音频 API 快速入门指南:在 Linux、Windows、FreeBSD 和 macOS 上播放和录制声音
听觉是我们人类所拥有的基本感官之一,与视觉、嗅觉、味觉和触觉并列。若我们失去听力,我们所认知的世界将变得单调乏味。那将是一片彻底的寂静,仅是想象便令人不寒而栗。说话让我们的生活充满乐趣,因为还有什么能比与亲朋好友交谈更让人愉悦呢?此外,借助电脑和耳机,我们无论身处何地都能聆听喜爱的音乐。通过集成在手机和笔记本电脑中的微型麦克风,我们现在能够借助互联网与世界各地的人们交流。但仅有计算机硬件是不够的,计算机软件才真正决定了硬件如何以及何时运行。操作系统为希望利用计算机音频功能的应用程序提供了实现这一目的的途径。在实际应用中,音频数据会经过一系列复杂的处理,如动态转换、压缩与解压缩、衰减和过滤等,从一端传输到另一端。但最终,这些处理都归结为两个基本过程:播放声音和录制声音。
今天我们将讨论如何使用流行的操作系统提供的 API:如果您想自己创建一个与音频 I/O 一起使用的应用程序,这是一个必不可少的知识。然而,我们面临一个问题:没有一个API能被所有操作系统支持。实际上,存在完全不同的API、方法和逻辑。虽然我们可以使用某些库来解决这些问题,但在那种情况下,我们将无法了解底层的运作机制,这又有何意义呢?但人类的天性驱使我们有时想要更深入地探索,学习更多本质的东西。因此,我们要学习操作系统默认提供的API,如ALSA(Linux)、PulseAudio(Linux)、WASAPI(Windows)、OSS(FreeBSD)和CoreAudio(macOS)。
尽管我试图解释我认为重要的每一个细节,但这些 API 非常复杂,以至于在任何情况下您都需要找到更详细地解释所有函数、标识符、参数等的官方文档。完成本教程并不意味着您不需要阅读官方文档 – 您必须阅读,否则您最终会对您编写的代码的理解不完整。
尽管我试图详尽解释每个我认为重要的细节,但这些API非常复杂,您在任何情况下都需要查阅更详细的官方文档来解释所有函数、标识符和参数等。完成本教程并不意味着您可以跳过官方文档——您必须阅读,否则您对您编写的代码的理解将是不完整的。
本指南的所有示例代码均可在以下链接获取:https://github.com/stsaz/audio-api-quick-start-guide。我建议您在阅读本教程时,同时打开一个示例文件,以便您更好地理解每个代码语句在整体上下文中的作用。当您准备更深入地使用音频API时,您可以分析ffaudio库的代码:https://github.com/stsaz/ffaudio。
概述
首先,我将介绍一般如何使用音频设备,而不涉及任何 API 细节。
步骤 1.这一切都始于列举可用的音频设备。操作系统管理着两种类型的设备:播放设备(我们向其写入音频数据)和捕获设备(我们从中读取音频数据)。每种设备都具备自己的唯一ID、名称以及其他属性。应用程序可以访问这些数据,以便选择最适合其需求的设备,或者向用户展示所有设备供其手动选择。然而,在大多数情况下,我们无需选择特定设备,只需使用默认设备即可。此时,我们无需枚举设备或检索任何属性。
值得注意的是,系统中可能存在已注册但当前不可用的设备,例如用户已在系统设置中将其禁用。如果我们在编写代码时执行了所有必要的错误检查,通常可以避免遇到这些禁用的设备。
有时,我们可以检索到特定设备所支持的所有音频格式列表,但对此信息的依赖度不应过高,因为它可能不具备跨平台性。相反,更好的做法是为该设备分配一个音频缓冲区,以实际验证其是否支持该音频格式。
步骤 2。在确定了要使用的设备之后,我们继续创建音频缓冲区并将其分配给该设备。在这个过程中,我们必须明确我们想要使用的音频格式,包括采样格式(如有符号整数)、采样宽度(如16位)、采样率(如48000 Hz)以及声道数量(如立体声为2)。
采样格式的示例包括有符号整数、无符号整数或浮点数。一些音频驱动程序可能支持所有类型的整数和浮点数,而有些可能仅支持16位有符号整数而不支持其他类型。但需要注意的是,这并不意味着设备可以原生地使用所有支持的格式,因为音频设备软件可能会在内部进行采样转换。
样本宽度指的是每个样本的大小,16位是CD音频质量的标准,但在某些音频处理场景中可能不是最佳选择,因为它容易产生伪影(尽管在实际听觉上我们可能很难分辨出这种差异)。24位样本则要好得多,许多音频设备都支持这一宽度。然而,专业的声音应用程序在执行混音操作和其他类型的滤波时,为了不给声音伪影留下任何机会,会在内部使用64位浮点样本。
采样率是指获取1秒整音频数据所需的采样数。最受欢迎的采样率包括44.1KHz和48KHz,但发烧友可能会认为96KHz采样率更佳。通常,音频设备可以支持高达192KHz的采样率,但我并不认为普通人能够分辨出48KHz及以上采样率之间的区别。请注意,采样率仅指每个通道每秒的采样数。因此,对于16位48KHz的立体声流,我们实际上需要处理的字节数是2乘以48000再乘以2。
0 sec 1 sec
| (Sample 0) ... (Sample 47999) |
| short[L] ... short[L] |
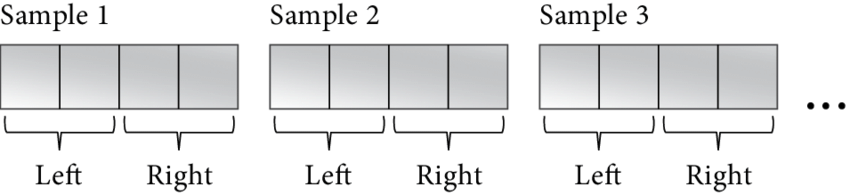
