使用Flask、Google Cloud SQL和App Engine设置API
Flask 使开发人员能够为各种用例构建 API。在本教程中,Wole Oyekanmi 将指导您如何设置 Google Cloud、Cloud SQL 和 App Engine,以构建 Flask API。Cloud SQL 是一个完全托管的平台即服务(PaaS)数据库引擎,而 App Engine 则是一个用于托管应用程序的完全托管式 PaaS。
在创建 API 时,Python 提供了多个框架供开发人员选择,其中 Flask 和 Django 是两个常用的选项。这些框架自带的功能有助于开发人员轻松实现用户与应用程序之间的交互。选择框架时,Web 应用程序的复杂性可能是一个关键因素。
Django
Django 是一个功能强大的框架,具有预定义的结构和内置功能。然而,对于某些项目来说,它的复杂性可能会使框架显得过于庞大,最适合需要利用 Django 高级功能的复杂 Web 应用程序。
Flask
相比之下,Flask 是一个轻量级的框架,非常适合用于构建 API。它易于上手,并提供了一些软件包以增强其运行时的健壮性。本文将重点介绍如何定义视图函数和控制器,以及如何连接到 Google Cloud 上的数据库,并将应用程序部署到 Google Cloud。
为了学习目的,我们将构建一个包含几个端点的 Flask API,用于管理我们最喜欢的歌曲集合。这些端点将支持 GET 和 POST 请求,以实现资源的获取和创建。此外,我们还将使用 Google Cloud 平台上的服务套件,包括为数据库设置 Google 的 Cloud SQL,并通过部署到 App Engine 来启动我们的应用程序。本教程面向首次尝试使用 Google Cloud 的初学者。
设置 Flask 项目
本教程假定您已安装 Python 3.x。如果没有,请前往官方网站下载并安装它。
要检查是否安装了 Python,请启动命令行界面 (CLI) 并运行以下命令:
python -V我们的第一步是创建我们的项目所在的目录。我们称之为:flask-app
mkdir flask-app && cd flask-app启动 Python 项目时,首要任务是创建一个虚拟环境。虚拟环境能够隔离您当前的 Python 开发工作,确保每个项目都拥有独立的依赖项,互不干扰。venv 是 Python 3 自带的一个模块,用于创建虚拟环境。
让我们在flask-app目录中创建一个虚拟环境:
python3 -m venv env此命令会在我们的目录中创建一个名为 env 的文件夹(env 是虚拟环境的别名,可以自定义为其他名称)。
创建完虚拟环境后,我们需要激活它,以便项目能够使用。激活虚拟环境的命令如下:
source env/bin/activate您将会看到命令行界面(CLI)提示符的开头显示为 (env),这表明我们的虚拟环境已经被成功激活。
现在,让我们安装我们的 Flask 包:
pip install flask在当前目录中,我们需要创建一个名为 api 的文件夹。创建这个文件夹的目的是为了容纳我们的应用程序的其他子文件夹和文件。
mkdir api && cd api接下来,创建一个main.py文件,它将作为我们应用程序的入口点:
touch main.py打开main.py,输入以下代码:
#main.py
from flask import Flask
app = Flask(__name__)
@app.route('/')
def home():
return 'Hello World'
if __name__ == '__main__':
app.run()让我们来回顾一下我们所做的步骤。首先,我们从 Flask 包中导入了 Flask 类。接着,我们创建了这个类的一个实例,并将其赋值给变量 app。随后,我们定义了第一个端点,它对应于应用的根路径。简而言之,这个端点是一个视图函数,当用户访问根路径时会调用它,并返回 “Hello World” 的响应。
