

掌握API建模:基本概念和实践

本文探讨了最受欢迎的大型语言模型(LLM)及其在构建聊天机器人、自然语言搜索和其他基于LLM的产品方面的集成能力。我们将说明如何根据业务目标选择合适的大型语言模型,并研究实际用例,包括AltexSoft的经验。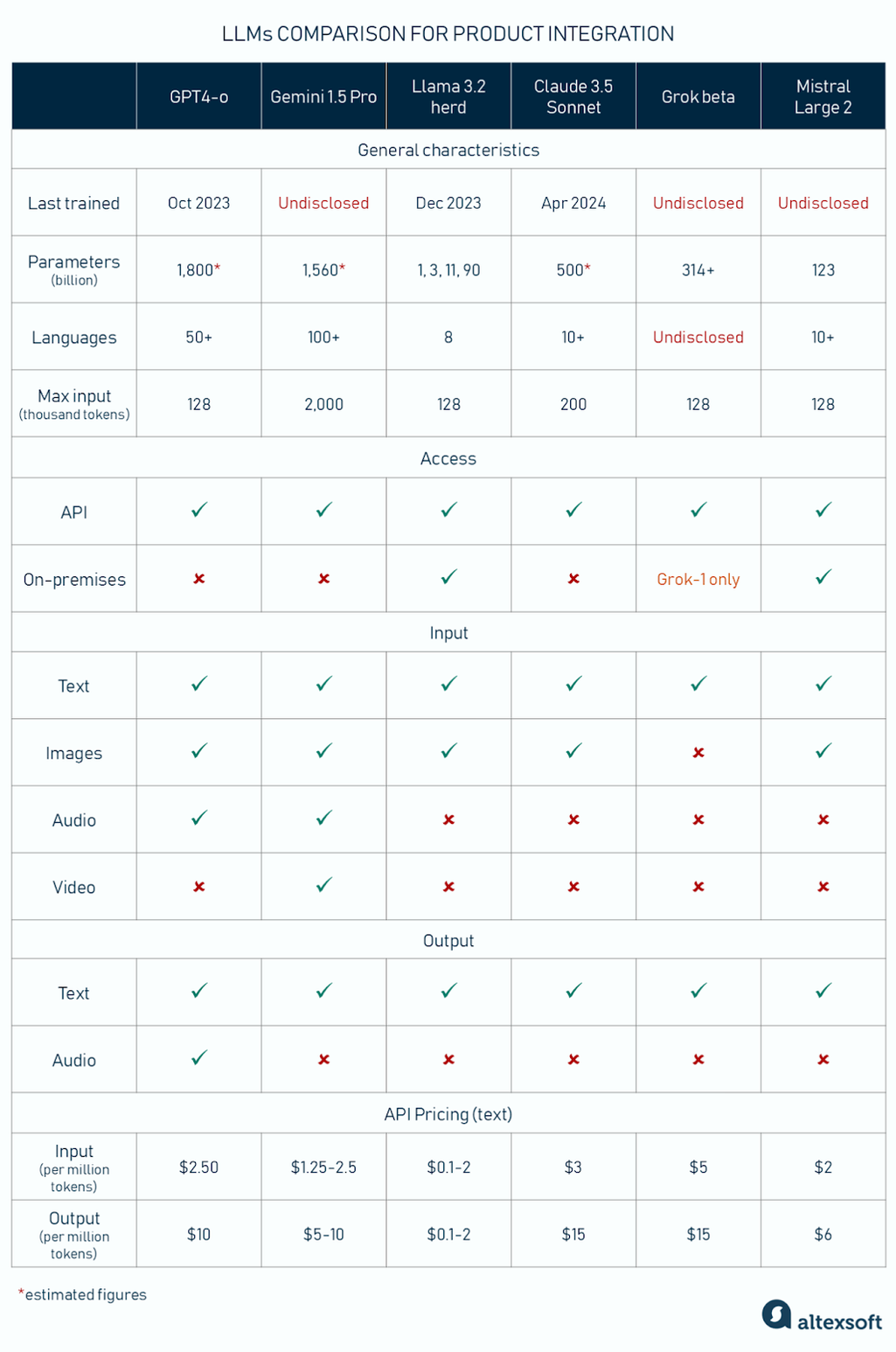
用于产品集成的旗舰 LLM 比较:主要特性和功能
在大型语言模型上构建业务应用程序时,了解核心指标和功能至关重要。在这里,我们将探讨可能影响性能和用户体验的关键属性。
参数中的大小。Parameters 是生成式 AI 模型在训练期间学习的变量。它们的数量表明 AI 理解人类语言和其他数据的能力。更大的模型可以捕获更复杂的模式和细微差别。何时将模型视为大型模型?定义很模糊,但最早被公认为 LLM 的模型之一是 BERT (110M 参数)。现代 LLM 有数千亿个参数。
支持的语言数量。 请注意,有些模型适用于 4-5 种语言,而另一些模型是真正的多语言。例如,如果您想要多语言客户支持,这一点至关重要。
Context 窗口(最大输入)。这是语言模型在生成回复时能够处理的一段文本或其他数据(图像、代码、音频)的量。更大的上下文窗口允许用户输入更多自定义、相关的数据(例如项目文档),这样系统就会考虑完整的上下文,并给出更精确的答案。
对于文本数据,context 窗口以标记计数。您可以将标记视为单词序列,其中 1,000 个标记大约是 750 个英语单词。
访问。 您可以通过 API 与大多数流行的 LLM 集成。但是,其中一些应用程序可供下载,并且可以在本地部署。
输入和输出模态。 模态是模型可以处理的数据类型。LLM 主要处理文本和代码,但多模态 LLM 可以将图像、视频和音频作为输入;输出主要是文本。
微调。通过微调,大型语言模型(LLM)可以获得特定领域的知识,从而更有效地服务于您的业务任务。这一选项通常适用于可下载的模型,但一些提供商允许用户在云端自定义其LLM,并设定微调数据集的最大规模。无论如何,这一过程都需要投入和准备充分的数据。
定价。价格按每百万个代币计算;图像文件和其他非文本形式也可以进行标记化,或按 Unite/Per second 进行计数。这是最流行的 LLM 的 OpenAI 定价计算器。列表中最便宜的是 Llama 3.2 11b Vision Instruct API,最贵的是支持语音生成的 GPT-4o RealTime API。
我们在这里只提到了 LLM 的主要特征。现在,让我们更详细地讨论最流行的模型。
OpenAI 于 2018 年发布了其第一个 GPT 模型,从那时起,它为复杂语言任务的性能设定了行业标准。LLM 在性能、推理技能和微调便利性方面仍然无与伦比。到目前为止,旗舰型号是 GPT-4o,它有一个更小、更快、更便宜的版本,称为 GPT-4o mini。
这两种变体都支持 50 多种语言,并且是多模态的:它们接受文本和图像输入并生成文本输出,包括代码、数学方程式和 JSON 数据。此外,借助 2024 年 10 月推出的 RealTime API,您还可以将音频馈送到 GPT-4o 中,并让模型以文本、音频或两者兼而有之的方式做出响应。
最近,OpenAI推出了一系列新的o1模型(包括o1和o1-mini),目前处于测试阶段。这些模型通过强化学习进行训练,能够进行更深层次的推理,并处理更复杂的任务,特别是在科学、编程和数学领域。然而,对于大多数常见用例来说,GPT-4o在不久的将来会更具能力,因为新一代模型缺乏许多功能(如上网浏览)。
