使用 TypeScript、PostgreSQL、Next.js、Prisma 和 GraphQL 的全栈应用程序:GraphQL API
文章目录
本文是课程的第二部分,您将使用Next.js、GraphQL、TypeScript、Prisma和PostgreSQL来构建一个全栈应用程序。在本文中,您将创建 GraphQL API 并在前端与其交互。

介绍
在本课程中,您将学习如何构建“awesome-links”,这是一个全栈应用程序,用户可以在其中浏览精选链接列表并为他们最喜欢的链接添加书签。
在上一部分中,您已经使用Prisma设置好了数据库层。当您完成本部分的学习后,将会对GraphQL有所了解:知道它是什么,以及如何在Next.js应用程序中利用它来构建API。
开发环境
要学习本教程,您需要安装 Node.js 和GraphQL 扩展。您还需要有一个正在运行的 PostgreSQL 实例。
注意:您可以选择在本地安装PostgreSQL,或者在Heroku上设置一个托管的数据库实例。但请注意,为了执行课程结束时的部署步骤,您将需要一个远程数据库。
克隆存储库
您可以在 GitHub 上找到该课程的完整源代码。
注:每篇文章都有相应的分支。这样,您就可以跟着进行。通过查看第 2 部分分支,您将获得与本文相同的起点。
首先,导航到您选择的目录并运行以下命令来克隆存储库。
git clone -b part-2 https://github.com/m-abdelwahab/awesome-links.git现在,您可以进入已克隆的目录,安装所需的依赖项,并启动开发服务器。
cd awesome-linksnpm installnpm run dev该应用程序将运行http://localhost:3000/,您将看到四个项目。数据是硬编码的,来源于/data/links.ts文件。

数据初始化
设置好PostgreSQL数据库后,请将env.example文件重命名为.env,并配置好数据库的连接字符串。接着,运行以下命令来在数据库中创建迁移和所需的表:
npx prisma migrate dev --name init如果prisma migrate dev没有触发种子步骤,请运行以下命令来初始化数据:
npx prisma db seed此命令将运行seed.ts位于/prisma目录中的脚本。此脚本使用 Prisma 客户端向您的数据库添加四个链接和一个用户。
查看项目结构和依赖关系
您将看到以下文件夹结构:
awesome-links/
┣ components/
┃ ┣ Layout/
┃ ┗ AwesomeLink.tsx
┣ data/
┃ ┗ links.ts
┣ pages/
┃ ┣ _app.tsx
┃ ┣ about.tsx
┃ ┗ index.tsx
┣ prisma/
┃ ┣ migrations/
┃ ┣ schema.prisma
┃ ┗ seed.ts
┣ public/
┣ styles/
┃ ┗ tailwind.css
┣ .env.example
┣ .gitignore
┣ next-env.d.ts
┣ package-lock.json
┣ package.json
┣ postcss.config.js
┣ README.md
┣ tailwind.config.js
┗ tsconfig.json这是一个 Next.js 应用程序,带有 TailwindCSS 和 Prisma 设置。
在该pages目录中,您将找到三个文件:
_app.tsx:全局App组件用于添加一个在页面切换之间持续显示的导航栏,并应用全局CSS样式。about.tsx:此文件导出一个 React 组件,该组件呈现位于http://localhost:3000/about 的页面。index.tsx:主页,其中包含链接列表。这些链接被硬编码在/data/links.ts文件中。
接下来,您将找到一个prisma包含以下文件的目录:
schema.prisma:我们数据库的模式,用 PSL(Prisma 模式语言)编写。seed.ts:使用虚拟数据为数据库播种的脚本。
以传统方式构建 API:REST
在课程的最后部分,您将利用Prisma来配置数据库层。紧接着的下一步,就是在数据模型的基础上构建API层,这将使得您能够从客户端接收请求或向其发送数据。
构造 API 的常见方法是让客户端向不同的 URL 端点发送请求。服务器将根据请求类型检索或修改资源并发回响应。这种架构风格称为 REST,它具有以下几个优点:
- 灵活:一个端点可以处理不同类型的请求
- 可缓存:您所需要做的就是缓存特定端点的响应数据
- 客户端和服务器分离:不同平台(例如Web应用程序、移动应用程序等)可以使用API
REST API 及其缺点
虽然 REST API 具有优点,但它们也有一些缺点。我们将以此awesome-links为例。
以下是构建 REST API 的一种可能方法:
| 资源 | HTTP方法 | 路线 | 描述 |
|---|---|---|---|
User | GET | /users | 返回所有用户及其信息 |
User | GET | /users/:id | 返回单个用户 |
Link | GET | /links | 返回所有链接 |
Link | GET, PUT,DELETE | /links/:id | 返回单个链接、更新或删除它。id是链接的 id |
User | GET | /favorites | 返回用户添加书签的链接 |
User | POST | /link/save | 添加指向用户收藏夹的链接 |
Link | POST | /link/new | 创建一个新链接(由管理员完成) |
每个 REST API 都是不同的
其他开发人员可能会根据自己的喜好和认为合适的方式来构建他们的REST API,这种灵活性确实带来了一定的代价,即每个API都可能存在差异。
这意味着每次使用 REST API 时,您都需要阅读其文档并了解:
- 不同的端点及其 HTTP 方法。
- 每个端点的请求参数。
- 每个端点返回哪些数据和状态代码。
当第一次使用 API 时,这种学习曲线会增加摩擦并降低开发人员的工作效率。
另一方面,构建 API 的后端开发人员需要管理它并维护其文档。
随着应用程序复杂度的提升,API也会相应地变得更加复杂:更多的需求会导致需要创建更多的端点来满足这些需求。
端点的增加很可能会带来两个问题:数据过度获取和数据获取不足。
过度获取和不足获取
当您获取的数据多于所需的数据时,就会发生过度获取。这会导致性能下降,因为您消耗了更多带宽。
另一方面,有时您可能会发现某个端点没有返回在用户界面(UI)上显示所需的所有信息,因此您最终不得不向另一个端点或多个端点发出请求来获取这些信息。这种做法会导致性能下降,因为需要执行大量的网络请求。
在“awesome-links”应用程序中,如果您希望页面显示所有用户及其链接,您将需要对端点进行 API 调用/users/,然后发出另一个请求以/favorites获取他们的收藏夹。
让/users端点返回用户及其收藏夹并不能解决问题。这是因为您最终会得到一个重要的 API 响应,需要很长时间才能加载。
REST API 未键入
REST API 的另一个缺点是它们没有类型。您不知道端点返回的数据类型,也不知道要发送的数据类型。这会导致对 API 做出假设,从而可能导致错误或不可预测的行为。
例如,在发出请求时,您是否将用户 ID 作为字符串或数字传递?哪些请求参数是可选的,哪些是必需的?这就是您需要依赖文档的原因,然而,随着API的不断演进,文档可能会变得不再准确或过时。尽管存在一些可以解决这些挑战的解决方案,但在本课程中我们不会详细介绍它们。
GraphQL的替代方案
GraphQL 是一种新的 API 标准,由 Facebook 开发并开源。它提供了一种比 REST 更高效、更灵活的替代方案,客户端可以准确接收其所需的数据。
您只需要将请求发送到单一的端点,而不是分别向一个或多个端点发送请求,然后再将它们的响应结果进行拼接。
以下是 GraphQL 查询的示例,该查询返回“awesome-links”应用程序中的所有链接。您稍后将在构建 API 时定义此查询:
query {
links {
id
title
description
}
}
即使链接有更多字段,API 也仅返回id和title。
注意:这是 GraphQL,一个运行 GraphQL 操作的游乐场。它提供了很好的功能,我们将更详细地介绍这些功能
现在您将了解如何开始构建 GraphQL API。
定义模式
这一切都是从GraphQL架构开始的,在这个架构中,您可以定义API所能执行的所有操作。同时,您还可以明确指定每个操作的输入参数以及预期的响应类型。
该模式充当客户端和服务器之间的契约。它还可以作为使用 GraphQL API 的开发人员的文档。您可以使用 GraphQL 的 SDL(模式定义语言)来定义模式。
让我们看看如何为“awesome-links”应用程序定义 GraphQL 模式。
定义对象类型和字段
您需要做的第一件事是定义一个对象类型。对象类型表示您可以从 API 获取的一种对象。
每种对象类型可以有一个或多个字段。由于您希望应用程序中有用户,因此您需要定义一个User对象类型:
type User {
id: ID
email: String
image: String
role: Role
bookmarks: [Link]
}
enum Role {
ADMIN
USER
}该User类型具有以下字段:
id,其类型为ID。email,其类型为String.image,其类型为String。role,其类型为Role。这是一个枚举,这意味着用户的角色可以采用两个值之一:USER或ADMIN。bookmarks,这是一个Link类型的数组。这意味着用户可以拥有多个链接。接下来,您将定义这个Link对象。
这是对象类型的定义:
type Link {
id: ID
category: String
description: String
imageUrl: String
title: String
url: String
users: [User]
}Link和User之间存在多对多的关系,因为一个Link可以有多个用户,同时一个User也可以有多个链接。这是使用Prisma在数据库中建模的。
定义查询
要从 GrahQL API 获取数据,您需要定义一个Query对象类型。在这种类型中,您可以定义每个 GraphQL 查询的入口点。对于每个入口点,您定义其参数及其返回类型。
这是返回所有链接的查询。
type Query {
links: [Link]!