让我们运行应用程序:
python main.py这将启动我们的本地服务器,它会在 https://127.0.0.1:5000/ 上为我们的 Flask 应用程序提供服务。只需在浏览器中输入这个 URL,您就能在屏幕上看到 “Hello World” 的响应。
看!我们的 Flask 应用程序已经成功启动并运行了。接下来,我们的任务是确保它能够正常工作,并进行一些扩展。
为了测试和调用我们的 API 端点,我们将使用 Postman,这是一个专为开发人员设计的用于测试 API 端点的服务。您可以从 Postman 的官方网站下载并安装它。
现在,让我们修改 main.py 文件,让它返回一些实际的数据,而不仅仅是 “Hello World”。
#main.py
from flask import Flask, jsonify
app = Flask(__name__)
songs = [
{
"title": "Rockstar",
"artist": "Dababy",
"genre": "rap",
},
{
"title": "Say So",
"artist": "Doja Cat",
"genre": "Hiphop",
},
{
"title": "Panini",
"artist": "Lil Nas X",
"genre": "Hiphop"
}
]
@app.route('/songs')
def home():
return jsonify(songs)
if __name__ == '__main__':
app.run()在这里,我们定义了一个包含歌曲列表的数组,每首歌曲都有标题和艺术家名字。接着,我们将根路由 / 更改为 /songs。这个新的路由会返回我们指定的歌曲数组。为了将列表以 JSON 格式返回,我们使用了 jsonify 函数来转换列表。现在,当我们访问 https://127.0.0.1:5000/songs 时,不再看到简单的 “Hello World” 响应,而是会看到包含艺术家和歌曲标题的列表。
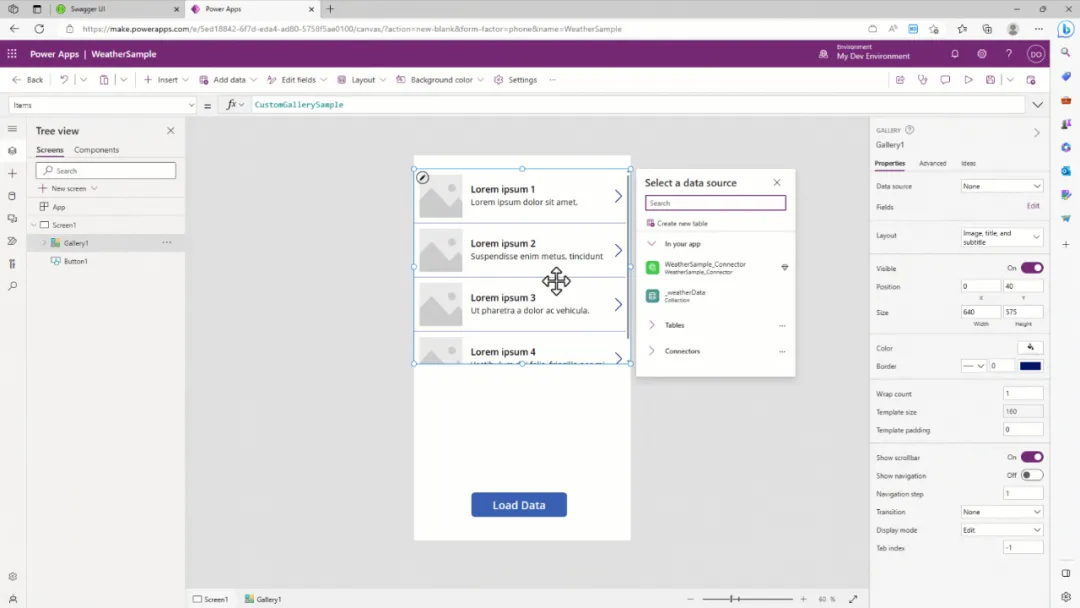
get回应(大预览)您可能已经注意到,在每次对代码进行更改后,都需要手动重新启动服务器才能看到效果。为了能够在代码更改时自动重新加载服务器,我们可以启用 Flask 的 debug 选项。要实现这一点,只需将 app.run() 调用修改为包含 debug=True 参数,如下所示:
app.run(debug=True)接下来,让我们使用post请求向数组中添加一首歌曲。首先,导入request对象,这样我们就可以处理来自用户的传入请求。稍后我们将在view函数中使用request对象来获取JSON格式的用户输入。
#main.py
from flask import Flask, jsonify, request
app = Flask(__name__)
songs = [
{
"title": "Rockstar",
"artist": "Dababy",
"genre": "rap",
},
{
"title": "Say So",
"artist": "Doja Cat",
"genre": "Hiphop",
},
{
"title": "Panini",
"artist": "Lil Nas X",
"genre": "Hiphop"
}
]
@app.route('/songs')
def home():
return jsonify(songs)
@app.route('/songs', methods=['POST'])
def add_songs():
song = request.get_json()
songs.append(song)
return jsonify(songs)
if __name__ == '__main__':