除了 LLM 之外,Open AI 还代表图像模型 DALL-E 和音频模型 Whisper 和 TTS。
GPT-4o 估计有数千亿个参数;一些消息来源声称 1.8 万亿,尽管确切的细节是专有的。在这两个版本中,上下文窗口最多可以容纳 128,000 个令牌,相当于 300 页文本。
GPT 模型仅作为云中的一项服务提供;您不能在本地部署它们。它们可通过 Open AI API、Python 、Node.js 和 .Net.或通过 Azure OpenAI 服务,该服务还支持 C#、Go 和 Java。借助社区库,您也可以使用其他语言调用 API。
下面,我们将列出 Open AI 直接提供的 API 产品。
Chat completions API 允许您将文本生成功能快速嵌入到您的应用程序、聊天机器人或其他对话界面中。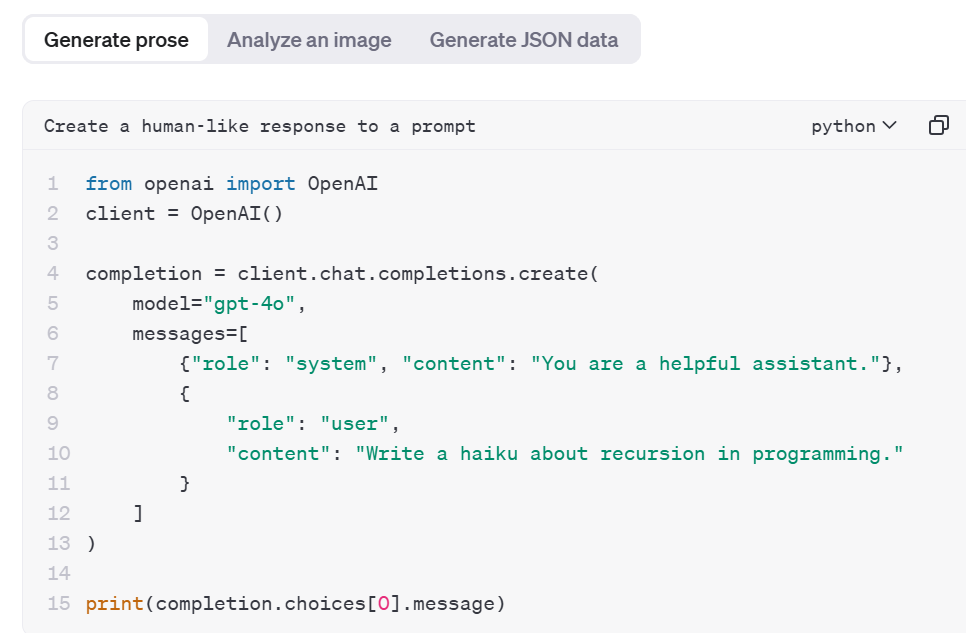
使用 Python 和 chat completions 端点生成散文。来源:OpenAI 平台
Assistants API(在 beta 测试模式下)专为设计强大的虚拟助手而设计。它带有内置工具,例如文件搜索,用于从文档中检索相关内容,以及代码解释器,可帮助解决复杂的数学和代码问题。API 可以并行访问多个工具。
Batch API 非常适合不需要立即响应的任务,例如酒店评论的情绪分析或大规模文本处理。单个批次最多可包含50,000个请求,而批次输入文件的大小不应超过100MB。与同步API相比,批次API的成本要低50%。
Realtime API(在 Beta 测试模式下)支持将文本和音频作为输入和输出,这意味着您可以构建低延迟的语音转语音、文本转语音或语音转文本聊天机器人,以支持与客户的音频对话。您可以从六种男声部或女声部中选取一个。虚拟对话者将使用您喜欢的任何语气,例如温暖、引人入胜或体贴;“他”或“她”甚至可以大笑和耳语。
为了自定义GPT-4o/GPT-4o mini模型,您需要准备一个包含至少10个对话模式的数据集,尽管OpenAI建议从50个训练示例开始。用于微调的数据集必须为JSON格式,且大小不超过1GB(尽管您无需如此大的数据集即可看到改进)。数据集还可以包含图像。要上传数据集,请使用Files API或针对大于512MB的文件使用Uploads API。
可以通过 OpenAI UI 执行微调,也可以使用 OpenAI SDK 以编程方式执行微调。Azure OpenAI 目前仅支持文本到文本的微调。
用于企业的 GPT-4o API 成本为 2.5 美元/1M 输入代币和 10 美元/1M 输出代币,而 GPT-4o 迷你要便宜得多——0.15 美元/1M 输入代币和 0.6 美元/1M 输出代币。
O1 预览版的成本为 15.00 美元/1M 输入令牌和 60.00 美元/1M 输出令牌。
Gemini (以前的 Bard) 模型系列针对高级推理和理解进行了优化,不仅可以理解文本,还可以理解图像、视频和音频数据。
该模型的名称灵感来源于NASA早期的登月计划——具有突破性的双子座计划(Project Gemini)。此外,它还与双子座占星术符号相关联,因为双子座出生的人具有高度适应性,能够轻松与不同的人建立联系,并自然地从多个角度看待事物。
