究的是平面图像-二维的图像,如果二维图像我们加上一个时间轴的信息,变成有时间序列的,那就变成视频的模态。
前一阵子元宇宙特别火的时候,就是在原来 2D 这种维度上再加一个维度,它变成一个 3D 的一个维度,然后从这些维度其实可以区分这种模态的一个分类的方式。
从另外一个维度看。视觉真正的目标千变万化的,针对人,文字或者商品的都有,所以从这个维度又可以分出若干个技术。
还有一个最基本的,视觉技术是为了完成什么样的功能,用来识别/检测/生成还是分割?从这个维度也可以去区分。
技术想要真的在行业当中应用,还根据不同的场景,可以细分成互娱互乐,社交,工业或电商。
所以从 4 个维度,可以对视觉技术进行一个相对比较合理的分类。从视觉树中可以看到视觉在模态、对象、功能、场景上面有各种各样的应用,这是从分类的体系来说。
趋势:从理解到生产
可以看到,人一出生而首先我要认识这个世界,理解世界。像读文章要先能够读懂,到后面可以写文章,然后可以去修改我的视觉内容,可以生产这些视觉内容。所以趋势肯定是从先理解,再到生产。
最近大家关注 AIGC 的内容是偏生产编辑这一类的。
趋势:从小到大,从单到多,从闭到开
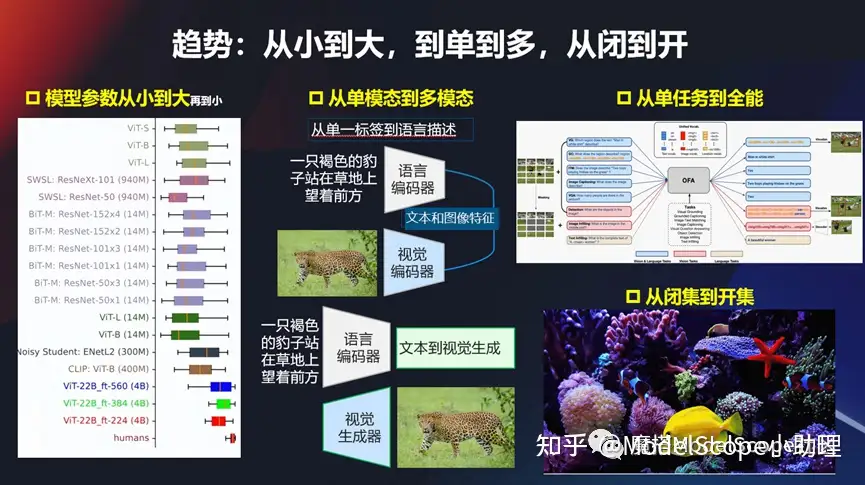
(1)从小到大
另外一个趋势,像现在各种各样的模型,从早期的比较经典的、比较小的模型,到现在的模型越来越大,像初期的比较经典的 VGG 的 ,到现在 VIT 的再到现在多模态的这种技术,发展得越来越快,所以这个参数量也会越来越大。从万级别、百万级别、千万,再到亿,还有更大万亿级别的,模型参数从小到大,也是当前的一个趋势。
(2)从单模态到多模态
从单模态到多模态,尤其大模型开始流行起来以后,是非常典型的一种趋势。早期给一张图,打一个标,或者给个分值等。现在基本上是图相对自然语言的描述,作为训练模型的输入,同时进行encoding,然后再来进行训练。现在大部分都是文本,视觉或者图像这一块的多模态。当然在对声音或者对其他的东西也可能是多模态的方式。总而言之,从单模态到多模态这个趋势非常明显。
(3)从单任务到全能
以前只解决检测问题,或者只解决分割问题,甚至它只能解决对某一个特定对象,特定场景的。但是从不久以前,阿里做了一个新的模型开始,就开始强调全能/多功能的模态,既可以做视觉的任务,也可以做文本的任务等等。所以从单任务到多任务的进行,也是一种趋势。这种趋势最后会发展成什么样的状态?是不是真的能够从一个全能/全任务的模型解决所有问题?这个可能有待考察和发展。
(4)从闭集到开集
另外可能还有一个经常会遇到的方式,以前的模型或者数据集,只能在一些闭集当中去做,比如说我们在训练得到它的标签就是在这个集合当中,当出来openset 的一个问题,它能不能解?其实现在这个趋势也是比较明显的,尤其是像现在的多模态大模型,其实它很多的时候能够解决就这种这个问题,可以解决以前在训练的过程当中或者是闭集的状态走上一个开集的状态,这也是其中一个趋势。
趋势:基于知识和反馈的训练

在训练的时候,可能需要把这种人的知识以及反馈,例如像 ChatGPT 半监护,半反馈的强化学习(RHLF)的方式加入到训练当中去,这也是一个趋势,使得我们的模型的表征能力越来越强。
视觉感知理解技术
事实上视觉感知理解,应该是人类获取认识这个世界最主要的最基本的任务。
视觉理解

例如最基础需要先识别上方图像中有什么东西?想知道是个猫还是个狗?然后要知道这个猫和狗在图像当中的位置,这是更进一步。当要知道每一个像素是什么东西的时候,就要做分割的问题,这是最经典的几类任务。
当然视觉理解还有一些表征或者识别行为等等一系列的任务。总的来说,基本上它的模式是输一个图,然后出来一个标签,一个 tag 这种方式,也可能是一个 score 或者是一个数字等等,所以我们可以从日常的生活当中发现非常多的有关于识别或者检测、理解相关的一些任务。
人的识别及检测

最经典的是去地铁站坐车或者坐飞机,打卡等等,或者要识别一个人,或者识别有多少人等等这一系列的任务,都是属于这类的。
生物识别系列模型
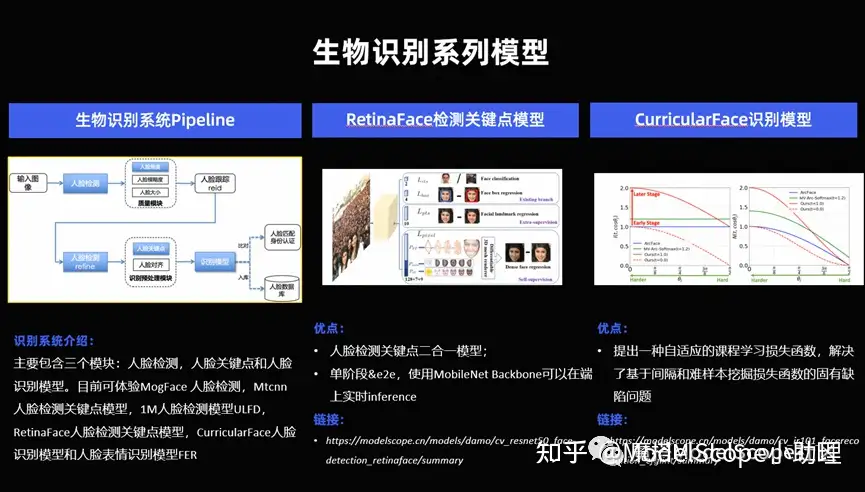
识别系列模型其实有很多,这里只举个几个最典型的,比如说对人脸的一个关键点识别, 1: 1 的识别或者 1: n 的识别。
(1)对人脸的识别来说,有三个关键的核心的模块,对于人脸的检测,人脸关键点的识别,人脸的识别本身。当然还有一些前序的,例如人脸的质量,图像质量的纠正,还有事后的等等也有非常多的模型,在人脸这个最经典的研究的最早的视觉任务,上面也另外沉淀非常多的技术。这个技术可以在 Model Scope 的官网去访问。