app.run(debug=True)我们的add_songs view函数接受用户提交的歌曲,并将其添加到现有的歌曲列表中。
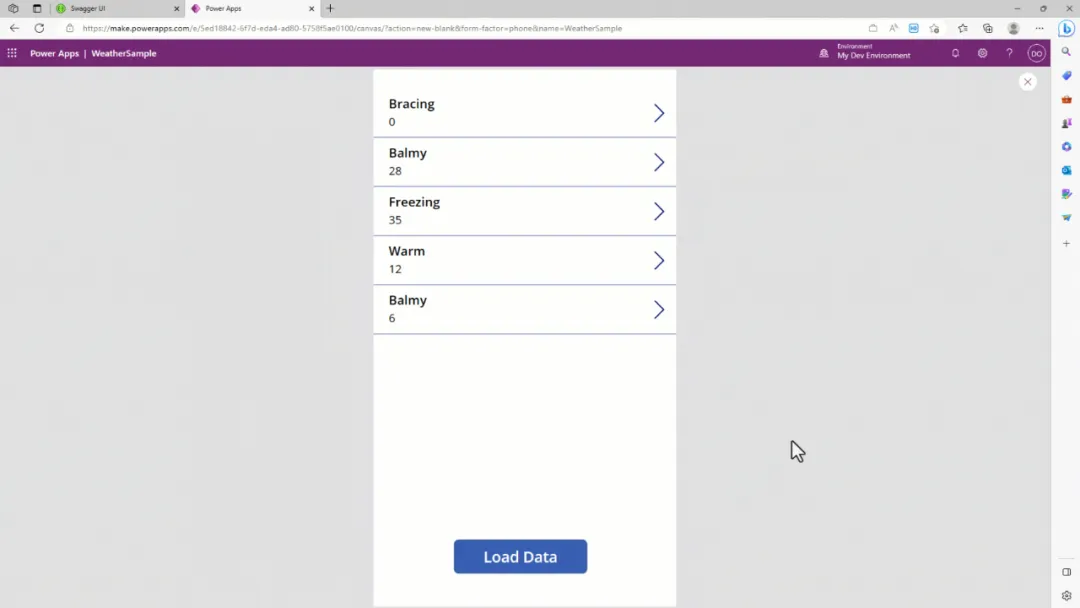
到目前为止,我们都是从 Python 列表中返回数据的,但这只是实验性的做法,因为在更实际的应用场景中,如果我们重新启动服务器,之前添加的数据就会丢失,这显然是不可行的,因此,我们需要一个实时的数据库来存储和检索数据,这就是 Cloud SQL 的用武之地。
为什么要使用 Cloud SQL 实例?
根据 Google 官方网站的介绍:
Google Cloud SQL 是一项完全托管的数据库服务,能够轻松地在云中设置、维护、管理和操作关系型 MySQL 和 PostgreSQL 数据库。Cloud SQL 托管在 Google Cloud Platform 上,为在任何位置运行的应用程序提供数据库基础架构支持。
这意味着我们可以将数据库基础设施的管理完全外包给 Google,同时享受灵活的定价策略。
Cloud SQL 和自我管理的计算引擎之间的区别
在 Google Cloud 上,我们可以在 Compute Engine 基础设施上启动虚拟机,并在其上安装 SQL 实例。但这样做的话,我们就需要负责垂直可扩展性、复制以及许多其他配置工作。而使用 Cloud SQL,我们可以获得大量开箱即用的配置,从而能够将更多时间花在编写代码上,减少设置和配置的时间。
在我们开始使用 Cloud SQL 之前,需要先完成以下准备工作:
- 注册 Google Cloud 账号。Google 会为新用户提供 300 美元的免费积分。
- 在 Google Cloud 控制台中创建一个新项目。这个过程非常简单,可以直接通过控制台完成。
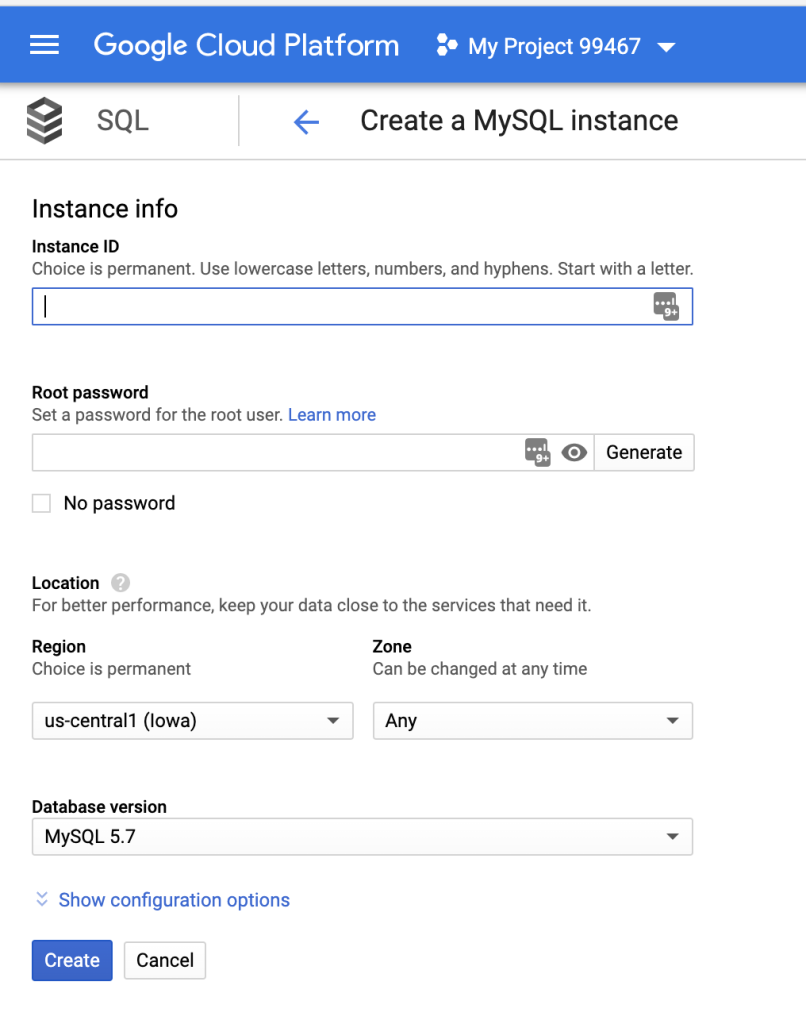
创建 Cloud SQL 实例
注册 Google Cloud 后,在左侧面板中,滚动到“SQL”选项卡并单击它。

首先,我们需要选择一个 SQL 引擎。在本文中,我们将使用 MySQL。
接下来,我们将创建一个 Cloud SQL 实例。默认情况下,实例将在美国创建,并且区域会自动为我们选择。
在设置过程中,我们需要为实例设置 root 密码并命名,然后点击“创建”按钮。如果想要进一步自定义实例的配置,可以点击“显示配置选项”下拉列表。这些设置允许我们调整实例的大小、存储容量、安全性、可用性、备份等参数。不过,在本文中,我们将使用默认设置来简化流程。请放心,这些设置在未来是可以更改的。
实例的创建过程可能需要几分钟时间。当看到绿色的对勾标记时,就意味着实例已经准备就绪。此时,可以点击实例的名称进入详细信息页面。
现在,我们的 Cloud SQL 实例已经启动并运行,接下来我们需要完成以下任务:
- 创建一个数据库。
- 创建一个新用户。
- 将我们的 IP 地址添加到白名单中。
创建数据库
导航到 “Database” 选项卡以创建数据库。
创建新用户
在 “Host name” 部分中,将其设置为允许 “% (any host)”。
将 IP 地址列入白名单
要连接到数据库实例,您可以选择使用私有 IP 地址或公共 IP 地址。使用私有 IP 地址需要配置 Virtual Private Cloud(VPC)。在本文中,我们选择使用公共 IP 地址,因为这是默认选项且更为简便。尽管公共 IP 地址是公开的,但只有那些 IP 地址已被列入白名单的用户才能访问数据库,从而确保了安全性。
要将您的 IP 地址添加到白名单中,请首先在搜索引擎中输入“my ip”以获取您的当前 IP 地址。然后,在 Cloud SQL 控制台中,转到“连接”选项卡,并选择“添加网络”。在出现的窗口中,输入您刚才获取的 IP 地址,以便将其添加到允许访问数据库的白名单中。
连接到实例
接下来,导航到“概述”面板并使用 Cloud Shell 进行连接。
