使用 FastAPI、Pytorch 和 SerpApi 进行自动训练
这是与人工智能实施相关的系列博客文章的一部分。如果您对故事的背景或进展感兴趣:
前几周,我们讨论了如何利用SerpApi的Google Images Scraper API来自动构建个人图像数据集。本周,我们将使用这些图像,并通过简单的命令对象自动训练一个网络模型,随后将其集成到FastAPI中。
自定义 CSV
为了这一目的,我们需要准备一个包含所需图像的自定义CSV文件。为此,我们将借助pandas库。以下是相关要求:
## create.py
from pydantic import BaseModel
from typing import List
import pandas as pd
import os我们需要创建一个从 SerpApi 的 Google Image Scraper API 收集的项目列表,设置要创建的 csv 文档的名称,并为训练数据定义一个分数。这里的分数概念很简单:TestData(测试数据)将包含我们收集的所有图像,而 TrainingData(训练数据)则只会从中选取一小部分图像。为了这些目的,我们需要构建一个可以传递给相关端点的对象。
class ClassificationsArray(BaseModel):
file_name: str
classifications_array: List[str]
train_data_fraction: float这里提到的分数有一个简单的解释。测试数据集将包含所有图像,而训练数据集将只包含其中的一小部分。这是为了在我们使用尚未训练的图像训练模型后测试模型,即测试数据集的差异。
现在我们已经定义了负责命令的对象,让我们定义 CSVCreator 类:
class CSVCreator:
def __init__(self, ClassificationsArray):
self.classifications_array = ClassificationsArray.classifications_array
self.file_name = ClassificationsArray.file_name
self.rows = []
self.train_data_fraction = ClassificationsArray.train_data_fraction
def gather(self):
for label in self.classifications_array:
images = os.listdir("datasets/test/{}".format(label))
for image in images:
row = ["datasets/test/{}/{}".format(label, image), label]
self.rows.append(row)
def create(self):
df = pd.DataFrame(self.rows, columns = ['path', 'label'])
df.to_csv("datasets/csv/{}.csv".format(self.file_name), index=False)
train_df = df.sample(frac = self.train_data_fraction)
train_df.to_csv("datasets/csv/{}_train.csv".format(self.file_name), index=False)它接收我们提供的参数列表,这些参数是我们对SerpApi的Google Images Scraper API进行查询时所使用的。基于这些参数,它会从相应文件夹中的每张图像生成一个CSV文件。在所有图像处理完毕后,它会随机选取一部分样本,并创建一个用于训练的CSV文件。
现在,让我们在main.py中定义一个函数来执行这一操作。
## main.py
from create import CSVCreator, ClassificationsArray这些类是执行该操作所必需的,而负责具体操作的函数位于 main.py 中。
@app.post("/create/")
def create_csv(arr: ClassificationsArray):
csv = CSVCreator(arr)
csv.gather()
csv.create()
return {"status": "Complete"}举个直观的例子,如果你前往并使用以下参数进行尝试:http://localhost:8000/docs/create/
{
"file_name": "apples_and_oranges",
"classifications_array": [
"Apple",
"Orange"
],
"train_data_fraction": 0.8
}
您将在 called 和 中创建两个 csv 文件datasets/csvapples_and_oranges.csvapples_and_oranges_train.csv
apples_and_oranges.csv将是测试 CSV,将被排序,将包含所有图像,如下所示:
| 路径 | 标签 |
|---|---|
| datasets/test/Apple/37.png | Apple |
| datasets/test/Apple/24.jpg | Apple |
| datasets/test/Apple/77.jpg | Apple |
| datasets/test/Apple/85.jpg | Apple |
| datasets/test/Apple/81.png | Apple |
| datasets/test/Apple/2.png | Apple |
| datasets/test/Apple/12.jpg | Apple |
| datasets/test/Apple/39.jpg | Apple |
| datasets/test/Apple/64.jpg | Apple |
| datasets/test/Apple/44.jpg | Apple |