(2)分类检测上面也有非常多实际的任务可以去研究。

(3)在工业场景下面,例如给一个电池版,或者给一个果冻,能不能检测到其中有些瑕疵?这些都可能是现实当中碰到的问题,这可能是检测问题,也可能是分割问题,或者是识别问题。这就是对这种工业场景下面的一个场景理解。

(4)达摩院也开放了DAMO-YOLO这个非常厉害的检测模型,它可以兼顾速度和精度同时去识别。大家都知道,视觉任务做到最后都面临精度、速度、成本等等的兼顾平衡,只有这样的话才能够使得这个模型真正的能够落到行业当中去,所以这是经典的检测模型,可以对单个人检测,也可以对多种目标、多种物体、动态的、静态的等等都可以去做检测。

(5)延展一下,自然图像例如手机照片,是普通的 RGB 图,但事实上还有很多,例如CT 图还是 X光,MRI ,超分,超声或者是 PET 等等这一系列的针对物体或者人体内部的扫描结构得到的影像,也算一种特殊的一种视觉。在这个层面也有很多事情可做,比如说对各个器官的一个分割/检测/识别,对病灶/病的种类等等这一系列,这些都是对人的内部,外部的感知理解的一系列的视觉技术。

(6)前面举的例子都是对静态的识别,同时可能对一个动态的视频,想要知道这个人做什么动作,识别出来是什么动作,以及做的标不标准,或者对人进行一个教学,做这个动作做得好不好?做了多少个?等等这一系列技术其实就是对人体的关键点,以及对人体连起来骨架,基于这个去做的动作识别。这个可以用于做一些app,或者记录今天做了哪些事情等有意思的应用。

(7)在城市级别或者是交通感知,交通事件等也有很多的视觉技术可以使用,比如识别车或者是交通是不是有拥堵,事故,违法等等都是视觉技术可以发挥价值的地方。此类发挥价值是通过城市级别,或者交通系统级别,对实时采集到的摄像头的数据,进行分析理解。所以这块除了算法技术以外,实际上还有一系列系统级的工程技术去配合的系统。

分割抠图-难点
除了前面的识别检测以外,还有技术相对不太一样的地方。比如说可能需要针对图像像素点是属于什么类别的检测识别问题,实际上属于分割抠图的问题。
如果经常使用PS等,就会经常使用到它。比如面对复杂背景/遮挡/发丝/或者是透明材质,像婚纱等等这一系列都是在识别当中会遇到的挑战。这些挑战 还有一个很大的问题在于标注成本非常多,导致高质量的数据本身也会严重不足。
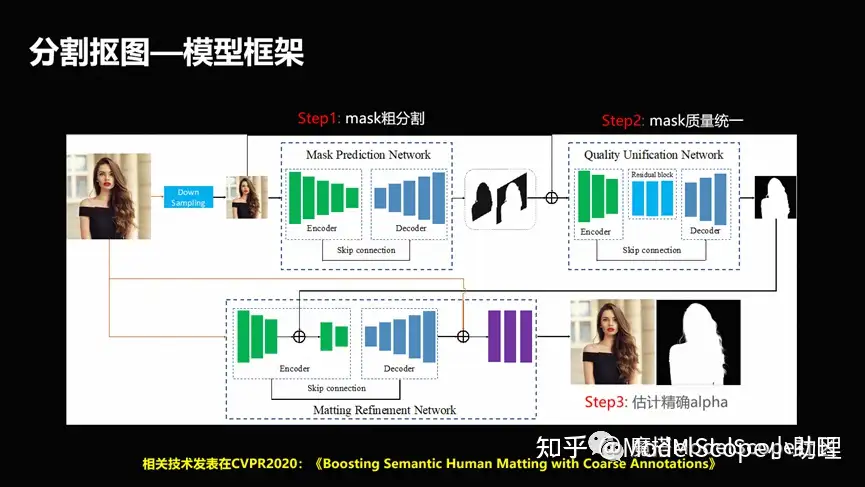
(1)分割抠图-模型框架
在解决这个问题上也有很多的方法,这里只列出一个例子。例如解决高质量的标注语料问题时,设计了粗分割精分割相互结合的方式,去促使这个方法可以快速的既能够兼顾粗分割,就是低级分割所带来的图像数量比较多,同时我们又能够利用精分割的质量比较高的情况,使得这个分割能够兼顾效果和数量上的统一。
(2)分割抠图-效果展示
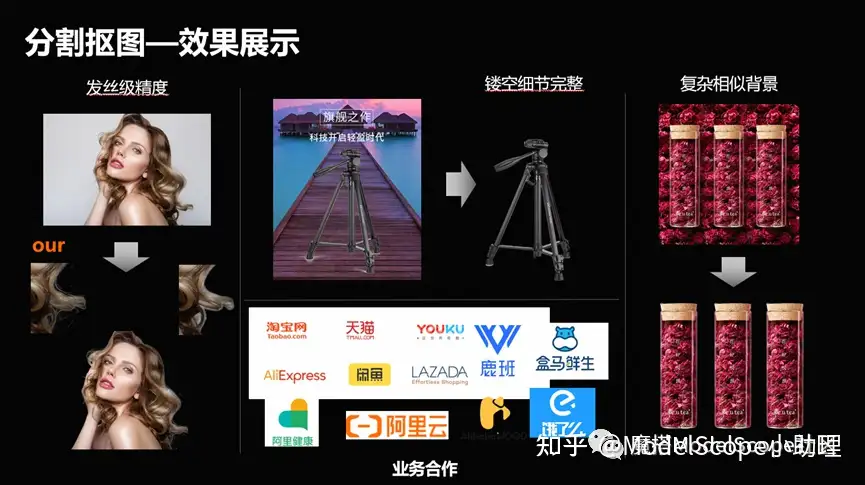
发丝级别的这种精度,或者图像它是镂空,或者是它跟背景相似的时候,怎么把它分割出来?这是一个非常有技术含量和应用面在里面的事情。
(3)分割抠图-图元解析

