大模型基座及API应用
在这篇文章开始之前,发个前段时间看到的笑话。
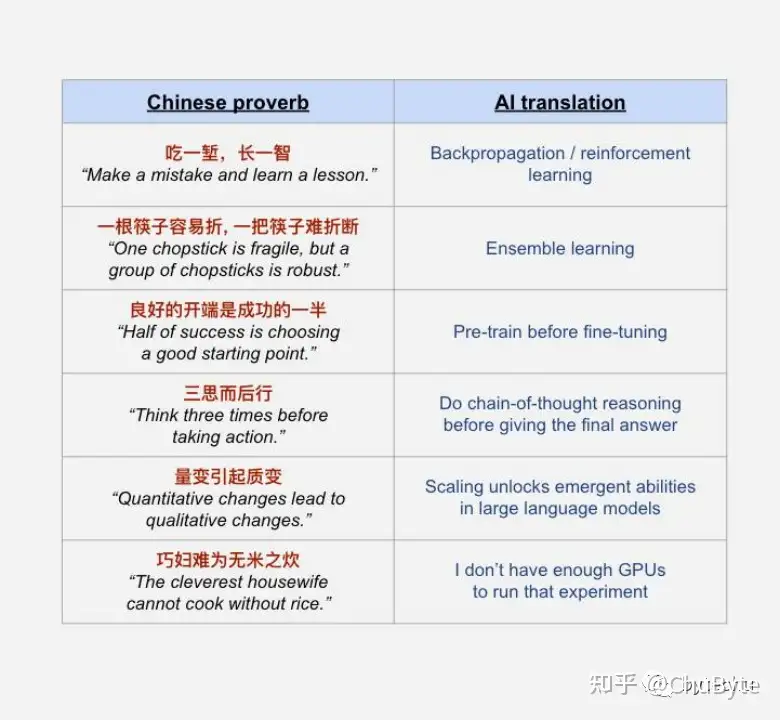
如果看完会心一笑,那么建议您继续阅读接下来的内容 🙂
趁着公司180B大模型即将上线,将自己最近的思考做个总结,这篇算是公司产品及商业的一个宣传。
TigerBot是公司自主研发的LLM(大语言模型)的名称。
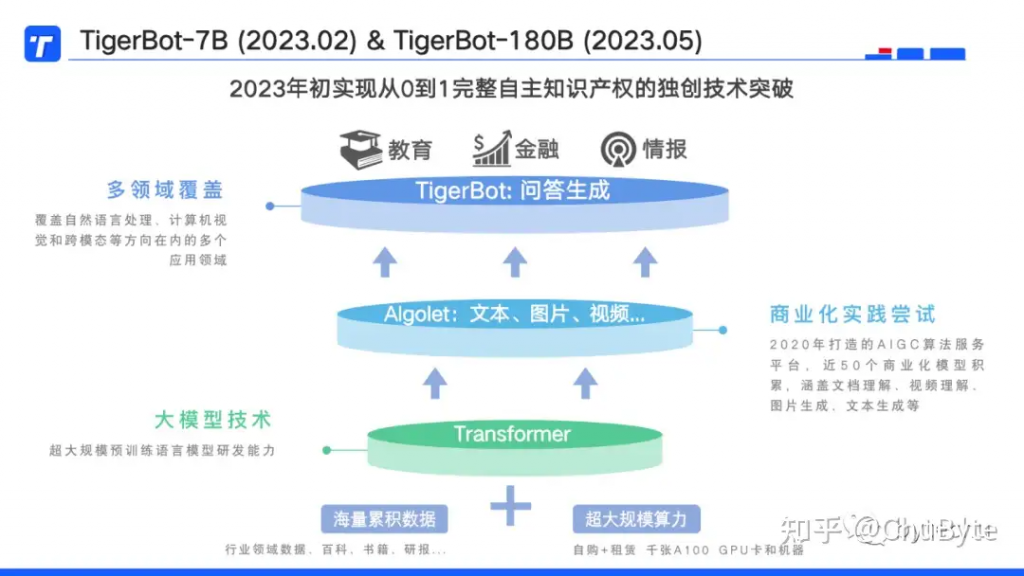
我们都知道LLM的研发离不开“海量的数据”、“超大规模的算力”、“核心的算法”三要素。
数据层面:拥有多年积累的行业高质量数据,以及对这些数据处理的经验,公开的资料表明:GPT3采集了45T的互联网公开数据,清洗过滤后只有570G进入到大模型中进行预训练,因此LLM研发前期很大的工作投入和成本需要花在数据层面,这是研发大模型的第一个门槛。尤其在中文语境下,要面临更加复杂的语言体系。
算力层面:目前拥有自购及长期租赁的千张A100 GPU显卡,幸好我们下手早,GPU市场现在待价而沽,其中各种“见闻”略过不表。顺便说一句,因为各家都在推出“自研”的大模型,可谓百“模”齐放,如果某个公司号称自研了商用千亿参数模型,但是他们储备的GPU却不多,那么这句话的真实性就很可疑了。目前GPU成了很多企业从零开始训练LLM的第二个门槛。
核心算法:由我司NLP领域世界级科学家,也是公司创始人兼CEO亲自Coding,当然大家炼丹的步骤都是公开且一致的,大规模预训练语言模型+SFT(有监督的指令微调)+RLHF(基于人工反馈的强化学习),这里面有很多算法及工程上技巧,成为了第三个门槛。市面上目前有很多开源的大模型方案,说实话优秀的不多。
TigerBot分为两个版本,一个是2月份开发完成的7B(70亿)参数模型,另一个是即将推出的180B(1800亿)参数模型。
TigerBot有哪些能力?