控制台中会预先提供用于连接到 Cloud SQL 实例的命令。
您可以选择使用 root 用户或之前创建的其他用户进行连接。以下命令示例展示了如何以用户 flask-demo 的身份连接到名为 USERNAME 的实例(请将 USERNAME 替换为实际的实例名):
系统会提示您输入该用户的密码以完成连接。
gcloud sql connect flask-demo --user=USERNAME如果您收到一条错误消息,指出您没有项目 ID,您可以通过运行以下命令来获取项目的 ID:
gcloud projects list取上面命令输出的项目ID,并将其输入到下面的命令中,将PROJECT_ID替换为它。
gcloud config set project PROJECT_ID然后,运行gcloud sql connect命令,我们将连接。
运行以下命令以查看活动数据库:
> show databases;
“显示数据库”的Shell输出(大预览)
我的数据库名为db_demo,我将运行下面的命令来使用db_demo数据库。您可能会看到其他一些数据库,例如information_schema和performance_schema。它们用于存储表Meta数据。
> use db_demo;接下来,创建一个表,该表镜像 Flask 应用程序中的列表。在记事本上键入以下代码并将其粘贴到 Cloud Shell 中:
create table songs(
song_id INT NOT NULL AUTO_INCREMENT,
title VARCHAR(255),
artist VARCHAR(255),
genre VARCHAR(255),
PRIMARY KEY(song_id)
);这段代码是一个SQL命令,它创建了一个名为songs的表,其中有四列(song_id、title、artist和genre)。我们还指示表应该将song_id定义为主键,并从1自动递增。
现在,运行show tables;以确认表已创建。
“show tables”的Shell输出(大预览)
就这样,我们已经成功创建了一个数据库以及名为 songs 的表。
接下来,我们的任务是配置 Google App Engine,以便能够部署我们的应用程序。
Google 应用引擎
App Engine 是一个全面托管的平台,专为大规模开发和托管 Web 应用程序而设计。它的一大优势在于能够自动扩展应用程序以满足不断变化的流量需求。
App Engine 官网介绍道:
“借助零服务器管理和零配置部署,开发人员可以全身心地投入到构建卓越的应用程序中,而无需为管理事务分心。”
设置 App Engine
配置 App Engine 可以通过 Google Cloud Console 的用户界面完成,也可以通过 Google Cloud SDK 实现。在本节中,我们将采用 SDK 的方式。SDK 允许我们从本地计算机上部署、管理和监控 Google Cloud 实例。
安装 Google Cloud SDK
请按照提供的指南下载并安装适用于 Mac 或 Windows 的 SDK。安装完成后,您需要在命令行界面中初始化 SDK,并选择要操作的 Google Cloud 项目。
现在,SDK 已经准备就绪,接下来我们将更新 Python 脚本,添加数据库凭证,并将应用程序部署到 App Engine。
本地设置
为了适应新的架构(包括 Cloud SQL 和 App Engine),我们需要在本地环境中进行相应的设置更新。
首先,我们需要在项目的根文件夹中添加一个名为 app.yaml 的文件。这是 App Engine 托管和运行应用程序所必需的配置文件。它包含了 App Engine 运行应用程序所需的运行时环境和其他变量信息。对于我们的应用程序,我们需要将数据库凭证作为环境变量添加到 app.yaml 文件中,以便 App Engine 能够识别并连接到我们的数据库实例。
