使用Rust语言的Rocket.rs和Diesel.rs构建API(采用整洁架构)
在本指南中,我将指导您从头开始在 Rust 中使用 Rocket.rs 构建一个简单的 CRUD(创建、读取、更新、删除)API。我将展示如何利用 Diesel.rs 创建迁移并访问 PostgreSQL 数据库,同时将这些内容与 React + TypeScript 前端整合。在构建项目的过程中,我们将遵循清晰架构的原则,尽管我不会深入讨论其细节,因为这不是本指南的核心内容。
本指南的前提条件如下:
- 您已经设置好了一个 PostgreSQL 数据库。
- 您已安装了最新版本的 Rust(本指南基于 v1.65.0)。
- 您对 Rust 的基本概念和语法有初步了解。
现在一切准备就绪,让我们开始吧!
构建项目架构
第一步是规划并设置应用程序的总体架构。首先,我们需要创建一个Rust项目作为整个应用的起点。
cargo new rust-blog
cd rust-blog在此之后,我们需要删除默认的src文件夹。因为我们将按照Clean Architecture的原则重新组织项目结构。接下来,我们将为架构中的每一层创建一个新的Rust项目或模块。我们的架构将遵循以下结构:
- API层:负责处理API请求并作为路由处理程序。
- 应用层:处理API请求背后的业务逻辑。
- 域层:包含数据库模型和架构。
- 基础架构层:包含数据库迁移和数据库连接代码。
- 共享层:包含项目中需要的任何其他共享模型,例如响应结构。
cargo new api --lib
cargo new application --lib
cargo new domain --lib
cargo new infrastructure --lib
cargo new shared --lib到最后,我们的项目目录结构应该类似于以下形式:
.
├── Cargo.lock
├── Cargo.toml
├── api
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── application
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── domain
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── infrastructure
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
└── shared
├── Cargo.toml
└── src
└── lib.rs现在我们需要在项目的根目录下的 Cargo.toml 文件中整合所有子项目。请清空该文件中的所有内容,并按照以下格式输入:
[workspace]
members = [
"api",
"domain",
"infrastructure",
"application",
"shared",
]很好!我们的模板已经接近完成,现在我们可以开始享受实际操作的乐趣了。
迁移
由于我们选择使用 Diesel.rs 作为数据库管理工具,我们需要安装它的 CLI 工具。Diesel CLI 有一些依赖项,这些依赖项取决于您计划使用的数据库类型:
- 对于 PostgreSQL,您需要安装 libpq。
- 对于 MySQL,您需要 libmysqlclient。
- 对于 SQLite,您需要 libsqlite3。
在这个项目中,我们将使用 PostgreSQL,所以我们只需要关注 libpq。请查阅相关文档,了解如何在您的操作系统上安装这些依赖项。
安装好 libpq 之后,我们可以通过以下命令来安装 Diesel CLI:
cargo install diesel_cli --no-default-features --features postgres安装完成后,我们需要设置一个连接字符串,以便连接到数据库。在项目的根目录下,运行以下命令,并包含您的连接信息:
echo DATABASE_URL=postgres://username:password@localhost/blog > .env现在,Diesel CLI 已经准备好帮助我们完成繁重的工作了。进入 infrastructure 文件夹,然后运行以下命令:
diesel setup这将生成一些文件和文件夹:
- migrations 文件夹:用于存放所有的迁移文件。
- 一个空的迁移文件:我们可以用它来管理数据库 schema。
接下来,使用 Diesel CLI 工具创建一个新的迁移,用于初始化帖子表。
Diesel CLI 会生成一个新的迁移文件,文件名类似于 2022–11–18–090125_create_posts。文件名的第一部分是生成迁移的日期和唯一代码,后面跟着迁移的名称。在这个迁移文件夹中,有两个文件:up.sql 和 down.sql,前者告诉 Diesel CLI 在迁移时需要执行哪些操作,后者告诉 Diesel CLI 如何撤销这些操作。
现在,我们可以开始为迁移编写 SQL 代码了。
-- up.sql
CREATE TABLE posts (
id SERIAL PRIMARY KEY,
title VARCHAR NOT NULL,
body TEXT NOT NULL,
genre VARCHAR NOT NULL,
published BOOLEAN NOT NULL DEFAULT false
)-- down.sql
DROP TABLE posts使用 Diesel CLI,我们可以轻松地应用刚才创建的新迁移。
diesel migration run有关使用 Diesel.rs 运行迁移的更多信息,请访问官方入门指南。
创建连接
在完成第一组迁移并搭建好项目架构之后,接下来我们来编写一些 Rust 代码,以便将我们的应用程序连接到数据库。
# infrastructure/Cargo.toml
[package]
name = "infrastructure"
version = "0.1.0"
edition = "2021"
[dependencies]
diesel = { version = "2.0.0", features = ["postgres"] }
