使用TypeScript、PostgreSQL与Prisma构建后端:数据建模与CRUD 操作
文章目录
本文是有关使用 TypeScript、PostgreSQL 和 Prisma 构建后端的一系列直播课程和文章的一部分。在本文中,我们将回顾首次直播课程的内容,深入了解如何使用 Prisma 来设计数据模型、执行 CRUD(创建、读取、更新、删除)操作以及实现聚合查询。
介绍
本系列的主旨在于,通过解决一个具有普遍性的具体问题——在线课程评分系统,来深入探索并展示现代后端开发中的各种模式、挑战及架构。这一实例之所以被选中,是因为它蕴含了多样化的关系类型,并且其复杂性足以反映真实世界的应用场景。
直播流录音
您可以在上方找到本次直播流的录音,其内容与本文紧密对应。
本系列涵盖的内容概览
本系列将全方位地探讨数据库在后端开发中的核心作用,涵盖以下关键领域:
- 数据建模:将问题域精准映射至数据库架构
- CRUD 系列:利用 Prisma Client 对数据库执行创建、读取、更新及删除操作
- 聚合查询:通过 Prisma 实现复杂的聚合查询,如平均值计算等
- API 层构建
- 数据验证
- 测试策略
- 认证与授权机制
- 与外部 API 的集成方法
- 部署实践
您今日的学习重点
作为本系列的首篇文章,我们将率先着手解决以下问题域,并开发后端的以下关键方面:
- 数据建模:将问题域精准转化为数据库架构
- CRUD 操作:借助 Prisma Client 对数据库执行创建、读取、更新和删除查询
- 聚合查询:运用 Prisma 实现聚合查询,以计算平均值等统计数据
在本文结束时,您将获得一个完整的 Prisma 架构、一个由 Prisma Migrate 自动创建的对应数据库架构,以及一个包含 CRUD 和聚合查询操作的种子脚本。
后续内容预告
本系列的后续部分将逐一深入探讨上述列表中的其他关键领域。
重要提示:在整个指南中,您将遇到多个检查点,它们将帮助您验证每一步骤是否正确执行。
先决条件
假定知识背景
本系列教程预设您已具备 TypeScript、Node.js 以及关系数据库的基础概念。即便您只有 JavaScript 的经验而尚未涉足 TypeScript,也完全有能力跟随本系列的学习步伐。虽然本系列将以 PostgreSQL 作为主要数据库,但所探讨的大多数概念均适用于其他关系型数据库,例如 MySQL。关于 Prisma 的相关知识,您无需提前掌握,因为本系列将对其进行全面介绍。
开发环境
您应该已安装以下内容:
- Node.js
- Docker(将用于运行开发 PostgreSQL 数据库)
若您使用的是 Visual Studio Code 编辑器,我们强烈推荐您安装 Prisma 扩展,以享受语法高亮、代码格式化等实用功能。
注意:如果您不想使用 Docker,您可以在 Heroku 上设置本地 PostgreSQL 数据库或托管 PostgreSQL 数据库。
克隆项目仓库
本系列的源代码已托管在 GitHub 上。
要开始使用,请克隆存储库并安装依赖项:
git clone -b part-1 git@github.com:2color/real-world-grading-app.git
cd real-world-grading-app
npm install注意:通过查看
part-1分支,您将能够从相同的起点跟踪文章。
启动 PostgreSQL
要启动PostgreSQL,请从real-world-grading-app文件夹运行以下命令:
docker-compose up -d注意:Docker 将使用
docker-compose.yml文件启动 PostgreSQL 容器。
在线课程评分系统的数据模型设计
理解问题域与实体定义
在着手构建后端系统时,准确理解问题域是至关重要的第一步。问题域,亦称问题空间,涵盖了定义问题及其解决方案约束的全部信息。通过深入剖析问题域,我们能够清晰地勾勒出数据模型的轮廓和结构。