}查询links返回类型为Link的数组。用于!指示该字段不可为 null,这意味着 API 在查询该字段时将始终返回一个值。
您可以根据要构建的 API 类型添加更多查询。对于“awesome-links”应用程序,您可以添加一个查询来返回单个链接,另一个查询返回单个用户,另一个查询返回所有用户。
type Query {
links: [Link]!
link(id: ID!): Link!
user(id: ID!): User!
users: [User]!
}这个查询接收一个类型为ID、名为id的参数(这个参数是必需的),并且返回一个Link类型的结果(响应结果不可为空)。其中,id用于指定要查询的链接的唯一标识符。
定义突变
要创建、更新或删除数据,您需要定义Mutation对象类型。按照约定,任何导致写入的操作都应通过突变显式发送。同样,您不应该使用GET请求来修改数据。
对于“awesome-links”应用程序,您将需要不同的突变来创建、更新和删除链接:
type Mutation {
createLink(category: String!, description: String!, imageUrl: String!, title: String!, url: String!): Link!
deleteLink(id: ID!): Link!
updateLink(category: String, description: String, id: String, imageUrl: String, title: String, url: String): Link!
}- 这个突变(Mutation)接收以下参数来创建一个新的链接
category、description、title、url以及imageUrl。所有这些字段都是字符串(String)类型,并且是必需的。此突变返回一个Link对象类型的结果。 - 该
deleteLink突变采用idof 类型ID作为必需参数。它返回一个必需的Link. - 突变
updateLink采用与突变createLink相同的参数,但是这些参数在updateLink中是可选的。这意味着,当您更新一个Link时,只需要传递您想要更新的那些字段。此突变返回一个Link对象,且该对象是必需的。
定义查询和突变的实现
到目前为止,您只定义了 GraphQL API 的架构,但尚未指定查询或突变运行时应该发生什么。负责执行查询或突变的函数被称为解析器(Resolver)。在解析器的内部,您可以执行向数据库发送查询的操作,或者向第三方API发起请求。
在本教程中,您将在解析器中使用Prisma将查询发送到 PostgreSQL 数据库。
构建 GraphQL API
要构建 GraphQL API,您将需要一个为单个端点提供服务的 GraphQL 服务器。
该服务器将包含 GraphQL 架构以及解析器。对于此项目,您将使用 GraphQL Yoga。
首先,在您一开始克隆的入门存储库中,在终端中运行以下命令:
npm install graphql graphql-yogagraphql包是GraphQL的JavaScript参考实现。而graphql-yoga则是一种基于graphql的对等依赖项。
定义应用程序的架构
接下来,您需要定义 GraphQL 模式。在项目的根文件夹中创建一个新graphql目录,并在其中创建一个新schema.ts文件。您将定义该Link对象以及返回所有链接的查询。
// graphql/schema.ts
export const typeDefs = `
type Link {
id: ID
title: String
description: String
url: String
category: String
imageUrl: String
users: [String]
}
type Query {
links: [Link]!
}定义解析器
您需要做的下一件事是为查询创建解析器函数links。为此,请创建一个/graphql/resolvers.ts文件并添加以下代码:
// /graphql/resolvers.ts
export const resolvers = {
Query: {
links: () => {
return [
{
category: 'Open Source',
description: 'Fullstack React framework',
id: 1,
imageUrl: 'https://nextjs.org/static/twitter-cards/home.jpg',
title: 'Next.js',
url: 'https://nextjs.org',
},
{
category: 'Open Source',
description: 'Next Generation ORM for TypeScript and JavaScript',
id: 2,
imageUrl: 'https://www.prisma.io/images/og-image.png',
title: 'Prisma',
url: 'https://www.prisma.io',
},
{
category: 'Open Source',
description: 'GraphQL implementation',
id: 3,
imageUrl: 'https://www.apollographql.com/apollo-home.jpg',
title: 'Apollo GraphQL',
url: 'https://apollographql.com',
},
]
},
},
}resolvers是一个对象,您将在其中定义每个查询和突变的实现。对象内的Query函数中的方法名称必须与GraphQL架构中定义的查询名称相匹配。同样地,对于突变(Mutation)也是如此,这里links解析器函数返回一个对象数组,其中每个对象的类型为Link。
创建 GraphQL 端点
要创建 GraphQL 端点,您将利用 Next.js 的API 路由。文件夹内的任何文件/pages/api都会映射到/api/*端点并被视为 API 端点。
继续创建一个/pages/api/graphql.ts文件并添加以下代码:
// pages/api/graphql.ts
import { createSchema, createYoga } from 'graphql-yoga'
import type { NextApiRequest, NextApiResponse } from 'next'
import { resolvers } from '../../graphql/resolvers'
import { typeDefs } from '../../graphql/schema'
export default createYoga<{
req: NextApiRequest
res: NextApiResponse
}>({
schema: createSchema({
typeDefs,
resolvers
}),
graphqlEndpoint: '/api/graphql'
})
export const config = {
api: {
bodyParser: false
}
}您创建了一个新的 GraphQL Yoga 服务器实例,该实例是默认导出。您还使用createSchema将类型定义和解析器作为参数的函数创建了一个架构。
然后,您使用graphqlEndpoint属性来指定GraphQL API的路径为/api/graphql。
最后,每个 API 路由都可以导出一个config对象来更改默认配置。
使用 GraphiQL 发送查询
完成前面的步骤后,通过运行以下命令启动服务器:
npm run dev当您导航到 时http://localhost:3000/api/graphql/,您应该看到以下页面:
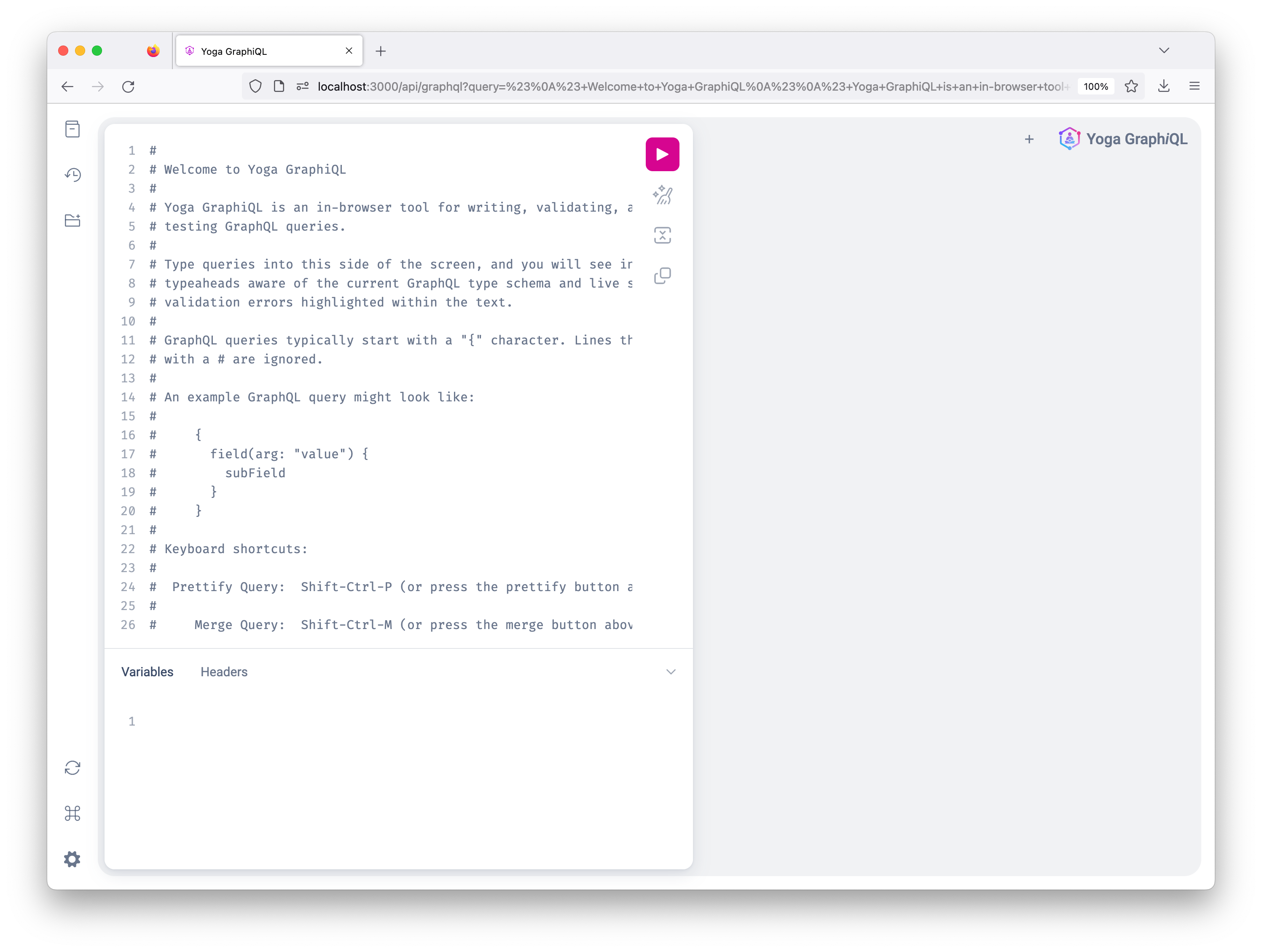
GraphQL Yoga 提供了一个交互式游乐场,名为GraphiQL,通过它您可以探索GraphQL架构并与API进行交互。
使用以下查询更新右侧选项卡上的内容,然后点击CMD/ CTRL+Enter执行查询:
query {
links {
id
title
description
}
}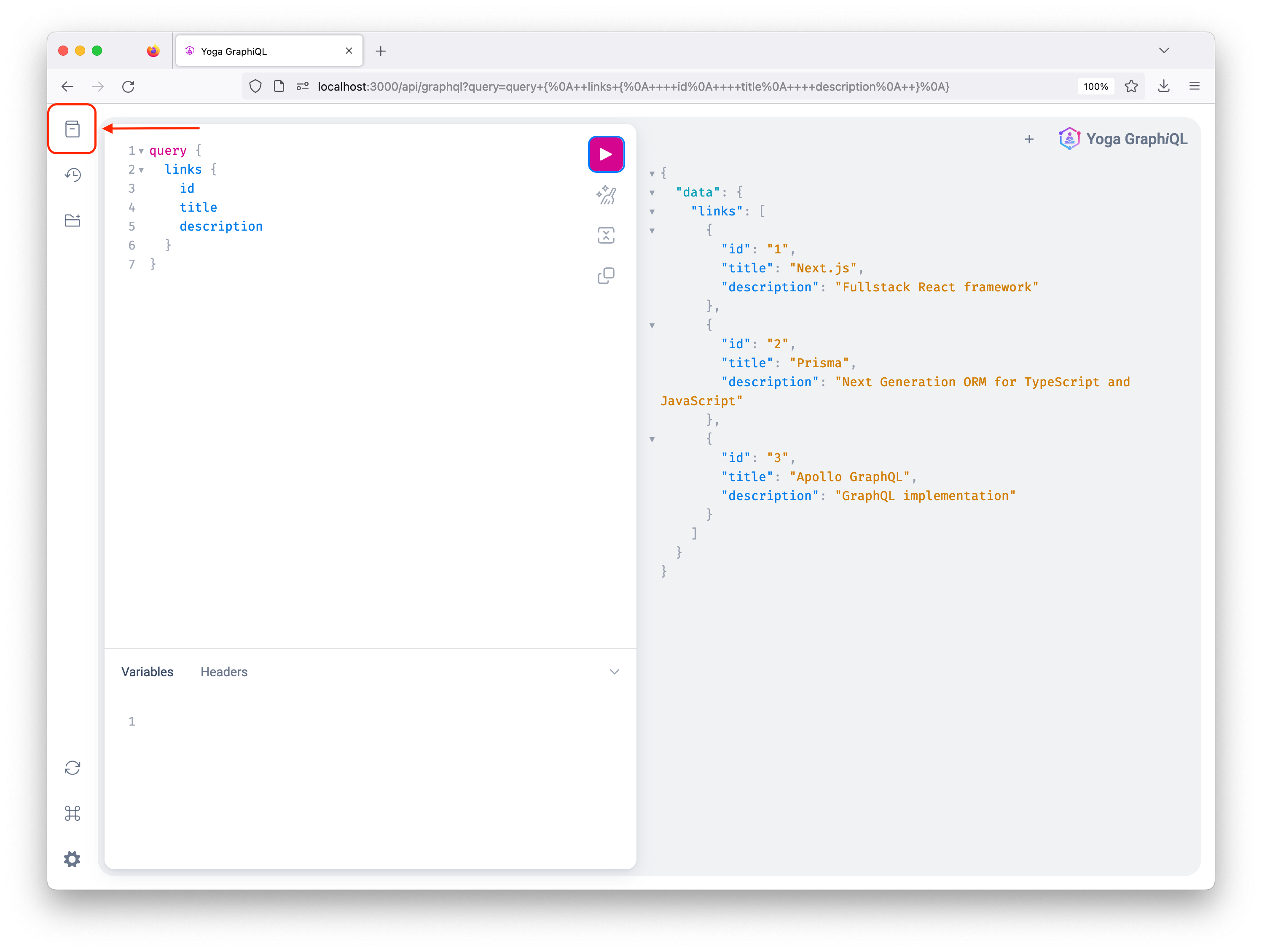
类似的屏幕截图中的左侧面板应该能够显示出响应内容。
文档资源管理器(页面左上角按钮)将允许您单独探索每个查询/突变,查看不同的所需参数及其类型。
初始化 Prisma 客户端
到目前为止,GraphQL API 在解析器函数中返回硬编码数据。您将在这些函数中使用 Prisma Client 将查询发送到数据库。
Prisma Client 是一个自动生成的、类型安全的查询生成器。为了能够在您的项目中使用它,您应该实例化它一次,然后在整个项目中重用它。继续/lib在项目的根文件夹中创建一个文件夹,并在其中创建一个prisma.ts文件。接下来,添加以下代码:
// /lib/prisma.ts
import { PrismaClient } from '@prisma/client'
let prisma: PrismaClient
declare global {
var prisma: PrismaClient;
}
if (process.env.NODE_ENV === 'production') {
prisma = new PrismaClient()
} else {
if (!global.prisma) {
global.prisma = new PrismaClient()
}
prisma = global.prisma
}
export default prisma首先,您要创建一个新的 Prisma 客户端实例。那么,如果你不在生产环境中,Prisma 会将其附加到全局对象上,这样你就不会因为数据库连接限制而被耗尽。有关更多详细信息,请参考Next.js和Prisma Client的最佳实践文档。
使用Prisma查询数据库
现在您可以更新解析器以从数据库返回数据。在文件内/graphql/resolvers.ts,将links函数更新为以下代码:
// /graphql/resolvers.ts
import prisma from '../lib/prisma'
export const resolvers = {
Query: {
links: () => {
return prisma.link.findMany()
},
},
}如果一切设置正确,当您转到 GraphiQL,athttp://localhost:3000/api/graphql并重新运行链接查询时,应该从数据库中检索数据。
我们当前 GraphQL 设置的缺陷
当 GraphQL API 变得越来越复杂时,当前手动创建模式和解析器的工作流程可能会降低开发人员的工作效率:
- 解析器必须与模式匹配相同的结构,反之亦然。否则,当架构或解析器实现发生变化时,这两个组件可能会意外地失去同步,导致出现错误且行为不可预测。
- GraphQL 架构被定义为字符串,因此不会对 SDL 代码进行自动完成和构建时错误检查。
为了解决这些问题,可以使用 GraphQL 代码生成器等工具组合。或者,您可以在使用解析器构建架构时使用代码优先方法。
使用Pothos 进行代码优先的 GraphQL API 开发
Pothos 是一个 GraphQL 模式构建库,您可以在其中使用代码定义 GraphQL 模式。这种方法的价值主张是您使用编程语言来构建 API,这有多种好处:
- 无需在 SDL 和用于构建业务逻辑的编程语言之间进行上下文切换。
- 从文本编辑器自动完成
- 类型安全(如果您使用的是 TypeScript)
这些好处能够减少开发过程中的摩擦,并带来更加出色的开发体验。
在本教程中,您将使用 Pothos。它还为 Prisma 提供了一个很棒的插件,可以在 GraphQL 类型和 Prisma 架构之间提供良好的开发体验和类型安全性。
注意:Pothos 能够与 Prisma 以类型安全的方式协同工作,且无需依赖插件,但这一过程相对较为手动。
首先,运行以下命令来安装 Pothos 和 Pothos 的 Prisma 插件:
npm install @pothos/plugin-prisma @pothos/core接下来,将pothos生成器块添加到生成器正下方的 Prisma 架构中client:
// prisma/schema.prisma
generator client {
provider = "prisma-client-js"
}
generator pothos {
provider = "prisma-pothos-types"
}运行以下命令重新生成 Prisma Client 和 Pothos 类型:
npx prisma generate接下来,创建 Pothos 架构构建器的实例作为可共享模块。在该graphql文件夹内,创建一个名为的新文件builder.ts并添加以下代码片段:
// graphql/builder.ts
// 1.
import SchemaBuilder from "@pothos/core";
import PrismaPlugin from '@pothos/plugin-prisma';
import type PrismaTypes from '@pothos/plugin-prisma/generated';
import prisma from "../lib/prisma";
// 2.
export const builder = new SchemaBuilder<{
// 3.
PrismaTypes: PrismaTypes
}>({
// 4.
plugins: [PrismaPlugin],
prisma: {
client: prisma,
}
})
// 5.
builder.queryType({
fields: (t) => ({
ok: t.boolean({
resolve: () => true,
}),
}),
});// graphql/builder.ts
// 1.
import SchemaBuilder from "@pothos/core";
import PrismaPlugin from '@pothos/plugin-prisma';
import type PrismaTypes from '@pothos/plugin-prisma/generated';
import prisma from "../lib/prisma";
// 2.
export const builder = new SchemaBuilder<{
// 3.
PrismaTypes: PrismaTypes
}>({
// 4.
plugins: [PrismaPlugin],
prisma: {
client: prisma,
}
})
// 5.
builder.queryType({
fields: (t) => ({
ok: t.boolean({
resolve: () => true,
}),
}),
});- 定义所需的所有库和实用程序
- 创建一个新
SchemaBuilder实例 - 定义将用于创建 GraphQL 模式的静态类型
- 在使用
SchemaBuilder时,可以定义包括将使用的插件、Prisma 客户端实例等在内的多项选项。 - 创建一个
queryType带有名为ok返回布尔值的查询
接下来,您需要在 /graphql/schema.ts 文件中,用以下从 Pothos 构建器创建的 GraphQL 架构来替换 typeDefs。
// graphql/schema.ts
import { builder } from "./builder";
export const schema = builder.toSchema()最后,更新文件中的导入/pages/api/graphql.ts:
// /pages/api/graphql.ts
import { createSchema, createYoga } from 'graphql-yoga'
import { createYoga } from 'graphql-yoga'
import type { NextApiRequest, NextApiResponse } from 'next'
import { resolvers } from '../../graphql/resolvers'
import { typeDefs } from '../../graphql/schema'
import { schema } from '../../graphql/schema'
export default createYoga<{
req: NextApiRequest
res: NextApiResponse
}>({
schema: createSchema({
typeDefs,
resolvers
}),
schema,
graphqlEndpoint: '/api/graphql'
})
export const config = {
api: {
bodyParser: false
}
}“graphql.ts”文件的更新内容:
// /pages/api/graphql.ts
import { createYoga } from 'graphql-yoga'
import type { NextApiRequest, NextApiResponse } from 'next'
import { schema } from '../../graphql/schema'
export default createYoga<{
req: NextApiRequest
res: NextApiResponse
}>({
schema,
graphqlEndpoint: '/api/graphql'
})
export const config = {
api: {
bodyParser: false
}
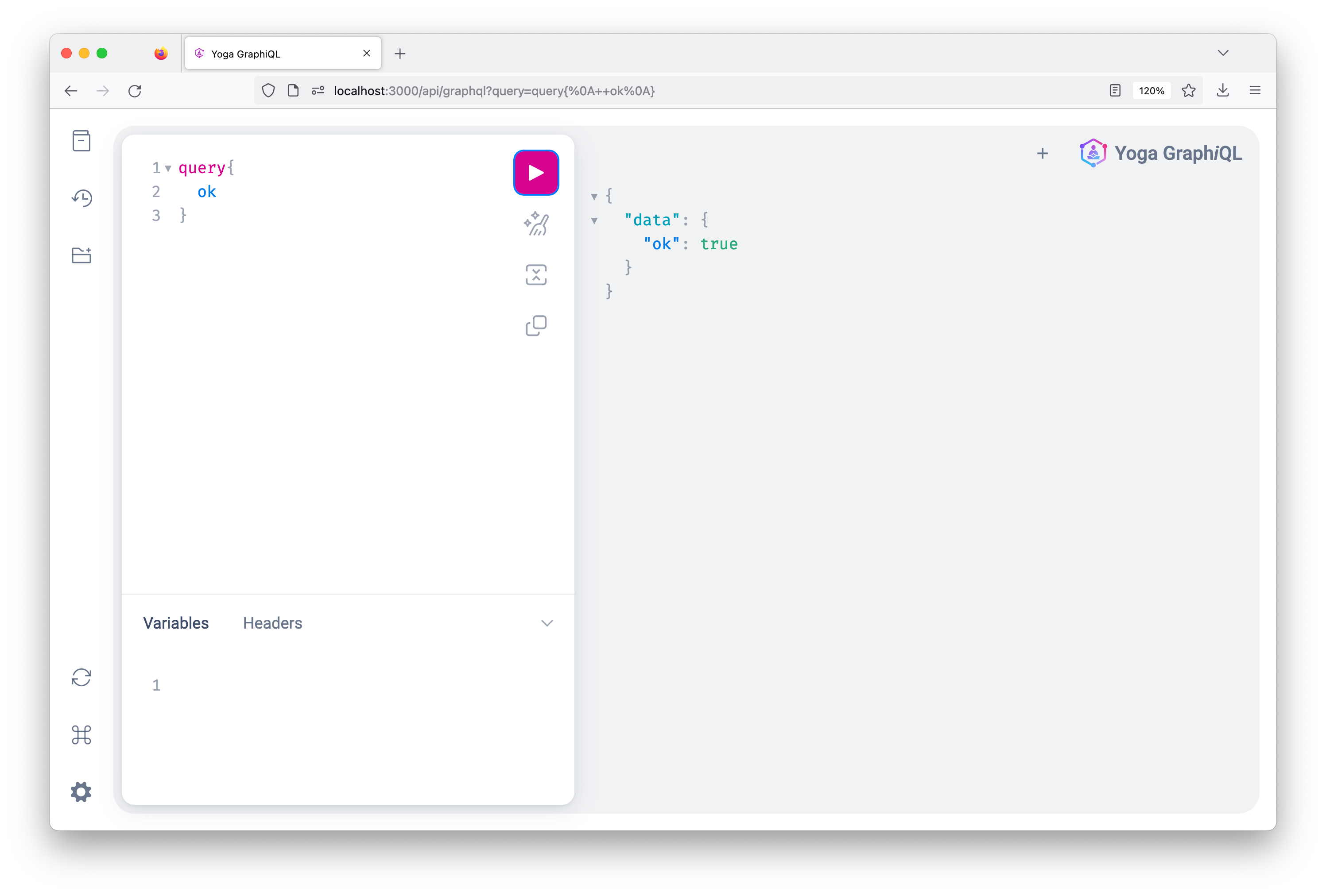
}确保服务器正在运行并导航到http://localhost:3000/api/graphql.您将能够发送带有ok字段的查询,该字段将返回true
使用 Pothos 定义模式
第一步是Link使用 Pothos 定义对象类型。继续创建一个/graphql/types/Link.ts文件,添加以下代码:
// /graphql/types/Link.ts
