

使用Python语言调用零一万物API实战指南

我正在做一个项目,需要我找出最适合内容创作的 LLM。我查看了 lmsys 排行榜上的顶级模型,阅读了其他人对这些模型的评价,查看了顶级 LLM 的模型卡,在没有明确答案的情况下,我决定对所有这些 LLM 进行测试,以完成不同的内容创作任务。
我想评估的模型(考虑到它们的成本、易用性和 lmsys 排行榜上的排名):
以下是我所做的……
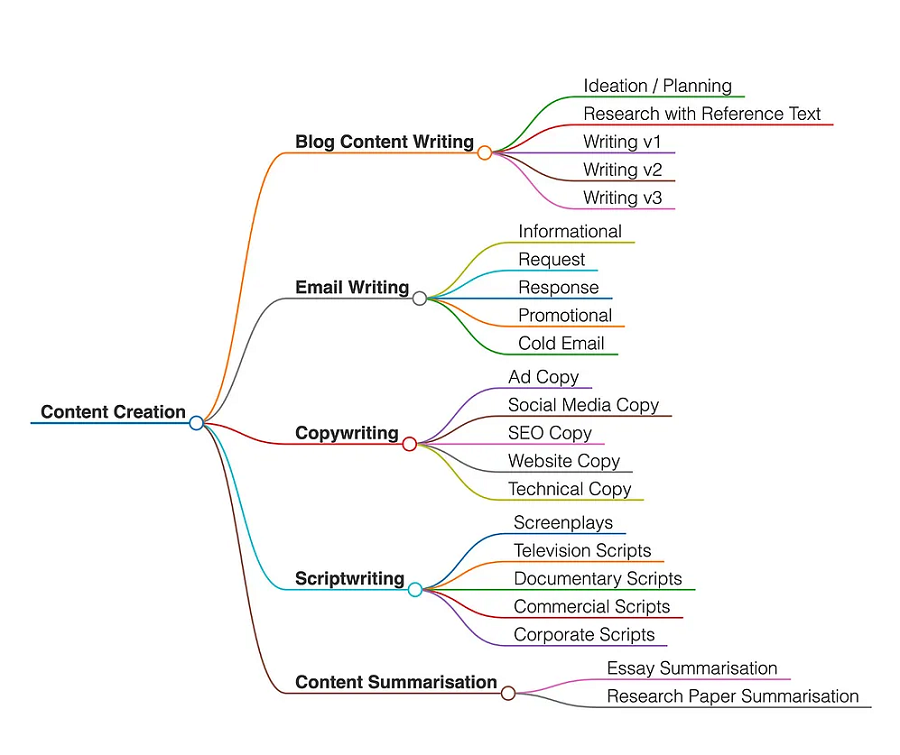
首先,我将内容创作领域分为 5 个不同的用例:
在每个用例中,我创建了多个类别,这些类别要么是子用例,要么是该用例流程的步骤。
每个用例如下所示:
GPT-4 Turbo 将作为第一位评委,根据我根据用例编写的评估提示,对每个答案进行满分 10 分的评分。
我自己担任第二位评委。
每位评委将对答案进行满分 10 分的评分
最终得分是 2 个分数的平均值。
在扩展每个用例的类别后,我必须仔细制作将提供给每个 LLM 的提示。不仅仅是创作提示,我知道如果我是唯一一个评估这些 LLM 答案的人,那将是非常有偏见和不可靠的,所以我与最好的 LLM gpt-04-turbo 联手。
现在,将会有,
其中评估将由另一个 LLM 完成,我知道这听起来很奇怪,但像 MT-Bench 这样的基准(请注意,这次评估与 MT-Bench 相差甚远)也使用强大的 LLM 作为评委来自动化评估过程。
为了策划创作提示,我使用了提示工程技术,例如人员采用、清晰的说明、思考时间和分隔的参考文本。
例如,
社交媒体文案提示:假设你是一家精品咖啡店的社交媒体经理,这家咖啡店以使用公平贸易的有机咖啡豆而自豪。你的目标是吸引经常光顾咖啡店作为社交中心的年轻时尚受众。制作一系列社交媒体帖子:— 用生动的视觉效果和诱人的描述介绍一种新的季节性混合咖啡。— 宣传即将举行的现场音乐晚会,突出舒适的氛围和优质的咖啡。— 分享客户对他们最喜欢的咖啡和学习场所的评价。确保每篇帖子都引人入胜,使用对话语气,并包含可提高知名度和推动互动的主题标签。
评估提示也使用了类似的技术和框架进行评估。我将每个评估标准分为 5 个部分,每个部分价值 2 分,部分满足标准则进行部分评分。
示例:
社交媒体文案响应评估提示:你是专业的文案撰稿人和编辑。根据以下标准对以下社交媒体文案(下面用三重引号分隔)进行 10 分制评分,其中每个点有 2 分,如果大纲未能完全捕捉到该元素,则给 0 分,如果大纲部分涵盖该元素,则给 1 分,如果大纲完全涵盖该标准的所有本质,则给 2 分:评估社交媒体文案的以下元素:— 相关性:内容是否与当前趋势、热门标签和受众兴趣一致?— 对话语气:文案是否使用友好、随意的语气,引起社交媒体用户的共鸣?— 视觉冲击:文案是否提到使用引人入胜的视觉效果(例如图像、视频或 GIF)来提高参与度? — 简洁性:文案是否简短、简洁,一目了然? — 可分享性:内容是否以鼓励点赞、分享和评论的方式制作,以扩大影响力? “””{text}”””
所有 22 个类别都进行了此项测试。
现在是生成和评估响应的时候了。
为了进行评估,我使用了 chatgpt,默认情况下它使用 gpt-4-turbo。
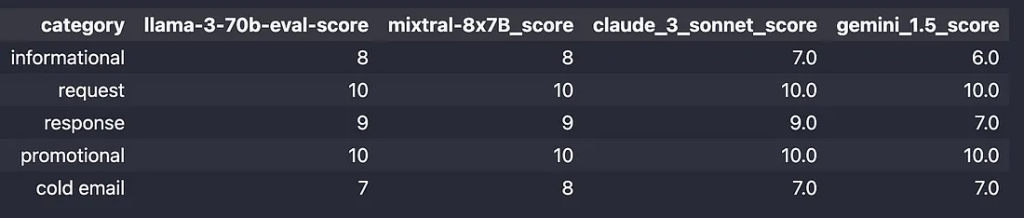
以下是我按类别得到的结果:
GPT 的评估分数:

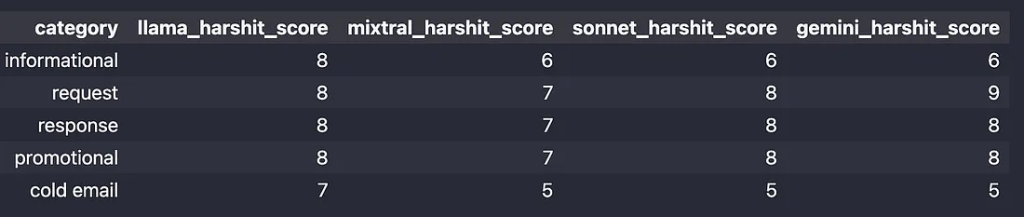
我的评估分数:

然后将以上两个分数的平均数作为最终得分:

博客写作评选 — Llama-3–70B
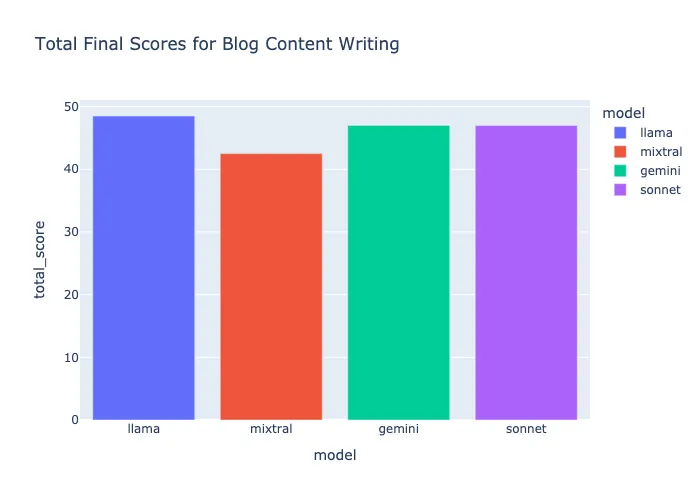
Llama-3–70b 得分 48.5,其大纲非常详尽,能够从参考文本中学习,并且具有高质量的文本生成能力,最终成为赢家。
Sonnet 和 Gemini 也给出了很好的回答,但 Llama 的回答具有人们在阅读真实文本时所寻找的细微差别或对细节的更多关注。
这是一个有点令人失望的类别,部分原因是提示,我应该花更多精力来制作更详细的电子邮件提示,但是,它们对所有人来说都是一样的,所以让我们看看结果:
GPT 分数:
我的分数:
最终分数:
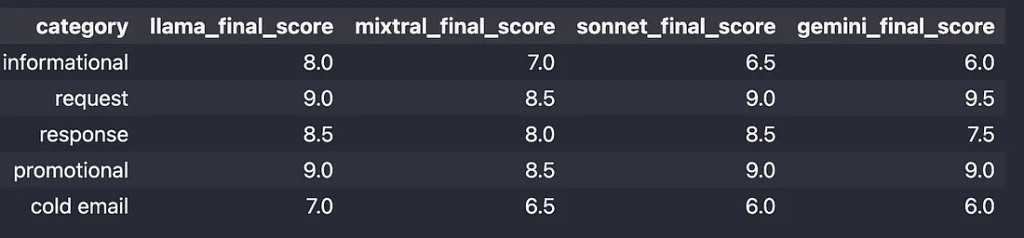
电子邮件写作的评价——Llama-3–70B
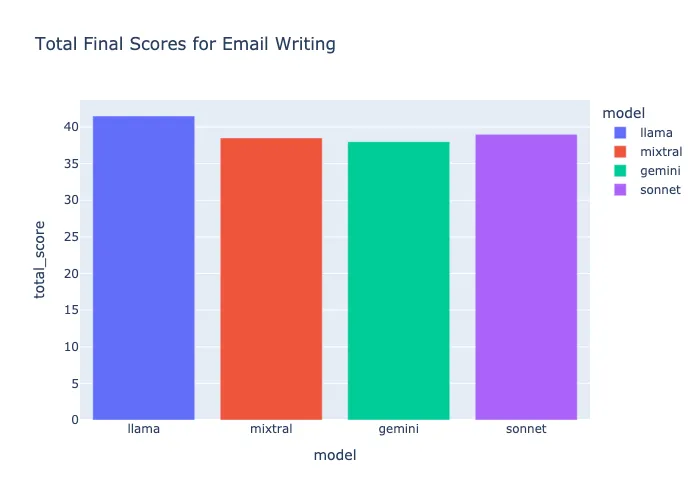
同样,Llama-3–70b 以 41.5 分(满分 50 分)的表现优于其竞争对手,但我对质量和现代电子邮件写作实践并不十分满意,我们优先考虑简洁和直接的回复,但考虑到提示,他们做得相当不错。
在文案撰写方面,所有模型都表现得相当不错。
GPT 得分:

我的得分:
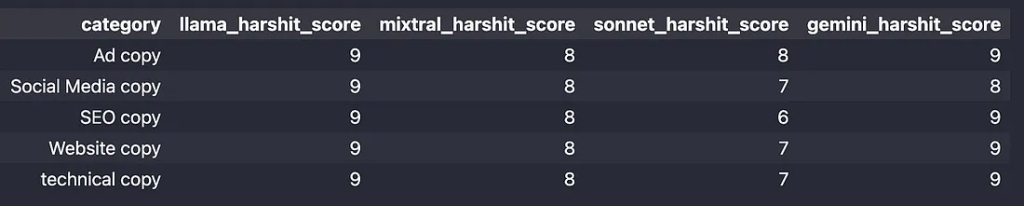
最终得分:
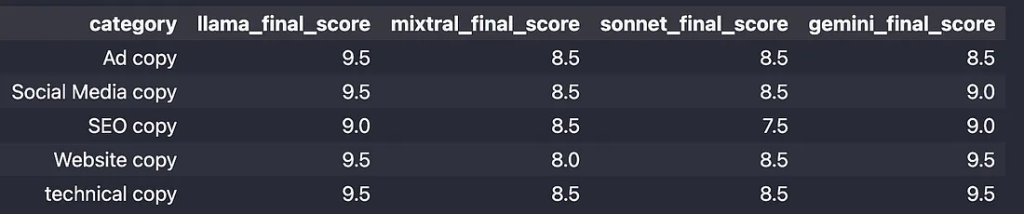
文案撰写评价 — Llama-3–70B
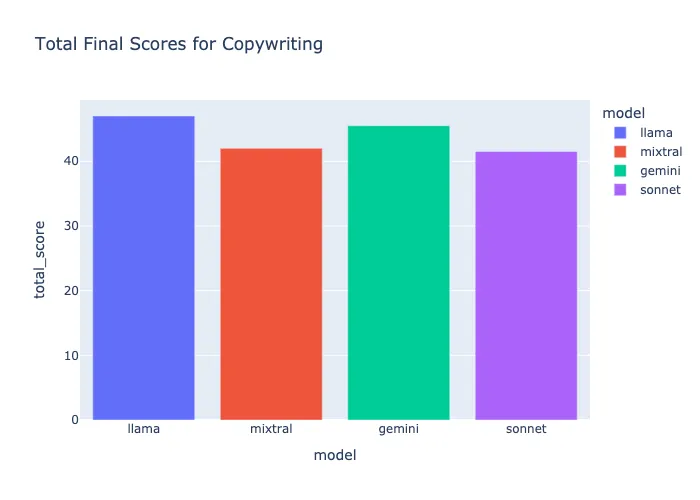
llama-3 的质量和遵循指令的能力都很不错。它抓住了提示中的每个小细节,因此不仅在 GPT 的评估中得分很高,而且我还发现文案更详细、更有条理、更连贯、更有吸引力。
GPT 分数:
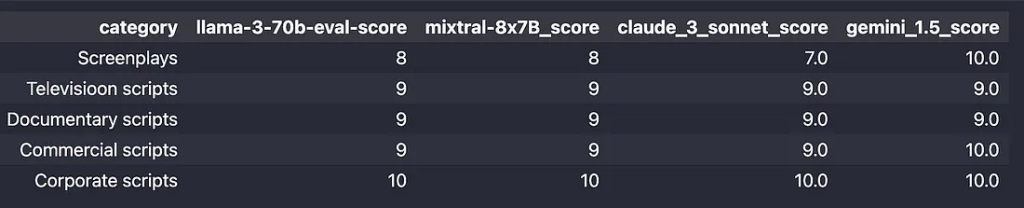
我的分数:

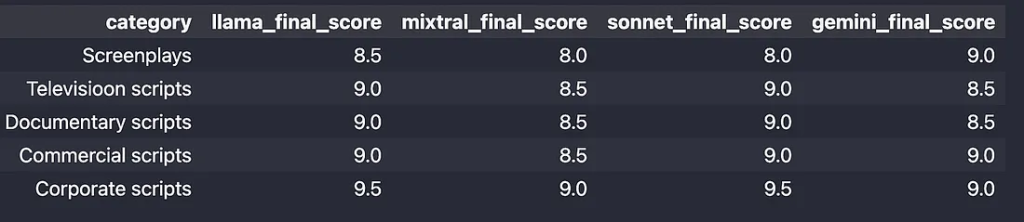
最终分数:
剧本写作评价——Llama-3–70b
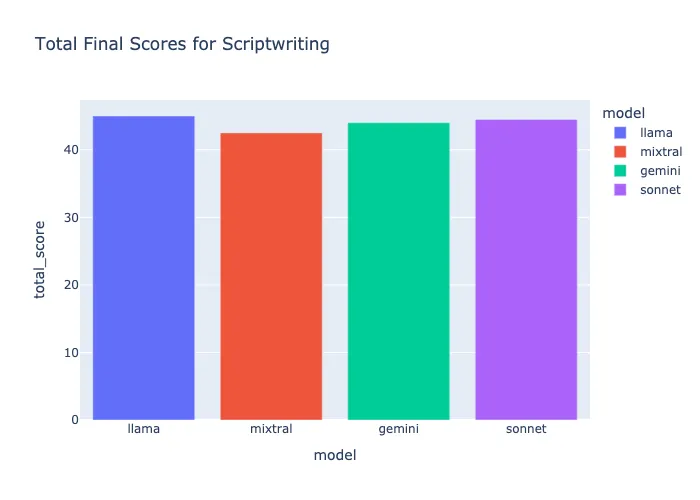
所有模型在制作初稿时都表现得相当不错,但需要大量改进才能跟上另一位作者的写作风格,这是我这次错过的,但肯定会检查的。
我们有 3 个获胜者。Llama-3–70B、Claude-3-Sonnet 和 Gemini 1.5 Pro。
这是我手头上最重要的任务之一,结果如下:
GPT 分数:

我的分数:

最终分数:

内容摘要评价——Claude 和 Gemini 1.5 Pro
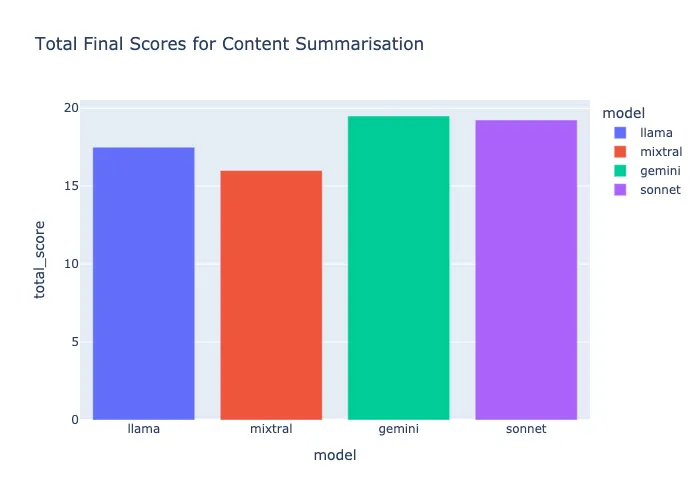
Claude 模型生成的摘要质量让我感到惊讶。Claude Sonnet 和我也尝试过 Claude 3 Opus(他们最好的模型,但非常昂贵),Opus 的摘要结构严谨、注重细节,尽可能地抓住了文档的精髓。经过微调后,这些模型的表现绝对非常好。

获胜者:Gemini 1.5 Pro 和 Claude 3 Sonnet
总分为 220 分,得分 199.5 分,Llama-3–70b 在内容创作方面总体表现优异。
原文链接:http://www.bimant.com/blog/llm-content-creation-capability-evaluation/