针对在线评分系统,我们确定了以下核心实体:
- 用户:代表拥有账户的个人。用户通过与课程的不同关联,可以担任教师或学生的角色。这意味着,某位用户在某课程中作为教师的同时,也可能在另一课程中作为学生身份出现。
- 课程:这是一个学习单元,包含至少一名教师、若干名学生,以及一个或多个测试。例如,“TypeScript入门”课程可能有两名教师和十名学生。
- 测试:用于评估学生对课程内容的理解程度。每门课程可以包含多个测试,测试具有特定的日期,并与相应课程相关联。
- 测试结果:记录学生在每次测试中的表现。每个学生在每次测试中可能有多条测试结果,这些结果与为学生评分的教师相关联。
(注:实体既可以表示物理对象,也可以是无形的概念。例如,用户对应的是真实的人,而课程则是一个抽象的概念。)
为了更直观地展示这些实体及其在关系数据库(本例中为PostgreSQL)中的表示,我们可以构建一幅图表。该图表不仅列出了每个实体及其外键,还详细描述了实体间的关联关系及对应的列。
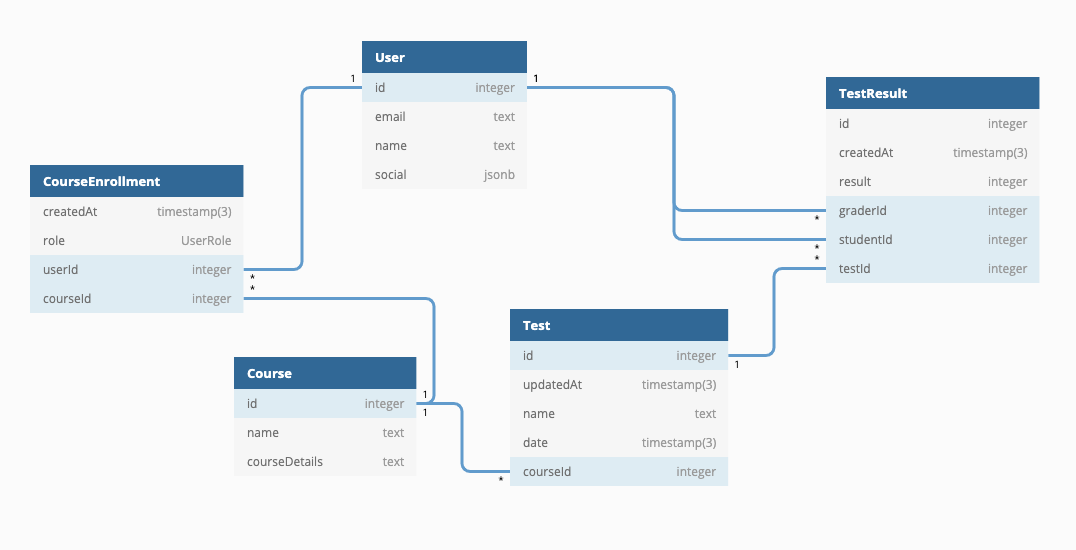
关于该图,首先要注意的是,每个实体都映射到一个数据库表。
该图具有以下关系:
- 一对多(也称为
1-N):- Test 与 TestResult 相关联
- Course 与 Test 相关联
- User 通过 graderId 与 TestResult 相关联
- User 通过 student 属性与 TestResult 相关联
- 多对多(也称为
M-N):- User 与 Course 通过包含两个外键(userId和courseId)的CourseEnrollment关系表相关联。多对多关系通常需要额外的表来实现。这是必要的,以便评分系统具有以下特性:
- 一门课程可以有多个关联用户(作为学生或教师)
- 一个用户可以与多门课程相关联
- User 与 Course 通过包含两个外键(userId和courseId)的CourseEnrollment关系表相关联。多对多关系通常需要额外的表来实现。这是必要的,以便评分系统具有以下特性:
注意:关系表(也称为JOIN表)用于连接两个或多个其他表,从而在它们之间建立关系。在SQL中,创建关系表是表示不同实体之间关系的常见数据建模实践。本质上,这意味着“在数据库中,一个m-n关系被建模为两个1-n关系”。
了解 Prisma 架构
要在数据库中创建表,首先需要定义Prisma架构。Prisma架构是数据库表的声明性配置,Prisma Migrate将使用此配置在数据库中创建表。与上面的实体图类似,它定义了数据库表之间的列和关系。
(Prisma架构是生成的Prisma客户端和Prisma Migrate创建数据库架构的真实来源。)
项目的Prisma架构可以在prisma/schema.prisma中找到。在架构中,您将找到在此步骤中定义的模型(对应数据库表)的占位符和一个datasource块。datasource块定义了要连接的数据库类型以及连接字符串。通过使用env(“DATABASE_URL”),Prisma将从环境变量中加载数据库连接URL。
注意:将秘密隐藏在代码库之外被认为是最佳实践。因此,在datasource块中定义了env(“DATABASE_URL”)。通过设置环境变量,您可以将秘密隐藏在代码库之外。
定义模型
Prisma架构的核心组成部分是model。每个model都直接对应数据库中的一个表。
以下是一个示例,展示了model的基本结构:
model User {
id Int @default(autoincrement()) @id
email String @unique
firstName String
lastName String
social Json?