在 app.yaml 文件中,添加以下代码片段。您需要根据在设置 Cloud SQL 时获取的信息,替换运行时环境和数据库变量的值,包括用户名、密码、数据库名称和连接名称。
#app.yaml
runtime: python37
env_variables:
CLOUD_SQL_USERNAME: YOUR-DB-USERNAME
CLOUD_SQL_PASSWORD: YOUR-DB-PASSWORD
CLOUD_SQL_DATABASE_NAME: YOUR-DB-NAME
CLOUD_SQL_CONNECTION_NAME: YOUR-CONN-NAME现在,我们将安装 PyMySQL。这是一个 Python MySQL 包,用于连接 MySQL 数据库并对其执行查询。通过在 CLI 中运行以下行来安装 PyMySQL 软件包:
pip install pymysql此时,我们已准备好使用 PyMySQL 从应用程序连接到我们的 Cloud SQL 数据库。这将使我们能够在数据库中获取和插入查询。
初始化数据库连接器
首先,在我们的根文件夹中创建db.py文件,并添加以下代码:
#db.py
import os
import pymysql
from flask import jsonify
db_user = os.environ.get('CLOUD_SQL_USERNAME')
db_password = os.environ.get('CLOUD_SQL_PASSWORD')
db_name = os.environ.get('CLOUD_SQL_DATABASE_NAME')
db_connection_name = os.environ.get('CLOUD_SQL_CONNECTION_NAME')
def open_connection():
unix_socket = '/cloudsql/{}'.format(db_connection_name)
try:
if os.environ.get('GAE_ENV') == 'standard':
conn = pymysql.connect(user=db_user, password=db_password,
unix_socket=unix_socket, db=db_name,
cursorclass=pymysql.cursors.DictCursor
)
except pymysql.MySQLError as e:
print(e)
return conn
def get_songs():
conn = open_connection()
with conn.cursor() as cursor:
result = cursor.execute('SELECT * FROM songs;')
songs = cursor.fetchall()
if result > 0:
got_songs = jsonify(songs)
else:
got_songs = 'No Songs in DB'
conn.close()
return got_songs
def add_songs(song):
conn = open_connection()
with conn.cursor() as cursor:
cursor.execute('INSERT INTO songs (title, artist, genre) VALUES(%s, %s, %s)', (song["title"], song["artist"], song["genre"]))
conn.commit()
conn.close()我们在这里完成了几个关键步骤来集成 Google App Engine 和 Cloud SQL。
首先,我们利用 app.yaml 文件从 os.environ.get 方法中检索数据库凭证。App Engine 能够使 app.yaml 中定义的环境变量在应用程序代码中轻松可用。
