使用 Python 和 Flask 开发 RESTful API
文章目录
在本文中,我们将使用 Flask 和 Python 来开发 RESTful API。首先,我们会创建一个返回静态数据(字典)的终端节点。接着,我们会构建一个包含两个子类及多个端点的类,用于插入和检索这些类的实例。最后,我们将探讨如何在 Docker 容器上运行该 API。本文开发的最终代码可在 GitHub 存储库中查阅。希望你会喜欢!
为什么选择 Python?
如今,Python 已成为开发应用程序的热门选择。根据 StackOverflow 的最新分析,Python 是增长最快的编程语言之一,平台上关于 Python 的问题数量甚至超越了 Java。而在 GitHub 上,Python 也展现出大规模应用的趋势,于 2021 年在编程语言排名中位列第二。
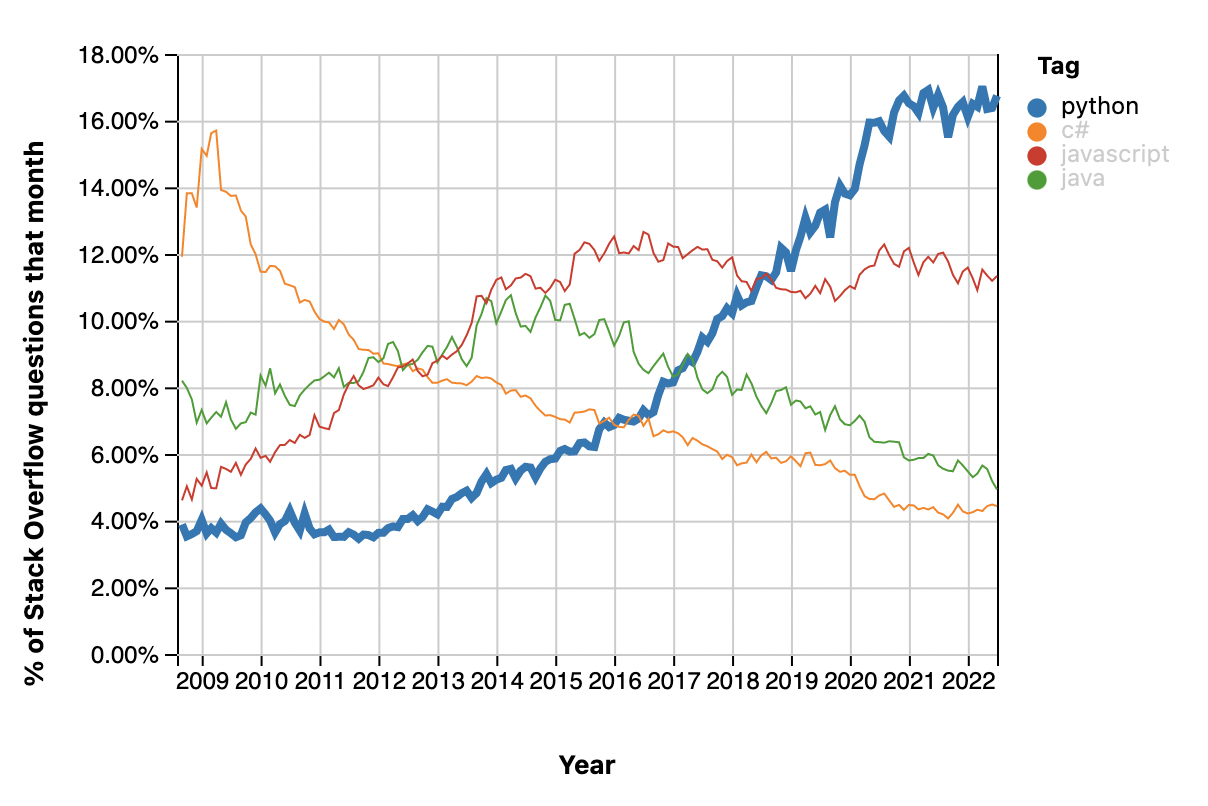
围绕 Python 形成的庞大社区正在改进该语言的各个方面。越来越多的开源库正被发布,以解决从人工智能、机器学习到Web开发等众多领域的挑战。除了整个社区提供的强大支持外,Python 软件基金会还提供了卓越的文档,使新采用者能够快速掌握其核心要点。
为什么选择 Flask?