dotenvy = "0.15"// infrastructure/src/lib.rs
use diesel::pg::PgConnection;
use diesel::prelude::*;
use dotenvy::dotenv;
use std::env;
pub fn establish_connection() -> PgConnection {
dotenv().ok();
let database_url = env::var("DATABASE_URL").expect("DATABASE_URL must be set.");
PgConnection::establish(&database_url).unwrap_or_else(|_| panic!("Error connecting to {}", database_url))
}
建立数据库连接后,下一步是为数据库创建一些模型,具体来说就是 Post 和 NewPost。。
模型与架构
首先,我们需要导航到 domain 目录,并将以下模块添加到 lib.rs 文件中。
// domain/src/lib.rs
pub mod models;
pub mod schema;我们将利用模型来定义数据库的结构以及代码中将使用的结构,而 schema 将由 Diesel CLI 自动生成。在我们生成迁移时,Diesel CLI 在 schema.rs 中创建了一个名为 infrastructure 的文件。请将这个文件移动到 #5 位置。如果出于某种原因没有生成 domain/src 目录,您可以在终端中运行 schema.rs 来查看模式。
# domain/Cargo.toml
[package]
name = "domain"
version = "0.1.0"
edition = "2021"
[dependencies]
rocket = { version = "0.5.0-rc.2", features = ["json"] }
diesel = { version = "2.0.0", features = ["postgres"] }
serde = { version = "1.0.147", features = ["derive"] }// domain/src/models.rs
use crate::schema::posts;
use diesel::prelude::*;
use rocket::serde::{Deserialize, Serialize};
use std::cmp::{Ord, Eq, PartialOrd, PartialEq};
// Queryable will generate the code needed to load the struct from an SQL statement
#[derive(Queryable, Serialize, Ord, Eq, PartialEq, PartialOrd)]
pub struct Post {
pub id: i32,
pub title: String,
pub body: String,
pub genre: String,
pub published: bool,
}
#[derive(Insertable, Deserialize)]
#[serde(crate = "rocket::serde")]
#[diesel(table_name = posts)]
pub struct NewPost {
pub title: String,
pub body: String,
pub genre: String,
}// domain/src/schema.rs
// @generated automatically by Diesel CLI.
diesel::table! {
posts (id) {
id -> Int4,
title -> Varchar,
body -> Text,
genre -> Varchar,
published -> Bool,
}
}schema.rs 中的代码可能有所差异,但其核心概念是一致的。每次我们运行或回滚迁移时,这个文件都会得到更新。重要的是要确保我们的 Post 结构体和 posts 表中的字段顺序是一致的。
在定义数据库模型的同时,我们也应该创建一个模型来规范如何格式化 API 响应。请导航到 shared/src 目录,并在那里创建一个新的文件 response_models.rs。
# shared/Cargo.toml
[package]
name = "shared"
version = "0.1.0"
edition = "2021"
[dependencies]
domain = { path = "../domain" }
rocket = { version = "0.5.0-rc.2", features = ["json"] }
serde = { version = "1.0.147", features = ["derive"] }// shared/src/lib.rs
pub mod response_models;// shared/src/response_models.rs
use domain::models::Post;
use rocket::serde::Serialize;
#[derive(Serialize)]
pub enum ResponseBody {
Message(String),
Post(Post),
Posts(Vec<Post>)
}
#[derive(Serialize)]
#[serde(crate = "rocket::serde")]
pub struct Response {
pub body: ResponseBody,
}ResponseBody 枚举将用于定义我们的API可以返回哪些类型的数据,而 Response 结构体将定义如何构造这些响应。
配置 Rocket.rs
哇,我们已经为数据库做了很多设置工作,这一切都是为了确保我们的项目保持最新状态。以下是我们项目结构的当前状况:
.