其次,我们创建了一个名为 open_connection 的函数,它使用这些凭证来建立与 MySQL 数据库的连接。
接着,我们添加了两个重要的函数:get_songs 和 add_songs。get_songs 函数通过调用 open_connection 函数来建立数据库连接,并查询 songs 表。如果表中没有记录,则返回“No Songs in DB”的消息。而 add_songs 函数则负责在 songs 表中插入新的记录。
最后,我们回到 main.py 文件,对代码进行了重构。现在,我们调用 add_songs 函数来插入新的歌曲记录,并调用 get_songs 函数从数据库中检索歌曲记录,而不是像之前那样从某个对象中获取歌曲数据。
现在,让我们来重构 main.py 文件,以确保它能够正确地与数据库进行交互。
#main.py
from flask import Flask, jsonify, request
from db import get_songs, add_songs
app = Flask(__name__)
@app.route('/', methods=['POST', 'GET'])
def songs():
if request.method == 'POST':
if not request.is_json:
return jsonify({"msg": "Missing JSON in request"}), 400
add_songs(request.get_json())
return 'Song Added'
return get_songs()
if __name__ == '__main__':
app.run()我们导入了 get_songs 和 add_songs 函数,并在 songs() 视图函数中根据请求类型分别调用它们。当接收到 POST 请求时,我们调用 add_songs 函数;当接收到 GET 请求时,我们调用 get_songs 函数。
至此,我们的应用程序已经开发完成。
接下来,我们需要添加 requirements.txt 文件。这个文件列出了运行应用程序所必需的所有程序包。App Engine 会自动检查这个文件,并安装其中列出的所有程序包,以确保应用程序能够顺利运行。
pip freeze | grep "Flask\|PyMySQL" > requirements.txt为了获取应用程序中使用的 Flask 和 PyMySQL 这两个包及其版本信息,我们创建了一个 requirements.txt 文件,并将这些信息追加到了该文件中。
至此,我们已经成功添加了三个新文件:db.py、app.yaml 和 requirements.txt。
部署到 Google App Engine
执行以下命令,部署您的应用。
gcloud app deploy如果运行顺利,您的控制台将输出以下内容:
您的应用现在正在App Engine上运行。要在浏览器中查看它,请在CLI中运行gcloud app browse。
我们可以启动Postman来测试我们的post和get请求。

get请求(大预览)我们的应用程序现已托管在 Google 的基础设施之上,能够充分利用无服务器架构所带来的各种优势,只需通过调整配置即可实现。展望未来,您可以基于本文的内容,进一步增强无服务器应用程序的健壮性。
结论
借助 App Engine 和 Cloud SQL 等平台即服务(PaaS)基础设施,我们得以从底层架构的繁琐事务中抽身,从而更专注于应用的快速构建。作为开发人员,我们无需再为配置管理、备份恢复、操作系统维护、自动扩展、防火墙设置以及流量迁移等事项而费心。当然,如果您对底层配置有着更为精细的控制需求,那么自定义构建的服务可能会是更好的选择。
原文链接:https://www.smashingmagazine.com/2020/08/api-flask-google-cloudsql-app-engine/