LLMs如何在时间序列模型中使用
基础模型推动了计算语言学和计算机视觉领域的最新进展,并在人工智能(AI)领域取得了巨大成功。
成功的基础模型的关键要素包括:
海量数据规模:广泛且多样的训练数据覆盖了全面的数据分布,使模型能够逼近任何潜在的测试数据分布。
可迁移性:通过记忆和回忆已学信息的机制,如提示(Prompting)[1]和自监督预训练[2],模型能够有效地适应新任务。
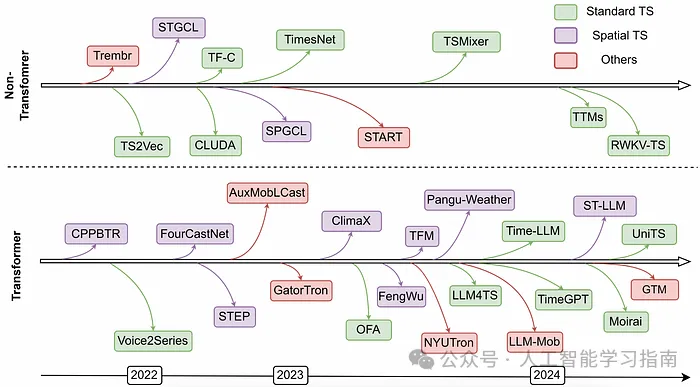
大型时间序列基础模型(LTSM)
在计算语言学领域基础模型取得成功后,越来越多的研究致力于将这种成功复制到另一种序列数据类型上:时间序列。
与大型语言模型(LLMs)类似,大型时间序列基础模型(LTSM)旨在从庞大且多样的时间序列数据集中学习以进行预测。
训练好的基础模型随后可以针对各种任务(如异常检测或时间序列分类)进行微调。
尽管时间序列基础模型的概念已存在一段时间,并且已经探索了多种神经网络架构(如MLP、RNN、CNN),但由于数据数量和质量的问题,尚未实现零样本预测。
在LLMs取得成功之后,人们开始投入更多努力,旨在利用从自然语言数据中学习到的序列信息来进行时间序列建模。
为什么LLMs能用于时间序列数据?
语言模型与时间序列模型之间的主要联系在于,它们的输入数据都是序列数据。
主要区别在于数据如何被编码以供模型捕捉不同类型的模式和结构。
对于大型语言模型,输入句子中的单词首先通过分词被编码为整数序列,然后通过嵌入查找过程转换为数值向量。
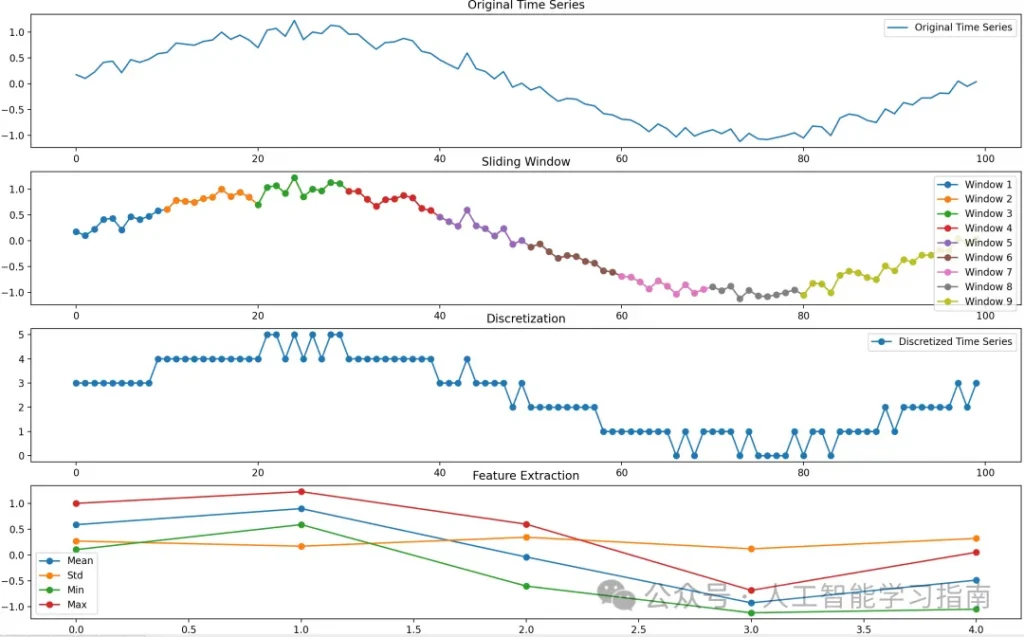
类似地,时间序列数据也可以被分词为一系列符号表示。
下图展示了一个将包含100个时间戳的时间序列转换为长度为5的序列的示例,其中序列中的每一步都由一个4维特征向量表示。
时间序列可以通过滑动窗口进行分割,并进行离散化处理以提取统计值(如均值、标准差、最小值、最大值)来表示每个窗口。