import { builder } from "../builder";
builder.prismaObject('Link', {
fields: (t) => ({
id: t.exposeID('id'),
title: t.exposeString('title'),
url: t.exposeString('url'),
description: t.exposeString('description'),
imageUrl: t.exposeString('imageUrl'),
category: t.exposeString('category'),
users: t.relation('users')
})
})由于您正在使用 Pothos 的 Prisma 插件,因此该 builder 实例提供了诸如 prismaObject 等实用方法,用于定义 GraphQL 模式。
prismaObject接受两个参数:
name:您想要公开的Prisma 模式中模型的名称。options:用于定义要公开的类型的选项,例如描述、字段等。
注意:您可以使用CTRL+Space调用编辑器的智能感知并查看可用参数。
fields 属性用于指定您希望通过“暴露”函数从 Prisma 架构中获取并包含在 GraphQL 模式中的字段。在本教程中,我们将公开 id、title、url、imageUrl 和 category 这几个字段。
该t.relation方法用于定义您希望从 Prisma 架构中公开的关系字段。
现在创建一个新/graphql/types/User.ts文件并将以下内容添加到代码中以创建User类型:
// /graphql/types/User.ts
import { builder } from "../builder";
builder.prismaObject('User', {
fields: (t) => ({
id: t.exposeID('id'),
email: t.exposeString('email', { nullable: true, }),
image: t.exposeString('image', { nullable: true, }),
role: t.expose('role', { type: Role, }),
bookmarks: t.relation('bookmarks'),
})
})
const Role = builder.enumType('Role', {
values: ['USER', 'ADMIN'] as const,
})由于 Prisma 模式中的 email 字段(以及其他可能同样可为空的字段)允许为空值,因此在通过“暴露”方法将其添加到 GraphQL 架构时,我们需要将 { nullable: true } 作为第二个参数进行传递。
在从生成的架构中“公开”字段类型时,role 字段的默认类型是其原有类型。但在上面的示例中,您首先定义了一个显式的枚举类型 Role,随后使用它来明确指定 role 字段的类型。
要使架构的定义对象类型在 GraphQL 架构中可用,请将导入添加到您刚刚在graphql/schema.ts文件中创建的类型:
// graphql/schema.ts
import "./types/Link"
import "./types/User"
import { builder } from "./builder";
export const schema = builder.toSchema()使用 Pothos 定义查询
在该graphql/types/Link.ts文件中,在对象类型定义下方添加以下代码Link:
// graphql/types/Link.ts
// code above unchanged
// 1.
builder.queryField("links", (t) =>
// 2.
t.prismaField({
// 3.
type: ['Link'],
// 4.
resolve: (query, _parent, _args, _ctx, _info) =>
prisma.link.findMany({ ...query })
})
)在上面的代码片段中:
- 定义一个名为 的查询类型
links。 - 定义将解析为生成的 Prisma 客户端类型的字段。
- 指定 Pothos 将用来解析该字段的字段。在这种情况下,它解析为
Link类型的数组 - 定义查询的逻辑。
query解析器函数中的参数将或添加到select您include的查询中,以在单个请求中解析尽可能多的关系字段。
现在,如果您回到 GraphiQL 界面,就可以发送一个查询请求,这个请求会返回数据库中所有的链接数据。
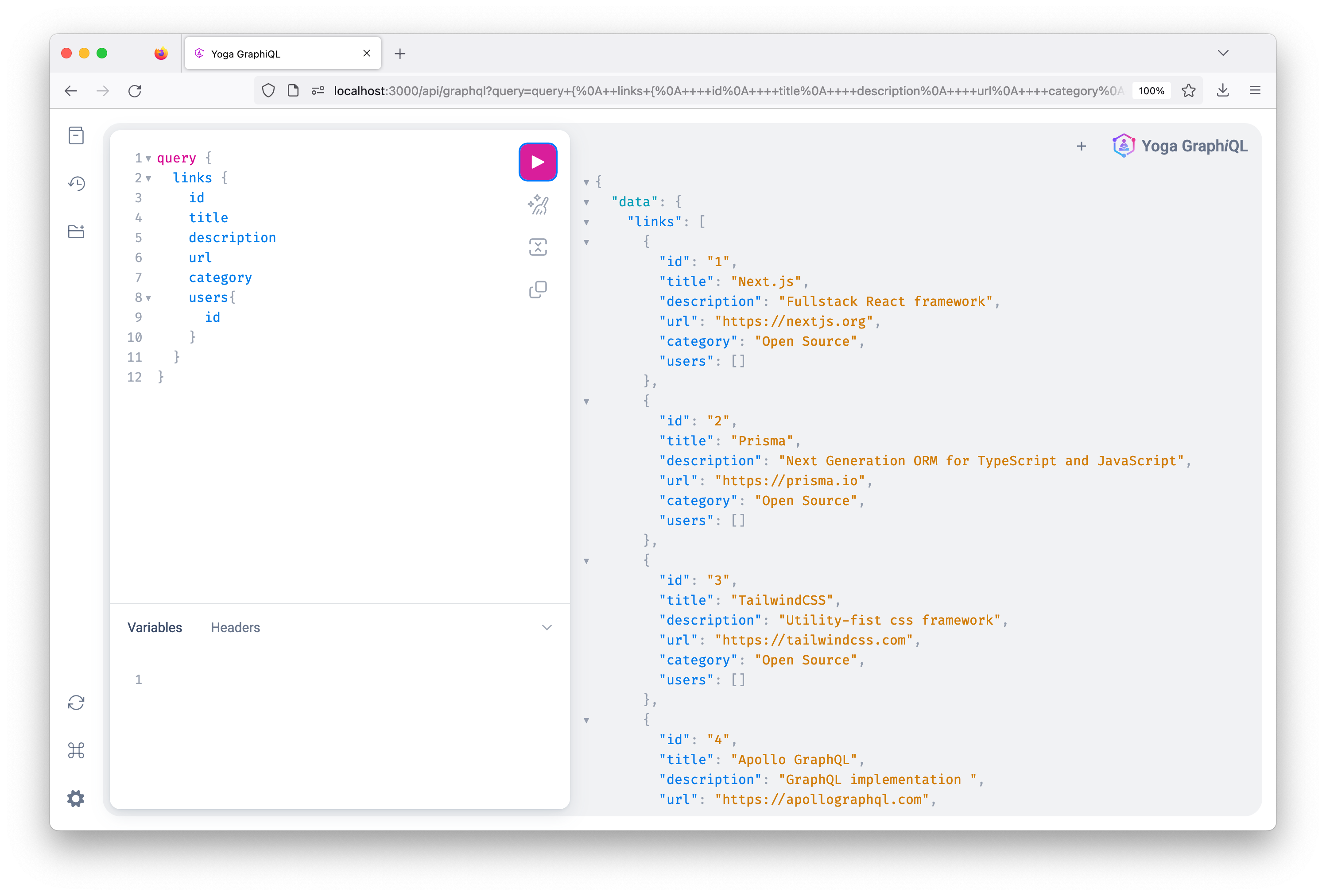
客户端 GraphQL 查询
对于此项目,您将使用 Apollo 客户端。您可以通过发送常规的 HTTP POST 请求来与刚刚构建好的 GraphQL API 进行通信。不过,使用 GraphQL 客户端能够带来诸多便利和优势。
Apollo 客户端负责请求和缓存您的数据,以及更新您的 UI。它还包括查询批处理、查询重复数据删除和分页功能。
在 Next.js 中设置 Apollo 客户端
要开始使用 Apollo Client,请通过运行以下命令添加到您的项目:
npm install @apollo/client接下来,在/lib目录中创建一个名为的新文件apollo.ts,并向其中添加以下代码:
// /lib/apollo.ts
import { ApolloClient, InMemoryCache } from '@apollo/client'
const apolloClient = new ApolloClient({
uri: '/api/graphql',
cache: new InMemoryCache(),
})
export default apolloClient您正在创建一个新ApolloClient实例,并向其中传递带有uri和cache字段的配置对象。
- 该
uri字段指定您将与之交互的 GraphQL 端点。部署应用程序时,这将更改为生产 URL。 - 该