}在这里,您定义了一个带有多个字段的User模型。每个字段都有一个名称,后跟一个类型和可选的字段属性。例如,id字段可以分解如下:
| 名字 | 类型 | 标量与关系 | 类型修饰符 | 属性 |
|---|---|---|---|---|
id | Int | 标量 | – | @id(表示主键)和 @default(autoincrement())(设置默认自增值) |
email | String | 标量 | – | @unique |
firstName | String | 标量 | – | – |
lastName | String | 标量 | – | – |
social | Json | 标量 | ? (自选) | – |
Prisma 提供了一系列数据类型,这些数据类型会根据您所使用的数据库自动映射到相应的本机数据库类型。
其中,Json 数据类型允许您存储自由格式的 JSON 数据。这对于在 User 记录中存储可能不一致或频繁变更的信息特别有用,因为这些变更可以在不影响后端核心功能的情况下轻松进行。在上面的 User 模型中,Json 数据类型被用于存储如 Twitter、LinkedIn 等社交链接。当您需要向 social 字段添加新的社交配置文件链接时,无需进行数据库迁移。
在充分理解问题域并掌握了使用 Prisma 进行数据建模的方法后,您现在可以将以下模型添加到 prisma/schema.prisma 文件中:
model User {
id Int @default(autoincrement()) @id
email String @unique
firstName String
lastName String
social Json?
}
model Course {
id Int @default(autoincrement()) @id
name String
courseDetails String?
}
model Test {
id Int @default(autoincrement()) @id
updatedAt DateTime @updatedAt
name String // Name of the test
date DateTime // Date of the test
}
model TestResult {
id Int @default(autoincrement()) @id
createdAt DateTime @default(now())
result Int // Percentage precise to one decimal point represented as result * 10^-1
}每个模型都有所有相关的字段,而忽略关系(将在下一步中定义)。
定义关系
一对多
在此步骤中,您将在 Test 和 TestResult 之间定义一个一对多关系。
首先,考虑在上一步中定义的Test和TestResult模型:
model Test {
id Int @default(autoincrement()) @id
updatedAt DateTime @updatedAt
name String
date DateTime
}
model TestResult {
id Int @default(autoincrement()) @id
createdAt DateTime @default(now())
result Int // Percentage precise to one decimal point represented result * 10^-1
}要定义两个模型之间的一对多关系,请添加以下三个字段:
- 在关系的“多”的一方(即TestResult)上添加一个名为testId的字段,类型为Int(关系标量)。这个字段代表底层数据库表中的外键。
- 添加一个名为test的字段,类型为Test(关系字段),并使用@relation属性将该关系标量testId映射到Test模型的主键id上。
- 在Test模型中添加一个名为testResults的字段,类型为TestResult[](关系字段)。
model Test {
id Int @default(autoincrement()) @id
updatedAt DateTime @updatedAt
name String
date DateTime
testResults TestResult[]// relation field
}
model TestResult {
id Int @default(autoincrement()) @id
createdAt DateTime @default(now())
result Int // Percentage precise to one decimal point represented result * 10^-1
testId Int // relation scalar field
test Test @relation(fields: [testId], references: [id]) // relation field
}关系字段,如test和testResults,可以通过其值类型指向另一个模型(例如Test和TestResult)来识别。这些字段的名称将影响使用Prisma客户端以编程方式访问关系的方式,但它们并不代表真实的数据库列。
多对多关系
在此步骤中,您将在 User 和 Course 模型之间定义一个多对多关系。
多对多关系在 Prisma 架构中可以是隐式的,也可以是显式的。在这一部分中,您将了解两者之间的区别以及何时选择隐式或显式。
首先,考虑在上一步中定义的 Test 和 TestResult 模型:
model User {
id Int @default(autoincrement()) @id
email String @unique
firstName String
lastName String
social Json?