这样,一个在广泛语料库上训练的大型语言模型可以被视为与从现实世界中广泛数值模式中学习的大型时间序列模型(LTSM)类似。
因此,时间序列预测问题可以被构造成一个类似于下一个单词预测的问题。
实现最佳性能和零样本/少样本预测的关键挑战在于对齐时间序列符号和自然语言符号之间的语义信息。
如何为时间序列建模重新编程LLM
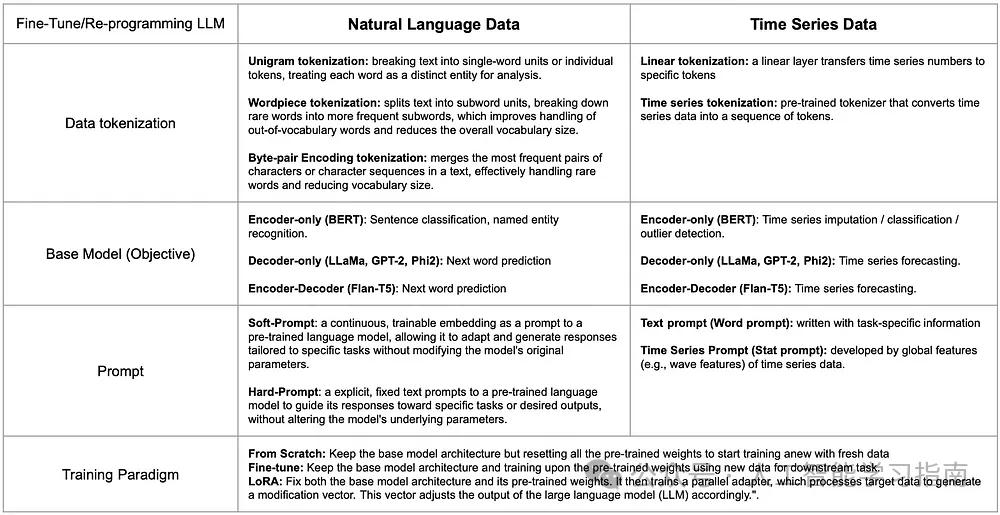
为了应对这一挑战,研究人员正在从训练大型语言模型的各个角度研究如何弥合时间序列与自然语言之间的信息鸿沟。下表展示了这两种数据类型在组件上的比较以及每个组件的代表性工作。
一般来说,将大型语言模型(LLM)重新编程用于时间序列建模,与针对特定领域进行微调的过程相似。
这一过程包含几个关键步骤:数据分词、基础模型选择、提示工程以及定义训练范式。
对于LLM来说,时间序列数据的分词可以通过符号化表示来实现。
这避免了手动离散化和启发式特征提取的复杂性,可以通过简单的线性层或预训练的分词器[3]将时间序列数据的片段映射到潜在嵌入空间中的标记上,从而使分词后的时间序列数据更好地适应LLM。
在选择基础模型时,可以通过比较不同架构的目标任务来进行。
例如,句子分类可以与时间序列分类或异常检测相对应,而下一个词的预测则可以对应于时间序列预测。
对时间序列数据进行提示时,可以依赖于数据的文本信息(如数据集或任务描述),或者从每个时间序列中提取全局统计特征,以突出不同数据集之间的总体差异。
时间序列数据的训练范式通常遵循自然语言处理中使用的类似方法。
这些方法包括:使用相同模型架构但不包含预训练权重的从头开始训练、在预训练权重上进行微调,或训练一个并行适配器(如LoRA)以使LLM适应时间序列数据。
每种方法都有不同的计算成本,而这些成本并不一定与性能结果成正比。
因此,鉴于每个步骤中的多样选择,我们如何确定最佳选项,以创建一个具有最优性能且更具泛化能力的模型呢?
