最新LangChain+GLM4开发AI应用程序系列(一):快速入门篇
要想开发出优秀的AI应用程序,除了有性能强大的大语言模型(后续简称LLM)作基础,优秀的提示词工程技术,借助检索增强生成从外部知识库获取LLM不具备的专有知识,通过智能体对接外部工具扩展LLM能力,缺一不可。此外AI应用程序通常都需要经过多轮提示以及解析输出,并有机连接成一个整体,本质上是个链的过程,如何快速高效实现也是一个问题。
基于以上这些痛点,哈里森·蔡斯 (Harrison Chase) 于2022年10月创建了LangChain,使我们能更方便和快捷的开发出功能强大的AI应用程序。可以说,LangChain是目前最强的AI应用程序开发框架之一,从Java程序员的视角来说,它的地位就相当于Java界的Spring一样。
如何学习LangChain,官网上的使用说明文档最权威,但是官网文档的一大特定或者说是弊端就是,知识点不聚焦,比较零散,初学者一上来很难抓住重点。此外LangChain迭代速度很快,网上虽然也有不少此类文章,但大部分都有所过时。
基于此,我实践并整理了最新版的LangChain结合国内性价比最高的智谱AI GLM-4大模型的系列文章,希望能给大家起到一定的参考作用,同时也欢迎共同探讨。本篇文章是第一篇,从零开始带大家快速入门LangChain开发AI应用程序。
一、LangChain简介
LangChain本质上是一个用于开发由LLM驱动的应用程序的框架。它通过连接LLM和外部一切可以利用的能力,给应用程序赋能,使得应用程序能够具备上下文意识和推理能力。
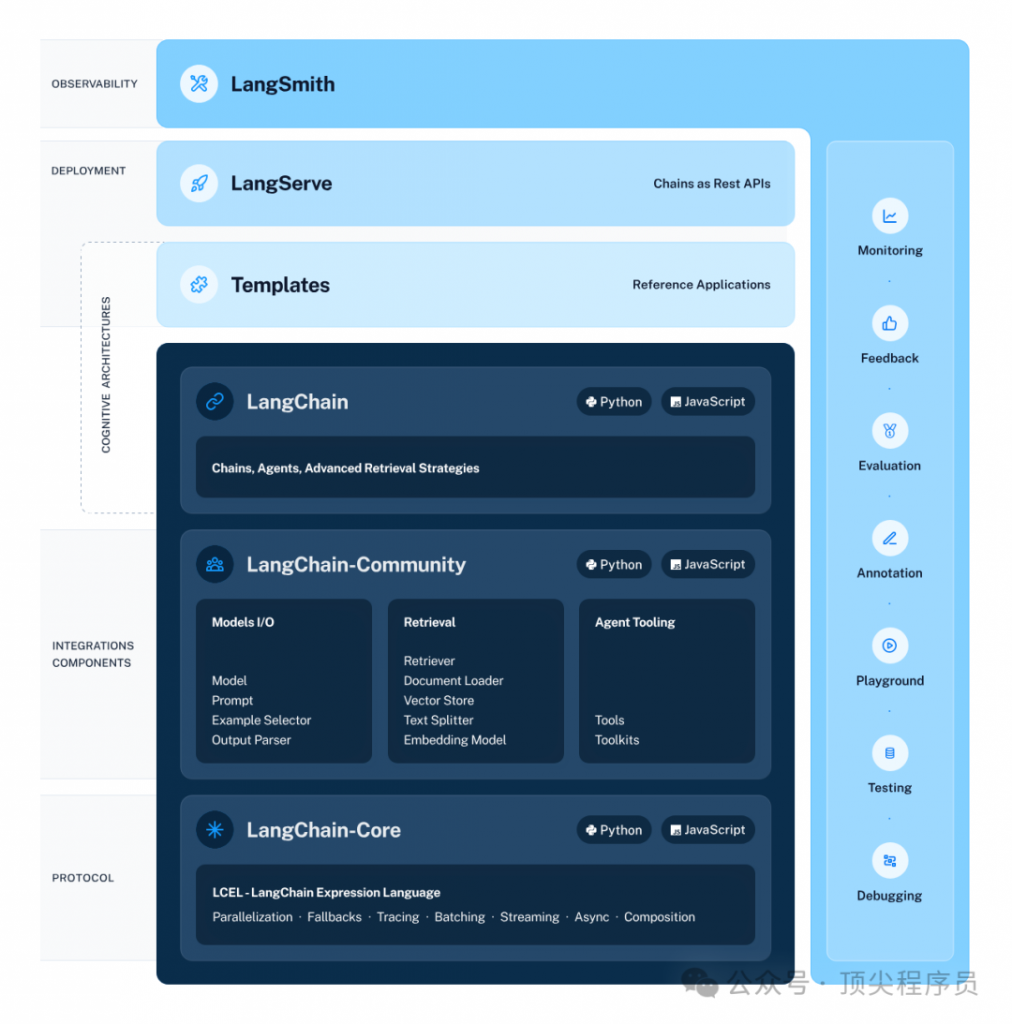
整个LangChain由六层组成,架构图如下。
最底层是协议层,包括LangChain表达语言(LCEL)和一些基础抽象类。主要是提示词模板、输出解析器、链的抽象类,通过LCEL语法以及管道的概念,来简化代码的开发。
第二层是集成组件层,包括各种大语言模型输入输出、外部知识库检索、智能体工具等第三方集成。具体的比如智谱AI大语言模型包装类、嵌入模型HuggingFaceEmbeddings、向量数据库FAISS等,都在这一层。
第三层是认知架构层,包括构成应用程序认知架构的链、智能体和检索策略。主要是链(Chains)、智能体(Agents)和检索策略的具体实现类。
第四层是应用模板层,包括各种参考应用模板。有多种可以快速运行部署的应用示例,参考价值还是比较高的。
第五层是部署层,LangServe,是一个用于将LangChain部署为REST API的库。
第六层是表现层,LangSmith,一个开发平台,允许调试、测试、评估和监控LangChain应用。
二、环境准备
在使用LangChain进行AI应用程序开发前,需要准备好相应的开发环境,包括Conda、Jupyter Notebook、使用的智谱AI GLM-4大模型。
1、安装Conda
使用Python的人都会遇到库的安装、环境的管理问题,Conda就是解决这些问题的一个工具,目前有AnaConda和MiniConda两种,都是Continuum Analytics的开源项目。这两种的区别就是:AnaConda大而全,预装了大部分科学计算库(99%其实用不上),提供了图形界面,适合初学者;MiniConda小而精,只有命令行。个人推荐使用MiniConda,比较轻量,节省时间和空间,需要什么再安装就可以。
MiniConda的下载地址如下:https://docs.conda.io/projects/miniconda/en/latest/ ,windows和mac版本都包括了,下载好直接安装即可。
创建虚拟环境:
conda create -n langchain python=3.9激活虚拟环境:
conda activate langchain2、安装Jupyter Notebook
为了能更方便编程和调试,及时执行代码块,我们使用Jupyter Notebook来作为Python集成开发工具。
在虚拟环境中安装Jupyter Notebook:
conda install jupyter notebook启动Jupyter notebook:
jupyter notebook3、安装LangChain
在Jupyter Notebook中进行操作,安装LangChain的最小集。
pip install --upgrade langchain4、调用智谱AI的GLM-4大模型
LLM的选择有多种方案。
方案一:远程调用OpenAI的ChatGPT系统API,效果较好,token花费较贵;
方案二:远程调用智谱AI的GLM-4的API,效果较好,token花费较低;
方案三:本地部署开源大语言模型ChatGLM3-6B,效果较差,不需要收费,但电脑需要有13GB以上的GPU。
综合考虑,方案二最理想。远程调用智谱AI的GLM-4的API的方式门槛最低,提示词工程的效果也比较好。目前智谱AI新注册会赠送18元金额,GLM-4是0.1元/1000tokens,实名认证的话会再送400万tokens(一个月内使用有效),算比较经济实惠的。注册地址:https://open.bigmodel.cn/。可以注册申请API key。