在 Python 的 Web 开发领域,三大主要框架分别是 Django、Flask 和一个相对较新的参与者 FastAPI。Django 历史悠久、成熟且广受欢迎,在 GitHub 上拥有约 66k 颗星、2.2k 名贡献者、约 350 个版本和超过 25k 个分支。
FastAPI 正在迅速崛起,其在 GitHub 上拥有 48k 颗星、370 名贡献者以及超过 3.9k 个分支。这个专为高性能和快速编码 API 设计的优雅框架备受瞩目。
尽管 Flask 在受欢迎程度上可能稍逊一筹,但它同样不容小觑。在 GitHub 上,Flask 拥有近 60k 颗星、约 650 名贡献者、23 个版本和近 15k 个分支。
尽管 Django 历史更为悠久且社区规模稍大,但 Flask 具有其独特优势。从一开始,Flask 就以可扩展性和简洁性为核心。与 Django 应用相比,Flask 应用以其轻量级而著称。Flask 开发人员将其称为 microframework,这里的 micro(微小)意味着其核心旨在保持简单但可扩展。Flask 不会为开发者预设很多决策,例如使用哪种数据库或选择哪种模板引擎。此外,Flask 提供了详尽的文档,满足开发者入门所需的一切。FastAPI 遵循与 Flask 类似的“微”理念,尽管它提供了更多工具,如自动生成的 Swagger UI,是 API 开发的绝佳选择。然而,由于其相对较新,与 Django 和 Flask 等框架相比,与之兼容的资源和库可能较少。
Flask 以其轻量级、易用性、详尽的文档和广泛的受欢迎程度,成为开发 RESTful API 的优选之一。
引导 Flask 应用程序
首先,我们需要在开发计算机上安装一些依赖项。这包括 Python 3、Pip(Python 包索引)以及 Flask。
安装 Python 3
如果你使用的是最新的流行 Linux 发行版(如 Ubuntu)或 macOS,那么你的计算机可能已经预装了 Python 3。而如果你在使用 Windows,可能需要手动安装 Python 3,因为该操作系统默认不附带 Python。
在机器上安装 Python 3 后,你可以通过运行以下命令来检查一切是否设置正确:
python --version
# Python 3.8.9请注意,当系统中存在不同版本的 Python 时,上述命令可能会产生不同的输出。重要的是,您应确保运行的是 Python 3 或更新版本。如果我们输入 python --version 得到的是 “Python 2”,那么我们可以尝试使用 python3 --version。如果此命令产生了正确的 Python 3 版本输出,那么我们必须在整篇文章中替换所有命令,使用 python3 而不是 python。
安装 Pip
Pip 是安装 Python 包的推荐工具。虽然官方安装页面指出,在 Ubuntu 上安装 Python 时,如果使用的是 Python 2.7.9 或更高版本,或 Python 3.4 或更高版本,通常不会默认安装 Pip。因此,我们需要检查一下是否需要单独安装 Pip,或者是否已经拥有它。
# we might need to change pip by pip3
pip --version
# pip 9.0.1 ... (python 3.X)如果上述指令能生成类似的输出,那么我们就可以着手进行下一步了。如果结果不符,我们可以尝试用 pip3 替换 pip。如果在计算机上未能找到与 Python 3 对应的 Pip,我们可以遵循相关说明来安装 Pip。
安装 Flask
既然我们已对 Flask 有所了解,接下来让我们专注于在机器上安装它,并进行测试,以确保能够运行基本的 Flask 应用程序。安装 Flask 的第一步是使用 Pip执行以下命令:
# we might need to replace pip with pip3
pip install Flask安装包后,我们将创建一个名为 file 并向其添加五行代码。由于我们将使用此文件来检查 Flask 是否已正确安装,因此我们不需要将其嵌套在新目录中。
# hello.py
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello_world():
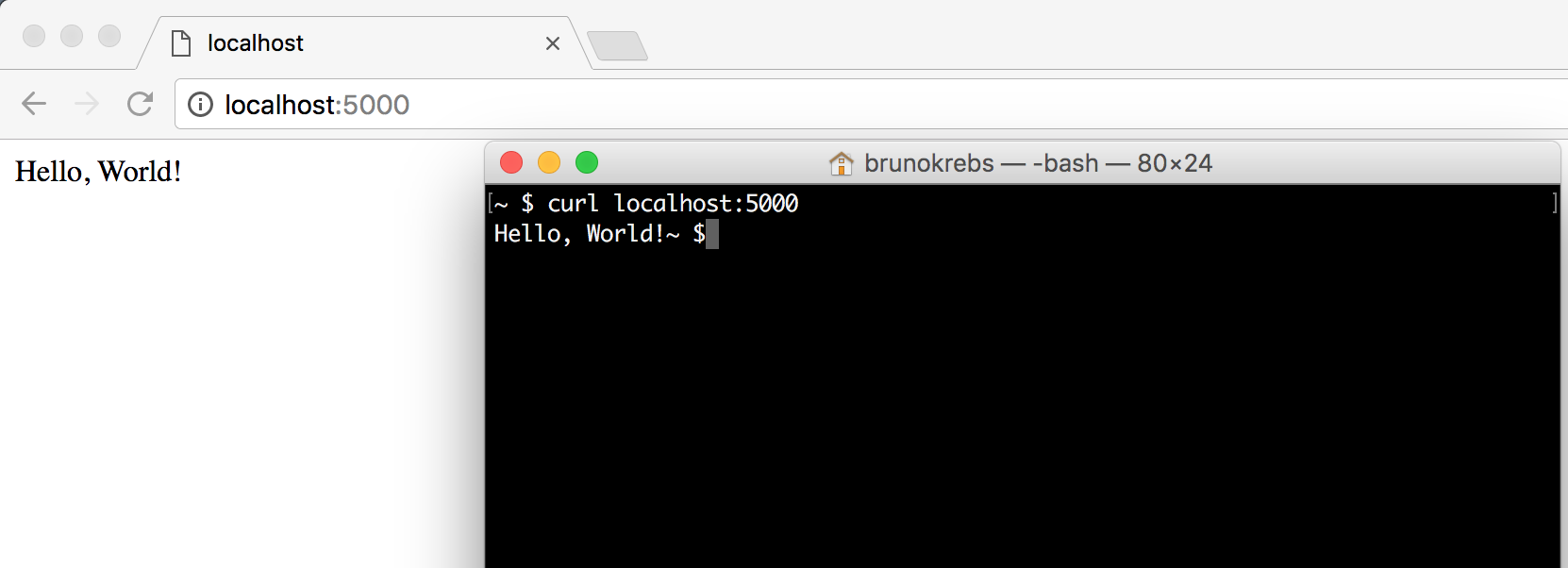
return "Hello, World!"这 5 行代码是我们处理 HTTP 请求并返回 “Hello, World!” 。要运行它,我们执行以下命令:
flask --app hello run
* Serving Flask app 'hello'