旗舰产品是 Gemini 1.5 Pro 和 Gemini 1.5 Flash。Flash 是一种中型多模态模型,针对各种推理任务进行了优化。Pro 可以处理大量数据。两种型号都支持 100 多种语言。
Vertex AI 平台上的 Gemini 1,5 Pro。来源:Vertex AI
据估计,双子座模型(Gemini models)拥有1.56万亿个参数。双子座1.5 Pro具有前所未有的200万个标记的上下文窗口,这意味着它可以在一个提示符中容纳10部《哈利·波特》小说(即现有的7部加上粉丝想象的3部)。或者一部《哈利·波特》电影(2小时的视频)或19小时的音频。双子座1.5 Flash的上下文窗口为100万个标记。
Gemini 模型仅基于云。Google 提供了两种访问其 LLM 的方法 — 在 Google AI 和 Vertex AI(Google 的端到端 AI 开发平台)上。这两个 API 都支持函数调用。
Google AI双子座(Gemini)API提供了一种快速探索大型语言模型(LLM)功能并开始原型设计和创建简单聊天机器人的方法。它支持移动设备,并与Firebase原生连接,Firebase是Google用于开发基于AI的Web、iOS和Android应用的平台。该API可以使用Python、Node.js和Go进行访问。对于原型设计,建议使用Flutter、Android、Swift和JavaScript的SDK。如果您想将以这些语言编写的应用程序投入生产,请迁移到Vertex AI。
Vertex AI Gemini API 允许构建复杂的企业级应用程序。借助 Vertex AI,您可以利用一系列附加服务,例如用于模型验证、版本控制和监控的 MLOps 工具、用于创建虚拟助手的代理构建控制台以及对生产环境至关重要的安全功能。
总的来说,开始使用 Google AI API 构建基于 Gemini 的应用程序是有意义的,随着您的项目成熟,迁移到 Vertex AI API。
使用 Google AI,可以仅对 1.5 Flash 和文本进行微调。它不包括聊天风格的对话。您可以从包含 20 个示例(每个示例不超过 40,000 个字符)的数据集开始,但最佳大小是 100 到 500 个示例。优化模型不支持 JSON 输入和长度超过 40,000 个字符的文本。
Vertex AI 支持对 1.5 Flash 和 Pro 进行监督微调,包括文本、图像、音频和文档输入。训练数据集的建议大小为 100 个样本,每个样本不超过 32000 个令牌。
您可以使用 Gemini REST API、Google Cloud 控制台的 Vertex AI 部分、Vertex AI SDK for Python 或 Colab Enterprise(Google Cloud 中的协作式托管笔记本环境)创建受监督的微调作业。
费率因模型、输入类型和提示大小而异(超过 128k 个令牌的输入/输出成本是其两倍)。文本输入/输出以百万个令牌或千个字符 (Vertex AI) 为单位,音频和视频输入(以秒为单位)以及视觉输入(以图像为单位)。
Google AI Gemini API 提供免费套餐用于测试目的,限制为每分钟 15 个请求、每天 1500 个请求和每分钟 1M 个令牌。 Vertex AI 提供 50% 折扣的批处理模式。