目前我们仅对7B模型做了总结,180B后续会有单独文章做介绍,受限于7B的参数和训练数据的局限性,目前拥有的包括自回归模型最擅长的生成类能力,包括开放问答、头脑风暴、润色重写、代码生成等,这类能力基本是大模型公司的标配,在此放上申请链接(https://www.tigerbot.com/),有兴趣可以直接申请账号体验。
同时LLM作为AI 2.0时代的拐点技术,以跨场景、多任务的统一模型对AI 1.0时代通过小模型进行单任务、多模型的限制进行了突破,作为基座模型可以通过0-shot、few-shot等低成本的方式适配各类五花八门的任务,包括摘要总结、情感分类、抽取等,从而可以实现规模化、平台化效应,这也是为什么LLM被称为AI的“iPhone”时刻的原因之一。
这里重点介绍下,TigerBot如何解决LLM的“幻觉”和“数据滞后”问题,LLM虽然很强大,但是也存在一些缺陷,其中一个是“幻觉”,也就是大家常说的会一本正经的胡说;另一个是“数据滞后”,由于LLM训练一次成本非常高,不可能将最新的数据实时放在预训练模型中。
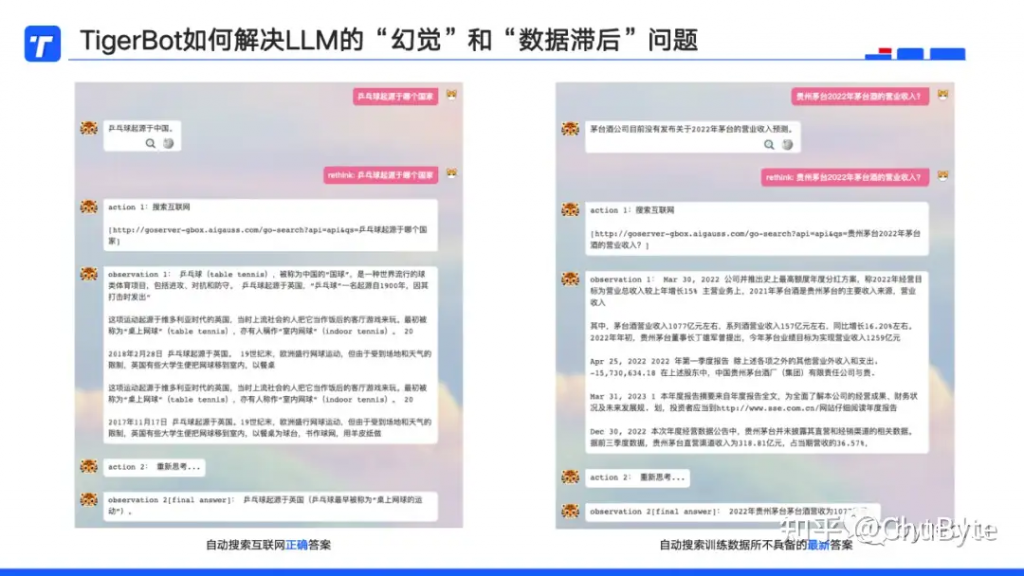
上图是两种缺陷的例子,以及如何通过插件的方式开发了Rethink功能,将提问的问题通过Plug-in的方式,搜索互联网信息/访问最新的研报知识库,将问题和检索结果放入LLM中提问,从而获得正确的答案。BTW:New Bing和LangChain也是采用的类似技术。
TigerBot LLM基座的优势做个小结:自主可控、垂直专业,更懂中文,以及支持私有化部署。下图是私有化部署所需的最低配置。