同时还有一个非常有意思的分割,是更复杂的图源解析的一个问题。如果大家用过 PS 就应该知道,一张图如果是 PSD 结构的话,它实际上是多个图层合起来变成一个图像的。
但反过来给一张图,你是否能把里头的各种元素,各种图层反向识别出来,分割出来?这就是一个对图像的反向解析的过程,这是相对更复杂的一个对图像的理解的问题。
感知理解系列开放模型
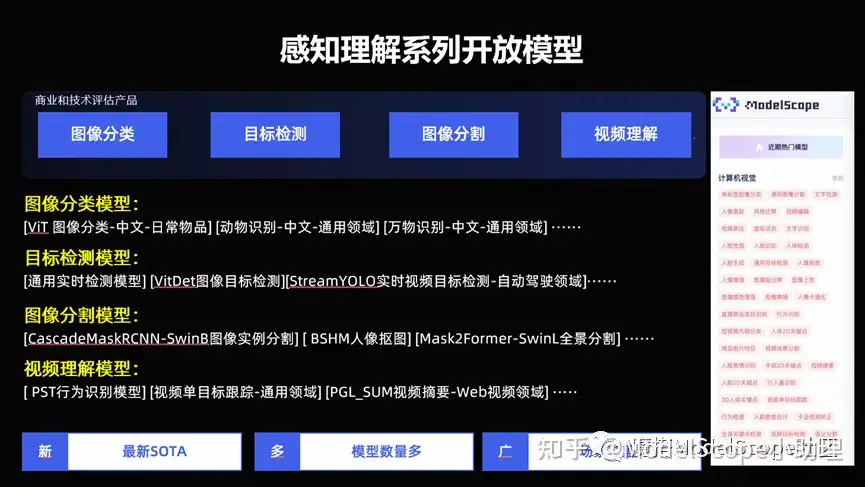
在 ModelScope 上面开放了这么几大类,包括分类、检测、分割,还包括视频里的一系列的理解能力,这个是最基础的一系列能力。
当然另外一系列能力例如先认识世界、感知理解到了世界,然后这个时候我要改造或者是生成我们的视觉信息,那么我们就可以归结为生成编辑类。
经典生成编辑技术
编辑类的大家可能知道,由于现代 ATC 大模型技术发展,可以把它分成两个阶段,一个阶段是经典的生成编辑技术,这里主要是指这一块。
视觉生产的定义
相当于输入一个视觉,然后出来一个视觉,产生一个新的视觉表达,它产生的不是一个标签,也不是一个特征。而且它输出的和输入的还不一样。
比如说经典的我生成一个从 0 到1,或者是我有了一个图,我生成更多的图是从 1 到n,或者是我有一个摘要,或者是一个升维,包括前面的平面图像到视频,或者是从视频到 3D 的图像,当然还有一些从 a 到b 增强/变换,或者我把两张图合到一起,或者是想从一个视觉当中移除一个东西。
视觉生产通用框架
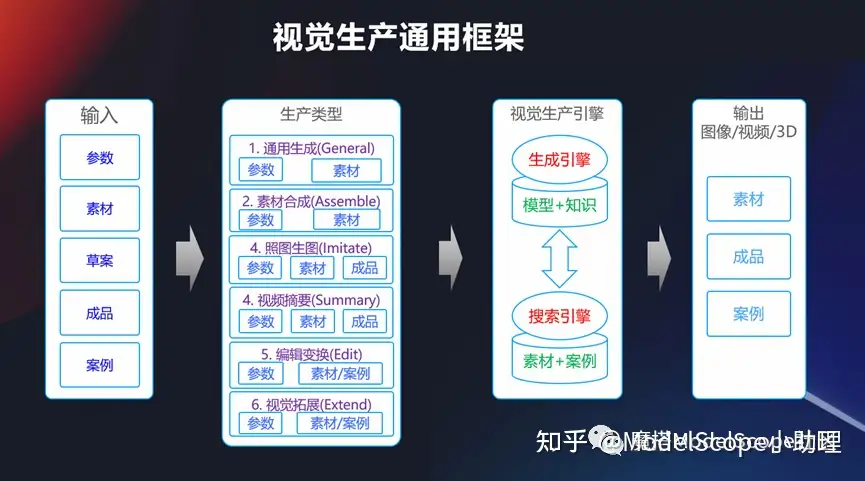
从上面可以看到,视觉生产实际上是包含了非常多的任务,这其中最经典的,是一个通用的框架,我们可以输入参数、素材或者是各种各的成品,当然也可以在早期的时候通过模型+知识的方式生成引擎去做,也可以通过一个搜索引擎去做,找相似的素材和案例,去产生一个输出,所以这是个通用框架。
视觉生成技术发展
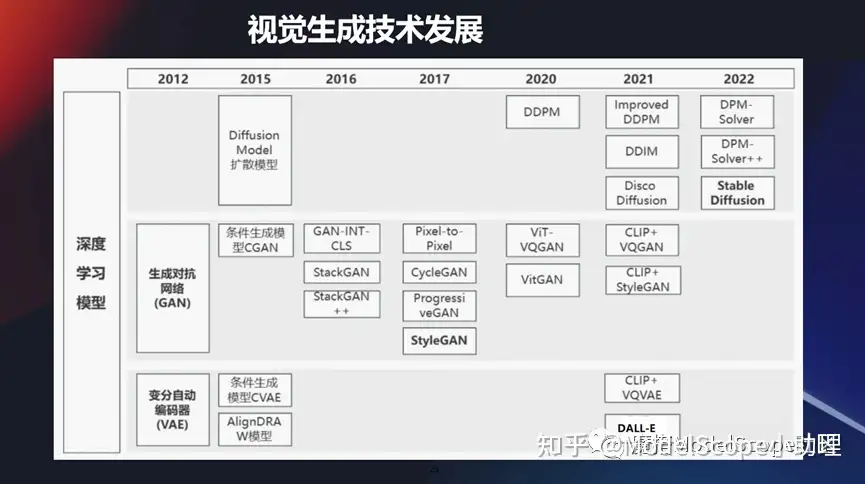
当然视觉生成技术其实发展的时间也比较长,虽然它跟理解力技术对比还是在之后的。包括我们最早些时候,大家应该知道,大概11年 12 年的时候,一个非常火的模型叫 GAN,它可以通过对抗的方式,通过判别器和识别器然后对抗的方式来获得图像的生成。
它是早期的一个最经典的生成式模型。当然之后也有很多的技术在发展,像 GAN 技术它也会有很多一系列的发展,包括条件生成CGAN 或者是styleGAN等等这一系列技术在当前还在不断地往前发展。
当然现在也有两大类非常火的技术,像那个 VAE 技术,变分自动编码器,这里面也有条件生成。运用的面最广的,当前最火的是基于扩散模型方式的一个生成方式。
视觉生成-五个关键维度
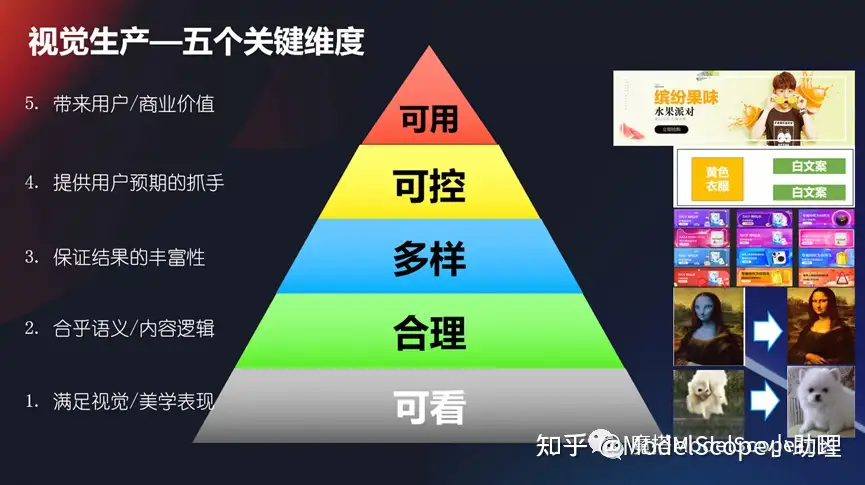
要想使得视觉生产技术或者生产技术能满足业务的需要,那么我们应该在哪些方面来衡量它呢?
(1)比如说我们首先肯定要满足视觉或者美学的一个表现,是可看的,不能说我们生成一个东西你看起来都不认识或者不知道,那这个肯定是没法满足的。
(2)第二个它相对来说要合理,它要合乎语义的逻辑或者是内容的逻辑,这点也很重要,我不能说生成个a,结果你给我个b这也不行。
(3)还有一个你要保证你结果的丰富性,它是个多样可变的,你不能说每次生成的都一模一样,它也是一个不是那么可用的状态。
(4)还有它要是可控的,我想要生成什么样子,它就要生成什么样子。不能说生成a,结果它生成b,或者说我没法控制它,这个也是不成的,所以我们要提供一个给用户预期的抓手。
(5)最后达成一个目标,使得这个结果生成结果是可用的,它能够给用户带来使用价值或者商业价值,这是最核心的。
所以从可看、合理、多样、可控和可用上面这几个维度来看,我们可以回过头去看一看我们的视觉生产这个过程,这个技术是不是合理的。
视频增强相关能力
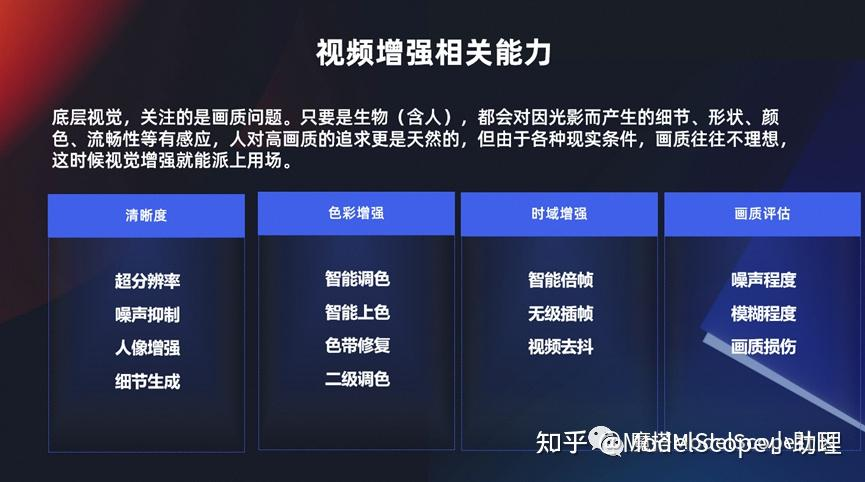
前面介绍到有若干种视觉生产,这里介绍两个最主要的。第一个就是视频增强技术,实际上是满足从 a 到 b 的一个过程。如果大家了解过底层视觉,就是比如说我一个视觉,那么我一出生以来,我不管是人,一只狗,或者是一个猫,或者是只要有眼睛能感知光的,那么它可能就对这个图像的清晰度、细节或者色彩或者它是否流畅等等这一方面东西它天然的就能够感知得到,这就是所谓的底层视觉。
对底层视觉我们永远是追求更高画质的视觉表现,包括我们在清晰度上面更清晰,然后在色彩上面要更鲜艳,然后在流畅度上面要刷新的更快,这些都是跟视频增强相关的一系列能力。
图像与视频的画质问题