下面的操作都在Jupyter Notebook中进行。
安装智谱的SDK包:
pip install zhipuai由于最新的LangChain 0.1.7集成的ChatZhipuAI类和最新zhipuai SDK版本兼容性方面有问题,需要重新包装一个类。代码如下:
finish_reason = choice.get("finish_reason")
generation_info = (
dict(finish_reason=finish_reason) if finish_reason is not None else None
)
default_chunk_class = chunk.__class__
chunk = ChatGenerationChunk(message=chunk, generation_info=generation_info)
yield chunk
if run_manager:
run_manager.on_llm_new_token(chunk.text, chunk=chunk)import asyncio
import logging
from functools import partial
from importlib.metadata import version
from typing import (
Any,
Callable,
Dict,
Iterator,
List,
Mapping,
Optional,
Tuple,
Type,
Union,
)
from langchain_core.callbacks import (
AsyncCallbackManagerForLLMRun,
CallbackManagerForLLMRun,
)
from langchain_core.language_models.chat_models import (
BaseChatModel,
generate_from_stream,
)
from langchain_core.language_models.llms import create_base_retry_decorator
from langchain_core.messages import (
AIMessage,
AIMessageChunk,
BaseMessage,
BaseMessageChunk,
ChatMessage,
ChatMessageChunk,
HumanMessage,
HumanMessageChunk,
SystemMessage,
SystemMessageChunk,
ToolMessage,
ToolMessageChunk,
)
from langchain_core.outputs import (
ChatGeneration,
ChatGenerationChunk,
ChatResult,
)
from langchain_core.pydantic_v1 import BaseModel, Field
from packaging.version import parse
logger = logging.getLogger(__name__)
def is_zhipu_v2() -> bool:
"""Return whether zhipu API is v2 or more."""
_version = parse(version("zhipuai"))
return _version.major >= 2
def _create_retry_decorator(
llm: ChatZhipuAI,
run_manager: Optional[
Union[AsyncCallbackManagerForLLMRun, CallbackManagerForLLMRun]
] = None,
) -> Callable[[Any], Any]:
import zhipuai
errors = [
zhipuai.ZhipuAIError,
zhipuai.APIStatusError,
zhipuai.APIRequestFailedError,
zhipuai.APIReachLimitError,
zhipuai.APIInternalError,
zhipuai.APIServerFlowExceedError,
zhipuai.APIResponseError,
zhipuai.APIResponseValidationError,
zhipuai.APITimeoutError,
]
return create_base_retry_decorator(
error_types=errors, max_retries=llm.max_retries, run_manager=run_manager
)
def convert_message_to_dict(message: BaseMessage) -> dict:
"""Convert a LangChain message to a dictionary.