这里稍微展开讲下更懂中文,一个国家/民族的语言与思维、世界观、价值观有很强的内在关联,听过一则趣闻,Sam Altman曾被问到为什么ChatGPT生成的夸Trump的字数比Biden的少?这里涉及到非英语语言世界关乎意识形态的深刻问题,也是为什么国家对于大模型始终保持谨慎踩刹车态度的原因之一。
TigerBot API生态和应用
接下来介绍下LLM基座之上规划的API生态及相关应用。
TigerBot API分为三类:
1、Chat-API:将LLM的问答能力以API方式进行暴露,从而可以调取使用;
2、Plug-in:一种外挂的插件能力,将大模型不具备的或者私域知识以“外脑”的方式进行挂载使用;
3、Fine-Tune:是一种改进预训练模型性能的技术,通过提供指令集和调整模型部分参数的方式,教授模型特定任务或模式,使其能够在特定领域更有效地执行。
Chat-API
下图是API的接入界面,左侧的模型即为Chat-API,另外包括完整的Plugin和FineTune接口流程及规范,支持Python、cURL等方式接入。
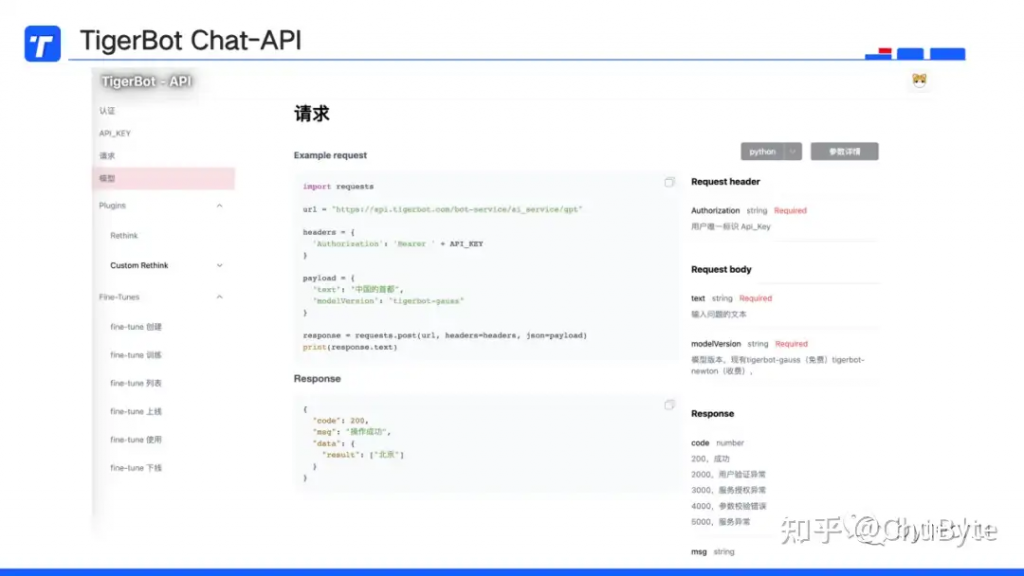
Chat-API的使用非常简洁,填入自己的API_KEY,需要LLM回答的问题,选择LLM版本,即可与TigerBot进行交互,返回生成的答案。
有些人可能会问Chat-API如何应用,其实这就是最近很火的Prompt Engineering(提示工程)。

吴恩达甚至专门开设了一系列课程《prompt-engineering-for-developers》来介绍,课程里有一个核心的观点:“问对问题是使用好大语言模型的关键”。
我们看到市面上已经有非常多基于大模型的应用被开发出来,包括英语口语对聊、虚拟男/女友,代码优化查Bug,产品评价内容智能回复等,这些应用短则只需一分钟就可以开发出来,因为它的功能模块编写非常简单,上图右下方就是每个应用的开发编程语言。