}
model Course {
id Int @default(autoincrement()) @id
name String
courseDetails String?
}要创建隐式多对多关系,请将关系字段定义为关系两侧的列表:
model User {
id Int @default(autoincrement()) @id
email String @unique
firstName String
lastName String
social Json?
courses Course[]
}
model Course {
id Int @default(autoincrement()) @id
name String
courseDetails String?
members User[]
}这样,Prisma 将根据所定义的属性来构建关系表,从而支持分级系统:
- 单个课程可以有多个关联用户。
- 单个用户可以与多个课程关联。
然而,评分系统的一个关键需求是允许用户以教师或学生的身份与课程相关联。这意味着我们需要一种机制来存储关于数据库中关系的“附加信息”。
为了满足这一需求,我们可以采用显式的多对多关系。具体来说,我们需要为连接User和Course的关系表添加一个名为CourseEnrollment的新模型,并在该关系表中添加额外的字段来指明用户是课程的教师还是学生。使用显式的多对多关系允许我们在关系表上定义这些额外的字段。
为此,我们将对User和Course模型进行更新,将它们的courses和members字段的类型更改为CourseEnrollment[],如下所示:
model User {
id Int @default(autoincrement()) @id
email String @unique
firstName String
lastName String
social Json?
courses CourseEnrollment[]
}
model Course {
id Int @default(autoincrement()) @id
name String
courseDetails String?
members CourseEnrollment[]
}
model CourseEnrollment {
createdAt DateTime @default(now())
role UserRole
// Relation Fields
userId Int
user User @relation(fields: [userId], references: [id])
courseId Int
course Course @relation(fields: [courseId], references: [id])
@@id([userId, courseId])
@@index([userId, role])
}
enum UserRole {
STUDENT
TEACHER
}关于CourseEnrollment模型的几点说明:
- 它使用UserRole枚举来表示用户是课程的学生还是教师。
- 通过
@@id([userId, courseId])定义了两个字段的多字段主键。这确保了每个用户只能以特定角色(学生或教师)与每个课程关联一次,但不能同时拥有两种角色。 @@index([userId, role])为userId和role字段创建了索引,这有助于提高基于这些字段进行查询的效率。
完整模式
现在您已经了解了关系的定义方式,请使用以下内容更新 Prisma 架构:
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model User {
id Int @id @default(autoincrement())
email String @unique
firstName String
lastName String
social Json?
// Relation fields
courses CourseEnrollment[]
testResults TestResult[] @relation(name: "results")
testsGraded TestResult[] @relation(name: "graded")
}
model Course {
id Int @id @default(autoincrement())
name String
courseDetails String?