| short[R] ... short[R] 有时,样本也被称为帧,这与视频帧的概念相似。音频样本(或帧)是一组数值,它们共同表示同一时间点每个硬件设备通道的音频信号强度。但请注意,一些官方文档对此持有不同观点:它们明确定义样本仅为单个数值,而帧则是所有通道这些数值的集合。那么,为什么我们不将采样率称为帧速率呢?请再次观察上面的图表。在那里,样本宽度(即列宽)保持为16位,无论我们有多少个通道(即下面的行数)。样本格式(在我们的例子中为有符号整数)也始终保持不变。采样率是指1秒内音频的列数,这与声道的数量无关。因此,我根据自己的逻辑理解了音频样本的定义(尽管其他人可能有不同的定义),而您的逻辑可能与我不同,这完全没问题。
样本大小(或帧大小)是处理数字音频时经常使用的另一个属性。它只是一个常量值,方便我们在字节数和音频样本数之间进行转换:
int sample_size = sample_width/8 * channels;
int bytes_in_buffer = samples_in_buffer * sample_size;当然,我们还可以为音频缓冲区设定更多参数,例如缓冲区的长度(可以是以毫秒或字节为单位来衡量),这是调控声音延迟的关键属性。但请注意,每种设备对于这一参数都有其自身的限制:若设备不支持,我们无法将长度设定得过低。对我而言,250毫秒对于多数应用程序而言是个不错的起点,不过,一些实时应用程序为了尽可能降低延迟,会接受更高的CPU使用率,这完全取决于您的具体应用场景。
在开启音频设备时,若我们使用的API返回“格式错误”的提示,这意味着我们选择的音频格式未得到底层软件或物理设备的支持,对此我们应始终有所准备。此时,我们应挑选更合适的格式并重新创建缓冲区。
值得注意的是,一个物理设备在同一时间内只能被打开一次,我们无法将两个或多个音频缓冲区连接到同一设备,否则将会引发混乱。然而,在实际应用中,我们可能会遇到多个音频应用程序希望通过单个设备并行播放音频的情况。Windows在WASAPI中通过引入共享模式和独占模式来解决这一问题。在共享模式下,我们将音频缓冲区附加到虚拟设备上,该设备会将来自不同应用程序的所有音频流进行混合,并可能应用一些过滤效果(例如声音衰减),然后将处理后的数据传递给物理设备。Linux上的PulseAudio在ALSA上的工作原理与此相同。当然,共享模式的缺点是可能会带来更高的延迟和CPU使用率。另一方面,在独占模式下,我们几乎可以直接与音频设备驱动程序建立连接,这意味着我们可以获得最高的音质和最小的延迟,但在使用该模式时,其他应用程序将无法访问此设备。
步骤3:在我们准备并配置好音频缓冲区后,就可以开始使用了:向其写入数据进行播放,或从中读取数据进行音频录制。音频缓冲区实际上是一个循环缓冲区,其中的读写操作会以环形的方式无限循环进行。

但有一个关键问题:当在同一个内存缓冲区上执行输入/输出(I/O)操作时,CPU 必须与音频设备保持同步。否则,CPU 可能会全速运行并在音频缓冲区上执行数百万次操作,而音频设备可能才刚刚完成第一轮操作。因此,CPU 必须等待音频设备缓慢地完成其工作。随后,CPU 会在一段时间后短暂地唤醒,以便从设备获取更多的音频数据(在录制模式下)或向设备提供新的数据(在播放模式下),然后 CPU 会继续进入休眠状态。这里,音频缓冲区长度参数就显得尤为重要:缓冲区越小,CPU 需要唤醒以执行工作的次数就越多。循环缓冲区可能处于三种不同的状态:空、半满和已满,我们需要了解如何在代码中正确处理这些状态。
在录制模式下,如果缓冲区为空,则意味着我们当前没有可用的音频样本,必须等待音频设备将新的数据放入其中。
播放时 如果缓冲区为空,则意味着我们可以随时将音频数据写入缓冲区。然而,如果音频设备正在运行且没有更多数据可供读取,就意味着我们没有跟上设备的节奏,这种情况被称为缓冲区下溢。如果发生这种情况,我们应该暂停设备,填充音频缓冲区,然后恢复正常操作。
录制时缓冲区半满意味着缓冲区内有一些音频样本,但尚未完全填满。我们应该尽快处理可用数据,并将此数据区域标记为已读(或无用),以避免下次重复处理。
播放流的半满缓冲区意味着我们可以向其中添加更多数据。
如果缓冲区已满,则意味着我们在读取可用数据方面落后于音频设备。此时,音频设备已经完全填满了缓冲区,没有更多空间来容纳新数据。这种状态被称为缓冲区上溢。在这种情况下,我们必须重置缓冲区并恢复(取消暂停)设备以继续正常操作。
播放流的缓冲区已满是正常情况,我们应该等到有空闲空间可用。
关于如何执行等待过程,一些API提供了订阅通知的方法,以实现尽可能低的I/O延迟。例如,ALSA能在将数据写入音频录制缓冲区后,向我们的进程发送信号。而WASAPI在独占模式下,则可通过Windows内核事件对象进行通知。但对于那些不需要高度精确性的应用程序,我们可以简单地使用自己的计时器,或者采用类似的方法。在使用这些方法时,我们需确保休眠时间不超过音频缓冲区长度的一半。例如,对于500毫秒的缓冲区,我们可以将计时器设置为250毫秒,并在每次缓冲区旋转时执行两次I/O操作。当然,您也明白,对于极小的缓冲区,我们无法可靠地做到这一点,因为即使是轻微的延迟也可能导致音频卡顿。不过,在本教程中,我们并不需要高度精确性,但我们需要的是易于理解的小代码段。
步骤 4。对于播放缓冲区,还有一项需要注意的事项。在我们完成向音频缓冲区写入所有数据后,仍需等待其处理完这些数据。换句话说,我们应确保缓冲区被完全耗尽。有时,我们可能需要手动向缓冲区添加静音,以防止播放旧的无效数据,从而避免音频伪影的出现。当我们观察到整个缓冲区已清空后,即可停止设备并关闭缓冲区。
此外,请记住,在正常操作期间可能会出现以下问题:
- 用户可以关闭物理音频设备,并且我们无法使用。
- 虚拟音频设备可以由用户重新配置,并要求我们重新打开并重新配置音频缓冲区。