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on http://127.0.0.1:5000
Press CTRL+C to quit在 Ubuntu 上,若要让 Flask 命令直接在终端中运行,我们可能需要调整环境变量。为此,请首先执行以下命令:
touch ~/.bash_aliasesecho "export PATH=\$PATH:~/.local/bin" >> ~/.bash_aliases执行这些命令后,为了使更改生效,你可以重新加载 bash 配置或者开启一个新的终端窗口。
接着,你可以启动你的 Flask 应用程序。一旦应用程序运行,你可以通过打开浏览器并导航到 http://127.0.0.1:5000/ 来访问它,或者通过发出 curl http://127.0.0.1:5000/ 命令来测试其响应。
虚拟环境 (virtualenv)
尽管 PyPA(Python Packaging Authority 组)建议作为安装 Python 包的工具,但我们需要使用另一个包来管理项目的依赖项。确实,pip支持通过requirements.txt文件来管理依赖项,但这种方式在严肃项目中,特别是在需要在不同生产和开发机器上运行的项目中,存在一些不足。其中,最突出的问题是:
pip全局安装包,因此很难在同一台计算机上管理同一包的多个版本。requirements.txt需要显式列出所有依赖项和子依赖项,这是一个繁琐且容易出错的手动过程。
为了解决这些问题,我们将使用Pipenv。Pipenv是一个依赖项管理器,它能够将项目隔离在私有的虚拟环境中,从而允许我们按项目安装软件包。如果您熟悉NPM(Node Package Manager)或Ruby的打包工具,那么Pipenv在本质上与这些工具是相似的。
pip install pipenv现在,为了开始构建一个关键的 Flask 应用程序,我们首先需要创建一个新目录来存放源代码。在本文中,我们将打造一个名为 Cashman 的小型 RESTful API,它将为用户提供管理收入和支出的功能。因此,我们将创建一个目录。随后,我们将使用 pipenv 来启动项目并管理其依赖项。具体来说,目录名可以定为 cashman-flask-project,并使用以下命令来初始化 pipenv 环境:
# create our project directory and move to it
mkdir cashman-flask-project && cd cashman-flask-project
# use pipenv to create a Python 3 (--three) virtualenv for our project
pipenv --three
# install flask a dependency on our project
pipenv install flask第二个命令创建我们的虚拟环境,我们所有的依赖项都安装在其中,第三个命令将添加 Flask 作为我们的第一个依赖项。如果我们检查项目的目录,我们将看到两个新文件:
Pipfile包含有关我们项目的详细信息,例如 Python 版本和所需的包。Pipenv.lock包含项目所依赖的每个包的版本及其传递依赖项。
Python 模块
Python 模块是组织源代码的一种方式,与其他主流编程语言中的类似概念(如 Java 的包和 C# 的命名空间)相呼应。在 Python 中,模块是包含 Python 代码的文件,这些文件可以被其他 Python 脚本导入。为了将一组相关的模块组织在一起,可以创建一个文件夹,并在其中添加一个名为 __init__.py 的文件,这样该文件夹就被视为一个 Python 包。
让我们在应用程序上创建第一个模块,即主模块,其中包含我们所有的 RESTful 端点。在应用程序的目录中,我们将创建一个新的文件夹。这个新文件夹将命名为我们项目的模块名,例如 cashmancashman-flask-project。然后,在这个新文件夹中,我们将添加 __init__.py 文件以及其他必要的 Python 脚本,以构成我们的主模块。
# create source code's root
mkdir cashman && cd cashman
# create an empty __init__.py file
touch __init__.py在主模块中,让我们创建一个名为 .index.py的脚本,我们将定义应用程序的第一个端点。
from flask import Flask
app = Flask(__name__)