├── Cargo.lock
├── Cargo.toml
├── api
│ └── ...
├── application
│ └── ...
├── domain
│ ├── Cargo.toml
│ └── src
│ ├── lib.rs
│ └── models.rs
├── infrastructure
│ ├── Cargo.toml
│ ├── migrations
│ │ └── 2022–11–18–090125_create_posts
│ │ ├── up.sql
│ │ └── down.sql
│ └── src
│ ├── lib.rs
│ └── schema.rs
└── shared
├── Cargo.toml
└── src
├── lib.rs
└── response_models.rs完成大部分数据库设置后,让我们开始设置项目的 API 部分。
导航到 api 并导入以下依赖项:
# api/Cargo.toml
[package]
name = "api"
version = "0.1.0"
edition = "2021"
[dependencies]
domain = { path = "../domain" }
application = { path = "../application" }
shared = { path = "../shared" }
rocket = { version = "0.5.0-rc.2", features = ["json"] }
serde_json = "1.0.88"设置了依赖项和对其他文件夹的引用后,让我们创建一个 bin 文件夹来保存 main.rs。
.
└── api
├── Cargo.toml
└── src
├── bin
│ └── main.rs
└── lib.rsmain.rs 将作为我们API的入口点,也就是我们定义计划使用的路由的地方。在构建应用程序的过程中,我们将逐一定义这些路由。
// api/src/lib.rs
pub mod post_handler;// api/src/bin/main.rs
#[macro_use] extern crate rocket;
use api::post_handler;
#[launch]
fn rocket() -> _ {
rocket::build()
.mount("/api", routes![
post_handler::list_posts_handler,
post_handler::list_post_handler,
])
}我们将通过 post_handler.rs 来定义路由的具体实现。为了避免在开发过程中持续遇到LSP(Language Server Protocol)的错误提示,我们将使用 todo!() 宏来告知Rust这些函数或路由尚未完成。
在 post_handler.rs 中,我们将创建一个新的文件 src,并编写以下模板代码:
// api/src/post_handler.rs
use shared::response_models::{Response, ResponseBody};
use application::post::{read};
use domain::models::{Post};
use rocket::{get};
use rocket::response::status::{NotFound};
use rocket::serde::json::Json;
#[get("/")]
pub fn list_posts_handler() -> String {
todo!()
}
#[get("/post/<post_id>")]
pub fn list_post_handler(post_id: i32) -> Result<String, NotFound<String>> {
todo!()
}这里我们定义了两个API请求:
- GET
/api/(用于列出所有帖子) - GET
/api/post/<post_id>(用于根据ID列出特定帖子)
处理 API 逻辑
在请求处理程序模板化之后,我们现在来编写路由所需的逻辑。在application内部,我们将创建一个名为post的新文件夹。这个文件夹将包含处理每个路由逻辑的文件。
# application/Cargo.toml
[package]
name = "application"
version = "0.1.0"
edition = "2021"
[dependencies]
domain = { path = "../domain" }
infrastructure = { path = "../infrastructure" }
shared = { path = "../shared" }
diesel = { version = "2.0.0", features = ["postgres"] }
serde_json = "1.0.88"
rocket = { version = "0.5.0-rc.2", features = ["json"] }// application/src/lib.rs
pub mod post;// application/src/post/mod.rs
pub mod read;// application/src/post/read.rs
use domain::models::Post;
use shared::response_models::{Response, ResponseBody};
use infrastructure::establish_connection;
use diesel::prelude::*;
use rocket::response::status::NotFound;
pub fn list_post(post_id: i32) -> Result<Post, NotFound<String>> {
use domain::schema::posts;
match posts::table.find(post_id).first::<Post>(&mut establish_connection()) {
Ok(post) => Ok(post),
Err(err) => match err {
diesel::result::Error::NotFound => {
let response = Response { body: ResponseBody::Message(format!("Error selecting post with id {} - {}", post_id, err))};
return Err(NotFound(serde_json::to_string(&response).unwrap()));
},
_ => {
panic!("Database error - {}", err);
}
}
}
}
pub fn list_posts() -> Vec<Post> {
use domain::schema::posts;
match posts::table.select(posts::all_columns).load::<Post>(&mut establish_connection()) {
Ok(mut posts) => {
posts.sort();
posts
},
Err(err) => match err {
_ => {
panic!("Database error - {}", err);
}
}
}
}请注意,在使用Rocket.rs框架时,panic!() 会导致返回500 Internal Server Error状态码,而不会直接导致程序崩溃。
完成路由逻辑编写后,让我们回到我们的帖子处理程序,以完善我们的两个GET路由。
// api/src/post_handler.rs
// ...