- CPU 忙于执行其他一些操作(针对其他应用程序或系统服务),导致缓冲区溢出/欠载情况。
细心的程序员必须始终检查所有可能的情况,检查我们调用的 API 函数的所有返回代码并处理它们,或者向用户显示错误消息。我没有在我的示例代码中这样做,只是因为本教程是为了让您了解音频 API。而这个目的可以通过尽可能短的代码供你阅读来实现 – 在这种情况下,到处都是错误检查会使情况变得更糟。
当然,在我们完成后,我们必须关闭音频缓冲区和设备的处理程序,释放分配的内存区域。但请注意,如果我们只是想播放另一个音频文件,那么重新准备新的音频缓冲区可能会花费大量时间,因此我们应始终尝试尽可能重用现有的缓冲区。
音频数据表示
现在我们来谈谈音频数据实际上是如何组织的以及如何分析它。音频缓冲区有两种类型:交错和非交错。Interleaved buffer 是一个连续的内存区域,其中的音频样本集逐个进行。这是 16 位立体声音频的样子:
short[0][L]
short[0][R]
short[1][L]
short[1][R]
...
其中,0 和 1 是样本索引,L 和 R 是通道。例如,我们如何读取样本 #9 的两个通道的值,方法是将样本索引乘以通道数:
short *samples = (short*)buffer;
short sample_9_left = samples[9*2];
short sample_9_right = samples[9*2 + 1];这些 16 位有符号值是信号强度,其中 0 表示静音。但信号强度通常以 dB 值来衡量。以下是我们将整数值转换为 dB 的方法:
short sample = ...;
double gain = (double)sample * (1 / 32768.0);
double db = log10(gain) * 20;在这里,我们首先将整数转换为浮点数 – 这是增益值,其中 0.0 是静音,+/-1.0 – 最大信号。然后,使用公式将增益转换为 dB 值。如果我们想进行相反的转换,我们可以使用以下代码:gain = 10 ^ (db / 20)
#include <emmintrin.h> // SSE2 functions. All AMD64 CPU support them.
double db = ...;
double gain = pow(10, db / 20);
double d = gain * 32768.0;
short sample;
if (d < -32768.0)
sample = -0x8000;
else if (d > 32768.0 - 1)
sample = 0x7fff;
else
sample = _mm_cvtsd_si32(_mm_load_sd(&d));我不是音频数学专家,我只是向您展示我是如何做到的,但您可能会找到更好的解决方案。
最流行的音频编解码器和大多数音频 API 使用交错音频数据格式。
相比之下,非交错缓冲区(Non-interleaved buffer)则是一个数组,它(可能)由不同的内存区域组成,每个通道占据一个区域。
L -> {
short[0][L]
short[1][L]
...
}
R -> {
short[0][R]
short[1][R]
...
}例如,主流的 Vorbis 和 FLAC 音频编解码器就采用了这种格式。如您所见,在非交错缓冲区中操作单个通道内的样本非常简单。例如,交换左右声道仅需几个 CPU 周期来交换指针即可完成。
我认为我们已经掌握了足够的理论知识,现在让我们通过一些真实的代码来实践,这些代码将使用真实的音频 API。
Linux 和 ALSA
ALSA 是 Linux 的默认音频子系统,因此我们从它开始了解。ALSA 由两部分组成:位于内核空间的音频驱动程序和提供对驱动程序通用访问的用户空间 API。我们将学习的是用户态 ALSA API,这是在用户态下访问声音硬件的最低级别接口。
首先,我们需要在 Fedora 上安装 ALSA 的开发包。安装完成后,我们就可以在代码中包含相关的库了,即 libalsa-devel。
#include <alsa/asoundlib.h>当链接我们的二进制文件时,我们添加了 flag。
ALSA:枚举设备
首先,遍历系统中所有可用的声卡,直到得到 -1 索引:
int icard = -1;
for (;;) {
snd_card_next(&icard);
if (icard == -1)
break;
...
}对于每个声卡索引,我们可以准备一个以 NULL 结尾的字符串来作为此声卡的唯一标识符。我们通过调用 snd_ctl_open() 函数,并传入这个标识符,来接收对应的声卡处理程序。在处理完毕后,我们使用 snd_ctl_close() 函数来关闭这个声卡处理程序,从而结束对其的使用。
char scard[32];
snprintf(scard, sizeof(scard), "hw:%u", icard);
snd_ctl_t *sctl = NULL;
snd_ctl_open(&sctl, scard, 0);
...
snd_ctl_close(sctl);对于每个声卡,我们遍历其所有设备,直到得到 -1 索引:
int idev = -1;
for (;;) {
if (0 != snd_ctl_pcm_next_device(sctl, &idev)
|| idev == -1)
break;
...