视频增强的问题从哪来的?其实有很多,比如从采集,运输处理,还有存储等等各方面,由于我们早期的时候在拍摄图像,它的设备/环境/其它的东西导致的各种各样的内容不够,甚至更早期的时候图像只有黑白等情况。这些情况基本上可以分为三大类:
(1)一大类是细节损伤,分辨的不够,或丢失了一些信息,这是第一类的。
(2)第二类色彩表现不好,以前可能是黑白的,后面只有8bit,或者就是马赛克形式,10bit的像素的表达,所以这种色彩的表现,有可能是RGB三个通道,也可能ARGB的四个通道。这一系列也是属于色彩表现添加的问题。
(3)或者可能是跳帧的,它连续性不够流畅等等。从这几方面来说的话,从传统的图像处理理论当中来说,想要把这些问题修复其实是非常困难的。所以也就是相当于在这几个方面,可以有很多的技术去专门攻克这一块。
空域增长-超分
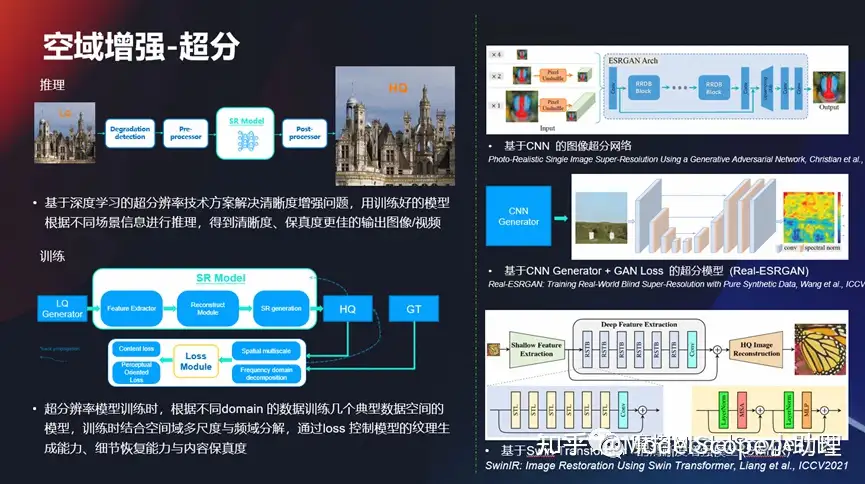
在空域增强上面,在细节上面做一些超分的任务,超分任务其实是比较典型的底层视觉的问题,而且这块问题其实发展的时间也非常长了,从早期的基于 CN 的图像超分,一直到现在利用这种domain手段去做这种增强任务,所以这一系列的技术也在不停地往前发展,使得的效果也不断地去往前提升,使得从早期的720P,到1080P,然后到后面的4K、2K,或者甚至到现在的 8K 的视频,细节越来越丰富,这是最基本的问题。
色彩增强示例