“apples_and_oranges_train.csv” 将作为训练用的 CSV 文件,其内容将被随机排列,并且会包含 80% 的图像,具体细节如下:
| 路径 | 标签 |
|---|---|
| datasets/test/Apple/38.jpg | Apple |
| datasets/test/Orange/55.jpg | Orange |
| datasets/test/Orange/61.jpg | Orange |
| datasets/test/Apple/23.jpg | Apple |
| datasets/test/Orange/62.png | Orange |
| datasets/test/Orange/39.jpg | Orange |
| datasets/test/Apple/76.jpg | Apple |
| datasets/test/Apple/33.jpg | Apple |
这两个项目将用于创建 Dataset 项。
自定义训练命令
我们需要一个对象来指定训练操作的详细信息,并在多个类之间共享使用以避免循环导入:
## commands.py
from pydantic import BaseModel
class TrainCommands(BaseModel):
model_name: str = "apples_and_oranges"
criterion: str = "CrossEntropyLoss"
annotations_file: str = "apples_and_oranges"
optimizer: str = "SGD"
lr: float = 0.001
momentum: float = 0.9
batch_size: int = 4
n_epoch: int = 2
n_labels: int = None
image_height: int = 500
image_width: int = 500
transform: bool = True
target_transform: bool = True
shuffle: bool = True让我们分解此对象中的项:
| 钥匙 | 解释 |
|---|---|
model_name | 不带扩展名的输出模型名称 |
| criterion | 训练过程的标准名称 |
| annotations_file | 不包含训练文件和扩展名 |
| optimizer | 优化器名称 |
| LR | 优化器的学习率 |
| momentum | Optimizer 的动量 |
| batch_size | 每个批次在 Custom Dataloader 中获取的项目数 |
| n_epoch | 要对训练文件运行的 epoch 数 |
| n_labels | 要训练的标签数量,自动收集到另一个类中 |
| image_height | 所需的固定图像高度 |
| image_width | 所需的固定图像宽度 |
| transform | 是否应应用输入转换 |
| target_transform | 是否应应用标签转换 |
| shuffle | Dataloader 是否应该对数据集进行 shuffle 以获取新项目 |
仅仅固定图像的高度和宽度是不够的,因为这样做可能会导致图像失真。本周,我们不会实施任何去噪的变换操作,但这类操作在批量加载时是必要的,因为批量中的张量图像需要保持相同的大小。
自定义数据集和自定义数据加载器
现在我们已经有了所需的命令,让我们开始了解创建 dataset 和 dataloader 的要求:
## dataset.py
import os
import pandas as pd
import numpy as np
from PIL import Image
from torchvision import transforms
from torch.utils.data import Dataset, DataLoader
from commands import TrainCommands然后让我们初始化我们的 dataset 类:
class CustomImageDataset(Dataset):
def __init__(self, tc: TrainCommands, type: str):
transform = tc.transform
target_transform = tc.target_transform
annotations_file = tc.annotations_file
self.image_height = tc.image_height
self.image_width = tc.image_width
if type == "train":
annotations_file = "{}_train".format(annotations_file)
self.img_labels = pd.read_csv("datasets/csv/{}.csv".format(annotations_file))
unique_labels = list(set(self.img_labels['label'].to_list()))
tc.n_labels = len(unique_labels)
dict_labels = {}
for label in unique_labels:
dict_labels[label] = unique_labels.index(label)
self.dict_labels = dict_labels
if transform == True:
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
else:
self.transform == False
if target_transform == True:
self.target_transform = transforms.Compose([
transforms.ToTensor(),
])
else:
self.transform == False我们使用参数(parameter)来定义我们的操作目标:是初始化数据库,还是指定数据库具有的类型(如 train 或 test)。