// Relation fields
members CourseEnrollment[]
tests Test[]
}
model CourseEnrollment {
createdAt DateTime @default(now())
role UserRole
// Relation Fields
userId Int
courseId Int
user User @relation(fields: [userId], references: [id])
course Course @relation(fields: [courseId], references: [id])
@@id([userId, courseId])
@@index([userId, role])
}
model Test {
id Int @id @default(autoincrement())
updatedAt DateTime @updatedAt
name String
date DateTime
// Relation Fields
courseId Int
course Course @relation(fields: [courseId], references: [id])
testResults TestResult[]
}
model TestResult {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
result Int // Percentage precise to one decimal point represented as result * 10^-1
// Relation Fields
studentId Int
student User @relation(name: "results", fields: [studentId], references: [id])
graderId Int
gradedBy User @relation(name: "graded", fields: [graderId], references: [id])
testId Int
test Test @relation(fields: [testId], references: [id])
}
enum UserRole {
STUDENT
TEACHER
}请注意,TestResult模型与User模型之间存在两个关系:student和gradedBy。student关系代表参加考试的学生,而gradedBy关系则代表给考试评分的老师。当一个模型与另一个模型之间存在多个关系时,我们需要使用@relation参数在关系的name属性上指定,以消除这些关系之间的歧义。
数据库迁移
在定义了Prisma模式之后,接下来您将使用Prisma Migrate在数据库中创建实际的表结构。
首先,在本地设置 DATABASE_URL 环境变量,以便Prisma可以连接到您的数据库。
export DATABASE_URL="postgresql://prisma:prisma@127.0.0.1:5432/grading-app"注意:本地数据库的用户名和密码都定义为
prisma中的docker-compose.yml。
要使用 Prisma Migrate 创建并运行迁移,请在终端中运行以下命令:
npx prisma migrate dev --preview-feature --skip-generate --name "init"该命令将执行两项操作:
- 保存迁移:Prisma Migrate 将拍摄您的架构快照并找出执行迁移所需的 SQL。包含 SQL 的迁移文件将保存到
prisma/migrations - 运行迁移:Prisma Migrate 将执行迁移文件中的 SQL 以运行迁移并更改(或创建)数据库架构
注意:Prisma Migrate 当前处于预览模式。这意味着不建议在生产中使用 Prisma Migrate。
检查点:您应该在输出中看到如下内容:
Prisma Migrate created and applied the following migration(s) from new schema changes:
migrations/
└─ 20201202091734_init/
└─ migration.sql
Everything is now in sync.恭喜,您已成功设计数据模型并创建数据库架构。在下一步中,您将使用 Prisma Client 对数据库执行 CRUD 和聚合查询。
生成 Prisma 客户端
Prisma Client 是为您的数据库架构量身定制的自动生成的数据库客户端。它的工作原理是解析 Prisma 架构并生成一个 TypeScript 客户端,您可以将其导入到代码中。
生成 Prisma 客户端通常需要三个步骤:
- 将以下
generator定义添加到您的Prisma模式:generator client { provider = "prisma-client-js" } - 安装
@prisma/clientnpm包 :npm install --save @prisma/client - 使用以下命令生成Prisma客户端:
npx prisma generate
检查点:您应该在输出中看到以下内容:✔ Generated Prisma Client to ./node_modules/@prisma/client in 57ms
为数据库设定种子数据
在此步骤中,您将使用 Prisma Client 编写种子脚本,目的是用一些示例数据来填充您的数据库。
在这个上下文中,种子脚本其实就是一组利用 Prisma Client 执行的 CRUD(创建、读取、更新和删除)操作。此外,您还可以利用嵌套写入的功能,在单个操作中为相关的数据库实体创建记录。
打开框架src/seed.ts文件,您将在其中找到导入的Prisma Client和两个Prisma Client函数调用:一个用于实例化Prisma Client,另一个用于在脚本完成运行时断开连接。
创建用户
开始,在 main 函数中创建一个用户,如下所示:
const grace = await prisma.user.create({
data: {
email: 'grace@hey.com',
firstName: 'Grace',
lastName: 'Bell',
social: {
facebook: 'gracebell',
twitter: 'therealgracebell',
},
},
})该操作将在User表中创建一行,并返回创建的用户(包括创建的id)。值得注意的是,user将推断出在User中定义的类型@prisma/client:
export type User = {
id: number
email: string
firstName: string
lastName: string
social: JsonValue | null
}要执行seed脚本并创建 User 记录,可以在 seed 中使用 package.json脚本,如下所示:
npm run seed在执行接下来的步骤时,您可能需要多次运行种子脚本。为了防止因重复运行而遇到唯一性约束错误(例如主键冲突或唯一索引冲突),您可以在 main 函数的开头添加代码来清空数据库的内容。
await prisma.testResult.deleteMany({})
await prisma.courseEnrollment.deleteMany({})
await prisma.test.deleteMany({})
await prisma.user.deleteMany({})
await prisma.course.deleteMany({})注意:这些命令将删除每个数据库表中的所有行。请谨慎使用,并在生产中避免这种情况!