Args:
message: The LangChain message.
Returns:
The dictionary.
"""
message_dict: Dict[str, Any]
if isinstance(message, ChatMessage):
message_dict = {"role": message.role, "content": message.content}
elif isinstance(message, HumanMessage):
message_dict = {"role": "user", "content": message.content}
elif isinstance(message, AIMessage):
message_dict = {"role": "assistant", "content": message.content}
if "tool_calls" in message.additional_kwargs:
message_dict["tool_calls"] = message.additional_kwargs["tool_calls"]
# If tool calls only, content is None not empty string
if message_dict["content"] == "":
message_dict["content"] = None
elif isinstance(message, SystemMessage):
message_dict = {"role": "system", "content": message.content}
elif isinstance(message, ToolMessage):
message_dict = {
"role": "tool",
"content": message.content,
"tool_call_id": message.tool_call_id,
}
else:
raise TypeError(f"Got unknown type {message}")
if "name" in message.additional_kwargs:
message_dict["name"] = message.additional_kwargs["name"]
return message_dict
def convert_dict_to_message(_dict: Mapping[str, Any]) -> BaseMessage:
"""Convert a dictionary to a LangChain message.
Args:
_dict: The dictionary.
Returns:
The LangChain message.
"""
role = _dict.get("role")
if role == "user":
return HumanMessage(content=_dict.get("content", ""))
elif role == "assistant":
content = _dict.get("content", "") or ""
additional_kwargs: Dict = {}
if tool_calls := _dict.get("tool_calls"):
additional_kwargs["tool_calls"] = tool_calls
return AIMessage(content=content, additional_kwargs=additional_kwargs)
elif role == "system":
return SystemMessage(content=_dict.get("content", ""))
elif role == "tool":
additional_kwargs = {}
if "name" in _dict:
additional_kwargs["name"] = _dict["name"]
return ToolMessage(
content=_dict.get("content", ""),
tool_call_id=_dict.get("tool_call_id"),
additional_kwargs=additional_kwargs,
)
else:
return ChatMessage(content=_dict.get("content", ""), role=role)
def _convert_delta_to_message_chunk(
_dict: Mapping[str, Any], default_class: Type[BaseMessageChunk]
) -> BaseMessageChunk:
role = _dict.get("role")
content = _dict.get("content") or ""
additional_kwargs: Dict = {}
if _dict.get("tool_calls"):
additional_kwargs["tool_calls"] = _dict["tool_calls"]
if role == "user" or default_class == HumanMessageChunk:
return HumanMessageChunk(content=content)
elif role == "assistant" or default_class == AIMessageChunk:
return AIMessageChunk(content=content, additional_kwargs=additional_kwargs)
elif role == "system" or default_class == SystemMessageChunk:
return SystemMessageChunk(content=content)
elif role == "tool" or default_class == ToolMessageChunk:
return ToolMessageChunk(content=content, tool_call_id=_dict["tool_call_id"])
elif role or default_class == ChatMessageChunk:
return ChatMessageChunk(content=content, role=role)
else:
return default_class(content=content)
class ChatZhipuAI(BaseChatModel):
"""
ZHIPU AI large language chat models API.
To use, you should have the `zhipuai` python package installed.
Example:
.. code-block:: python
from langchain_community.chat_models import ChatZhipuAI
zhipuai_chat = ChatZhipuAI(
temperature=0.5,
api_key="your-api-key",
model_name="glm-3-turbo",
)
"""
zhipuai: Any
zhipuai_api_key: Optional[str] = Field(default=None, alias="api_key")
"""Automatically inferred from env var ZHIPUAI_API_KEY if not provided."""
client: Any = Field(default=None, exclude=True) #: :meta private:
model_name: str = Field("glm-3-turbo", alias="model")
"""
Model name to use.
-glm-3-turbo:
According to the input of natural language instructions to complete a
variety of language tasks, it is recommended to use SSE or asynchronous
call request interface.
-glm-4:
According to the input of natural language instructions to complete a
variety of language tasks, it is recommended to use SSE or asynchronous
call request interface.
"""
temperature: float = Field(0.95)
"""
What sampling temperature to use. The value ranges from 0.0 to 1.0 and cannot
be equal to 0.
The larger the value, the more random and creative the output; The smaller
the value, the more stable or certain the output will be.
You are advised to adjust top_p or temperature parameters based on application
scenarios, but do not adjust the two parameters at the same time.
"""
top_p: float = Field(0.7)
"""
Another method of sampling temperature is called nuclear sampling. The value
ranges from 0.0 to 1.0 and cannot be equal to 0 or 1.
The model considers the results with top_p probability quality tokens.
For example, 0.1 means that the model decoder only considers tokens from the
top 10% probability of the candidate set.
You are advised to adjust top_p or temperature parameters based on application
scenarios, but do not adjust the two parameters at the same time.
"""
request_id: Optional[str] = Field(None)
"""
Parameter transmission by the client must ensure uniqueness; A unique
identifier used to distinguish each request, which is generated by default
by the platform when the client does not transmit it.