另外色彩,有时可能不是那么通透,或者是带有一点点灰蒙蒙这种感觉,使得从8位的一个像素深度变成一个 10 位,或使得色彩表现力更丰富。上图这里应该是从 SDR 到HDR,大家用过电视机或者是比较好的一些手机都支持 HDR 的方式,但早期的时候很多是都是 SDR 的格式,所以在这些方面都可以做很多的事情,使得即便当时的视频质量不是那么好,经过 AI 的处理以后它可以变得更好一些。
图像去噪开放模型
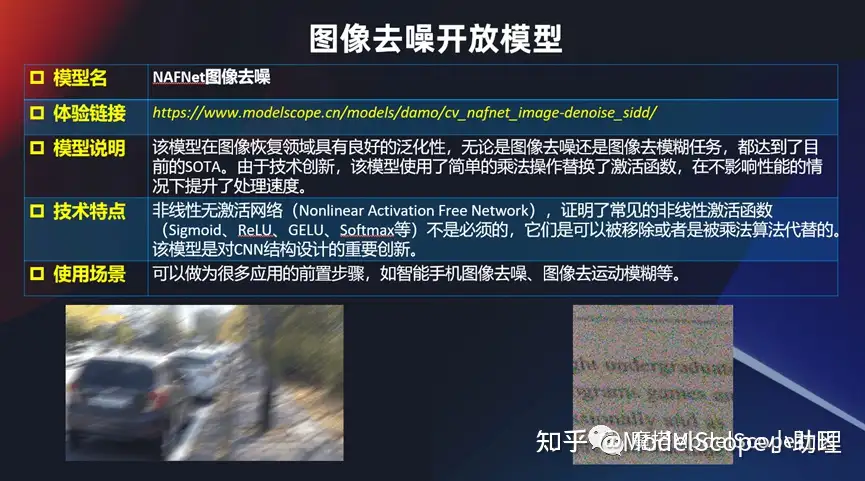
同时也开放了一些其他的跟底层视觉相关的一些模型或者算法,比如说两个最经典的。图像拍的特别模糊,或者是噪声点特别多,那么这个时候能不能有个办法呢?其实也有一些专门的办法去解,比如不管是对文字的噪点的去除,还是对拍摄过程当中因为运动模糊带来的一系列的问题都可以去解。
人像增强开放模型

还有针对人像的增强,在github 上很早就开放了GPEN 人像增强模型。基于 StyleGAN2 作为 decoder 的方式嵌进去的一个方式实现的。在这一块的话可以对一些老照片来进行修复。
例如早期拍的家庭合照或者早期的一些影视剧,质量不好的时候可以使用这个模型,把其中相对于人的这块识别做的更好一点。
生成编辑相关能力

增强相对来说偏底层视觉相关的,但是生成编辑还有非常多的其他任务。包括对这个风格变化,或者是从 0 到 1 生成一个东西,或者生成以后对它进行一个增、删、查、改等等一系列的视觉能力。
视觉编辑开放模型
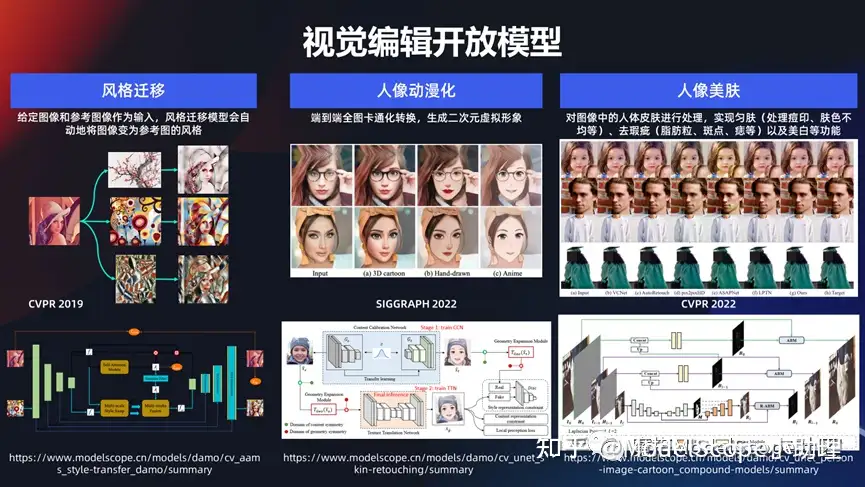
如果接触到玩得非常火一系列的风格变换,给个图变成各种各样的风格,这些风格当然很多时候都是色彩+内容的变化,还有卡通画:把一个正常的人变成一个各种各样的模式的卡通画,或者是变一个风格。是比较清新的风格?还是迪士尼的风格?还是 3D 的风格?等等。
或者一个人的皮肤不是那么好,但是又想使这个人美化以后还能保持真实的感觉,这是相对比较高级的美肤能力,这一系列都是属于视觉编辑。一张图生成各种文的风格,这些风格也可能是日漫风、 3D 风、手绘风、迪士尼风,而且这一个当前买可以定制化的。