}现在,我们准备一个以 NULL 结尾的字符串,例如 plughw:0,0,这是我们在后续分配音频缓冲区时可能会使用的设备ID。前缀 plughw: 表示 ALSA 将在必要时尝试应用一些音频转换。如果我们希望直接使用硬件设备,应该使用 hw: 前缀来代替。对于默认设备,我们可能会使用某个特定的字符串,但理论上这个字符串可能不可用——因此,您应该为用户提供一种选择特定设备的方法。请注意,plughw:hw: 是不正确的用法,正确的应该是直接使用 hw: 后跟设备编号,如 hw:0,0,或者在使用 plughw: 前缀时也指定设备编号,如 plughw:0,0。
char device_id[64];
snprintf(device_id, sizeof(device_id), "plughw:%u,%u", icard, idev);ALSA:打开音频缓冲区
现在我们知道了设备 ID,我们可以使用 为其分配新的音频缓冲区。请注意,我们无法两次打开同一个 ALSA 设备。如果系统 PulseAudio 进程使用此设备,则在我们按住它时,系统中的其他应用程序将无法使用音频。
snd_pcm_t *pcm;
const char *device_id = "plughw:0,0";
int mode = (playback) ? SND_PCM_STREAM_PLAYBACK : SND_PCM_STREAM_CAPTURE;
snd_pcm_open(&pcm, device_id, mode, 0);
...
snd_pcm_close(pcm);接下来,我们需要设置缓冲区的参数。在这个过程中,我们会告知 ALSA,我们打算使用 mmap 风格的函数来直接访问其缓冲区,并且我们期望的是一个交错的缓冲区。随后,我们会设定音频格式以及缓冲区长度。值得注意的是,如果设备不支持我们提供的这些值,ALSA 会自动为我们更新部分值。然而,如果设备不支持我们指定的示例格式,那么我们就需要通过使用 snd_pcm_hw_params_get_format_mask() 和 snd_pcm_format_mask_test() 等函数来进行检查和处理。在现实生活中,您应当在高级代码中验证这些新配置是否被支持。
snd_pcm_hw_params_t *params;
snd_pcm_hw_params_alloca(¶ms);
snd_pcm_hw_params_any(pcm, params);
int access = SND_PCM_ACCESS_MMAP_INTERLEAVED;
snd_pcm_hw_params_set_access(pcm, params, access);
int format = SND_PCM_FORMAT_S16_LE;
snd_pcm_hw_params_set_format(pcm, params, format);
u_int channels = 2;
snd_pcm_hw_params_set_channels_near(pcm, params, &channels);
u_int sample_rate = 48000;
snd_pcm_hw_params_set_rate_near(pcm, params, &sample_rate, 0);
u_int buffer_length_usec = 500 * 1000;
snd_pcm_hw_params_set_buffer_time_near(pcm, params, &buffer_length_usec, NULL);
snd_pcm_hw_params(pcm, params);最后,我们需要记住帧大小和整个缓冲区大小(以字节为单位)。
int frame_size = (16/8) * channels;
int buf_size = sample_rate * (16/8) * channels * buffer_length_usec / 1000000;ALSA:录制音频
要开始录制,我们调用 :
snd_pcm_start(pcm);在正常操作期间,我们向 ALSA 请求一些新的音频数据,这些数据返回缓冲区、有效区域的偏移量和有效帧数。要使此函数正常工作,我们应该首先调用 which 更新缓冲区的内部指针。处理完数据后,必须处理数据。
for (;;) {
snd_pcm_avail_update(pcm);
const snd_pcm_channel_area_t *areas;
snd_pcm_uframes_t off;
snd_pcm_uframes_t frames = buf_size / frame_size;
snd_pcm_mmap_begin(pcm, &areas, &off, &frames);
...
snd_pcm_mmap_commit(pcm, off, frames);
}当我们获得 0 个可用帧时,这意味着缓冲区是空的。如有必要,启动录制流,然后等待更多数据。我使用 100 毫秒的间隔,但实际上它应该使用实际缓冲区大小来计算。
if (frames == 0) {
int period_ms = 100;
usleep(period_ms*1000);
continue;
}在我们获得一些数据后,我们获得指向实际交错数据和此区域中可用字节数的指针:
const void *data = (char*)areas[0].addr + off * areas[0].step/8;
int n = frames * frame_size;ALSA:播放音频
写入音频与读取音频的过程几乎相同。我们首先通过 snd_pcm_mmap_begin() 获取缓冲区,然后将数据复制到该缓冲区中,接着使用 snd_pcm_mmap_commit() 将其标记为处理完成。当缓冲区已满时,我们会收到指示,表明没有可用的空闲帧。在这种情况下,我们会首次启动播放流,并随后开始等待,直到缓冲区中再次出现一些可用空间。
if (frames == 0) {
if (SND_PCM_STATE_RUNNING != snd_pcm_state(pcm))
snd_pcm_start(pcm);
int period_ms = 100;
usleep(period_ms*1000);
continue;
}ALSA:引流
要耗尽播放缓冲区,我们不需要做任何特殊的事情。首先,我们检查 buffer 中是否还有一些数据,如果有,请等待 buffer 完全清空。
for (;;) {
if (0 >= snd_pcm_avail_update(pcm))
break;
if (SND_PCM_STATE_RUNNING != snd_pcm_state(pcm))
snd_pcm_start(pcm);
int period_ms = 100;
usleep(period_ms*1000);
}但是,我们为何总是需要检查缓冲区的状态,并在必要时调用 snd_pcm_start(),这是因为 ALSA 不会自动开始音频流的传输。我们需要在缓冲区填满后手动启动它,并且在每次遇到缓冲区溢出等错误时也需要重新启动。此外,即使我们没有完全填充缓冲区,有时也需要启动它。
ALSA:错误检查
在使用 ALSA 时,大多数函数都会返回一个整数结果代码。成功时返回 0,失败时则返回非零的错误代码。为了将这些错误代码转换为用户友好的错误消息,我们可以使用 snd_strerror() 函数。同时,我还建议记录返回错误的函数名称,这样用户就能获得关于具体错误的完整信息。
然而,处理错误还远远不够。在正常播放或录制音频的过程中,我们还需应对缓冲区溢出或欠载的情况。那么,该如何处理呢?首先,我们需要检查错误代码是否为 -EPIPE。如果是,那么就需要调用 snd_pcm_prepare() 来重置缓冲区。如果重置失败,那么我们就无法继续正常操作,这是一个致命错误。但如果重置成功,我们就可以像没有发生缓冲区溢出一样继续正常操作。