深入理解大型时间序列模型训练中的不同设计选择
为了全面评估每一步选择的优势与劣势,论文《LTSM-bundle》研究了在开源基准数据集上不同选择组合的效果,并提供了一个开源基准框架,使公众能够针对自己的时间序列数据重新编程和基准测试不同的LLM(大型语言模型)选择。
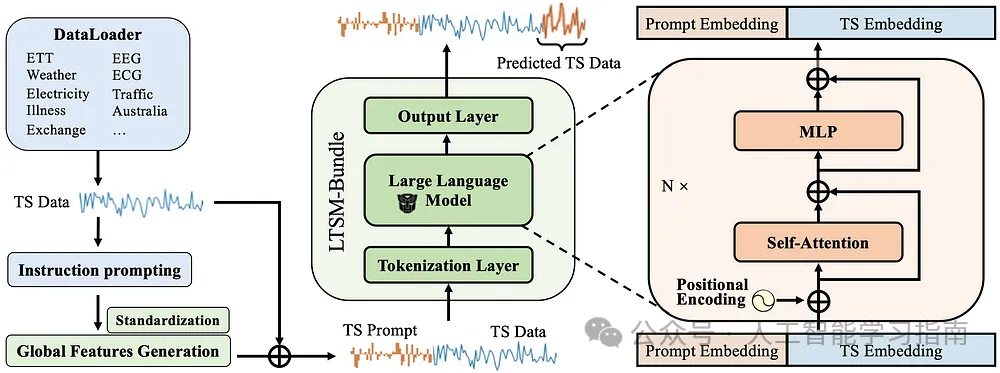
这篇论文深入探讨了训练LTSM(长短期记忆)模型的多种因素,包括模型提示的不同方式、数据分割策略、训练方法、基础模型的选择、数据量的多少以及数据集的多样性等。
在审视现有方法的基础上,我们提出了一种新的概念——“时间序列提示”(Time Series Prompt)。
这种新方法通过从训练数据中提取关键特征来生成提示,为每个数据集提供了坚实的统计概览。
我们基于预测误差(均方误差/平均绝对误差)来评估不同的选择,误差值越低,模型性能越好。
研究中的一些关键发现包括:
简单的统计提示(TS Prompt)在提升LTSM模型训练方面优于文本提示,并且与不使用任何提示的场景相比,使用统计提示能带来更优的性能表现。

使用可学习的线性层对时间序列进行分词,在训练LTSM模型时表现更佳,特别是在同时处理来自不同领域的数据时,这一方法相较于其他分词方法更具优势。

虽然从头开始训练模型在初期可能表现良好,但由于参数众多,存在过拟合的风险。全面微调通常能达到最佳性能,并且收敛速度是从头开始训练的两倍,从而确保了预测的高效性和准确性。
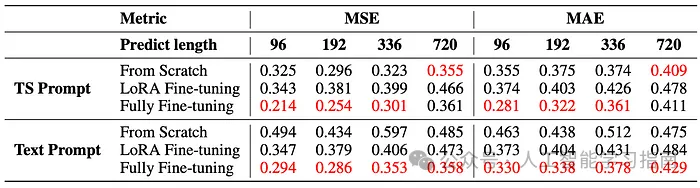
在长期预测(336步和720步)中,小型模型表现出高达2%的性能优势;而在短期预测(96步和192步)中,中等大小的模型则优于大型模型,这可能是因为大型模型存在潜在的过拟合问题。

数据量的增加并不总是能带来模型性能的改善,因为每个数据集的数据量增加会提高训练时间序列的粒度,反而可能降低模型的泛化能力。但增加数据集的多样性通常能提升性能。
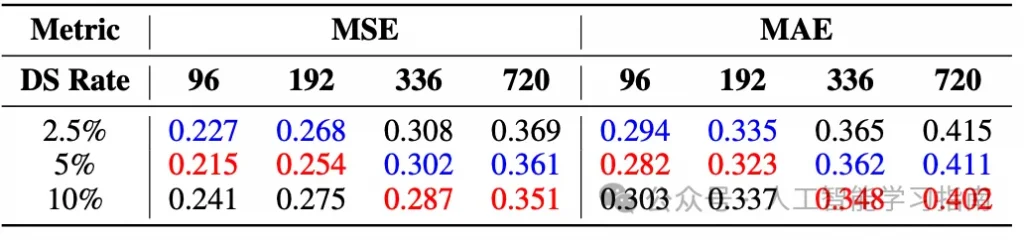
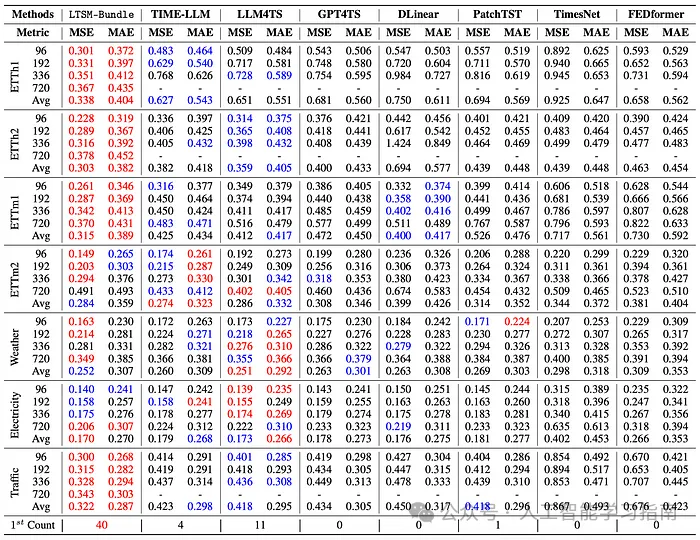
综合以上发现,作者创建了LTSM-Bundle模型,该模型在重新编程用于时间序列的LLM(大型语言模型)和基于Transformer的时间序列预测模型方面,表现优于所有现有方法。
自己重新编程LTSM
如果大家想尝试自己重新编程LTSM,以下是LTSM-bundle的教程链接:https://github.com/daochenzha/ltsm/blob/main/tutorial/README.md
步骤1:创建一个虚拟环境。克隆并安装所需的依赖项和仓库。
conda create -n ltsm python=3.8.0
conda activate ltsm
git clone git@github.com:daochenzha/ltsm.gitclone git@github.com:daochenzha/ltsm.git