"""
do_sample: Optional[bool] = Field(True)
"""
When do_sample is true, the sampling policy is enabled. When do_sample is false,
the sampling policy temperature and top_p are disabled
"""
streaming: bool = Field(False)
"""Whether to stream the results or not."""
model_kwargs: Dict[str, Any] = Field(default_factory=dict)
"""Holds any model parameters valid for create call not explicitly specified."""
max_tokens: Optional[int] = None
"""Number of chat completions to generate for each prompt."""
max_retries: int = 2
"""Maximum number of retries to make when generating."""
@property
def _identifying_params(self) -> Dict[str, Any]:
"""Get the identifying parameters."""
return {**{"model_name": self.model_name}, **self._default_params}
@property
def _llm_type(self) -> str:
"""Return the type of chat model."""
return "zhipuai"
@property
def lc_secrets(self) -> Dict[str, str]:
return {"zhipuai_api_key": "ZHIPUAI_API_KEY"}
@classmethod
def get_lc_namespace(cls) -> List[str]:
"""Get the namespace of the langchain object."""
return ["langchain", "chat_models", "zhipuai"]
@property
def lc_attributes(self) -> Dict[str, Any]:
attributes: Dict[str, Any] = {}
if self.model_name:
attributes["model"] = self.model_name
if self.streaming:
attributes["streaming"] = self.streaming
if self.max_tokens:
attributes["max_tokens"] = self.max_tokens
return attributes
@property
def _default_params(self) -> Dict[str, Any]:
"""Get the default parameters for calling ZhipuAI [API](https://www.explinks.com/wiki/api/)."""
params = {
"model": self.model_name,
"stream": self.streaming,
"temperature": self.temperature,
"top_p": self.top_p,
"do_sample": self.do_sample,
**self.model_kwargs,
}
if self.max_tokens is not None:
params["max_tokens"] = self.max_tokens
return params
@property
def _client_params(self) -> Dict[str, Any]:
"""Get the parameters used for the zhipuai client."""
zhipuai_creds: Dict[str, Any] = {
"request_id": self.request_id,
}
return {**self._default_params, **zhipuai_creds}
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
try:
from zhipuai import ZhipuAI
if not is_zhipu_v2():
raise RuntimeError(
"zhipuai package version is too low"
"Please install it via 'pip install --upgrade zhipuai'"
)
self.client = ZhipuAI(
api_key=self.zhipuai_api_key,
# 填写您的 APIKey
)
except ImportError:
raise RuntimeError(
"Could not import zhipuai package. "
"Please install it via 'pip install zhipuai'"
)
def completions(self, **kwargs) -> Any | None:
return self.client.chat.completions.create(**kwargs)
async def async_completions(self, **kwargs) -> Any:
loop = asyncio.get_running_loop()
partial_func = partial(self.client.chat.completions.create, **kwargs)
response = await loop.run_in_executor(
None,
partial_func,
)
return response
async def async_completions_result(self, task_id):
loop = asyncio.get_running_loop()
response = await loop.run_in_executor(
None,
self.client.asyncCompletions.retrieve_completion_result,
task_id,
)
return response
def _create_chat_result(self, response: Union[dict, BaseModel]) -> ChatResult:
generations = []
if not isinstance(response, dict):
response = response.dict()
for res in response["choices"]:
message = convert_dict_to_message(res["message"])
generation_info = dict(finish_reason=res.get("finish_reason"))
if "index" in res:
generation_info["index"] = res["index"]
gen = ChatGeneration(
message=message,
generation_info=generation_info,
)
generations.append(gen)
token_usage = response.get("usage", {})
llm_output = {
"token_usage": token_usage,
"model_name": self.model_name,
"task_id": response.get("id", ""),
"created_time": response.get("created", ""),
}
return ChatResult(generations=generations, llm_output=llm_output)
def _create_message_dicts(
self, messages: List[BaseMessage], stop: Optional[List[str]]
) -> Tuple[List[Dict[str, Any]], Dict[str, Any]]:
params = self._client_params
if stop is not None:
if "stop" in params:
raise ValueError("stop found in both the input and default params.")
params["stop"] = stop
message_dicts = [convert_message_to_dict(m) for m in messages]
return message_dicts, params
def completion_with_retry(
self, run_manager: Optional[CallbackManagerForLLMRun] = None, **kwargs: Any
) -> Any:
"""Use tenacity to retry the completion call."""
retry_decorator = _create_retry_decorator(self, run_manager=run_manager)
@retry_decorator
def _completion_with_retry(**kwargs: Any) -> Any:
return self.completions(**kwargs)
return _completion_with_retry(**kwargs)
async def acompletion_with_retry(
self,
run_manager: Optional[AsyncCallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> Any:
"""Use tenacity to retry the async completion call."""
retry_decorator = _create_retry_decorator(self, run_manager=run_manager)
@retry_decorator
async def _completion_with_retry(**kwargs: Any) -> Any:
return await self.async_completions(**kwargs)
return await _completion_with_retry(**kwargs)
def _generate(
self,
messages: List[BaseMessage],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
stream: Optional[bool] = None,
**kwargs: Any,
) -> ChatResult:
"""Generate a chat response."""