@app.route("/")
def hello_world():
return "Hello, World!"与前面的示例一样,我们的应用程序返回 “Hello, world!” 消息。我们稍后会开始改进它,但首先,让我们创建一个在应用程序的根目录中调用的可执行文件bootstrap.sh。
# move to the root directory
cd ..
# create the file
touch bootstrap.sh
# make it executable
chmod +x bootstrap.sh此文件的目标是促进应用程序的启动。其源代码如下:
#!/bin/sh
export FLASK_APP=./cashman/index.py
pipenv run flask --debug run -h 0.0.0.0第一个命令用于指定 Flask 要执行的主脚本。第二个命令则在虚拟环境的上下文中运行我们的 Flask 应用程序,并使其监听计算机上的所有接口(通过 -h 0.0.0.0 参数实现)。
注意:为了提升开发体验并启用热重载功能,我们已将 Flask 设置为在调试模式下运行。这意味着在每次更改代码后,无需手动重启服务器。但请注意,如果您在生产环境中运行 Flask,应更新这些设置以适应生产环境的需求。
为了验证此脚本是否正常运行,我们可以执行 ./bootstrap.sh 脚本,预期会得到与运行“Hello, world!”应用程序时相似的结果。
* Serving Flask app './cashman/index.py'
* Debug mode: on
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:5000
* Running on http://192.168.1.207:5000
Press CTRL+C to quit使用 Flask 创建 RESTful 终端节点
现在我们的应用程序已经结构化,我们可以开始编写一些相关的端点。如前所述,我们应用程序的目标是帮助用户管理收入和支出。我们将首先定义两个终端节点来处理收入。让我们将./cashman/index.py文件的内容替换为以下内容:
from flask import Flask, jsonify, request
app = Flask(__name__)
incomes = [
{ 'description': 'salary', 'amount': 5000 }
]
@app.route('/incomes')
def get_incomes():
return jsonify(incomes)
@app.route('/incomes', methods=['POST'])
def add_income():
incomes.append(request.get_json())
return '', 204自从我们对应用程序进行改进以来,已经移除了原先向用户返回“Hello, world!”的终端节点。取而代之的是,我们定义了一个专门处理返回收入HTTP请求的终端节点,以及另一个用于处理添加新收入HTTP请求的终端节点。这些终端节点均附有注释,清晰地说明了它们各自监听的路由。Flask 提供了详尽的文档,很好地阐述了这些功能的具体实现。具体来说,我们使用了 @app.route 装饰器来定义 /incomes 的 GET 和 POST 方法。
目前,我们暂将收入以字典的形式进行处理,但很快就会创建专门的类来表示收入和支出。
要与我们创建的两个端点进行交互,我们可以启动我们的应用程序并发出一些 HTTP 请求:
# start the cashman application
./bootstrap.sh &
# get incomes
curl http://localhost:5000/incomes
# add new income
curl -X POST -H "Content-Type: application/json" -d '{
"description": "lottery",
"amount": 1000.0
}' http://localhost:5000/incomes
# check if lottery was added
curl localhost:5000/incomes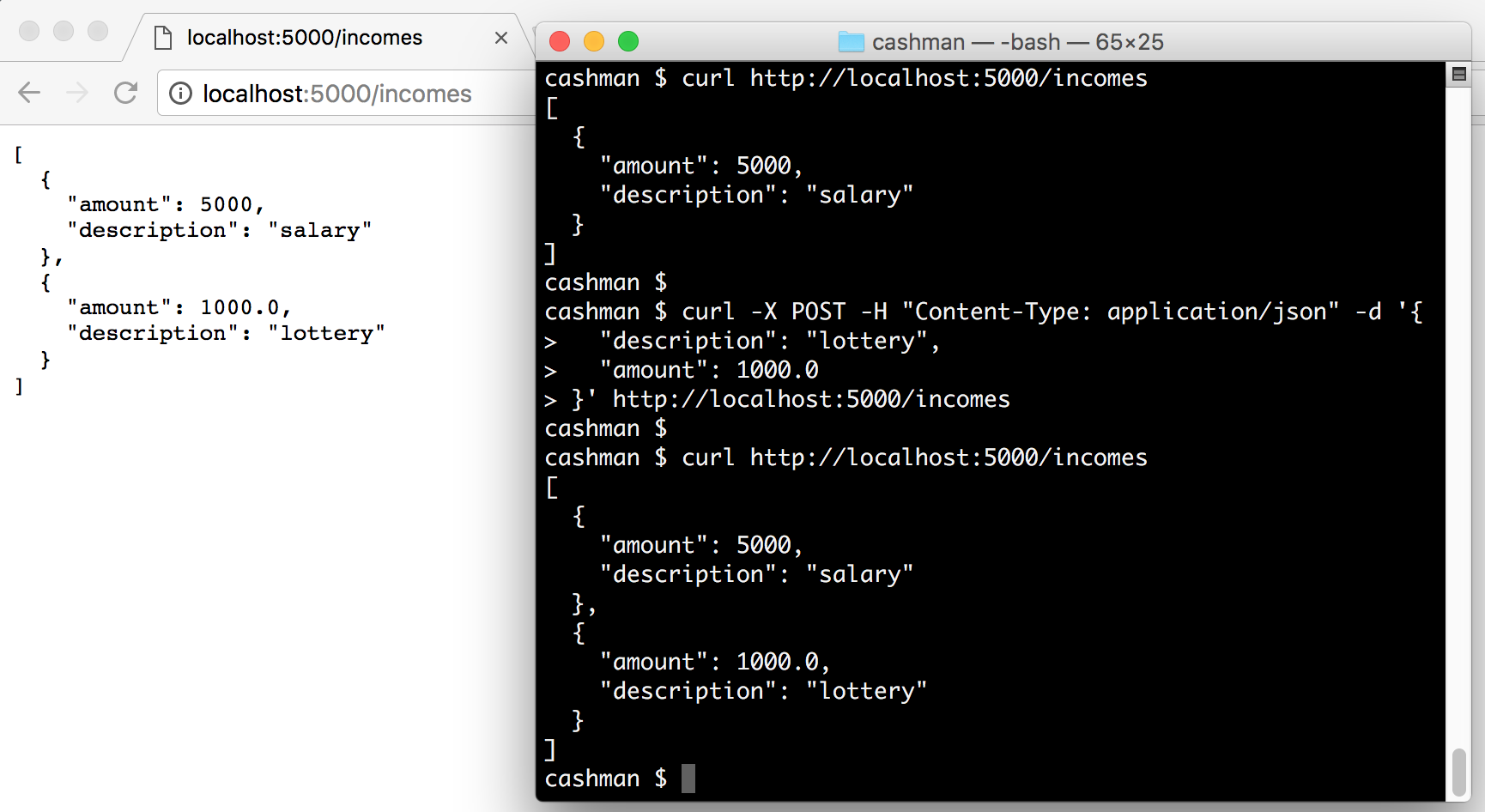
使用 Python 类映射模型
在像上面这样的简单用例中使用字典就足够了。但是,对于处理不同实体并具有多个业务规则和验证的更复杂的应用程序,我们可能需要将数据封装到 Python 类中。