#[get("/")]
pub fn list_posts_handler() -> String {
// 👇 New function body!
let posts: Vec<Post> = read::list_posts();
let response = Response { body: ResponseBody::Posts(posts) };
serde_json::to_string(&response).unwrap()
}
#[get("/post/<post_id>")]
pub fn list_post_handler(post_id: i32) -> Result<String, NotFound<String>> {
// 👇 New function body!
let post = read::list_post(post_id)?;
let response = Response { body: ResponseBody::Post(post) };
Ok(serde_json::to_string(&response).unwrap())
}恭喜!您刚刚成功编写了前两个路由,并将它们与数据库连接,现在它们都能从数据库中读取内容了。不过,由于我们的表中还没有博客文章,所以可读的内容还不多。
让我们来改变这个状况。
创建帖子
和之前一样,我们将从创建路由处理程序的模板开始。这次,我们将创建一个接受JSON数据的POST请求。
// api/src/post_handler.rs
use shared::response_models::{Response, ResponseBody};
use application::post::{create, read}; // 👈 New!
use domain::models::{Post, NewPost}; // 👈 New!
use rocket::{get, post}; // 👈 New!
use rocket::response::status::{NotFound, Created}; // 👈 New!
use rocket::serde::json::Json;
// ...
#[post("/new_post", format = "application/json", data = "<post>")]
pub fn create_post_handler(post: Json<NewPost>) -> Created<String> {
create::create_post(post)
}这样,我们就可以开始实现create_post()函数了。
// application/src/post/mod.rs
pub mod read;
pub mod create; // 👈 New!// application/src/post/create.rs
use domain::models::{Post, NewPost};
use shared::response_models::{Response, ResponseBody};
use infrastructure::establish_connection;
use diesel::prelude::*;
use rocket::response::status::Created;
use rocket::serde::json::Json;
pub fn create_post(post: Json<NewPost>) -> Created<String> {
use domain::schema::posts;
let post = post.into_inner();
match diesel::insert_into(posts::table).values(&post).get_result::<Post>(&mut establish_connection()) {
Ok(post) => {
let response = Response { body: ResponseBody::Post(post) };
Created::new("").tagged_body(serde_json::to_string(&response).unwrap())
},
Err(err) => match err {
_ => {
panic!("Database error - {}", err);
}
}
}
}最后一步是注册我们的路由,以便它们可以被使用。
// api/src/bin/main.rs
#[macro_use] extern crate rocket;
use api::post_handler;
#[launch]
fn rocket() -> _ {
rocket::build()
.mount("/api", routes![
post_handler::list_posts_handler,
post_handler::list_post_handler,
post_handler::create_post_handler, // 👈 New!
])
}现在,我们已经完成了所有设置,接下来让我们用一些数据来测试我们的API!