if (err == -EPIPE)
assert(0 == snd_pcm_prepare(pcm));我们需要特殊错误处理的下一个情况是在我们调用 function 之后。问题是,即使它返回了一些数据而不是错误代码,我们仍然需要检查是否所有数据都被处理了。如果没有,我们自己设置错误代码,然后我们可以用上面显示的相同代码来处理它。
err = snd_pcm_mmap_commit(pcm, off, frames);
if (err >= 0 && (snd_pcm_uframes_t)err != frames)
err = -EPIPE;接下来,这些函数可能会返回错误代码,这意味着由于某种原因,我们当前使用的设备已暂时停止或暂停。如果发生这种情况,我们应该等到设备再次上线,定期检查状态。然后我们调用以重置缓冲区并照常继续。
if (err == -ESTRPIPE) {
while (-EAGAIN == snd_pcm_resume(pcm)) {
int period_ms = 100;
usleep(period_ms*1000);
}
snd_pcm_prepare(pcm);
}不要忘记,在处理完这些错误之后,我们需要调用 start 缓冲区。对于录制流,我们会立即执行此操作,对于播放流,我们会在缓冲区已满时执行此操作。
Linux 和 PulseAudio
PulseAudio 工作在 ALSA 之上,它并不能替代 ALSA,而只是作为一个音频层,提供了一些在图形多应用程序环境中非常有用的功能,比如混音、转换、重新路由以及播放音频通知。因此,与 ALSA 不同,PulseAudio 能够允许多个应用程序共享单个音频设备——我认为这是它最为有用的特性。
请注意,在 Fedora 上,PulseAudio 不再是默认的音频层,它被 PipeWire 和另一个音频 API 所取代(尽管 PulseAudio 应用程序将继续通过 PipeWire-PulseAudio 层工作)。但是,在 PipeWire 不是其他流行的 Linux 发行版的默认选择之前,PulseAudio 总体上更有用。
首先,我们需要安装 Fedora 的开发包。现在,我们可以将其包含在我们的代码中:libpulse-devel。
#include <pulse/pulseaudio.h>当链接我们的二进制文件时,我们添加了 flag。-lpulse
关于 PulseAudio 与其他产品的不同之处。PulseAudio 采用客户端-服务器设计,这意味着我们不直接在音频设备上操作,而只是向 PulseAudio 服务器发出命令并从中接收响应。因此,我们总是从连接到 PulseAudio 服务器开始。我们必须实现一些复杂的逻辑来做到这一点,因为我们和服务器之间的交互是异步的:我们必须向服务器发送命令,然后等待它处理我们的命令并接收结果,所有这些都通过套接字 (UNIX) 连接完成。当然,这种通信需要一些时间,我们可以在等待服务器响应的同时做一些其他事情。但是,对于这里的示例代码,我们不会那么复杂:我们只会同步等待响应,这样更容易理解。
我们首先创建一个单独的线程,它将为我们处理套接字 I/O 操作。不要忘记在完成 PulseAudio 后停止此线程并关闭其处理程序。
pa_threaded_mainloop *mloop = pa_threaded_mainloop_new();
pa_threaded_mainloop_start(mloop);
...
pa_threaded_mainloop_stop(mloop);
pa_threaded_mainloop_free(mloop);使用 PulseAudio 时首先要记住的是,我们必须在持有此 I/O 线程的内部锁的同时执行所有操作。“锁定线程”,对 PA 对象执行必要的调用,然后“解锁线程”。未能正确锁定线程可能随时导致争用条件。此锁是递归的,这意味着从同一线程多次锁定它是安全的。只需调用 unlocking 函数相同次数即可。但是,我看不出锁递归在现实生活中有什么用处。递归锁通常意味着我们的架构很糟糕,它们可能会导致难以发现的问题 – 我从不建议使用此功能。
pa_threaded_mainloop_lock(mloop);
...
pa_threaded_mainloop_unlock(mloop);现在开始连接到PA服务器。请注意,即便连接尚未建立,function通常会立即返回。我们稍后会在设置的回调函数中接收到连接的结果。完成后,别忘了断开与服务器的连接。pa_context_connect() pa_context_set_state_callback()
pa_mainloop_api *mlapi = pa_threaded_mainloop_get_api(mloop);
pa_context *ctx = pa_context_new_with_proplist(mlapi, "My App", NULL);
void *udata = NULL;
pa_context_set_state_callback(ctx, on_state_change, udata);
pa_context_connect(ctx, NULL, 0, NULL);
...
pa_context_disconnect(ctx);
pa_context_unref(ctx);在我们发出 connection 命令后,除了等待结果之外,我们别无他法。我们询问连接状态,如果它还没有准备好,我们调用 which 阻塞我们的线程,直到收到信号。
while (PA_CONTEXT_READY != pa_context_get_state(ctx)) {
pa_threaded_mainloop_wait(mloop);
}下面是我们的 on-state-change 回调函数的样子,它并不复杂:我们只是向我们的线程发出信号,让它从我们当前挂起的位置退出。请注意,此函数并非由我们自己的线程(它仍处于挂起状态)调用,而是由之前启动的 I/O 线程调用。作为一般原则,请尽量保持这些回调函数中的代码简短。你的函数被调用时,接收结果并向你的线程发送一个信号,这样通常就足够了。至于 pa_threaded_mainloop_wait() 和 pa_threaded_mainloop_start(),它们在这段描述中并未直接涉及。
void on_state_change(pa_context *c, void *userdata)
{
pa_threaded_mainloop_signal(mloop, 0);
}我希望这个调用堆栈图能让您更清楚地了解 PA 服务器连接逻辑:
[Our Thread]
|- pa_threaded_mainloop_start()
| [PA I/O Thread]
|- pa_context_connect() |
|- pa_threaded_mainloop_wait() |
| |- on_state_change()
| |- pa_threaded_mainloop_signal()
[pa_threaded_mainloop_wait() returns]相同的逻辑适用于使用我们的回调函数处理所有操作结果。
PulseAudio:枚举设备
建立与 PA 服务器的连接后,我们继续列出可用设备。我们使用回调函数创建一个新操作。我们也可以传递一些指向回调函数的指针,但我只使用 value。操作完成后,不要忘记释放指针。当然,这段代码应该只在持有 mainloop 线程锁时执行。
pa_operation *op;
void *udata = NULL;
if (playback)
op = pa_context_get_sink_info_list(ctx, on_dev_sink, udata);
else
op = pa_context_get_source_info_list(ctx, on_dev_source, udata);
...