if type == "train":
annotations_file = "{}_train".format(annotations_file)
self.img_labels = pd.read_csv("datasets/csv/{}.csv".format(annotations_file))要定义要在模型整形中使用的标签列表,我们使用以下行:
unique_labels = list(set(self.img_labels['label'].to_list()))
tc.n_labels = len(unique_labels)
dict_labels = {}
for label in unique_labels:
dict_labels[label] = unique_labels.index(label)
self.dict_labels = dict_labels这为我们提供了一个要分类的项目的字典,每个项目都有自己唯一的整数:
## self.dict_labels
{
"Apple": 0,
"Orange": 1
}我们必须为 input 和 label 定义某些转换。这些转换定义了如何将它们转换为用于训练的张量,以及在转换后应应用哪些操作:
if transform == True:
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
else:
self.transform == False
if target_transform == True:
self.target_transform = transforms.Compose([
transforms.ToTensor(),
])
else:
self.transform == False我们还定义一个函数,为我们提供给定数据集中的图像数量:
def __len__(self):
return len(self.img_labels)最后,我们需要定义要给出的内容,一个 image 的张量和一个 label 的张量:
def __getitem__(self, idx):
img_path = os.path.join(self.img_labels.iloc[idx, 0])
label = self.img_labels.iloc[idx, 1]
label = self.dict_labels[label]
label_arr = np.full((len(self.dict_labels), 1), 0, dtype=float) #[0.,0.]
label_arr[label] = 1.0 #[0.,1.]
image = Image.open(img_path).convert('RGB')
image = image.resize((self.image_height,self.image_width), Image.ANTIALIAS)
if not self.transform == False:
image = self.transform(image)
if not self.target_transform == False:
label = self.target_transform(label_arr)
return image, label让我们逐个部分地分解它。
以下行将获取具有给定索引的图像路径:
img_path = os.path.join(self.img_labels.iloc[idx, 0])假设数据集是训练数据集,索引为 0:
| datasets/test/Apple/38.jpg | Apple |
路径包含的原因是我们目前将所有文件都保存在同一目录中。该图像数据来源于一个dataframe,因此不会引发问题。接下来的几行代码将从相关标签的索引中创建一个one-hot向量,例如使用self.img_labels.iloc[0, 0]
label = self.img_labels.iloc[idx, 1]
label = self.dict_labels[label]
label_arr = np.full((len(self.dict_labels), 1), 0, dtype=float) #[0.,0.]
label_arr[label] = 1.0 #[0.,1.]我进行评论的原因是,在我们的例子中存在两个标签,即“Apple”和“Orange”,因此one-hot向量的大小将根据这两个标签来定义。接下来,我们会将这个向量转换为numpy数组,以便进一步转换为张量。
image = Image.open(img_path).convert('RGB')
image = image.resize((self.image_height,self.image_width), Image.ANTIALIAS)我们将图像转换为 RGB 格式,以获得一个包含三个维度的向量,其中第三个维度代表颜色。接着,我们使用 ANTIALIAS 方法对图像进行大小调整,以确保调整后的图像仍然能够被人类视觉所识别。尽管我之前提到过,这样的处理通常并不足够,但目前我们就按照这种方式来进行。
现在是自定义数据加载器:
class CustomImageDataLoader:
def __init__(self, tc: TrainCommands, cid: CustomImageDataset):
batch_size = tc.batch_size
train_data = cid(tc, type = "train")
test_data = cid(tc, type = "test")
self.train_dataloader = DataLoader(train_data, batch_size = tc.batch_size, shuffle = tc.shuffle)
self.test_dataloader = DataLoader(test_data, batch_size = batch_size, shuffle = tc.shuffle)
def iterate_training(self):