更多详细信息可在 Google Cloud 定价页面上找到。
Llama (Large Language Model Meta AI 的缩写) 是一个开源、高度可定制的语言模型系列。最新版本 Llama 3.2 有两个模型集合:
所有版本均支持八种语言:英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。
请注意,将于 2025 年夏季生效的欧盟 AI 法案增加了开源 AI 的监管复杂性。由于担心 GDPR 合规性,Llama 3.2 目前被限制进入欧洲市场。
Vertex AI 平台上的 Llama API 服务。来源:Vertex AI
Llama 3.2 以 1、3、11 和 900 亿个参数大小表示。它们都支持 128,000 个令牌的上下文长度。11B 和 90B 型号具有视觉功能:它们可以从图像中提取细节、分析销售图表、解释地图以回答地理查询等。
Llama 可以在本地部署,这使公司能够控制数据安全和隐私。这些模型可在 llama.com 和 Hugging Face 上下载。
2024 年 9 月,Meta 推出了 Llama Stack,这是该公司的第一个框架,用于在各种环境中高效部署 Llama 模型:本地、云端和本地设备。
它包含一组 API,例如
用于运行 Llama Stack 的客户端 SDK 包括 Python、Node、Swift、Kotlin 等。
此外,公司还可以在多个合作伙伴平台上访问 Llama,例如 AWS(通过 Amazon Bedrock,一种通过单个 API 提供模型选择的服务)、Databricks、Dell、Google Cloud、Groq、IBM、Intel、Microsoft Azure、NVIDIA、Oracle Cloud、Snowflake 等。
您可以使用不同的环境自定义 Llama 模型。以下是几个选项。
Llama是开源的,但仍受特定情况下限制其使用的许可协议约束。月活跃用户超过7亿的企业必须联系Meta以获得特殊许可。下载Llama是免费的。然而,如果您想将其作为服务使用,则需要向所选的云提供商或API平台支付费用,价格将取决于许多因素以及供应商提供的附加功能。
例如,Amazon Bedrock 的定价取决于区域:北美分为两个价格区,欧洲分为三个。在美国东部区域,框架对集成 Llama 3.2 1B 收取 0.1 美元/M 输入或输出令牌的费用; Llama 3.2 90B — 2 美元/M 的输入或输出令牌。
Groq 平台上的 Llama 3.2 1B 价格高出四倍:0,4 美元/M 输入或输出代币。
Claude 是一系列模型,可以处理文本、代码和图像输入,并生成代码和文本。上一代包括两个最先进的型号:旗舰 Claude 3.5 Sonnet,专门用于复杂任务、编码和创意写作,以及更小、更快的 Claude 3.5 Haiku。上一代最强大的型号是 Claude 3 Opus,擅长数学和编码。这些模型支持 10+ 种语言。
虽然所有主要的大型语言模型(LLMs)都经过训练,以避免给出危险、歧视性或有害的回复,但Claude的创作者特别强调了道德和责任。他们基于普遍的人类价值观和原则,构思并发表了一份关于宪法人工智能的宣言。这个负责任的人工智能系统经过训练,能够评估其输出,并选择更安全、危害更小的输出。