我们将重构我们的应用程序,以学习将实体(如 incomes)映射为类的过程。我们要做的第一件事是创建一个子模块来保存我们所有的实体。让我们在模块中创建一个目录,并添加一个名为它的空文件。
# create model directory inside the cashman module
mkdir -p cashman/model
# initialize it as a module
touch cashman/model/__init__.py映射 Python超类
我们会在这个新的模块/目录中创建三个类:其中两个类的名称暂时省略,而第一个类将作为这两个类的基础类,我们将其命名为Transaction。接下来,我们将在model目录中创建一个名为transaction.py的文件,并编写以下代码:
import datetime as dt
from marshmallow import Schema, fields
class Transaction(object):
def __init__(self, description, amount, type):
self.description = description
self.amount = amount
self.created_at = dt.datetime.now()
self.type = type
def __repr__(self):
return '<Transaction(name={self.description!r})>'.format(self=self)
class TransactionSchema(Schema):
description = fields.Str()
amount = fields.Number()
created_at = fields.Date()
type = fields.Str()除了类定义之外,我们还定义了一个TransactionSchema。我们将使用这个TransactionSchema来从JSON对象反序列化以及将其实例序列化为JSON对象。这个类继承自另一个尚未安装的包中的超类,名为TransactionSchema的基类。
# installing marshmallow as a project dependency
pipenv install marshmallowMarshmallow 是一个广受欢迎的 Python 包,它能够实现复杂数据类型(例如对象)与内置 Python 数据类型之间的转换。利用这个包,我们可以对数据进行验证、序列化和反序列化操作。虽然本文不会深入探讨验证功能(这将是另一篇文章的主题),但如前所述,我们将利用 Marshmallow 通过 API 端点对实体进行序列化和反序列化。
将 Income 和 Expense 映射为 Python 类
为了保持代码的条理性和实用性,我们不会在 API 端点上直接公开 Transaction 类。相反,我们会创建两个专门用于处理请求的类:一个处理收入(Income),另一个处理支出(Expense)。接下来,我们将在名为 income.py 的模块内部使用以下代码来定义一个名为 Transaction 的基类以及 Income 和 Expense 两个子类。
from marshmallow import post_load
from .transaction import Transaction, TransactionSchema
from .transaction_type import TransactionType
class Income(Transaction):
def __init__(self, description, amount):
super(Income, self).__init__(description, amount, TransactionType.INCOME)
def __repr__(self):
return '<Income(name={self.description!r})>'.format(self=self)
class IncomeSchema(TransactionSchema):
@post_load
def make_income(self, data, **kwargs):
return Income(**data)这个类目前为我们的应用程序带来的唯一价值在于它对事务类型进行了硬编码。事务类型将采用 Python 枚举器来表示,尽管我们尚需创建这个枚举器,但它将在未来帮助我们过滤交易。接下来,我们将在名为 transaction_type.py 的文件中定义这个枚举器。