创建课程以及相关测试和用户
在此步骤中,您将创建一个课程并使用嵌套写入创建相关测试。
将以下内容添加到 main 函数:
const weekFromNow = add(new Date(), { days: 7 })
const twoWeekFromNow = add(new Date(), { days: 14 })
const monthFromNow = add(new Date(), { days: 28 })
const course = await prisma.course.create({
data: {
name: 'CRUD with Prisma',
tests: {
create: [
{
date: weekFromNow,
name: 'First test',
},
{
date: twoWeekFromNow,
name: 'Second test',
},
{
date: monthFromNow,
name: 'Final exam',
},
],
},
},
})这将会在 Course 表中插入一行数据,并且在 Tests 表中插入三个与之相关联的行(由于 Course 和 Tests 之间存在一对多的关系,因此可以这样做)。
如果您希望将上一步中创建的用户与本课程的教师角色建立关联,那么应该怎么做呢?
User 和 Course 之间存在一个显式的多对多关系。这意味着我们需要在 CourseEnrollment 表中插入一行数据,并通过分配一个特定的角色来将 User 与 Course 关联起来。
这可以按如下方式完成(添加到上一步的查询中):
const weekFromNow = add(new Date(), { days: 7 })
const twoWeekFromNow = add(new Date(), { days: 14 })
const monthFromNow = add(new Date(), { days: 28 })
const course = await prisma.course.create({
data: {
name: 'CRUD with Prisma',
tests: {
create: [
{
date: weekFromNow,
name: 'First test',
},
{
date: twoWeekFromNow,
name: 'Second test',
},
{
date: monthFromNow,
name: 'Final exam',
},
],
},
members: {
create: {
role: 'TEACHER',
user: {
connect: {
email: grace.email,
},
},
},
},
},
include: {
tests: true,
},
})注意:
include参数允许你获取结果中的关系。这将有助于在后面的步骤中将测试结果与测试相关联
当采用嵌套写入(例如为 members 和 tests)时,您有两个选项可供选择:
- connect:用于建立与已存在数据行的关系。
- create:不仅创建新的数据行,还同时建立新的关系。
在 tests 的例子中,你传递了一个对象数组,这些对象与刚刚创建的课程存在关联。
至于 members 的情况,create 和 connect 两者都会被用到。这是至关重要的,因为即便用户数据已经存在于数据库中,也仍然需要在关系表(即 CourseEnrollment,它引用了 members)中插入一行新的数据。这行新数据会利用 connect 与之前已创建的用户数据建立起关系。
创建用户并与课程关联
在上一步中,您创建了课程、相关测试,并为该课程分配了一名教师。在此步骤中,您将创建更多用户,并将他们作为学生与课程关联。
添加以下语句:
const shakuntala = await prisma.user.create({
data: {
email: 'devi@prisma.io',
firstName: 'Shakuntala',
lastName: 'Devi',
courses: {
create: {
role: 'STUDENT',
course: {
connect: { id: course.id },
},
},
},
},
})
const david = await prisma.user.create({
data: {
email: 'david@prisma.io',
firstName: 'David',
lastName: 'Deutsch',
courses: {
create: {
role: 'STUDENT',
course: {
connect: { id: course.id },
},
},
},
},
})为学生添加测试结果
看看TestResult模型,它有三个关系:student、gradedBy和test。要为Shakuntala和大卫添加测试结果,您将使用与前面步骤类似的嵌套写入。
以下是TestResult模型再次供参考:
model TestResult {
id Int @default(autoincrement()) @id
createdAt DateTime @default(now())
result Int // Percentage precise to one decimal point represented as result * 10^-1
// Relation Fields
studentId Int
student User @relation(name: "results", fields: [studentId], references: [id])
graderId Int
gradedBy User @relation(name: "graded", fields: [graderId], references: [id])
testId Int
test Test @relation(fields: [testId], references: [id])
}添加单个测试结果将如下所示:
await prisma.testResult.create({
data: {
gradedBy: {
connect: { email: grace.email },
},
student: {
connect: { email: shakuntala.email },
},
test: {
connect: { id: test.id },
},
result: 950,
},
})要为这三个测试中的每一个添加 David 和 Shakuntala 的测试结果,您可以创建一个循环:
const testResultsDavid = [650, 900, 950]