很多人对编程语言的印象还停留在Java、C++、Python等,在大模型时代,以自然语言就可以实现功能模块的编写,毕竟无论编程语言还是自然语言,都是一种语言,以前要专人帮忙把你的需求翻译成计算机语言,从而产生了程序员角色,今后可以直接通过描述需求的方式让大模型实现。
在使用Chat-API的过程中,有两个可以提升大模型答案效果的技巧:
1. 更明确具体的指令:
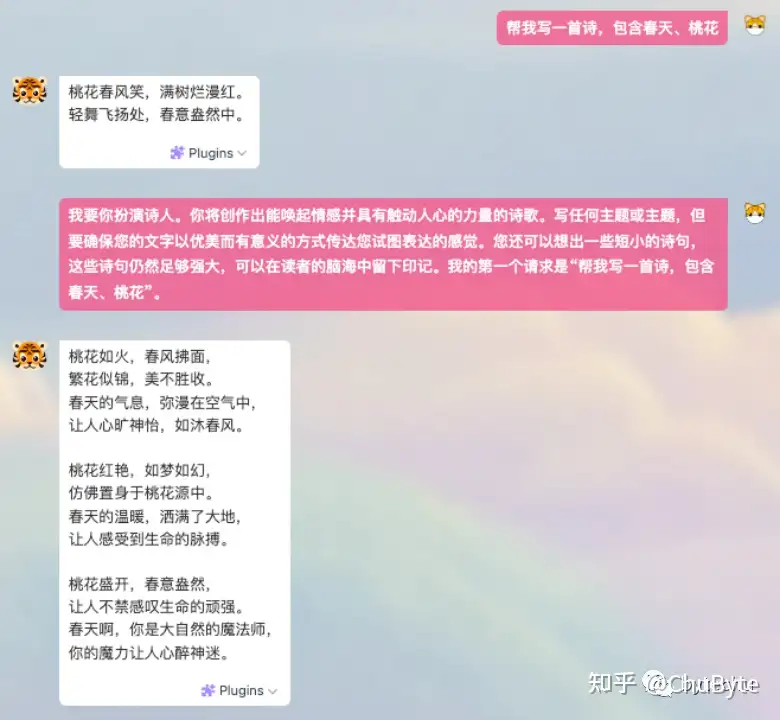
比如我们想让大模型写一首诗,一般人会想到的是“帮我写一首诗,包含春天、桃花”,此时大模型会输出一段贴合需求的诗。
但是如果你这样描述Prompt:“我要你扮演诗人。你将创作出能唤起情感并具有触动人心的力量的诗歌。写任何主题或主题,但要确保您的文字以优美而有意义的方式传达您试图表达的感觉。您还可以想出一些短小的诗句,这些诗句仍然足够强大,可以在读者的脑海中留下印记。我的第一个请求是“帮我写一首诗,包含春天、桃花”。”以这样的指令,将同样的需求给到LLM,那么就可以得到一个效果更好的答案。
2. 给大模型多个示例:
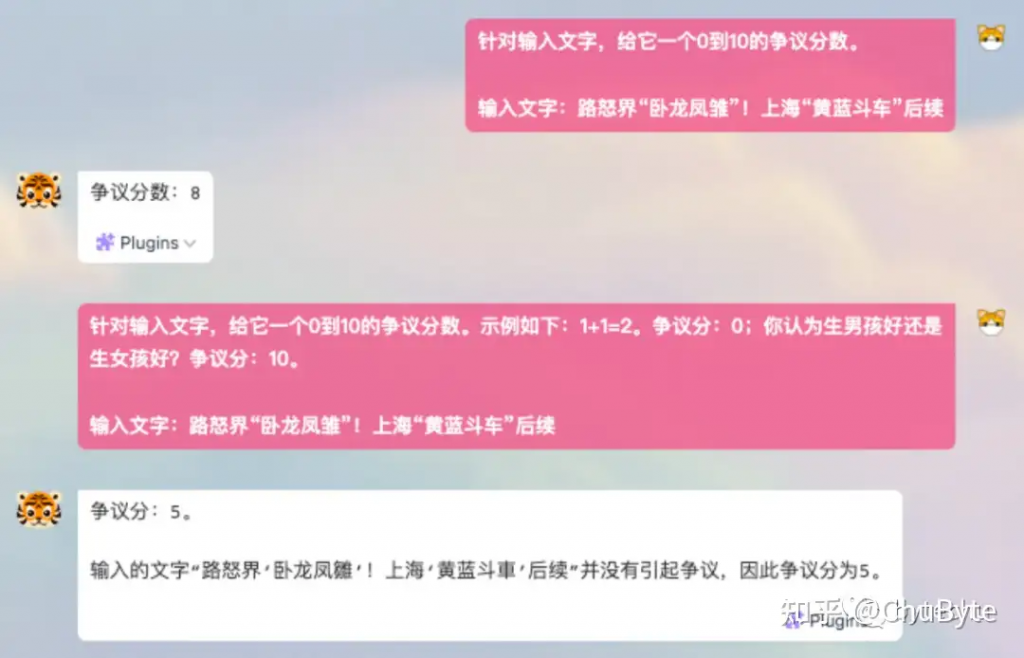
假设现在有这样一个需求,开发一个文本争议度打分模型,在AI 2.0时代,你所需要做的仅仅只需要一句话:“针对输入文字,给它一个0到10的争议分数。输入文字:路怒界“卧龙凤雏”!上海“黄蓝斗车”后续”,模型即可对你输入的文字进行打分。
但是如果你补充一些示例:“针对输入文字,给它一个0到10的争议分数。示例如下:1+1=2。争议分:0;你认为生男孩好还是生女孩好?争议分:10。输入文字:路怒界“卧龙凤雏”!上海“黄蓝斗车”后续”,那么得到的分数会更加准确。
Plug-in