CRUD测试
完成了CRUD操作中的两个之后,我们来进行一个小测试。请回到项目的根目录并启动应用程序。
cargo run一旦项目构建完成,打开您常用的API测试工具,然后验证路由是否正常工作,符合预期。

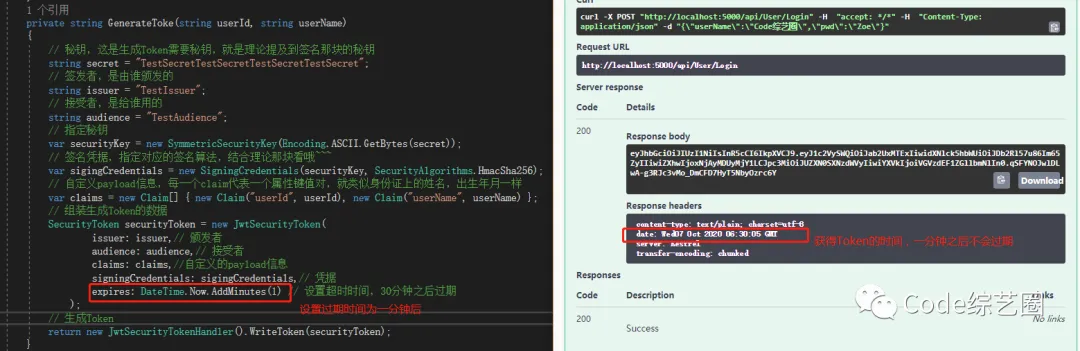
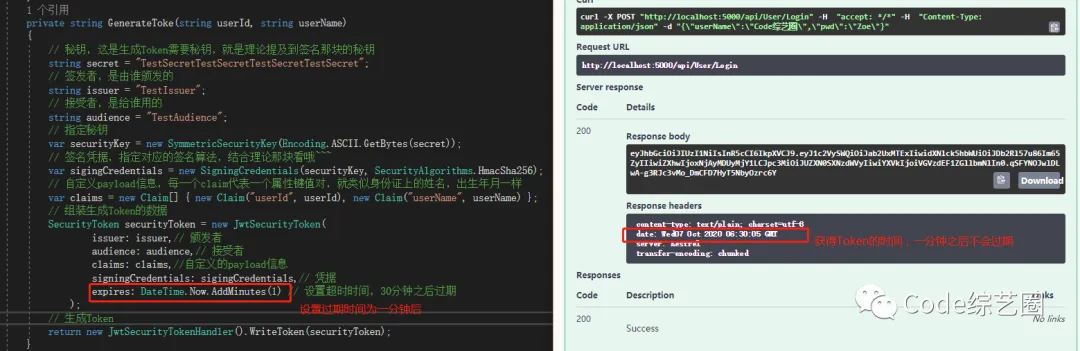
最后两个字母
我们需要实现的最后两个操作是更新(Update)和删除(Delete)。我们将通过发布帖子来实现更新,以及直接删除帖子来实现删除功能。
和之前的两个操作一样,我们来创建相应的处理程序。
// api/src/post_handler.rs
use shared::response_models::{Response, ResponseBody};
use application::post::{create, read, publish, delete}; // 👈 New!
use domain::models::{Post, NewPost};
use rocket::{get, post};
use rocket::response::status::{NotFound, Created};
use rocket::serde::json::Json;
// ...
#[get("/publish/<post_id>")]
pub fn publish_post_handler(post_id: i32) -> Result<String, NotFound<String>> {
let post = publish::publish_post(post_id)?;
let response = Response { body: ResponseBody::Post(post) };
Ok(serde_json::to_string(&response).unwrap())
}
#[get("/delete/<post_id>")]
pub fn delete_post_handler(post_id: i32) -> Result<String, NotFound<String>> {
let posts = delete::delete_post(post_id)?;
let response = Response { body: ResponseBody::Posts(posts) };
Ok(serde_json::to_string(&response).unwrap())
}并为他们实现逻辑。
// application/src/post/mod.rs
pub mod create;
pub mod read;
pub mod publish; // 👈 New!