cache字段是 InMemoryCache 的一个实例,Apollo Client 会获取查询结果,并使用cache来存储这些查询结果以便缓存。
接下来,转到该/pages/_app.tsx文件并向其中添加以下代码,以设置 Apollo 客户端:
// /pages/_app.tsx
import '../styles/tailwind.css'
import Layout from '../components/Layout'
import { ApolloProvider } from '@apollo/client'
import apolloClient from '../lib/apollo'
import type { AppProps } from 'next/app'
function MyApp({ Component, pageProps }: AppProps) {
return (
<ApolloProvider client={apolloClient}>
<Layout>
<Component {...pageProps} />
</Layout>
</ApolloProvider>
)
}
export default MyApp您正在使用 Apollo Provider 包装全局App组件,以便项目的所有组件都可以发送 GraphQL 查询。
注意:Next.js 支持不同的数据获取策略。您可以在服务器端、客户端或构建时获取数据。为了支持分页,您需要在客户端获取数据。
使用发送请求useQuery
要使用 Apollo 客户端在前端加载数据,请更新/pages/index.tsx文件以使用以下代码:
// /pages/index.tsx
import Head from 'next/head'
import { gql, useQuery } from '@apollo/client'
import type { Link } from '@prisma/client'
const AllLinksQuery = gql`
query {
links {
id
title
url
description
imageUrl
category
}
}
`
export default function Home() {
const { data, loading, error } = useQuery(AllLinksQuery)
if (loading) return <p>Loading...</p>
if (error) return <p>Oh no... {error.message}</p>
return (
<div>
<Head>
<title>Awesome Links</title>
<link rel="icon" href="/favicon.ico" />
</Head>
<div className="container mx-auto max-w-5xl my-20">
<ul className="grid grid-cols-1 md:grid-cols-2 lg:grid-cols-3 gap-5">
{data.links.map((link: Link) => (
<li key={link.id} className="shadow max-w-md rounded">
<img className="shadow-sm" src={link.imageUrl} />
<div className="p-5 flex flex-col space-y-2">
<p className="text-sm text-blue-500">{link.category}</p>
<p className="text-lg font-medium">{link.title}</p>
<p className="text-gray-600">{link.description}</p>
<a href={link.url} className="flex hover:text-blue-500">
{link.url.replace(/(^\w+:|^)\/\//, '')}
<svg
className="w-4 h-4 my-1"
fill="currentColor"
viewBox="0 0 20 20"
xmlns="http://www.w3.org/2000/svg"
>
<path d="M11 3a1 1 0 100 2h2.586l-6.293 6.293a1 1 0 101.414 1.414L15 6.414V9a1 1 0 102 0V4a1 1 0 00-1-1h-5z" />
<path d="M5 5a2 2 0 00-2 2v8a2 2 0 002 2h8a2 2 0 002-2v-3a1 1 0 10-2 0v3H5V7h3a1 1 0 000-2H5z" />
</svg>
</a>
</div>
</li>
))}
</ul>
</div>
</div>
)
}您正在使用该useQuery挂钩将查询发送到 GraphQL 端点。这个挂钩需要一个必需的参数,即 GraphQL 查询字符串。当组件进行渲染时,useQuery 会返回一个对象,该对象包含三个值:
loading:一个布尔值,确定数据是否已返回。error:包含错误消息的对象,以防发送查询后发生错误。data:包含从 API 端点返回的数据。
保存文件并导航到 后http://loclahost:3000,您将看到从数据库获取的链接列表。
分页
AllLinksQuery 会返回数据库中的所有链接。随着应用程序的不断扩展和链接数量的增加,您可能会收到大量的 API 响应,这将导致加载时间变长。此外,解析器发送的数据库查询也会变慢,因为您使用该prisma.link.findMany()函数返回数据库中的链接。
提升性能的一种常见做法就是引入分页支持。分页能够将大型数据集切分成更小的数据块,这样我们就可以根据需要来请求特定的数据块了。
有多种不同的方法来实现分页。您可以进行编号页面,例如 Google 搜索结果,也可以进行无限滚动,如 Twitter 的提要。

数据库级别的分页
现在在数据库级别,您可以使用两种分页技术:基于偏移量和基于游标的分页。