比如以上是一个非常受欢迎的一个例子,例如给一张图,可以生成各种各样的风格,这些风格可能是日漫风,3D风,迪士尼风,或者还可以定制化,例如我希望得到一个风格,那么可以上传若干个风格的图片,然后根据这几张图片提取其中的一个风格特性,同时生成这种方式。所以这也是玩法非常多的一个方式,如果大家去试用会觉得很有趣。
电商海报设计
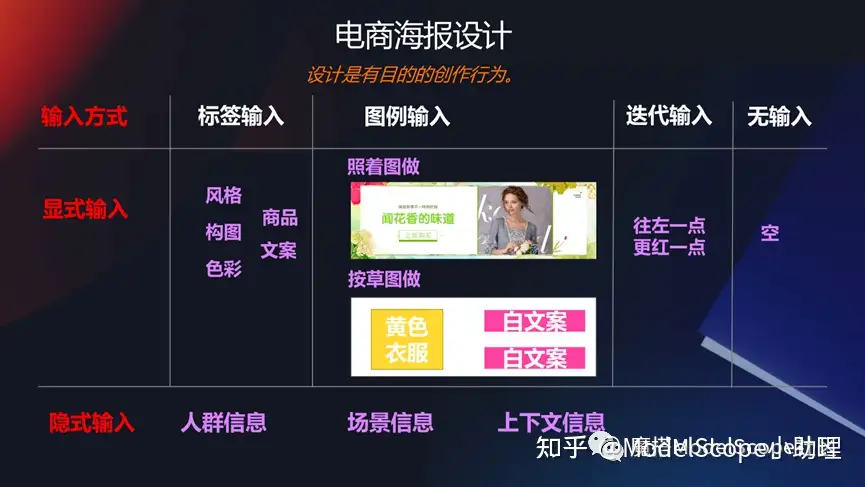
在一些特定的领域,比如说电商的海报领域,能不能生成一些banner图/广告图?如果大家早期关注过阿里的鹿班这个产品,就应该关注到这其中的一系列。
例如可以通过给一个商品主图以及一些文本,去生成一段背景,同时这个背景还能够非常好的和前景以及商品相互融合起来,包括这些细节也是非常使用的一个技术,是非常经典的生成编辑的能力。
视觉大模型技术
随着大模型技术的发展,以及算力,还有数据规模化的不断发展,还有多模态技术等等这一系列。前面的这些经典的像感知理解类的技术,或者生成编辑类的技术,现在都在往前发展。
视觉统一分割任务模型:SAM

对这种感知理解的技术,大家如何关注?前不久,Meta公司发表 SAM,通过模型可以对所有视觉分割任务进行统一的处理,且是zero shot 的问题。他可以对看得到、认识到之前识别不到的一系列目标对象进行识别分割,且能够达到精准的像素级别分割。这块它也可以在视频当中去做,比如我们看到视频当中有一个人,就能够把他检测出来,并且能够给出识别。在 3D 领域也都是可以去做的。
所以这个模型在两个地方很有意义,第一个解决很多目标中的分割问题。另外数据量也是非常庞大的。训练图像应该有 1000 多万,做一个 billion 的一个 mask, 去做监督的训练。
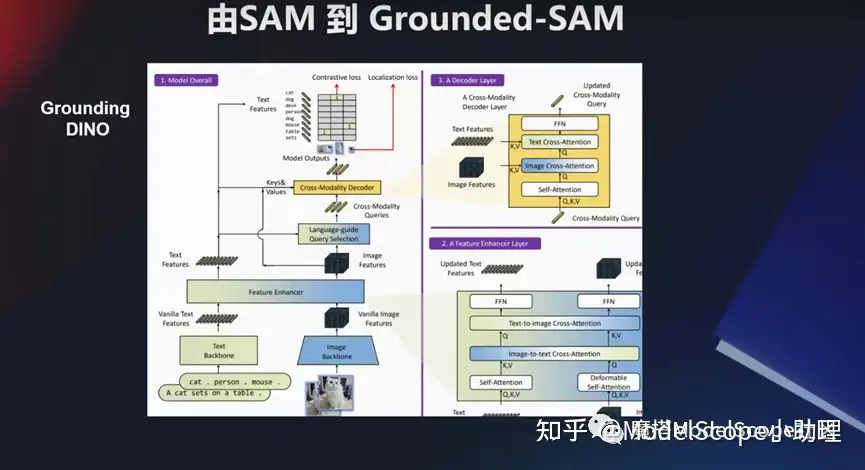
这个模型也可以结合其他的模型做综合玩法。比如说像国内 grounding DINO 这个检测模型,然后跟这个 SAM 模型结合起来。还可以把一些像生成类的模型,例如Stable Diffusion,甚至 ChatGPT 这种领域的一些问题,或者语音领域的一些问题。可以结合起来去做一些事情。
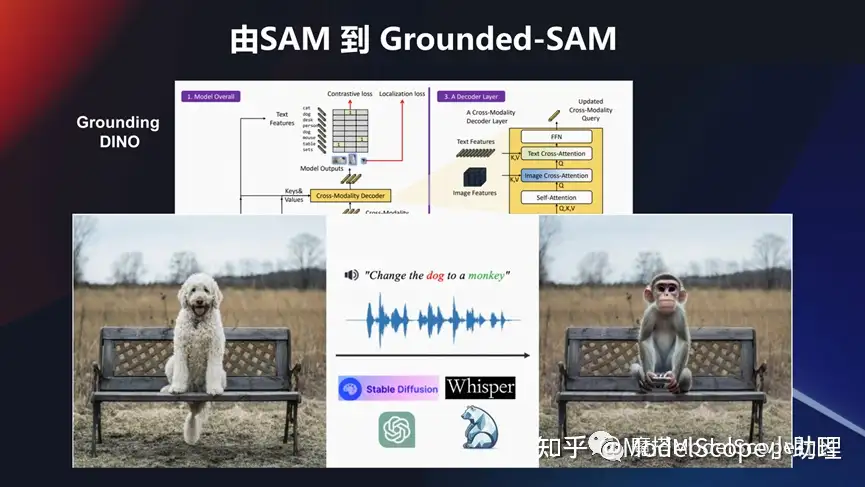
例如希望把这个坐在椅子上面的狗狗换成 一个猴子, change the dog to a monkey,这也是一个多模态的输入,结合这个分割模型,把这个狗识别出来,同时结合生成的技术,把这个前景的这个目标换掉,然后变成一个新的猴子这个目标,这也是非常有意思的一个玩法。
文生图大模型发展
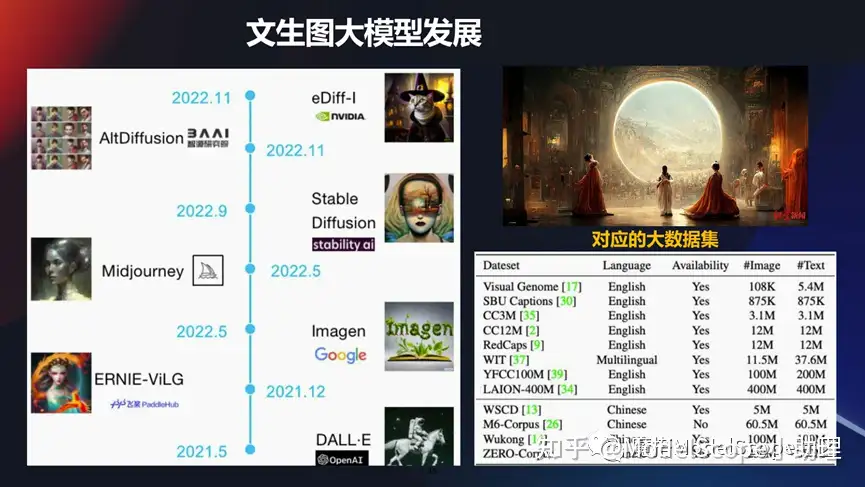
像文生图这种模型,其实最近是特别火的。右上角这一张图,是MJ公司一战成名生成的一个图像。文生图这个领域越来越成熟,应用越来越多。同时也有非常多的经典的大模型的发展,包括早期的像 DALLE,到谷歌的imagen 方法,然后到现在最火的形成Stable Diffusion 。
这其中国内外也涌现了一批比较知名的专门在这个领域做,且做的得非常好的产品。业界中公认的做的最好的是Midjourney。
国内像文心一格,包括阿里也发布了若干个相关的一些文生图的大模型。当然想要把这些模型训练出来也是非常不容易的,这里也举例了干个大数据集,如果真的想要 去训练起来一个大模型,我们可能要消耗好几百块的 GPU 卡,而且是需要训练很长的过程,其中除了算法本身以外,在算力和数据方面还有很多工作要做。所以要想做这一类的大模型其实是一个系统工程的问题。
“通义”预训练大模型系列