在技术属性方面,该公司最近推出了一项突破性功能:计算机使用。这套工具使模型能够像人类一样与机器一起工作,与屏幕和软件进行交互。例如,您可以指示模型“使用来自我的计算机和 Internet 的数据填写此表单”。系统将搜索您 PC 上的文件、打开浏览器、浏览网页等。 该功能现在处于 beta 测试模式。
这些参数没有披露,但有传言称约为 5000 亿。所有 Claude 3.5 版本的上下文窗口均为 200k+ 令牌(500 页文本或 100 张图像)。
该模型仅是云托管的。有三个第一方 Anthropic APIS:
Anthropic API 控制台。资料来源:Anthropic
您可以直接调用 API,也可以使用 Python SDK 和 TypeScript SDK。
Claude 3.5 和 Claude 3 系列也可通过 Amazon Bedrock API 和 Vertex AI API 获得。
Anthropic严格的信息安全要求在模型定制方面是一个绊脚石,因为调优数据是由用户控制的。到目前为止,只有 Amazon Bedrock 中的 Claude 3 Haiku 才能进行微调。
Claude 3.5 Sonnet 的使用成本为 3 美元/M 输入令牌和 15 美元/M 输出令牌;Claude 3.5 Haiku 是 0.25 美元/M 的输入代币和 1.25 美元/M 的输出代币。Batches API 提供 50% 的折扣。
Grok 是埃隆·马斯克 (Elon Musk) 的心血结晶,它与 X(前身为 Twitter)集成,并将 X 中的帖子和评论中的信息整合到其答案中。Grok-1 是开源的;您可以从 GitHub 下载代码。
最新一代的 Grok 系列包括商用 Grok-2 和 Grok-2 mini,预计将很快发布。目前,xAI 控制台上只能访问 Beta 版本。
该网站声称 X Grok 2 Beta AI 支持多种语言,但它们的数量未披露。显然,模特会说英语。
“grok”这个词是由科幻小说作家罗伯特·A·海因莱因(Robert A. Heinlein)在1961年的小说《异乡异客》(Stranger in a Strange Land)中创造的。Grok的意思是深刻理解并感同身受。然而,同理心似乎并不是Grok的强项。由于马斯克(Musk)已将争取社交网络言论自由作为自己的信条,因此他创造的这个模型缺乏其他模型所具备的内置信任和安全措施也就不足为奇了,这意味着它可能会给出有毒的、侮辱性的、粗俗的和危险的回复。
对六种不同模型进行的测试表明,Grok 最容易纵来发出指令,例如如何制造炸弹或如何引诱孩子。这意味着该模型不是客户服务应用程序的适当选择。但它在编码和数学计算方面很好。
为 Grok-1 声明了 3140 亿个参数,并且它有一个 8.000 长度的上下文窗口。 到目前为止,Grok-2 的参数尚不清楚,但属于 Grok-2 系列的 Grok 测试版具有 128 长度的上下文窗口。
Grok-2 是多模态的。该模型可以在 X 社交网络上生成高分辨率图像并理解输入图像,甚至可以解释模因的含义。但是,它尚未公开可用。
Grok-1 可以在本地下载和部署。
起初,Grok 仅被 X 平台和 X 的高级用户用作聊天机器人。然而,在 2024 年 10 月,Grok 推出了其第一个面向企业的 REST API 服务,目前处于公开测试阶段。该 API 可通过 xAI 控制台访问,该控制台提供了用于创建 API 密钥、管理团队、处理计费、比较模型、跟踪使用情况和访问 API 文档的工具。 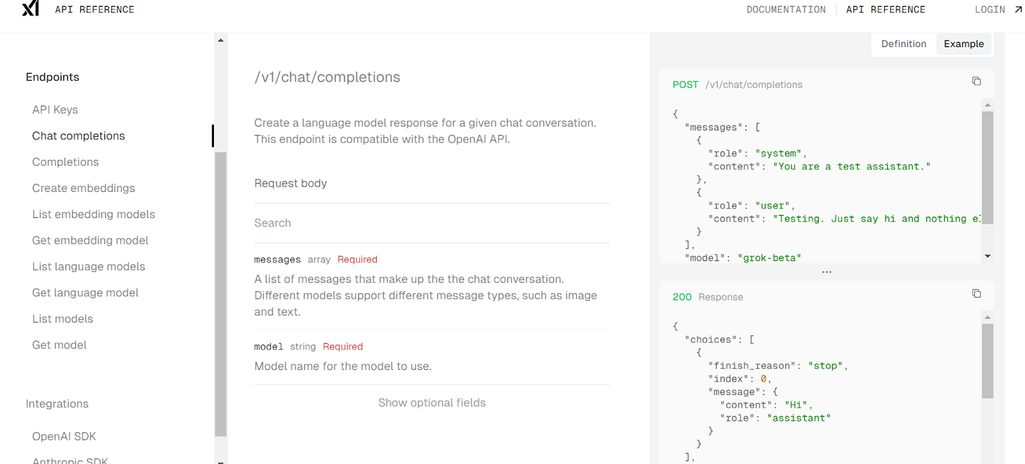