train_features, train_labels = next(iter(self.train_dataloader))
print(f"Feature batch shape: {train_features.size()}")
print(f"Ladabels batch shape: {train_labels.size()}")
return train_features, train_labels如前所述,我们首先使用参数进行初始化,并在其中定义了数据集。接着,我们利用Pytorch的DataLoader函数来声明一个数据加载器。在调用数据加载器时,我们通过batch size参数来指定每次迭代中要获取的图像数量。
在迭代过程中,我们会使用在初始化阶段定义的自定义图像数据集(Custom Image Dataset),该数据集为我们提供图像及其对应的标签。self.train_dataloader和self.test_dataloader分别代表训练集和测试集的数据加载器。当我们从数据集中获取一批图像时,train_features将表示这批图像的张量,而train_labels则代表这些图像对应的标签的张量。
自动训练
现在我们已经拥有了一个自定义的图像数据集以及一个用于从数据集中加载图像的自定义数据加载器。接下来,我们将使用object来进行自动训练。训练类和模型的要求是:TrainCommands
# train.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from dataset import CustomImageDataLoader, CustomImageDataset
from commands import TrainCommands我们还声明我们要使用的 CNN 模型:
class CNN(nn.Module):
def __init__(self, tc: TrainCommands):
super().__init__()
n_labels = tc.n_labels
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.flatten = nn.Flatten(start_dim=1)
self.fc1 = nn.Linear(16*122*122, 120) # Manually calculated I will explain next week
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, n_labels) #unique label size
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = self.flatten(x)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x这里需要强调的一点是,在我们的案例中,输出大小 n_labels 被设定为 2,因为我们仅在两个类别间进行分类。此外,还有一个计算步骤是基于我手动确定的图像嵌入大小以及图像的高度和宽度。总体而言,这是一个高度通用的图像分类函数。在接下来的几周里,我们将探讨如何自动完成我原先手动进行的大小计算,并研究如何向该函数中添加更多层,以实现更进一步的自动化。
现在,我们来定义一个训练函数 AppleOrangeTrainCommands,该函数将使用自定义的数据集和数据加载器。
class Train:
def __init__(self, tc: TrainCommands, cnn: CNN, cidl: CustomImageDataLoader, cid: CustomImageDataset):
self.loader = cidl(tc, cid)
self.cnn = cnn(tc)
self.criterion = getattr(nn, tc.criterion)()
self.optimizer = getattr(torch.optim, tc.optimizer)(self.cnn.parameters(), lr=tc.lr, momentum=tc.momentum)
self.n_epoch = tc.n_epoch
self.model_name = tc.model_name
def train(self):
for epoch in range(self.n_epoch): # how many times it'll loop over
running_loss = 0.0
for i, data in enumerate(self.loader.train_dataloader):
inputs, labels = data
self.optimizer.zero_grad()
outputs = self.cnn(inputs)
loss = self.criterion(outputs, labels.squeeze())
loss.backward()
self.optimizer.step()
running_loss = running_loss + loss.item()
if i % 5 == 4:
print(
f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0
torch.save(self.cnn.state_dict(), "models/{}.pt".format(self.model_name))让我们逐个部分分解它。以下行使用训练命令使用自定义数据集初始化自定义训练数据集。
self.loader = cidl(tc, cid)下一行使用训练命令声明模型 (卷积神经网络):
self.cnn = cnn(tc)以下行负责创建标准:
self.criterion = getattr(nn, tc.criterion)()在我们的例子中,使用torch.nn.CrossEntropyLoss()是等价的。
下一行用于创建具有所需参数的优化器:
self.optimizer = getattr(torch.optim, tc.optimizer)(self.cnn.parameters(), lr=tc.lr, momentum=tc.momentum)这相当于说,在未来的几周内,我们将开发一种机制,允许为可选参数指定可选的名称,从而能够灵活地配置优化器和标准。但就目前而言,现有的方法已经足够使用。例如,我们可以使用 torch.optim.SGD(CNN.parameters(), lr=0.001, momentum=0.9) 来初始化一个带有特定学习率和动量的随机梯度下降优化器。
最后,我们需要设定要运行的训练周期(epoch)数,并确定保存模型的名称:
self.n_epoch = tc.n_epoch
self.model_name = tc.model_name在以下部分中,我们将迭代 epochs,声明损失,并使用 function 从数据集中调用图像和标签:
def train(self):
for epoch in range(self.n_epoch): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(self.loader.train_dataloader):数据将以元组形式出现:
inputs, labels = data然后我们在 optimizer 中将梯度归零:
self.optimizer.zero_grad()运行预测:
outputs = self.cnn(inputs)然后,使用我们的标准将预测与实际标签进行比较,以计算损失:
loss = self.criterion(outputs, labels.squeeze())标签在此处被挤压以匹配要在 criterion function 中计算的输入的形状。
然后我们运行反向传播以自动重新累积梯度:
loss.backward()我们逐步执行优化器:
self.optimizer.step()然后更新 :running_loss
running_loss = running_loss + loss.item()以下行是每 5 个步骤的流程输出:
if i % 5 == 4:
print(
f'[{epoch + 1}, {i + 1:5d}] loss: {running_loss / 2000:.3f}')
running_loss = 0.0最后,我们将模型保存到所需的位置:
torch.save(self.cnn.state_dict(), "models/{}.pt".format(self.model_name))现在我们已经万事俱备,接下来将在main.py中声明一个端点,通过这个端点我们可以接收训练命令。
# main.py
from fastapi import FastAPI
from add import Download, Query
from create import CSVCreator, ClassificationsArray
from dataset import CustomImageDataLoader, CustomImageDataset
from train import CNN, Train
from commands import TrainCommands
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.post("/add/")
def create_query(query: Query):
## Create unique links
serpapi = Download(query)
serpapi.download_all_images()
return {"status": "Complete"}
@app.post("/create/")
def create_csv(arr: ClassificationsArray):
csv = CSVCreator(arr)
csv.gather()
csv.create()
return {"status": "Complete"}
@app.post("/train/")
def train(tc: TrainCommands):
trainer = Train(tc, CNN, CustomImageDataLoader, CustomImageDataset)
trainer.train()
return {"status": "Success"}/train/endpoint 将接收您的命令,并自动为您训练一个模型:
现在,如果您访问并使用以下路径尝试我们的服务:localhost:8000/docs/train/,并附带相应的参数。
{
"model_name": "apples_and_oranges",
"criterion": "CrossEntropyLoss",
"annotations_file": "apple_orange",
"optimizer": "SGD",
"lr": 0.001,
"momentum": 0.9,
"batch_size": 4,
"n_epoch": 2,
"n_labels": 0,
"image_height": 500,
"image_width": 500,
"transform": true,
"target_transform": true,
"shuffle": true
}
您可以从终端观察训练过程,因为我们为 epochs 声明了 print 函数:
训练结束后,您将在文件夹中保存一个模型,其中包含您指定的所需名称: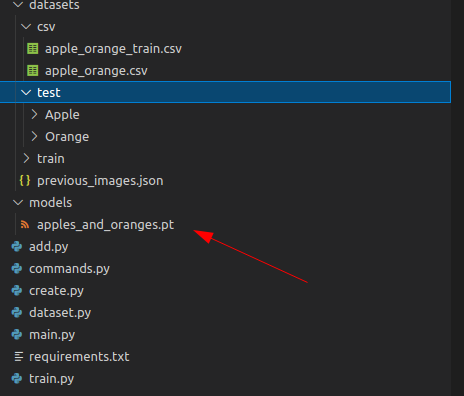
结论
我衷心感谢SerpApi的杰出团队,正是他们的努力使得这篇博文得以问世。同时,我也非常感谢读者的关注与支持。在接下来的几周里,我们将深入探讨如何提升本文提及的某些部分的效率与可定制性。此外,我们还将更全面地讨论FastAPI的异步处理机制,以及如何实现对SerpApi的Google Images Scraper API的异步调用。
原文链接:https://serpapi.com/blog/automatic-training-fastapi-pytorch-serpapi/