from enum import Enum
class TransactionType(Enum):
INCOME = "INCOME"
EXPENSE = "EXPENSE"枚举器的代码相当简洁,只需定义一个名为 TransactionTypeEnum 的类,该类将继承自 Python 的 Enum 类,并包含两种类型:INCOME 和 EXPENSE。
最后,为了表示支出,我们将创建一个新的类。为此,我们将在名为 expense.py 的文件中添加相应的代码。
from marshmallow import post_load
from .transaction import Transaction, TransactionSchema
from .transaction_type import TransactionType
class Expense(Transaction):
def __init__(self, description, amount):
super(Expense, self).__init__(description, -abs(amount), TransactionType.EXPENSE)
def __repr__(self):
return '<Expense(name={self.description!r})>'.format(self=self)
class ExpenseSchema(TransactionSchema):
@post_load
def make_expense(self, data, **kwargs):
return Expense(**data)与之前提到的类不同,现在的Income类会将给定金额(amount)转换为负数。这样做的目的是无论用户发送的是正值还是负值,我们都能够统一将其存储为负值,从而简化后续的计算过程。而Expense类在处理金额时可能不会有这样的转换,或者会有不同的处理方式。
使用 Marshmallow 序列化和反序列化对象
随着超类及其特化的充分实现,我们现在可以增强我们的端点来处理这些类。让我们将内容替换为:
from flask import Flask, jsonify, request
from cashman.model.expense import Expense, ExpenseSchema
from cashman.model.income import Income, IncomeSchema
from cashman.model.transaction_type import TransactionType
app = Flask(__name__)
transactions = [
Income('Salary', 5000),
Income('Dividends', 200),
Expense('pizza', 50),
Expense('Rock Concert', 100)
]
@app.route('/incomes')
def get_incomes():
schema = IncomeSchema(many=True)
incomes = schema.dump(
filter(lambda t: t.type == TransactionType.INCOME, transactions)
)
return jsonify(incomes)
@app.route('/incomes', methods=['POST'])
def add_income():
income = IncomeSchema().load(request.get_json())
transactions.append(income)
return "", 204
@app.route('/expenses')
def get_expenses():
schema = ExpenseSchema(many=True)
expenses = schema.dump(
filter(lambda t: t.type == TransactionType.EXPENSE, transactions)
)
return jsonify(expenses)
@app.route('/expenses', methods=['POST'])
def add_expense():
expense = ExpenseSchema().load(request.get_json())
transactions.append(expense)
return "", 204
if __name__ == "__main__":