第二类API就是Plug-in,目前拥有内置的插件和支持自定义插件开发。
内置Plugins包括:
- wiki:百科类
- internet:网络搜索引擎
- finace_research:金融研报/年报
- law:法律条款
直接在答案右下角选择对应的插件即可体验使用。
自定义插件也非常简单,仅仅只需要三步骤:
- 创建Plugin名称
- 按格式导入数据集(Datasets)
- 根据Plugin ID调用Plugin

如上图右侧的例子,当提问法律问题“胎儿尚未出生,其父亲因车祸不幸身亡,胎儿是否有权继承父亲的遗产?”
由于7B的TigerBot并未利用法律文书进行预训练,因此给出的答案认为遗腹子不能继承遗产,但我们可以通过law plugin(法律插件)查询《民法典》从而得到正确的答案:“胎儿虽然不是被继承人的法定继承人,但胎儿的出生并不意味着其与被继承人的亲属关系被消灭。胎儿出生后,其父亲所遗留的遗产仍应被继承。因此,胎儿有权利继承父亲的遗产。”
Plug-in可以应用于:查找最新的事件,检索内部私域的非公开文档,以及突破大模型的输入Token限制。
Plug-in的原理是一种先search后ask的流程,将外挂知识处理成一段段的文本块,再将其表示为向量存储进行索引,插件在运行过程中会将问题与答案所在的文本块进行向量匹配,将可能存在答案的所有文本块与问题拼接后,一并放入大模型中进行提问,从而得到正确答案。
Plug-in的优势尤其是在大型数据集中,可以用更低的计算成本,更快的搜索相关信息,同时还能防止“幻觉”导致的虚构或捏造事实。在很多领域都可以进行实际应用,比如可以基于TigerBot等大模型结合药品说明书、病历等开发自己的医药问诊插件,结合工厂的规章制度文件、检修报告开发工业故障巡检插件。