阿里发布了一系列的通义预训练大模型,包括M6-OFA这种包括文生图,这系列的基础模型都可以访问。
我们关注的是跟视觉领域相关的技术更多一些,在自己的这个文生图大模型上面,其实是基于一个知识重组的大模型训练。
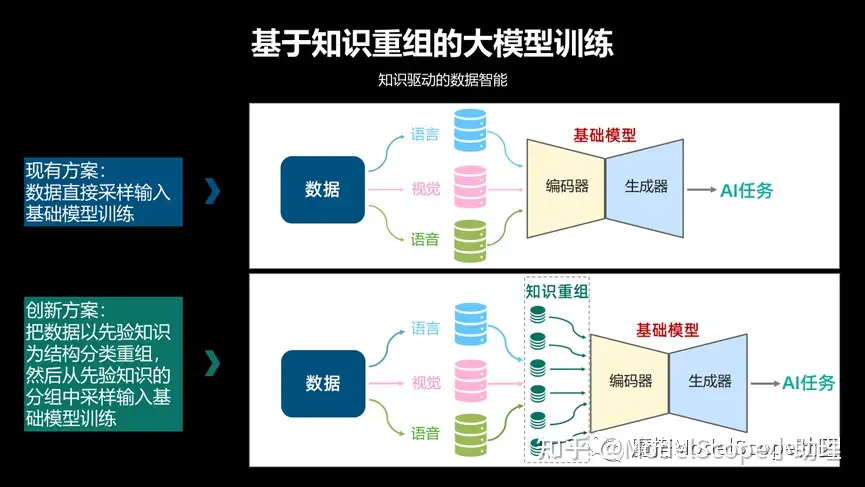
相当于把知识信息这种先验信息,不管是语言的,视觉的或语音的,通过知识重组方式或者分组的方式作为编码器输入训练得到大模型,此时在规模越大的时候会产生更加良好的一个效果。

上图是举的几个例子,像生成这种动物或者 3D 的动物,或者跟人相关的,卡通画的人相关的。用的比较多的可能是国外的Midjourney或者是开源社区的 Stable Diffusion,此类文生图的大模型用的比较多,同时也欢迎大家去Model Scope 上使用。
基于扩散模型的图像超分
除了文生图以外基于扩散模型,其实还可以带来对于其他任务的一系列的增强和更新。比如说我们在前面说的图像超分其实也可以利用这种扩散模型去做,使得它的效果能够变得非常好。

这款它有自己特定的问题需要去解答。比如说在这种任务上面,我们怎么能够使得这个成本降低,速度加快,然后能够真的可以部署?这是一个现实的问题,因为大模型在生成的效率上面和消耗上面还是有比较多的问题。另外很多的任务可能不一定需要文本引导或需要多模态,它可能就是一个纯粹的视觉领域的问题。这也是在这个领域尝试的用大模型技术去解决的问题。
可控的图像生成:ControlNet
还有一种情况,我们希望以一种更可控的去做图像生成。去年年底的时候出的ControlNet模型在这个领域目前应用最广的,它可以对我们生成的目标进行一个预期的控制,无论是在轮廓上面还是在骨架上面、动作行为或者色彩上面,都可以通过这种方式去做。
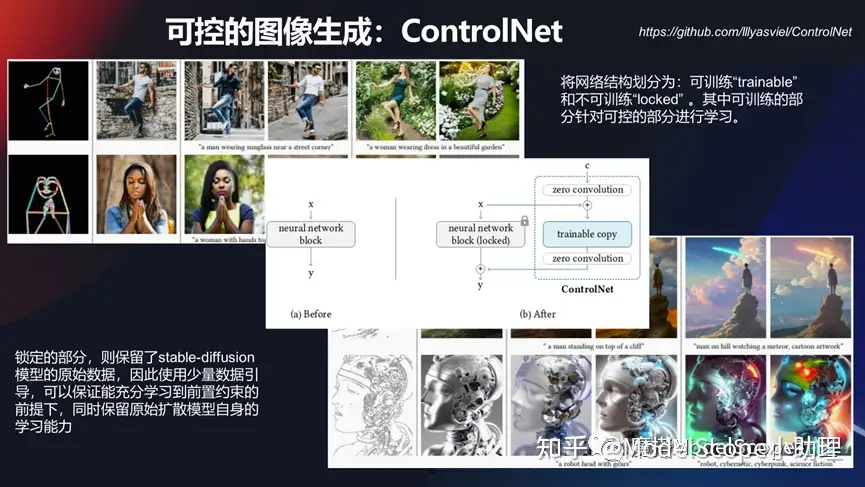
其实它是将某个结构分成可训练的部分和不可训练部分,然后分别去针对这种模型进行充分的迭代,既能保留非常明显自身的学习能力,同时又能使得约束及控制存在。
可组合图像生成:Composer
当然在可控的投入量生产我们在达摩院上面也做了一个非常有意思的研究,此研究的核心特点是可以支持多个条件引导的图像合成,可以更加可控的生成方式去完成图片可控的生产。
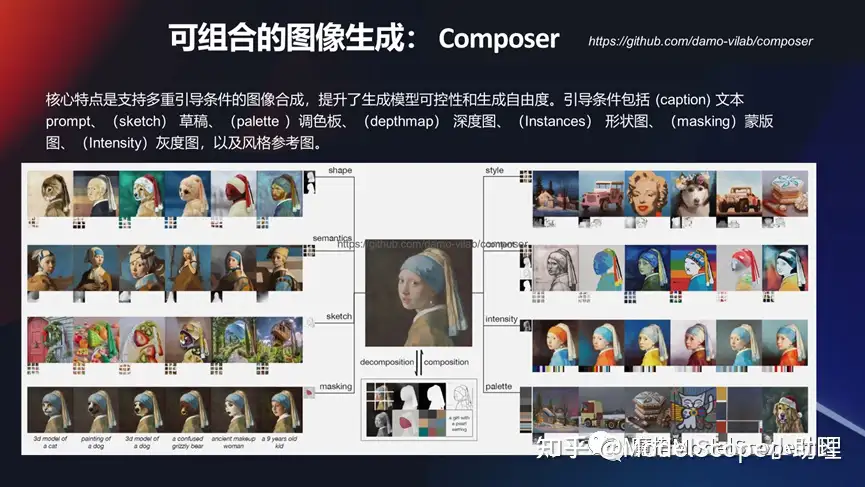
例如在 8 个维度上,不管是形状还是深度形状或者 mask 等等,这上面都可以对生产的结果进行一系列的可控。
除了纯粹的文生图以外,怎么可控的去生产?举了两个例子,一个是那个业界用的比较早期的ControlNet,包括我们达摩院自研的一个 Composer 的一个模型。
文本生成图像