pa_operation_unref(op);现在等待操作完成。
for (;;) {
int r = pa_operation_get_state(op);
if (r == PA_OPERATION_DONE || r == PA_OPERATION_CANCELLED)
break;
pa_threaded_mainloop_wait(mloop);
}当我们这样做时,I/O 线程正在从服务器接收数据,并对我们的回调函数执行几次成功的调用,我们可以在其中访问每个可用设备的所有属性。当发生错误或没有更多设备时,parameter 将设置为非零值。发生这种情况时,我们只需将信号发送到我们的线程。列出播放设备的函数如下所示:
void on_dev_sink(pa_context *c, const pa_sink_info *info, int eol, void *udata)
{
if (eol != 0) {
pa_threaded_mainloop_signal(mloop, 0);
return;
}
const char *device_id = info->name;
}列出录制设备的函数看起来类似:
void on_dev_source(pa_context *c, const pa_source_info *info, int eol, void *udata)PulseAudio: Opening Audio Buffer
我们创建一个新的音频缓冲区,并将我们的连接上下文传递给它、我们的应用程序的名称和我们想要使用的声音格式。
pa_sample_spec spec;
spec.format = PA_SAMPLE_S16LE;
spec.rate = 48000;
spec.channels = 2;
pa_stream *stm = pa_stream_new(ctx, "My App", &spec, NULL);
...
pa_stream_unref(stm);接下来,我们将缓冲区附加到设备。我们将缓冲区长度设置为特定字节数,并将所有其他参数保留为默认值(即将它们设置为-1)。同时,我们分配了一个callback函数,该函数会在每次音频I/O完成时被调用。我们可以使用在枚举设备时获得的device_id值,或者将device_id设置为NULL以使用默认设备。相关的函数调用包括pa_stream_connect_(),设置pa_buffer_attr::t.length,以及pa_stream_set__callback()。
pa_buffer_attr attr;
memset(&attr, 0xff, sizeof(attr));
int buffer_length_msec = 500;
attr.tlength = spec.rate * 16/8 * spec.channels * buffer_length_msec / 1000;对于录制流,我们执行以下操作:
void *udata = NULL;
pa_stream_set_read_callback(stm, on_io_complete, udata);
const char *device_id = ...;
pa_stream_connect_record(stm, device_id, &attr, 0);
...
pa_stream_disconnect(stm);对于播放流:
void *udata = NULL;
pa_stream_set_write_callback(stm, on_io_complete, udata);
const char *device_id = ...;
pa_stream_connect_playback(stm, device_id, &attr, 0, NULL, NULL);
...
pa_stream_disconnect(stm);像往常一样,我们必须等到操作完成。我们使用(某种方法)来读取缓冲区的当前状态:如果状态是 PA_STREAM_READY,则表示录制已成功开始,我们可以继续正常操作;如果状态是 PA_STREAM_FAILED,则表示发生了错误。
for (;;) {
int r = pa_stream_get_state(stm);
if (r == PA_STREAM_READY)
break;
else if (r == PA_STREAM_FAILED)
error
pa_threaded_mainloop_wait(mloop);
}当我们挂起时,回调函数将在 I/O 线程内的某个时间点被调用。现在我们只需向主线程发送一个信号。
void on_io_complete(pa_stream *s, size_t nbytes, void *udata)
{
pa_threaded_mainloop_signal(mloop, 0);
}PulseAudio:录制音频
我们使用 PulseAudio 获取包含音频样本的数据区域,处理完后,丢弃此数据。
for (;;) {
const void *data;
size_t n;
pa_stream_peek(stm, &data, &n);
if (n == 0) {
// Buffer is empty. Process more events
pa_threaded_mainloop_wait(mloop);
continue;
} else if (data == NULL && n != 0) {
// Buffer overrun occurred
} else {
...
}
pa_stream_drop(stm);
}pa_stream_peek() 函数在缓冲区为空时会返回 0 个样本。在这种情况下,我们无需调用它,而是应该等待更多数据到达。当缓冲区溢出发生时,这只是给我们的一个通知,我们可以通过再次调用 pa_stream_peek()来继续处理。不过,需要注意的是,连续调用 pa_stream_drop() 和 pa_stream_peek() 并不是处理溢出的标准或推荐方式,如果缓冲区溢出,可能需要更复杂的逻辑来处理数据流,例如调整读取速率或请求更少的数据。
PulseAudio:播放音频
当我们将数据写入音频设备时,我们首先必须用 获取音频缓冲区中的可用空间量。当缓冲区已满时,它返回 0,我们必须等到有可用空间后再试一次。
size_t n = pa_stream_writable_size(stm);
if (n == 0) {
pa_threaded_mainloop_wait(mloop);
continue;
}我们得到缓冲区,我们可以在其中复制音频样本。填满缓冲区后,我们调用 to release this memory region.