xAI 控制台中的 Ghat 完成示例。来源:xAI
目前,只有 Grok 测试版模型(提供与 Grok 2 相当的性能,但效率、速度和功能更高)可以通过控制台上的 API 访问。
xAI API 完全集成,可通过 OpenAI SDK 和 Anthropic SDK 使用。 更新基 URL 后,您可以使用 SDK 通过 xAI API 密钥调用 Grok 模型。
尽管可以下载,但Grok-1 模型无法进行微调。
Grok-beta 版的成本为 5 美元/M 输入代币和 15 美元/M 输出代币。 您可以免费下载早期版本 Grok-1。
Mistral AI 成立于 2024 年,是一家法国初创公司,由前 Meta 员工 Timothée Lacroix 和 Guillaume Lample 以及前 DeepMind 研究员 Arthur Mensch 共同创立。该公司提供开源和商业生成模型的组合。
高级(商业)产品系列包括六种 LLM:用于高复杂度任务的 Mistral Large 2、用于 AI 编码的 Codestral、3 B 和 8B(小巧但快速的模型)等。Mistral Large 2 允许免费使用和修改用于研究和非商业目标。
除了商业解决方案外,还有 7 个免费模型,例如 Mathstral 7b 和多语言 Mistral NeMo。
大多数Mistral模型都熟练掌握五种主要的欧洲语言;Mistral NeMo支持11种语言;Mistral Large 2则能“说”几十种语言,包括法语、德语、西班牙语、意大利语、葡萄牙语、阿拉伯语、印地语、俄语、中文、日语和韩语,以及80多种编程语言。
Mistral AI SDK。来源:Mistral AI
Mistral Large 2 使用 1230 亿个参数运行。
Mistral Large 2、Mistral 3B 和 8B 的上下文窗口为 128,000 个令牌。
首先,您可以在 La Plateform(托管在 Mistral 基础设施上的开发人员平台)上访问任何模型,并按使用量付费用于商业用途。
开源模型可以从Hugging Face下载,并在您的设备或私有云基础设施上使用,但您需要购买商业许可证(要获取价格表,请联系Mistral AI网站的团队)。此外,您还可以通过云合作伙伴GCP、AWS、Azure、IBM、Snowflake、NVIDIA和Outscale访问这些模型,这些合作伙伴采用按需付费的定价模式。
Mistral Large 2 可在 Azure AI Studio、AWS Bedrock、Google Cloud Model Garden、IBM Watson 和 Snowflake 上使用。
Mistral AI API 包括专用于特定任务的 API 列表:用于生成响应的聊天完成 API、用于将单词矢量化或表示为向量的嵌入 API(文本分类、情感分析等所必需的)、用于上传可跨各种端点使用的文件的文件 API 等。
所有模型都对实验和定制开放。您可以使用 La Plateforme 的专用微调 API 来创建微调管道。GitHub 上的开源代码库也可以自定义。
虽然单个训练数据文件的最大大小为 512MB,但您可以上传的文件数量是无限的。