const testResultsShakuntala = [800, 950, 910]
let counter = 0
for (const test of course.tests) {
await prisma.testResult.create({
data: {
gradedBy: {
connect: { email: grace.email },
},
student: {
connect: { email: shakuntala.email },
},
test: {
connect: { id: test.id },
},
result: testResultsShakuntala[counter],
},
})
await prisma.testResult.create({
data: {
gradedBy: {
connect: { email: grace.email },
},
student: {
connect: { email: david.email },
},
test: {
connect: { id: test.id },
},
result: testResultsDavid[counter],
},
})
counter++
}恭喜您!如果您已经顺利完成了上述步骤,那么就意味着您已经在数据库中成功创建了用户、课程、测试以及测试结果的示例数据。
为了直观地查看并浏览这些数据,您可以运行 Prisma Studio。Prisma Studio 是一个功能强大的数据库可视化工具。要启动 Prisma Studio,您只需在终端中输入并执行以下命令:
npx prisma studio使用 Prisma Client 聚合测试结果
Prisma Client 允许您对模型的数字字段(例如 和 )执行聚合操作。聚合操作从一组 Importing 值(即表中的多行)计算单个结果。例如,计算一组行中列的最小值、最大值和平均值。IntFloatresultTestResult
在此步骤中,您将运行两种聚合操作:
1.对于所有学生的课程中的每个测试,生成表示测试难度或班级对测试主题的理解的聚合:
for (const test of course.tests) {
const results = await prisma.testResult.aggregate({
where: {
testId: test.id,
},
avg: { result: true },
max: { result: true },
min: { result: true },
count: true,
})
console.log(test: ${test.name} (id: ${test.id}), results)
}这将导致以下结果:
test: First test (id: 1) {
avg: { result: 725 },
max: { result: 800 },
min: { result: 650 },
count: 2
}
test: Second test (id: 2) {
avg: { result: 925 },
max: { result: 950 },
min: { result: 900 },
count: 2
}
test: Final exam (id: 3) {
avg: { result: 930 },
max: { result: 950 },
min: { result: 910 },
count: 2
}2.对于所有测试中的每个学生,生成表示学生在课程中的表现的聚合:
// Get aggregates for David
const davidAggregates = await prisma.testResult.aggregate({
where: {
student: { email: david.email },
},
avg: { result: true },
max: { result: true },
min: { result: true },
count: true,
})
console.log(David's results (email: ${david.email}), davidAggregates)
// Get aggregates for Shakuntala
const shakuntalaAggregates = await prisma.testResult.aggregate({
where: {
student: { email: shakuntala.email },
},
avg: { result: true },
max: { result: true },
min: { result: true },
count: true,
})
console.log(Shakuntala's results (email: ${shakuntala.email}), shakuntalaAggregates)这将导致以下终端输出:
David's results (email: david@prisma.io) {
avg: { result: 833.3333333333334 },
max: { result: 950 },
min: { result: 650 },
count: 3
}
Shakuntala's results (email: devi@prisma.io) {
avg: { result: 886.6666666666666 },
max: { result: 950 },
min: { result: 800 },
count: 3
}摘要和后续步骤
本文广泛涵盖了多个基础领域,从问题域的初步探索,到数据建模的深入研究,再到Prisma Schema的解析、使用Prisma Migrate进行数据库迁移的方法,以及借助Prisma Client执行CRUD操作和聚合的技巧。
在着手编写代码之前,明智之举是先规划出问题域。因为问题域将指导数据模型的设计思路,进而对后端的各个环节产生深远影响。
尽管Prisma致力于简化关系数据库的使用流程,但深入理解底层数据库的运作机制仍大有裨益。
建议您查阅Prisma的数据指南,以获取关于数据库工作原理的详尽信息、数据库选择的策略,以及如何将数据库与应用程序高效融合,从而充分发挥其效能。
在本文系列的后续篇章中,我们将深入介绍以下主题:
- API层的构建
- 数据验证的实施
- 测试流程的优化
- 认证机制的建立
- 授权管理的完善
- 与外部API的无缝集成
- 部署策略的制定与实施
原文链接:https://www.prisma.io/blog/backend-prisma-typescript-orm-with-postgresql-data-modeling-tsjs1ps7kip1