app.run()对于用于检索收入的终端节点,我们定义了一个IncomeSchema实例来生成收入的JSON表示。同时,我们使用过滤功能(filter)从transactions列表中仅提取出收入类型的交易。最后,我们将这个JSON格式的收入数组发送回给用户。
负责接受新收入的端点也经过了重构。此终端节点的关键更改是添加了基于用户发送的JSON数据来加载Income实例的功能。由于transactions列表包含Transaction及其子类(如Income和Expense)的实例,因此我们在列表中添加了新的Income实例。
负责处理费用的另外两个端点(get_expenses和add_expense)几乎是处理收入端点(get_incomes和add_income)的副本。区别在于:
- 处理费用的端点不是处理
Income的实例,而是处理Expense的实例。 - 在筛选交易以将费用发送回用户时,我们不是按
TransactionType.INCOME进行筛选,而是按TransactionType.EXPENSE进行筛选。
这样就完成了我们 API 的实现。如果我们现在运行 Flask 应用程序,我们将能够与端点进行交互,如下所示:
# start the application
./bootstrap.sh
# get expenses
curl http://localhost:5000/expenses
# add a new expense
curl -X POST -H "Content-Type: application/json" -d '{
"amount": 20,
"description": "lottery ticket"
}' http://localhost:5000/expenses
# get incomes
curl http://localhost:5000/incomes
# add a new income
curl -X POST -H "Content-Type: application/json" -d '{
"amount": 300.0,
"description": "loan payment"
}' http://localhost:5000/incomesDocker 化 Flask 应用程序
由于我们打算最终将 API 发布到云端,因此需要创建一个文件来描述在 Docker 容器上运行应用程序所需的内容。为了测试和运行项目的 Docker 化实例,我们需要在开发计算机上安装 Docker。定义一个 Dockerfile 将有助于我们在不同的环境中运行 API。也就是说,在将来,我们还将在生产、暂存等环境中安装 Docker 并运行我们的程序。
让我们使用以下代码在项目的根目录中创建 Dockerfile:
# Using lightweight alpine image
FROM python:3.8-alpine
# Installing packages
RUN apk update
RUN pip install --no-cache-dir pipenv
# Defining working directory and adding source code
WORKDIR /usr/src/app
COPY Pipfile Pipfile.lock bootstrap.sh ./
COPY cashman ./cashman
# Install API dependencies
RUN pipenv install --system --deploy
# Start app
EXPOSE 5000
ENTRYPOINT ["/usr/src/app/bootstrap.sh"]配方中的第一项是定义一个基于默认的 Python 3 Docker 映像来创建 Docker 容器。随后,我们会更新 APK(注意:这里可能是个笔误,通常与 Docker 容器相关的是 apt-get 更新,用于安装或更新软件包,而非 APK,APK 是 Android 应用包的格式)并安装必要的软件。接着,我们使用 pipenv(一个 Python 包管理工具,用于管理依赖关系和虚拟环境)来定义将在 Docker 映像中使用的工作目录,并复制启动和运行应用程序所需的代码到该目录。
注意:对于我们的 ,我们使用 Python 版本 3.8,但是,根据您的系统配置,可能在文件中为 Python 设置了不同的版本。请确保两者中的 Python 版本一致,否则 docker 容器将无法启动服务器。
要基于我们创建的容器创建和运行 Docker 容器,我们可以执行以下命令:
# build the image
docker build -t cashman .