还可以通过 Amazon Bedrock 进行微调。
Mistral Large 2 的输入代币成本为 $2/1M,输出代币的成本为 $6/1M。最近的降价使其成为最具成本效益的 Frontier 车型之一。 Ministral 3B 的输入/输出代币为 $0.04/1M。
免费 API 层具有速率限制,允许大多数模型(包括 Mistral Large 2)每分钟最多 500K 个令牌和每月 1M 个令牌的上限。
您可能已经注意到,几乎每个知名的 LLM 制造商都提供了小型和大型模型,并且大多数模型在过去一年中在技术能力和性能方面都实现了显着的统一。
“大型云托管 LLM 的性能相似,并且或多或少具有相同的功能,”AltexSoft 工程卓越中心负责人 Glib Zhebrakov 证实道。
由于模型的功能具有可比性,因此 Glib 建议考虑更多因素。
现有基础设施。如果企业已经在使用特定的云提供商(例如Azure、AWS、Google Cloud),那么从同一平台选择大型语言模型(LLM)服务可以确保更容易的集成。此外,对于数据敏感型应用来说,将所有数据流保持在同一云基础设施内,而不暴露于公共互联网上,是至关重要的。
本地部署的可能性。 不仅出于安全原因,而且如果提供商不提供基于云的微调服务,还可以进行微调。
流式处理或逐个令牌解码允许用户实时查看生成的每个单词。此功能对于即时反馈可增强用户体验的对话应用程序非常重要。许多 LLM(包括 GPT、Claude 和 Gemini)都有流式处理功能,但较小的 LLM 通常缺乏此功能,并将响应作为单个输出提供。
函数调用。如果 LLM API 支持函数调用,则意味着模型可以与外部工具交互以执行一系列任务,从获取最新数据(如天气预报)到进行数学计算。
例如,如果客户告诉公司聊天机器人他/她将终止合同并想知道其状况,则可以调用该函数从内部数据库中检索合同,同时通知人工客户经理。
缓存。 上下文缓存是指存储对话历史记录的一部分,以减少重新处理重复或未更改信息的需求。它降低了计算成本和延迟。
配料。 如果您打算将 LLM 用于批量数据分析或内容生成等任务,那么选择具有批处理功能的 API 是有意义的。这意味着请求和响应将定期累积并分组发送,例如每天一次。在批处理模式下处理的令牌通常比使用流式处理处理的令牌便宜两倍。
如果您打算下载大型语言模型(LLM),请不要被那些庞大的模型所诱惑。庞大的规模既是福也是祸:它需要在硬件或云计算GPU上进行大量投资。例如,如果您从AWS租用基础设施,费用大约为每月1500-2000美元。
在许多情况下,较小的、经过适当指导或微调的模型更具成本效益,并且可以胜过较大的 LLM
Glib Zhebrakov,AltexSoft 工程卓越中心负责人
例如,根据 AltexSoft 的经验,一家保险公司开发了一个模型来预测疗养院的保险风险。最终,每个家庭都收到了一个独特的小型模型,根据其特定条件和索赔类型量身定制,因为每个家庭都有特殊的需求和风险因素。
自定义窗口的大小也具有另一面。
我总是喜欢保持提示简洁明了:在一个提示中添加太多数据会导致 AI 幻觉
Glib Zhebrakov,AltexSoft 工程卓越中心负责人
这就是检索增强生成 (RAG) 发挥作用的地方:一个包含域和公司特定文档的矢量化数据库,可以搜索这些文档以查找上下文匹配的信息。按照提示符,模型检索并处理匹配的数据块,然后将它们包含在其响应上下文中。要创建 RAG,您需要工程师。因此