cd ltsm
pip3 install -e .
pip3 install -r requirements.txt步骤2:准备你的数据集。确保你的本地数据文件夹结构如下所述。
- ltsm/ - datasets/ DATA_1.csv/ DATA_2.csv/ DATA_3.csv/
...步骤3: 从训练、验证和测试数据集中生成时间序列提示
python3 prompt_generate_split.pypy步骤4:在‘./prompt_data_split’文件夹中找到生成的时间序列提示。然后运行以下命令以完成提示的定制。
# normalizing the promptspython3 prompt_normalization_split.py --mode fit#export the prompts to the "./prompt_data_normalize_split" folder
python3 prompt_normalization_split.py --mode transform最后步骤:使用时间序列提示和线性分词在gpt2-medium上训练你自己的LTSM模型。
python3 main_ltsm.py \ --model LTSM \ --model_name_or_path gpt2-medium \ --train_epochs 500 \ --batch_size 10 \ --pred_len 96 \ --data_path "DATA_1.csv DATA_2.csv" \"DATA_1.csv DATA_2.csv" \ --test_data_path_list "DATA_3.csv" \ --prompt_data_path "prompt_bank/prompt_data_normalize_split" \ --freeze 0 \ --learning_rate 1e-3 \ --downsample_rate 20 \
--output_dir [Your_Output_Path] \论文和GitHub仓库:
论文链接:
https://arxiv.org/pdf/2406.14045
代码仓库:
https://github.com/daochenzha/ltsm/
参考文献:
- Liu, Pengfei 等人. “预训练、提示与预测:自然语言处理中提示方法的系统综述.” ACM Computing Surveys, 2023, 55(9): 1-35.
- Liu, Xiao 等人. “自监督学习:生成式还是对比式.” IEEE Transactions on Knowledge and Data Engineering, 2021, 35(1): 857-876.
- Ansari, Abdul Fatir 等人. “Chronos:学习时间序列的语言.” arXiv 预印本 arXiv:2403.07815, 2024.
原文转自 微信公众号@人工智能学习指南