void *buf;
pa_stream_begin_write(stm, &buf, &n);
...
pa_stream_write(stm, buf, n, NULL, 0, PA_SEEK_RELATIVE);PulseAudio:耗尽
为了耗尽缓冲区,我们创建一个 drain 操作,并将我们的回调函数传递给它,该函数将在 draining 完成时调用。
void *udata = NULL;
pa_operation *op = pa_stream_drain(stm, on_op_complete, udata);
...
pa_operation_unref(op);现在等待我们的回调函数向我们发出信号。
for (;;) {
int r = pa_operation_get_state(op);
if (r == PA_OPERATION_DONE || r == PA_OPERATION_CANCELLED)
break;
pa_threaded_mainloop_wait(mloop);
}我们的回调函数如下所示:
void on_op_complete(pa_stream *s, int success, void *udata)
{
pa_threaded_mainloop_signal(mloop, 0);
}Windows 和 WASAPI
WASAPI 是从 Windows Vista 开始的默认声音子系统。它是 DirectSound API 的后继者,我们在这里不讨论,由于我怀疑您可能不希望支持旧的 Windows XP 系统,因此在这里我们不对 DirectSound API 进行讨论。但如果您确实需要支持 Windows XP,请自行查阅 ffaudio 中的相关代码。WASAPI 可以在 2 种不同的模式下工作:共享模式和独占模式。在共享模式下,多个应用程序可以使用同一物理设备,这是适合通常播放/录制应用程序的模式。在独占模式下,我们可以独占访问音频设备,这适用于专业的实时声音应用程序。
请注意,在使用 WASAPI 的 include 指令之前,必须确保有预处理器定义 COBJMACROS,以确保纯 C 定义能够正常工作。
#define COBJMACROS
#include <mmdeviceapi.h>
#include <audioclient.h>在执行任何其他操作之前,我们必须初始化 COM 接口子系统。
CoInitializeEx(NULL, 0);我们必须使用链接器标志链接所有 WASAPI 应用程序。
大多数 WASAPI 函数在成功时返回 0,在失败时返回非零。
WASAPI:枚举设备
我们使用 CoCreateInstance()创建设备枚举器对象。完成后,请不要忘记发布它。
IMMDeviceEnumerator *enu;
const GUID _CLSID_MMDeviceEnumerator = {0xbcde0395, 0xe52f, 0x467c, {0x8e,0x3d, 0xc4,0x57,0x92,0x91,0x69,0x2e}};
const GUID _IID_IMMDeviceEnumerator = {0xa95664d2, 0x9614, 0x4f35, {0xa7,0x46, 0xde,0x8d,0xb6,0x36,0x17,0xe6}};
CoCreateInstance(&_CLSID_MMDeviceEnumerator, NULL, CLSCTX_ALL, &_IID_IMMDeviceEnumerator, (void**)&enu);
...
IMMDeviceEnumerator_Release(enu);我们使用这个设备枚举器对象来获取可用设备的数组。
IMMDeviceCollection *dcoll;
int mode = (playback) ? eRender : eCapture;
IMMDeviceEnumerator_EnumAudioEndpoints(enu, mode, DEVICE_STATE_ACTIVE, &dcoll);
...
IMMDeviceCollection_Release(dcoll);通过要求返回指定数组索引的设备处理程序来枚举设备。
for (int i = 0; ; i++) {
IMMDevice *dev;
if (0 != IMMDeviceCollection_Item(dcoll, i, &dev))
break;
...
IMMDevice_Release(dev);
}然后,获取此设备的属性集。
IPropertyStore *props;
IMMDevice_OpenPropertyStore(dev, STGM_READ, &props);
...
IPropertyStore_Release(props);使用 读取单个属性值。下面介绍如何获取设备的用户友好名称。
PROPVARIANT name;
PropVariantInit(&name);
const PROPERTYKEY _PKEY_Device_FriendlyName = {{0xa45c254e, 0xdf1c, 0x4efd, {0x80, 0x20, 0x67, 0xd1, 0x46, 0xa8, 0x50, 0xe0}}, 14};
IPropertyStore_GetValue(props, &_PKEY_Device_FriendlyName, &name);
const wchar_t *device_name = name.pwszVal;
...
PropVariantClear(&name);现在我们需要列出设备的主要原因是:我们使用 IMMDevice_GetId().
wchar_t *device_id = NULL;
IMMDevice_GetId(dev, &device_id);
...
CoTaskMemFree(device_id);要获取系统默认设备,我们使用 IMMDeviceEnumerator_GetDefaultAudioEndpoint() 方法。之后,我们可以采用与上述步骤完全相同的方式来获取该设备的 ID 和 name。
IMMDevice *def_dev = NULL;
IMMDeviceEnumerator_GetDefaultAudioEndpoint(enu, mode, eConsole, &def_dev);
IMMDevice_Release(def_dev);WASAPI:在共享模式下打开音频缓冲区
这是在共享模式下打开音频缓冲区的最简单方法。我们再次从创建一个设备枚举器对象开始。
IMMDeviceEnumerator *enu;
const GUID _CLSID_MMDeviceEnumerator = {0xbcde0395, 0xe52f, 0x467c, {0x8e,0x3d, 0xc4,0x57,0x92,0x91,0x69,0x2e}};
const GUID _IID_IMMDeviceEnumerator = {0xa95664d2, 0x9614, 0x4f35, {0xa7,0x46, 0xde,0x8d,0xb6,0x36,0x17,0xe6}};
CoCreateInstance(&_CLSID_MMDeviceEnumerator, NULL, CLSCTX_ALL, &_IID_IMMDeviceEnumerator, (void**)&enu);
...