请注意,最具挑战性的部分不是 API 集成本身,而是提示工程 – 为模型制作说明,以便它产生与您的目标相关的答案。在这个阶段,成功取决于 ML 工程团队的技能和经验。
如果您正在考虑聘请专家来完成这项任务,或者您是一名正在探索新职业的工程师,请阅读我们关于提示工程师的角色、他们的职责和所需技能的文章。
如果您想对模型进行微调,可以考虑聘请具有数据科学、数据工程和/或机器学习工程背景的专家。如果做得得当,微调可以显著改善结果。韩国领先公司之一的SK Telecom定制了Claude模型,通过整合行业特定知识来增强客户支持工作流程并改善服务体验。部署微调后的Claude模型后,代理回复的正面反馈提高了73%。
LLM 集成最近在各行各业越来越受欢迎。从客户支持到数据分析 – 以下是最常见的使用案例。
由 LLM 提供支持的 сhatbots 了解人类语言的细微差别,为客户的询问提供个性化和善解人意的回复。模型可以支持更具吸引力、知识渊博和高效的对话,从而提高客户满意度和忠诚度。
一家澳大利亚旅游初创公司与AltexSoft合作,构建了一个自动结合可用航班和酒店旅游的预订平台。客户可以从各种度假套餐中进行选择,并定制自己的假期。其中一个关键功能是集成了OpenAI API的搜索栏,用于访问GPT语言模型。
由于集成了ChatGPT,旅行者可以用简单的语言描述他们理想的假期并进行搜索,即使他们不知道确切的目的地。例如,用户可以输入“哪里可以吃到一碗完美的越南河粉”,“我想找一个舒适的山间小屋去滑雪”,或者“带家人去一个风景如画的海岛享受放松的海滩度假”。
通过引入 ChatGPT 功能,我们的合作伙伴通过自然语言交互增强了客户体验,并提高了平台的转化率。
从起草营销文案到生成冗长的报告,LLM 可以简化内容生成创建过程,让您的团队腾出时间来处理更复杂的任务。例如
Duolingo 是一款国际公认的语言学习应用程序,它使用 LLM 为他们的课程创建练习。
跨国电子商务平台 Shopify 创建了一个由 G PT 提供支持的数字助理,用于生成和校对引人注目的产品 SEO 描述。
LLM 可以分析大量文本数据,发现具有挑战性的或无法手动检测的有价值的见解和模式。这种数据驱动的智能可以为战略决策提供信息并优化业务运营。
爱尔兰裔美国跨国金融服务公司Stripe利用GPT来了解客户的需求以及每个用户如何使用Stripe平台。许多客户都是小企业,比如夜店,他们的网站非常简单,这使得收集必要信息变得困难。GPT会扫描这些网站,并提供比人类生成的摘要更有信息量的内容。
LLM 可以根据个人偏好和行为定制推荐、内容和交互。这种级别的个性化可以带来更高的参与度和更高的转化率。
Amazon 开发了基于 LLM 的框架 COSMO 来改进其推荐引擎。通过 COSMO 框架,LLM 分析客户互动数据以发现隐藏的关系,例如将防滑鞋与孕妇联系起来。COSMO 构建了一个知识图谱,将 18 个类别的产品与相关的人类环境联系起来(例如,查询“孕妇的鞋子应提供防滑鞋”),为各种受众和用途提炼推荐。客户审核员确保这些洞察准确且相关。
请记住,以上只是LLM(大型语言模型)成功应用的最突出示例,可能还有很多其他应用。奥地利哲学家路德维希·维特根斯坦(Ludwig Wittgenstein)曾说:“我的语言的界限意味着我的世界的界限。”现在可能是时候让大型语言模型为您的业务拓展这些界限了。