# run a new docker container named cashman
docker run --name cashman \
-d -p 5000:5000 \
cashman
# fetch incomes from the dockerized instance
curl http://localhost:5000/incomes/这很简单但非常有效,使用起来也同样方便。凭借这些命令和Dockerfile,我们可以轻松地运行所需数量的API实例,而不会出现任何问题。只需在主机上(甚至是在另一台主机上)定义另一个端口即可。
使用 Auth0 保护 Python API
使用 Auth0 保护 Python API 非常简单,并且带来了许多很棒的功能。使用 Auth0,我们只需编写几行代码即可获得:
- 可靠的身份管理解决方案,包括单点登录
- 用户管理
- 支持社交身份提供商(如 Facebook、GitHub、Twitter 等)
- 企业身份提供商(Active Directory、LDAP、SAML 等)
- 我们自己的用户数据库
例如,要保护使用 Flask 编写的 Python API,我们可以简单地创建一个装饰器requires_auth:
# Format error response and append status code
def get_token_auth_header():
"""Obtains the access token from the Authorization Header
"""
auth = request.headers.get("Authorization", None)
if not auth:
raise AuthError({"code": "authorization_header_missing",
"description":
"Authorization header is expected"}, 401)
parts = auth.split()
if parts[0].lower() != "bearer":
raise AuthError({"code": "invalid_header",
"description":
"Authorization header must start with"
" Bearer"}, 401)
elif len(parts) == 1:
raise AuthError({"code": "invalid_header",
"description": "Token not found"}, 401)
elif len(parts) > 2:
raise AuthError({"code": "invalid_header",
"description":
"Authorization header must be"
" Bearer token"}, 401)
token = parts[1]
return token
def requires_auth(f):
"""Determines if the access token is valid
"""
@wraps(f)
def decorated(*args, **kwargs):
token = get_token_auth_header()
jsonurl = urlopen("https://"+AUTH0_DOMAIN+"/.well-known/jwks.json")
jwks = json.loads(jsonurl.read())
unverified_header = jwt.get_unverified_header(token)
rsa_key = {}
for key in jwks["keys"]:
if key["kid"] == unverified_header["kid"]:
rsa_key = {
"kty": key["kty"],
"kid": key["kid"],
"use": key["use"],
"n": key["n"],
"e": key["e"]
}
if rsa_key:
try:
payload = jwt.decode(
token,
rsa_key,
algorithms=ALGORITHMS,
audience=API_AUDIENCE,
issuer="https://"+AUTH0_DOMAIN+"/"
)
except jwt.ExpiredSignatureError:
raise AuthError({"code": "token_expired",
"description": "token is expired"}, 401)
except jwt.JWTClaimsError:
raise AuthError({"code": "invalid_claims",
"description":
"incorrect claims,"
"please check the audience and issuer"}, 401)
except Exception:
raise AuthError({"code": "invalid_header",
"description":
"Unable to parse authentication"
" token."}, 400)
_app_ctx_stack.top.current_user = payload
return f(*args, **kwargs)
raise AuthError({"code": "invalid_header",
"description": "Unable to find appropriate key"}, 400)
return decorated然后在我们的端点中使用它:
# Controllers API
# This doesn't need authentication
@app.route("/ping")
@cross_origin(headers=['Content-Type', 'Authorization'])
def ping():
return "All good. You don't need to be authenticated to call this"
# This does need authentication
@app.route("/secured/ping")
@cross_origin(headers=['Content-Type', 'Authorization'])
@requires_auth
def secured_ping():
return "All good. You only get this message if you're authenticated"要了解有关使用 Auth0 保护 Python API 的更多信息,请查看本教程。除了后端技术(如 Python、Java 和 PHP)的教程外,Auth0 Docs 网页还提供移动/本机应用程序和单页应用程序的教程。
后续步骤
在本文中,我们已了解了开发结构清晰的 Flask 应用程序所需的核心组件。我们探讨了如何使用 pipenv 来管理 API 的依赖项。随后,我们安装并运用了 Flask 和 Marshmallow,以创建能够接收和发送 JSON 响应的终端节点。最后,我们还研究了如何将 API Docker 化,以便将应用程序部署到云端。
尽管我们的 API 结构清晰,但其功能性仍有待提升。在后续的文章中,我们将介绍以下可改进之处:
- 使用 SQLAlchemy 实现数据库持久性
- 向 Flask API 应用程序中整合授权功能
- 在 Python 中处理 JWT 的方法
敬请持续关注!
原文链接:https://auth0.com/blog/developing-restful-apis-with-python-and-flask/