其实文本生成图像,现在的视频越来越用得广,那么文本能不能直接生成视频?其实这一块达摩院也在做相应的研究。
视频的生成确实要比图像的生成质量和可控性相对来说差一点,离真正的使用还是有一定的距离,它不像Midjourney或者文心一格,或者我们自己发布的一系列图像的生成产品慢慢的已经达到可用或者是商业可用的状态。但是对于视频的生产还是有比较多的问题要去解决。

发布的通义大模型文本生成视频,业界大家如何关注到?Runway 公司有个Gen-2, 也就是Gen的一代、二代都可以生成一系列的视频。已经可以预测到文生视频的巨大潜力,这也是一个非常有前景,有意思,有挑战的技术方向。

当然文生视频其实还有另外一个做成的方式,例如想要做一个通用的文生视频其实非常难,生成的结果质量,不管是高清的这方面还是流畅性的这种控制还是语义的符合,是有非常大的一个挑战。那么我们在特定的环境或者是特定的范式下面能不能做一些事情?
例如我们希望什么样的人,在什么样的地方做什么样的动作,这样一个特定的模式能不能做呢?是可以的。比如说,我们做一个在盖有城堡的沙滩上跳舞,然后右边就是我希望秋天的树叶,在这个下跳舞。
这就是我们可以把这种特定范式下的视频生成做得相对可控和高清。
达摩院视觉AI开发服务
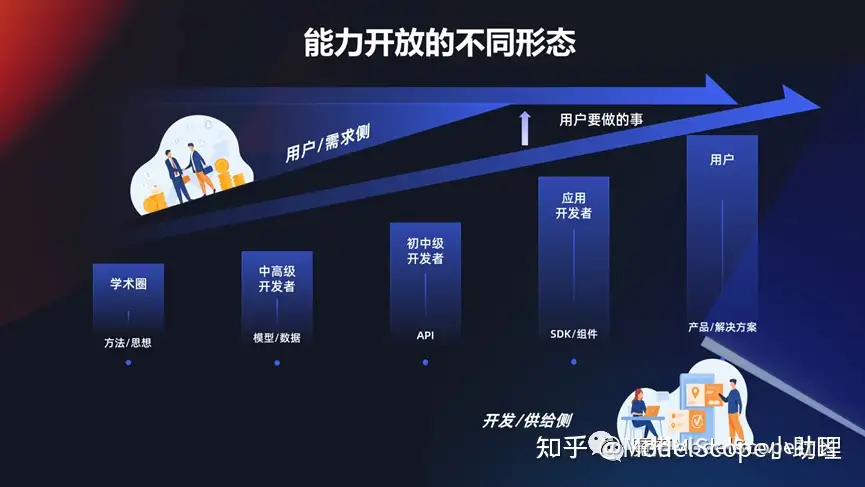
能力开放的不同形态
上面介绍到的这些能力达摩院和业界或者学业界做了非常多的探索,这些能力想要放开的话,无外乎是要要通过一个方式使得开发者/研发者/供给社研发出的模型或能力,能够满足用户的需要。这些需要是多个层面的,例如对于学生或学术圈来说,可能发一篇论文就够,把方法思想开放出去。对一些中高级的开发者,需要使用模型,使用数据,还有一些需要直接调用 API ,甚至有些人只需要一个组件或者一个 SDK 就可以满足。当然对于行业,政企,大行业或者解决方案的时候,需要提供一系列完整的产品和解决方案去满足用户的需求。
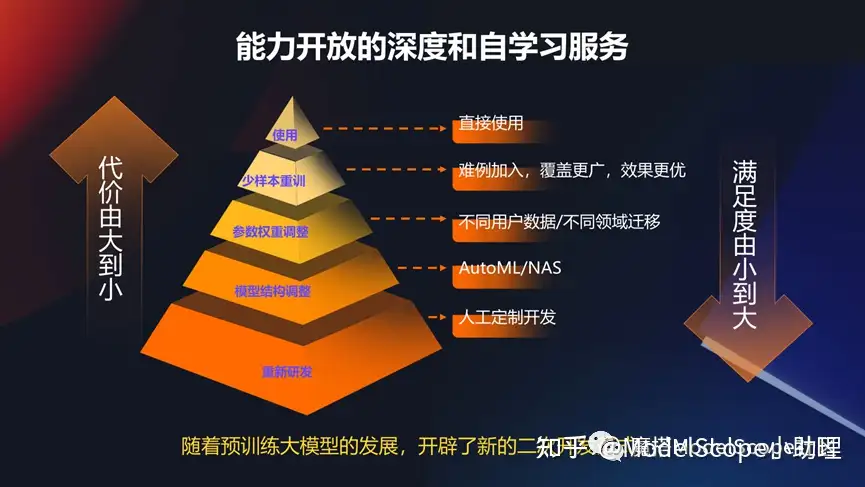
能力开放的深度和自学习服务
所以随着预训的大模型的发展,还有非常重要的是,怎么能够基于这些预训练模型进行二次开发,基于统一的范式去满足一次开发或基础模型不能满足用户定制化需求的时候的一种方式。
达摩院视觉AI开放服务
所以达摩院开放了开放了两种模式,一种是模型即服务的方式ModelScope,一种就是通过 API 平台去满足业界所有的需要,也就是前面所说的所有的模型或者 API 都可以从这两个地方去找得到。

文章转载自 @ModelScope小助理