should_stream = stream if stream is not None else self.streaming
if should_stream:
stream_iter = self._stream(
messages, stop=stop, run_manager=run_manager, **kwargs
)
return generate_from_stream(stream_iter)
message_dicts, params = self._create_message_dicts(messages, stop)
params = {
**params,
**({"stream": stream} if stream is not None else {}),
**kwargs,
}
response = self.completion_with_retry(
messages=message_dicts, run_manager=run_manager, **params
)
return self._create_chat_result(response)
async def _agenerate(
self,
messages: List[BaseMessage],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
stream: Optional[bool] = False,
**kwargs: Any,
) -> ChatResult:
"""Asynchronously generate a chat response."""
should_stream = stream if stream is not None else self.streaming
if should_stream:
stream_iter = self._astream(
messages, stop=stop, run_manager=run_manager, **kwargs
)
return generate_from_stream(stream_iter)
message_dicts, params = self._create_message_dicts(messages, stop)
params = {
**params,
**({"stream": stream} if stream is not None else {}),
**kwargs,
}
response = await self.acompletion_with_retry(
messages=message_dicts, run_manager=run_manager, **params
)
return self._create_chat_result(response)
def _stream(
self,
messages: List[BaseMessage],
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> Iterator[ChatGenerationChunk]:
"""Stream the chat response in chunks."""
message_dicts, params = self._create_message_dicts(messages, stop)
params = {**params, **kwargs, "stream": True}
default_chunk_class = AIMessageChunk
for chunk in self.completion_with_retry(
messages=message_dicts, run_manager=run_manager, **params
):
if not isinstance(chunk, dict):
chunk = chunk.dict()
if len(chunk["choices"]) == 0:
continue
choice = chunk["choices"][0]
chunk = _convert_delta_to_message_chunk(
choice["delta"], default_chunk_class
)
finish_reason = choice.get("finish_reason")
generation_info = (
dict(finish_reason=finish_reason) if finish_reason is not None else None
)
default_chunk_class = chunk.__class__
chunk = ChatGenerationChunk(message=chunk, generation_info=generation_info)
yield chunk
if run_manager:
run_manager.on_llm_new_token(chunk.text, chunk=chunk)创建调用的对话大模型对象,api key需要修改成你自己的:
# 填写您自己的APIKey
ZHIPUAI_API_KEY = "..."
llm = ChatZhipuAI(
temperature=0.1,
api_key=ZHIPUAI_API_KEY,
model_name="glm-4",
)三、AI应用程序开发入门
环境准备好之后,就可以开始使用LangChain进行应用程序开发的入门,介绍了简单LLM链、检索链、智能体三个示例程序,通过一步一步操作,让大家快速入门。
1、简单LLM链(LLM Chain)
1)上面已经安装并创建了智谱AI大模型,现在可以直接调用它。
llm.invoke("langsmith如何帮助测试?")结果:
AIMessage(content='LangSmith 是一个旨在帮助开发者将大语言模型(LLM)应用程序从原型阶段推进到生产阶段的全栈开发平台。在测试方面,LangSmith 提供了一系列功能和工具来支持开发者对 LLM 应用进行全面的测试,确保其性能、可靠性和稳定性。以下是 LangSmith 在测试方面如何提供帮助的几个方面:nn1. **调试工具**:LangSmith 为开发者提供了调试工具,可以帮助他们理解模型的输出以及其在特定输入下的行为。这包括错误追踪和日志分析功能,使得开发者可以快速定位并解决模型在运行时出现的问题。nn2. **跟踪功能**:它允许开发者跟踪模型的使用情况,包括性能指标和错误率,从而帮助开发者监控模型在实际使用中的表现。nn3. **集成测试框架**:LangSmith 可能提供了集成测试框架,使得开发者可以编写测试用例来验证模型的预期行为。这包括单元测试和集成测试,以确保模型在各种条件下都能正确运行。nn4. **Prompt 优化**:在生成式语言模型中,Prompt(提示)的设计对输出质量至关重要。LangSmith 可能提供了Prompt优化工具,帮助开发者测试和比较不同Prompt对模型输出的影响。nn5. **模型评估**:LangSmith 可能包括模型评估功能,这允许开发者测试模型的性能,并与其他[模型或数据](https://www.explinks.com/blog/yq-deepspeed-chat-model-and-data)集进行比较,以确保模型能够满足生产环境中的需求。nn6. **监控和指标**:它可能提供了实时监控功能,帮助开发者收集和分析模型的性能指标,如响应时间、错误率等,从而持续监控模型的健康状况。nn通过这些功能,LangSmith 帮助开发者确保他们的 LLM 应用程序在推向生产之前经过了严格的测试,能够提供稳定和高质量的输出。这对于确保企业级应用的可靠性、一致性和用户满意度至关重要。')2)在LangChain中,可以使用提示词模板,将原始用户输入转换为更好的 LLM 输入。提示词模板是LangChain的一大提效法宝。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_messages([