- 基于偏移:您跳过一定数量的结果并选择有限的范围。例如,您可以跳过前 200 个结果,只获取后面的 10 个结果。这种方法的缺点是它不能在数据库级别进行扩展。例如,如果您跳过前 200,000 条记录,数据库仍然需要遍历所有这些记录,这会影响性能。

- 基于游标的分页:您可以使用游标在结果集中的特定位置做上标记。在后续的请求里,您便能直接跳转到这个已保存的位置,这有点像是通过索引去访问数组里的元素。
游标通常需要是唯一且连续的列,比如 ID 或时间戳。与基于偏移量的分页相比,这种方法更加高效,并且也是本教程中将要采用的方法。

GraphQL 中的分页
为了使 GraphQL API 支持分页,您需要向 GraphQL 架构引入中继游标连接规范。这是 GraphQL 服务器应如何公开分页数据的规范。
分页查询如下所示:
query allLinksQuery($first: Int, $after: ID) {
links(first: $first, after: $after) {
pageInfo {
endCursor
hasNextPage
}
edges {
cursor
node {
id
imageUrl
title
description
url
category
}
}
}
}该查询采用两个参数,first并且after:
first:Int指定您希望 API 返回的项目数。after:ID为结果集中的最后一项添加书签的参数,这就是光标。
此查询返回一个包含两个字段的对象,pageInfo并且edges:
pageInfo:这个对象会协助客户端判断是否还有更多数据需要获取。它包含两个字段:endCursor和hasNextPage。endCursor:结果集中最后一项的光标。该游标的类型为StringhasNextPage:API 返回的布尔值,让客户端知道是否有更多页面可以获取。
edges是一个对象数组,其中每个对象都有 一个cursor和 一个node字段。这里的字段node返回Link对象类型。
您将实现单向分页,在页面首次加载时请求一些链接,然后用户可以通过单击按钮获取更多链接。
或者,您也可以选择在用户滚动到页面底部时自动发出这个请求。
其工作原理是在页面首次加载时获取一些数据。然后,单击按钮后,您向 API 发送第二个请求,其中包括您想要返回的项目数和光标。然后将数据返回并显示在客户端上。
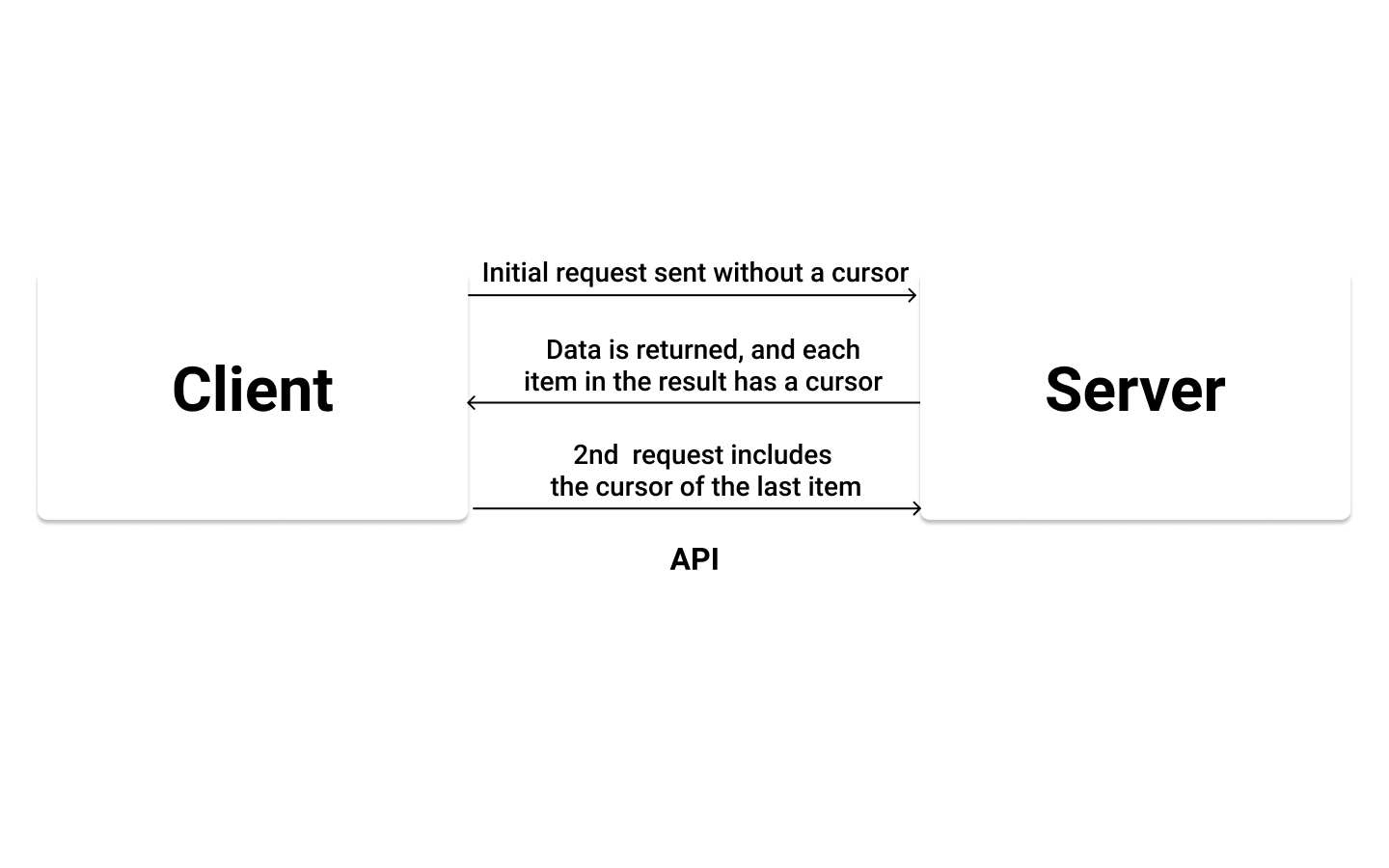
注意:双向分页的一个示例是 Slack 等聊天应用程序,您可以在其中向前或向后加载消息。
修改 GraphQL 架构
Pothos 提供了一个插件,该插件专门用于处理中继式光标分页,其中包含了节点、连接以及其他一些实用的工具。
使用以下命令安装插件:
npm install @pothos/plugin-relay更新graphql/builder.ts以包含中继插件:
// graphql/builder.ts
import SchemaBuilder from "@pothos/core";
import PrismaPlugin from '@pothos/plugin-prisma';
import prisma from "../lib/prisma";
import type PrismaTypes from '@pothos/plugin-prisma/generated';
import RelayPlugin from '@pothos/plugin-relay';
export const builder = new SchemaBuilder<{
PrismaTypes: PrismaTypes
}>({
plugins: [PrismaPlugin],
plugins: [PrismaPlugin, RelayPlugin],
relayOptions: {},
prisma: {
client: prisma,
}
})
builder.queryType({
fields: (t) => ({
ok: t.boolean({
resolve: () => true,
}),
}),
});更新解析器以从数据库返回分页数据
要使用基于游标的分页,请对查询进行以下更新:
// ./graphql/types/Link.ts
// code remains unchanged
builder.queryField('links', (t) =>
t.prismaField({
t.prismaConnection({
type: ['Link'],
type: 'Link',
cursor: 'id',
resolve: (query, _parent, _args, _ctx, _info) =>
prisma.link.findMany({ ...query })
})
)该prismaConnection方法用于创建一个connection字段,该字段还预加载该连接内的数据。
“Link.ts”文件的更新内容:
// /graphql/types/Link.ts
import { builder } from "../builder";
builder.prismaObject('Link', {
fields: (t) => ({
id: t.exposeID('id'),
title: t.exposeString('title'),
url: t.exposeString('url'),
description: t.exposeString('description'),
imageUrl: t.exposeString('imageUrl'),
category: t.exposeString('category'),
users: t.relation('users')
}),
})
builder.queryField('links', (t) =>
t.prismaConnection({
type: 'Link',
cursor: 'id',
resolve: (query, _parent, _args, _ctx, _info) =>
prisma.link.findMany({ ...query })
})
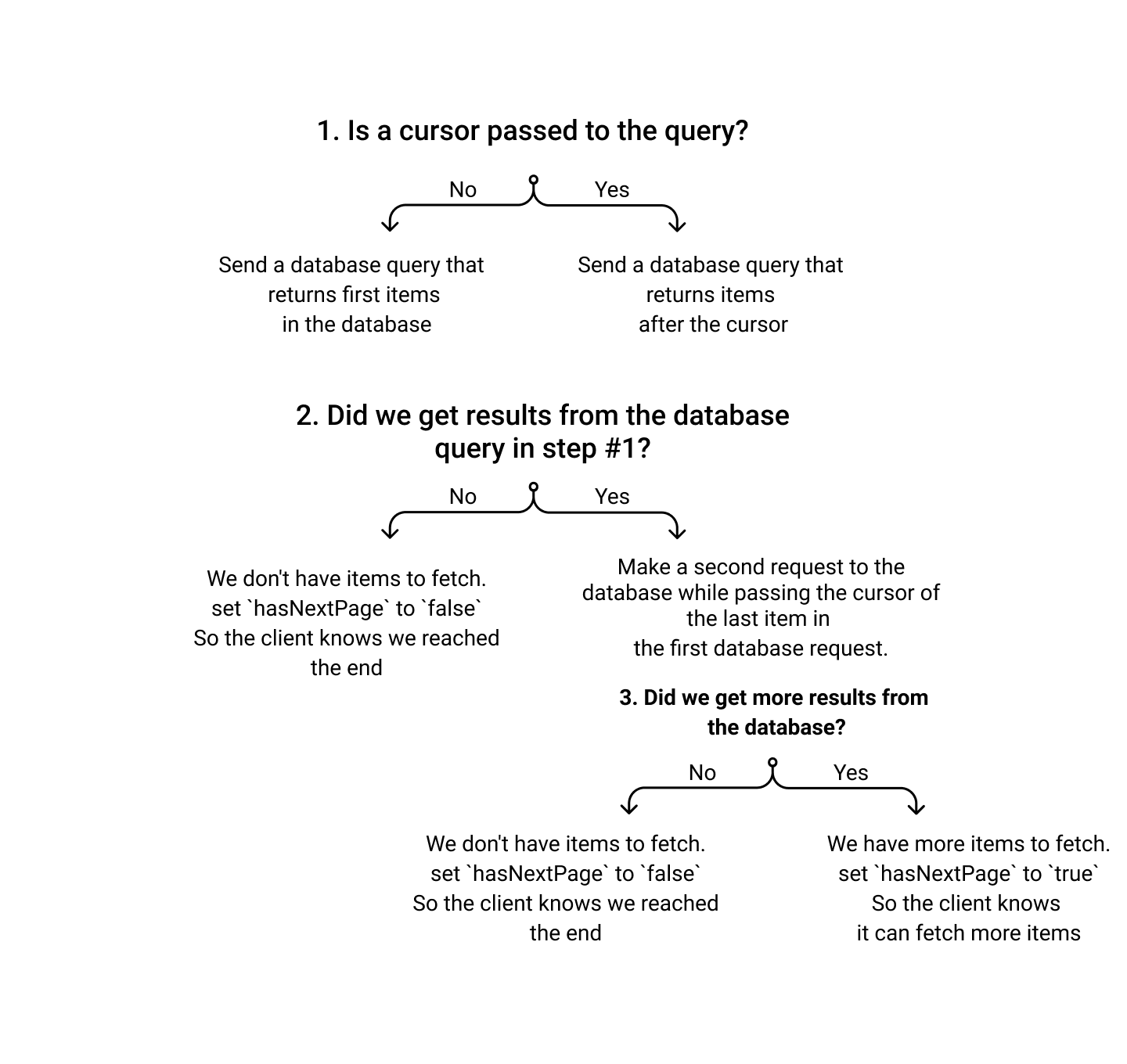
)下面的图表总结了分页在服务器上的工作原理:
在客户端使用分页fetchMore()
现在API支持分页,您可以使用Apollo Client在客户端获取分页数据。
useQuery 钩子会返回一个对象,该对象包含 data、loading 和 errors 这几个属性。除此之外,useQuery 还会提供一个 fetchMore() 函数,这个函数用于处理分页逻辑,并在获取到新结果时更新用户界面。导航到该/pages/index.tsx文件并更新它以使用以下代码添加对分页的支持:
// /pages/index.tsx
import Head from "next/head";
import { gql, useQuery, useMutation } from "@apollo/client";
import { AwesomeLink } from "../components/AwesomeLink";
import type { Link } from "@prisma/client";
const AllLinksQuery = gql`
query allLinksQuery($first: Int, $after: ID) {
links(first: $first, after: $after) {
pageInfo {
endCursor
hasNextPage
}
edges {
cursor
node {
imageUrl
url
title
category
description
id
}
}
}
}
`;
function Home() {
const { data, loading, error, fetchMore } = useQuery(AllLinksQuery, {
variables: { first: 2 },
});
if (loading) return <p>Loading...</p>;
if (error) return <p>Oh no... {error.message}</p>;
const { endCursor, hasNextPage } = data.links.pageInfo;
return (
<div>
<Head>
<title>Awesome Links</title>
<link rel="icon" href="/favicon.ico" />
</Head>
<div className="container mx-auto max-w-5xl my-20">
<div className="grid grid-cols-1 md:grid-cols-2 lg:grid-cols-3 gap-5">
{data?.links.edges.map(({ node }: { node: Link }) => (
<AwesomeLink
title={node.title}
category={node.category}
url={node.url}
id={node.id}
description={node.description}
imageUrl={node.imageUrl}
/>
))}
</div>
{hasNextPage ? (
<button
className="px-4 py-2 bg-blue-500 text-white rounded my-10"
onClick={() => {
fetchMore({
variables: { after: endCursor },
updateQuery: (prevResult, { fetchMoreResult }) => {
fetchMoreResult.links.edges = [
...prevResult.links.edges,
...fetchMoreResult.links.edges,
];
return fetchMoreResult;
},
});
}}
>
more
</button>
) : (
<p className="my-10 text-center font-medium">
You've reached the end!{" "}
</p>
)}
</div>
</div>
);
}
export default Home;您在使用 useQuery 挂钩时,需要先传递一个 variables 对象,该对象含有一个名为 first 的键,其对应的值设为 2。这意味着您希望初始时获取两个链接。当然,您可以根据实际需求将这个值设置为您想要的任何数字。
该data变量将包含从对 API 的初始请求返回的数据。
然后,您将解构对象中的值。
如果 hasNextPage 的值为 true,我们将展示一个按钮,并为其设置 onClick 事件处理程序。这个处理程序会返回一个函数,该函数在被调用时会执行 fetchMore() 方法,而 fetchMore() 方法则需要接收一个对象作为参数,该对象包含以下字段:
variables获取endCursor从初始数据返回的对象。updateQuery函数,它负责通过将先前的结果与第二个查询返回的结果相结合来更新 UI。
如果hasNextPage是false,则意味着没有更多可以获取的链接。
如果您已经保存了更改并且应用程序正在运行,那么您应该能够成功地从数据库中获取分页数据。
摘要和后续步骤
恭喜!您已成功完成课程的第二部分!如果您遇到任何问题或有任何疑问,请随时联系我们的 Slack 社区。
在这一部分中,您了解了:
- 使用 GraphQL 相对于 REST 的优势
- 如何使用 SDL 构建 GraphQL API
- 如何使用 Pothos 构建 GraphQL API 及其提供的优势
- 如何在 API 中添加对分页的支持以及如何从客户端发送分页查询
在课程的下一部分中,您将:
- 通过引入 Auth0 进行身份验证,我们可以为 API 端点增设保护机制,确保仅有登录状态的用户才有权限查看链接。
- 创建突变,以便登录用户可以为链接添加书签
- 创建仅用于创建链接的管理员路由
- 设置 AWS S3 来处理文件上传
- 添加突变以以管理员身份创建链接
原文链接:https://www.prisma.io/blog/fullstack-nextjs-graphql-prisma-2-fwpc6ds155