pub mod delete; // 👈 New!// application/src/post/publish.rs
use domain::models::Post;
use shared::response_models::{Response, ResponseBody};
use infrastructure::establish_connection;
use rocket::response::status::NotFound;
use diesel::prelude::*;
pub fn publish_post(post_id: i32) -> Result<Post, NotFound<String>> {
use domain::schema::posts::dsl::*;
match diesel::update(posts.find(post_id)).set(published.eq(true)).get_result::<Post>(&mut establish_connection()) {
Ok(post) => Ok(post),
Err(err) => match err {
diesel::result::Error::NotFound => {
let response = Response { body: ResponseBody::Message(format!("Error publishing post with id {} - {}", post_id, err))};
return Err(NotFound(serde_json::to_string(&response).unwrap()));
},
_ => {
panic!("Database error - {}", err);
}
}
}
}// application/src/post/delete.rs
use shared::response_models::{Response, ResponseBody};
use infrastructure::establish_connection;
use diesel::prelude::*;
use rocket::response::status::NotFound;
use domain::models::Post;
pub fn delete_post(post_id: i32) -> Result<Vec<Post>, NotFound<String>> {
use domain::schema::posts::dsl::*;
use domain::schema::posts;
let response: Response;
let num_deleted = match diesel::delete(posts.filter(id.eq(post_id))).execute(&mut establish_connection()) {
Ok(count) => count,
Err(err) => match err {
diesel::result::Error::NotFound => {
let response = Response { body: ResponseBody::Message(format!("Error deleting post with id {} - {}", post_id, err))};
return Err(NotFound(serde_json::to_string(&response).unwrap()));
},
_ => {
panic!("Database error - {}", err);
}
}
};
if num_deleted > 0 {
match posts::table.select(posts::all_columns).load::<Post>(&mut establish_connection()) {
Ok(mut posts_) => {
posts_.sort();
Ok(posts_)
},
Err(err) => match err {
_ => {
panic!("Database error - {}", err);
}
}
}
} else {
response = Response { body: ResponseBody::Message(format!("Error - no post with id {}", post_id))};
Err(NotFound(serde_json::to_string(&response).unwrap()))
}
}最后一步,我们需要注册新的路由。
// api/src/bin/main.rs
#[macro_use] extern crate rocket;
use api::post_handler;
#[launch]
fn rocket() -> _ {
rocket::build()
.mount("/api", routes![
post_handler::list_posts_handler,
post_handler::list_post_handler,
post_handler::create_post_handler,
post_handler::publish_post_handler, // 👈 New!
post_handler::delete_post_handler, // 👈 New!
])
}就是这样!现在,您已经成功编写了一个功能齐全的API,它使用Rocket.rs框架,并通过Diesel.rs与PostgreSQL数据库进行连接。此外,该应用程序还遵循了Clean Architecture的架构原则进行组织。
您的项目结构现在应该接近如下:
.
├── Cargo.lock
├── Cargo.toml
├── api
│ ├── Cargo.toml
│ └── src
│ ├── bin
│ │ └── main.rs
│ ├── lib.rs
│ └── post_handler.rs
├── application
│ ├── Cargo.toml
│ └── src
│ ├── lib.rs
│ └── post
│ ├── create.rs
│ ├── delete.rs
│ ├── mod.rs
│ ├── publish.rs
│ └── read.rs
├── domain
│ ├── Cargo.toml
│ └── src
│ ├── lib.rs
│ ├── models.rs
│ └── schema.rs
├── infrastructure
│ ├── Cargo.toml
│ ├── migrations
│ │ └── 2022–11–18–090125_create_posts
│ │ ├── up.sql
│ │ └── down.sql
│ └── src
│ └── lib.rs
└── shared
├── Cargo.toml
└── src
├── lib.rs
└── response_models.rs进一步的改进
在审视整个应用程序时,我们可以考虑以下几点改进措施。
首先,每次使用数据库时我们都在打开一个新的连接,这在大规模应用中可能会导致资源消耗过大。为了解决这个问题,我们可以使用连接池。Rocket.rs 提供了对 R2D2 的内置支持,R2D2 是 Rust 的一个连接池处理库。
其次,Diesel.rs 目前并不支持异步操作——在当前规模下这可能不是大问题,但在大型应用中可能会成为瓶颈。截至目前,Diesel.rs 的官方团队还没有提供异步支持。作为替代方案,可以考虑使用第三方的 crate 来实现异步功能。
最后,可以考虑为 Rust API 创建一个前端用户界面。您可以在项目的根目录下,使用您选择的前端技术栈创建一个名为 web_ui 的新项目。接下来,您只需分别运行前端和后端项目,并通过前端调用 Rust API。以下是一些前端实现的例子,供您参考和获取灵感。
结论
哇!这是一段多么精彩的旅程啊。我们不仅学会了如何使用 Rocket.rs 和 Diesel.rs,还掌握了如何将它们结合起来在 Rust 中创建一个博客 API。不仅如此,我们还为这个 API 构建了一个前端,并按照 Clean Architecture 的原则将整个项目整合到了一个文件结构中。
我希望大家今天能收获满满,亲自动手尝试一下,创造出属于自己的新作品!
感谢阅读!