("system", "你是世界级的技术文档作者。"),
("user", "{input}")
])然后可以将提示词、LLM组合成一个简单的LLM链。Chain是LangChain的核心,最新的版本使用了Unix经典的管道方式来连接,相比之前简洁了很多。
chain = prompt | llm调用LLM链。
chain.invoke({"input": "langsmith如何帮助测试?"})结果:
AIMessage(content='Langsmith是一个机器学习模型,旨在帮助开发人员创建、理解和测试自然语言处理(NLP)模型。作为一个技术文档作者,我可以为你提供一个关于Langsmith如何帮助测试的概述:nn1. **自动化测试生成**:Langsmith可以自动生成用于测试NLP模型的示例输入和预期输出。这可以节省开发人员的时间,并确保测试覆盖了各种可能的输入情况。nn2. **测试用例优化**:Langsmith能够识别测试用例中的冗余或低效部分,并提出优化的建议。这有助于提高测试的效率和准确性。nn3. **模型行为分析**:通过分析NLP模型的行为,Langsmith可以帮助识别模型的潜在问题和缺陷。这有助于在模型部署之前发现并修复问题。nn4. **测试结果评估**:Langsmith可以评估测试结果,提供关于模型性能的详细反馈。这有助于开发人员了解模型的表现,并确定是否需要进一步的改进。nn5. **集成与协作**:Langsmith可以与其他开发工具和平台集成,以便在模型的开发和测试过程中提供无缝的支持。这有助于提高团队协作和开发效率。nn总的来说,Langsmith可以作为一个强大的工具,帮助开发人员创建高质量的NLP模型,并通过自动化和优化测试过程来提高测试效率和准确性。')3)可以看到,输出结果是一个AIMessage消息对象。很多情况使用字符串要方便得多,可以添加一个字符串输出解析器来将聊天消息转换为字符串。输出解析器也是LangChain的一大提效法宝。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_messages([
("system", "你是世界级的技术文档作者。"),
("user", "{input}")
])
output_parser = StrOutputParser()
chain = prompt | llm | output_parser
chain.invoke({"input": "langsmith如何帮助测试?"})输出结果变成了字符串类型:
'Langsmith是一个机器学习模型,旨在帮助开发人员创建、理解和测试自然语言处理(NLP)模型。作为一个技术文档作者,我可以为你提供一个关于Langsmith如何帮助测试的概述:nn1. **自动化测试生成**:Langsmith可以自动生成用于测试NLP模型的示例输入和预期输出。这可以节省开发人员的时间,并确保测试覆盖了各种可能的输入情况。nn2. **测试用例优化**:Langsmith能够识别测试用例中的冗余或低效部分,并提出优化的建议。这有助于提高测试的效率和准确性。nn3. **模型行为分析**:通过分析NLP模型的行为,Langsmith可以帮助识别模型的潜在问题和缺陷。这有助于在模型部署之前发现并修复问题。nn4. **测试结果评估**:Langsmith可以评估测试结果,提供关于模型性能的详细反馈。这有助于开发人员了解模型的表现,并确定是否需要进一步的改进。nn5. **集成与协作**:Langsmith可以与其他开发工具和平台集成,如Jenkins、GitHub等,以便在模型开发和测试过程中实现自动化和协作。nn总的来说,Langsmith作为一个AI工具,旨在简化NLP模型的测试过程,提高测试的质量和效率,并帮助开发人员更快地构建和部署可靠的NLP解决方案。'本示例通过提示词模板、LLM、输出解析器,以管道的方式组成一个链,可以快速的调用AI大模型,实现一个简单的AI应用程序。
2、检索链(Retrieval Chain)
之前简单LLM链示例里问的问题(“langsmith 如何帮助测试?”),完全是依赖大语言模型已有的知识来进行回答。当我们有更专业更准确的知识时,可以通过检索的方式从外部获取最相关的知识,然后作为背景知识传递给大语言模型,来获得更精准的结果。
1)首先从互联网获取数据
需要先安装BeautifulSoup:
pip install beautifulsoup4导入并使用WebBaseLoader。官网原示例的"https://docs.smith.langchain.com/overview" 这个地址是错误的,改成:"https://docs.smith.langchain.com"
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://docs.smith.langchain.com")
docs = loader.load()2)接下来需要使用嵌入模型进行向量化,再存储到向量数据库。
因为OpenAIEmbeddings嵌入模型需要和OpenAI ChatGPT配套使用。我们换成更通用的HuggingFaceEmbeddings。
from langchain_community.embeddings import HuggingFaceEmbeddingsembeddings = HuggingFaceEmbeddings()
现在可以使用此嵌入模型将文档提取到向量存储中了,为了简单起见,使用了本地向量数据库FAISS 。
首先安装FAISS所需的软件包:
pip install faiss-cpu然后在向量数据库中建立索引:
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter()
documents = text_splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embeddings)3)创建一个检索链。该链将接受传入的问题,查找相关文档,然后将这些文档与原始问题一起传递给LLM并要求其回答原始问题。
首先,建立一个文档链,该链接受问题和检索到的文档并生成答案。
from langchain.chains.combine_documents import create_stuff_documents_chain
prompt = ChatPromptTemplate.from_template("""仅根据所提供的上下文回答以下问题:
{context}
问题: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)使用检索器动态选择最相关的文档,并将其传递给检索链。
from langchain.chains import create_retrieval_chain
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)调用检索链,得到答案。
response = retrieval_chain.invoke({"input": "langsmith如何帮助测试?"})
print(response["answer"])结果:
根据上下文信息,LangSmith 是一个用于构建生产级大型语言模型(LLM)应用程序的平台。它可以让用户调试、测试、评估和监控基于任何[LLM框架构](https://www.explinks.com/blog/summary-of-large-model-techniques)建的链和智能代理。LangSmith 与 [LangChain 无缝集成](https://www.explinks.com/blog/wx-openai-assistants-api-minimal-intro-with-langchain-integration),LangChain 是一个用于与 LLMs 一起构建的开源框架。
具体来说,LangSmith 帮助测试的方式可能包括:
1. **调试**:提供调试工具和界面,帮助开发者发现并修复代码中的错误。