Fine-Tune
第三类API是Fine-Tune,借助TigerBot基座模型,利用行业及内部数据,快速微调定制属于自己的大语言模型。
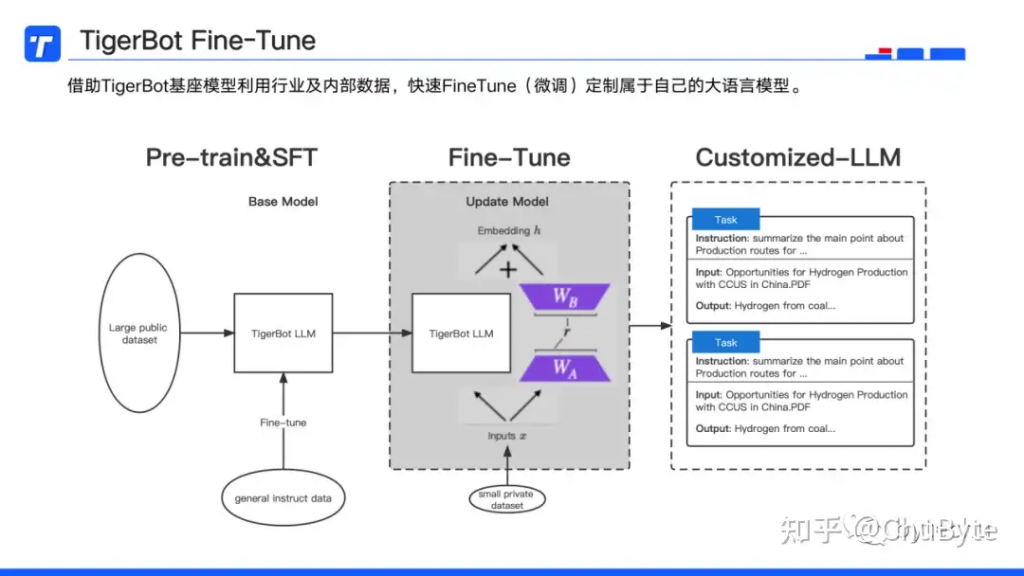
之前对比图可以看到Fine-Tune存在计算成本较高,灵活适应性较低等问题。因此是否选择微调LLM,具体取决于自身具体要求、行业性质和特殊目标,我这里整理了如下几个适合选择微调的应用场景:
- 定制化需求:企业通常具有通用语言模型可能无法解决的独特需求和目标,微调使其能够定制模型的行为以适应他们的特定目标,例如生成个性化的营销文案,一般来说大模型生成的文字都比较书面,如果希望以李佳琦的风格在小红书上写推广文案,那么就需要拿到相关数据进行微调定制化大模型。
- 数据敏感和合规性要求:处理敏感数据或在严格监管环境下运营的企业,需要微调模型以确保遵循其隐私要求,遵守其内容准则并生成符合国家及行业法规要求的内容。
- 领域特定术语:许多行业使用的行话、技术术语和专业词汇可能无法在LLM的通用训练数据中得到很好的体现,对特定领域数据的模型进行微调,使其能够在业务行业的背景下理解并生成准确的答案。
- 任务性能增强:微调可提高模型在与业务相关的特定任务或应用程序上的性能,例如:1)情绪分析;2)文本分类;3)信息提取。微调可以带来更好的决策、更高的效率和更好的结果。
- 改善用户体验:经过微调的模型可以通过生成更准确、相关和上下文感知的答案来提供更好的用户体验,从而提高客户满意度,例如:聊天机器人,客户支持系统等。
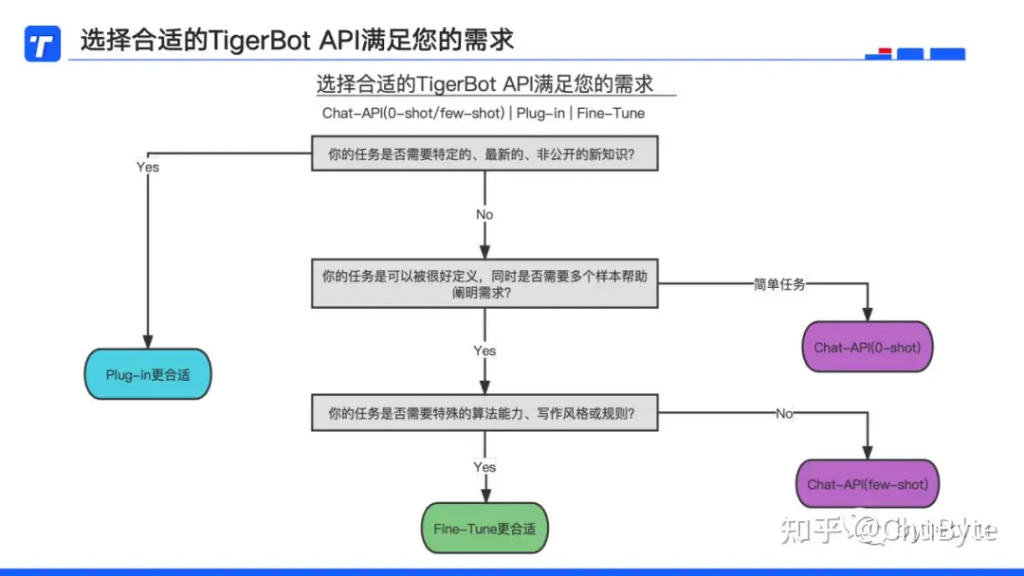
最后以一张图做个总结,也是给各位希望结合大模型赋能自身业务的企业一个选择路径参考。
原文链接:大模型基座及API应用