2. **监控**:在模型运行时监控其性能,确保其按照预期工作,并及时发现异常。
3. **评估**:提供评估功能,让开发者可以测试智能代理的响应和行为是否符合预期。
4. **集成**:与 LangChain 无缝集成,使得测试基于 LangChain 构建的 LLM 应用更为方便。
开发者可以使用 LangSmith 提供的文档和指南来学习如何使用这些测试功能。此外,LangSmith 可能还提供了一些示例和教程,帮助用户更好地理解和应用测试工具。
请注意,上述解释是基于提供的上下文信息推测的,具体langsmith如何帮助测试的详细信息需要查阅其官方文档或联系其技术支持以获得更准确的答案。本示例首先获取外部互联网页面数据,经过嵌入模型对数据进行向量化,存储到向量数据库,当用户输入提示词时,到向量数据库中获取相关信息作为背景知识一起输入给LLM,最后LLM输出更准确的信息。通过这种检索增强生成的方式,可以方便的构建一些面向特定私有化知识领域的专用AI应用程序。后续会有一篇文章专门深入的介绍检索增强生成方面的应用。
3、智能体(Agent)
所谓智能体,实际上是指预先提供多种工具(tools),智能体调用LLM根据我们的问题决定使用某种工具,进而调用工具获得需要的信息,再把需要的信息发送给LLM,获得最终结果。工具可以是LangChain内置的工具,也可以是自定义的工具,比如通过网络进行搜索获取信息的工具、数学计算的工具、我们自己定义的特定功能函数等。
在这个示例中,我们给智能体提供了两个工具:一个是刚才创建的有关 LangSmith的检索器,另一个是能够回答最新信息的搜索工具。
1)首先,为刚才创建的检索器设置一个工具,名字叫"langsmith_search":
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"langsmith_search",
"搜索有关LangSmith的信息。关于LangSmith的任何问题,您都可以使用这个工具",
)2)对于另一个搜索工具,需要使用到Tavily,需要用到API 密钥,从https://app.tavily.com/home网站上可以免费申请。
然后设置为环境变量:
export TAVILY_API_KEY=...创建搜索工具:
from langchain_community.tools.tavily_search import TavilySearchResults
search = TavilySearchResults()3)创建智能体使用的工具列表:
–
tools = [retriever_tool, search]4)接下来可以创建智能体来使用这些工具。
首先安装langchain hub,这个网站上提供了很多提示词模板,可以直接使用。
pip install langchainhub获取提示词和创建智能体执行器。这里做了些优化,create_openaifunctionsagent换成了create_openai_tools_agent,"hwchase17/openai-functions-agent"换成了"hwchase17/openai-tools-agent"。
from langchain import hub
from langchain.agents import create_openai_tools_agent
from langchain.agents import AgentExecutor
# Get the prompt to use - you can modify this!
prompt = hub.pull("hwchase17/openai-tools-agent")
agent = create_openai_tools_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)4)现在可以调用智能体了。先向它询问有关 LangSmith 的问题:
agent_executor.invoke({"input": "langsmith如何帮助测试?"})结果如下,可以看到LLM先根据问题确定要使用"langsmith_search"工具,然后LangChain调用"langsmith_search"工具从向量数据库中获得相关信息,最后返回信息给LLM得到最终结果。
> Entering new AgentExecutor chain...
Invoking: langsmith_search with {'query': 'langsmith如何帮助测试'}
LangSmith | ️️ LangSmith
Skip to main content️️ LangSmith DocsLangChain [API key](https://www.explinks.com/blog/api-key-what-is-an-api-key/), and configure your environment.Pricing: Learn about the pricing model for LangSmith.Self-Hosting: Learn about self-hosting options for LangSmith.Tracing: Learn about the tracing capabilities of LangSmith.Evaluation: Learn about the evaluation capabilities of LangSmith.Prompt Hub Learn about the Prompt Hub, a prompt management tool built into LangSmith.Additional ResourcesLangSmith Cookbook: A collection of tutorials and end-to-end walkthroughs using LangSmith.LangChain Python: Docs for the Python LangChain library.LangChain [Python API](https://www.explinks.com/blog/sa-creating-python-apis) Reference: documentation to review the core APIs of LangChain.LangChain JS: Docs for the TypeScript LangChain libraryDiscord: Join us on our Discord to discuss all things LangChain!Contact SalesIf you're interested in enterprise security and admin features, special deployment options, or access for large teams, reach out to speak with sales.NextUser GuideIntroductionQuick StartNext StepsAdditional ResourcesCommunityDiscordTwitterGitHubDocs CodeLangSmith SDKPythonJS/TSMoreHomepageBlogCopyright © 2024 LangChain, Inc.LangSmith 是一个用于构建生产级 LLM 应用程序的平台。它可以让您调试、测试、评估和监控基于任何 LLM 框架构建的链和智能代理,并且可以无缝地与 LangChain 集成,LangChain 是构建 LLM 的首选开源框架。LangSmith 是由 LangChain 开发的,LangChain 是 LLM 应用程序生命周期各个阶段的 workflow 支持,例如调试、测试、评估和监控。此外,LangSmith 还提供了 Prompt Hub,这是一个内置的提示管理工具,可以让您轻松地管理和维护提示。
> Finished chain.
[31]:
{'input': 'langsmith如何帮助测试?',
'output': 'LangSmith 是一个用于构建生产级 LLM 应用程序的平台。它可以让您调试、测试、评估和监控基于任何 LLM 框架构建的链和智能代理,并且可以无缝地与 LangChain 集成,LangChain 是构建 LLM 的首选开源框架。LangSmith 是由 LangChain 开发的,LangChain 是 LLM 应用程序生命周期各个阶段的 workflow 支持,例如调试、测试、评估和监控。此外,LangSmith 还提供了 Prompt Hub,这是一个内置的提示管理工具,可以让您轻松地管理和维护提示。'}5)再询问下天气情况:
agent_executor.invoke({"input": "旧金山的天气怎么样?"})结果如下,可以看到LLM先根据问题确定要使用"tavily_search_results_json"工具,然后LangChain调用"tavily_search_results_json"工具从互联网上获得相关信息,最后返回信息给LLM得到最终结果。
> Entering new AgentExecutor chain...
Invoking: tavily_search_results_json with {'query': '旧金山的天气'}
[{'url': 'https://tianqi.2345.com/america_united-states/san-francisco-ca/', 'content': '2345天气预报提供旧金山天气预报,未来旧金山15天天气,通过2345天气预报详细了解旧金山天气预报以及旧金山周边各地区未来15天、30天天气情况,温度,空气质量,降水,风力,气压,紫外线强度等! ... 您使用的浏览器版本过低! ...'}, {'url': 'https://zh.weather-forecast.com/locations/San-Francisco/forecasts/latest', 'content': '邻近旧金山的实时气象站n*注意:并非所有旧金山附近的气象站会同时更新,我们只显示最近气象站的报告 被视为当前的。还包括在可接受的时间范围内旧金山 附近的任何船舶(SYNOP)提交的天气报告。Read Moren旧金山 Location mapn加利福尼亚州天气地图n加利福尼亚州天气地图n旧金山的天气照片n上传一幅 旧金山的天气照片 | 上传另一个城市n目的地旧金山附近城市的天气预报:n© 2024 Meteo365.com Very mild (max 14°C on Fri morning, min 8°C on Wed night). Very mild (max 14°C on Fri morning, min 8°C on Wed night). Very mild (max 11°C on Sat afternoon, min 7°C on Thu night). Very mild (max 15°C on Sat afternoon, min 10°C on Mon night).'}, {'url': 'http://www.weather.com.cn/weather/401640100.shtml', 'content': '【旧金山天气】旧金山天气预报,天气预报一周,天气预报15天查询 预报 美国>旧金山(Sanfrancisco) 18:00更新 数据来源 中央气象台 今天 周末 7天 8-15天 10日(今天) 晴转阴 16 / 8℃ 4-5级转3-4级 11日(明天) 小雨转阴 14 / 7℃ <3级 12日(后天) 阴 13 / 8℃ <3级 13日(周二) 阴 13 / 7℃ <3级 14日(周三) 小雨转阴 13 / 8℃ <3级 15日(周四) 多云转阴 14 / 8℃ Finished chain.
[25]:
{'input': '旧金山的天气怎么样?',
'output': '旧金山现在的天气我无法获取,但是根据tavily_search_results_json的结果,最近旧金山的天气情况如下:今天是晴天,最高温度为16°C,最低温度为8°C。明天有小雨,最高温度为14°C,最低温度为7°C。后天天气阴,最高温度为13°C,最低温度为8°C。'}本示例通过给智能体提供多种工具(有关LangSmith的检索器、回答最新信息的搜索工具),智能体调用LLM根据我们的问题决定使用某种工具,进而调用工具获得需要的信息,再把需要的信息发送给LLM,获得最终结果。通过这种工具增强的方式,可以构建集成特定应用的AI应用程序,比如在应用程序中集成在线购物、自定义的数据计算等实用功能。后续会有一篇文章专门深入的介绍智能体工具方面的应用。
四、总结
本文是最新版LangChain使用智谱AI的GLM-4大模型开发AI应用程序系列的第一篇文章-快速入门篇。
首先对LangChain做了介绍,LangChain是哈里森·蔡斯 (Harrison Chase) 于2022年10月创建的,对于AI应用程序开发来说,它的地位就相当于Java界的Spring。LangChain的整体架构分为六层,它的核心概念就是链,链接外部一切能链接的东西赋予LLM力量。
然后从零基础开始介绍了LangChain环境的安装和配置,包括Conda、Jupyter Notebook、LangChain,以及智谱AI GLM-4在LangChain的最新调用API。
最后再通过LLM链、检索链、智能体三个经典的示例,带大家一步一步的快速上手了提示词模板、输出解析器、管道、LLM链、检索链、智能体等功能的使用和开发。
希望能给大家起到一定的参考作用,同时也欢迎共同探讨。后续文章会继续深入分析检索链、智能体等的使用,敬请期待。
文章转自微信公众号@顶尖程序员