IMMDeviceEnumerator_Release(enu);现在,我们要么使用默认捕获设备,要么已经知道特定的设备 ID。无论哪种情况,我们都会得到设备描述符。
IMMDevice *dev;
wchar_t *device_id = NULL;
if (device_id == NULL) {
int mode = (playback) ? eRender : eCapture;
IMMDeviceEnumerator_GetDefaultAudioEndpoint(enu, mode, eConsole, &dev);
} else {
IMMDeviceEnumerator_GetDevice(enu, device_id, &dev);
}
...
IMMDevice_Release(dev);我们创建一个音频捕获缓冲区,并向其传递 identificator。
IAudioClient *client;
const GUID _IID_IAudioClient = {0x1cb9ad4c, 0xdbfa, 0x4c32, {0xb1,0x78, 0xc2,0xf5,0x68,0xa7,0x03,0xb2}};
IMMDevice_Activate(dev, &_IID_IAudioClient, CLSCTX_ALL, NULL, (void**)&client);
...
IAudioClient_Release(client);由于我们希望在共享模式下打开 WASAPI 音频缓冲区,因此无法使其使用所需的音频格式。音频格式是系统级配置的主题,我们只需要遵守它。这种格式很可能是 16bit/44100/立体声或 24bit/44100/立体声,但我们无法确切知道。值得注意的是,尽管 WASAPI 有时能够接受与我们提供的样本不同的格式(例如,我们提供 float32 格式,而 WASAPI 自动将其转换为 16 位),但我们不能依赖这种自动转换行为。要获得正确的音频格式,最可靠的方法是调用相关函数让它为我们创建一个 WAVE 格式标头,这种标头格式与 .wav 文件中使用的相同。此外,请注意,在 Windows 中,音频格式有两种不同的设置,这取决于我们的缓冲区是分配给哪个设备的。要获取混合格式,可以使用 IAudioClient_GetMixFormat() 方法。
WAVEFORMATEX *wf;
IAudioClient_GetMixFormat(client, &wf);
...
CoTaskMemFree(wf);现在我们只需使用这种音频格式来设置我们的缓冲区。请注意,我们在这里使用 flag,这意味着我们想要在共享模式下配置缓冲区。缓冲区长度参数必须以 100 纳秒为间隔。请记住,这只是一个提示,在函数成功返回后,我们应该始终获取 WASAPI 选择的实际缓冲区长度。
int buffer_length_msec = 500;
REFERENCE_TIME dur = buffer_length_msec * 1000 * 10;
int mode = AUDCLNT_SHAREMODE_SHARED;
int aflags = 0;
IAudioClient_Initialize(client, mode, aflags, dur, dur, (void*)wf, NULL);
u_int buf_frames;
IAudioClient_GetBufferSize(client, &buf_frames);
buffer_length_msec = buf_frames * 1000 / wf->nSamplesPerSec;WASAPI:在共享模式下录制音频
我们初始化了缓冲区,但它没有为我们提供可用于执行 I/O 的接口。在我们的记录流中,我们必须从中获取接口对象。
IAudioCaptureClient *capt;
const GUID _IID_IAudioCaptureClient = {0xc8adbd64, 0xe71e, 0x48a0, {0xa4,0xde, 0x18,0x5c,0x39,0x5c,0xd3,0x17}};
IAudioClient_GetService(client, &_IID_IAudioCaptureClient, (void**)&capt);准备工作已完成,我们已准备好开始录制。
IAudioClient_Start(client);为了获取一段录制的音频数据,我们调用 IAudioCaptureClient_GetBuffer() 方法。当缓冲区内没有未读数据时,该方法会返回 AUDCLNT_S_BUFFER_EMPTY 错误。在这种情况下,我们只需等待一段时间,然后再尝试调用一次。处理完音频样本后,我们使用 IAudioCaptureClient_ReleaseBuffer() 方法来释放缓冲区。
for (;;) {
u_char *data;
u_int nframes;
u_long flags;
int r = IAudioCaptureClient_GetBuffer(capt, &data, &nframes, &flags, NULL, NULL);
if (r == AUDCLNT_S_BUFFER_EMPTY) {
// Buffer is empty. Wait for more data.
int period_ms = 100;
Sleep(period_ms);
continue;
} else (r != 0) {
// error
}
...
IAudioCaptureClient_ReleaseBuffer(capt, nframes);
}WASAPI:在共享模式下播放音频
播放音频与录音非常相似,但我们需要使用另一个接口进行 I/O。这次我们传入 identificator 并获取接口对象。
IAudioRenderClient *render;
const GUID _IID_IAudioRenderClient = {0xf294acfc, 0x3146, 0x4483, {0xa7,0xbf, 0xad,0xdc,0xa7,0xc2,0x60,0xe2}};
IAudioClient_GetService(client, &_IID_IAudioRenderClient, (void**)&render);
...
IAudioRenderClient_Release(render);正常的播放操作是,一旦缓冲区中有一些空闲空间,我们就会在循环中向音频缓冲区添加更多数据。为了获得已用空间量,我们调用 。为了获得可用空间量,我们使用打开缓冲区时获得的缓冲区 () 的大小。这些数字以样本为单位,而不是以字节为单位。
u_int filled;
IAudioClient_GetCurrentPadding(client, &filled);
int n_free_frames = buf_frames - filled;当缓冲区已满时,该函数将已用空间数设置为 0。现在,我们第一次拥有完整的缓冲区必须开始播放。
if (!started) {
IAudioClient_Start(client);
started = 1;
}我们获得了 free buffer region,在用音频样本填充它之后,我们使用 IAudioRenderClient_ReleaseBuffer() 来释放并提交这个缓冲区。而在此之前,我们是通过 IAudioRenderClient_GetBuffer() 来获取这个 free buffer region 的。
u_char *data;
IAudioRenderClient_GetBuffer(render, n_free_frames, &data);
...
IAudioRenderClient_ReleaseBuffer(render, n_free_frames, 0);WASAPI:关闭
我们永远不会忘记在关闭之前耗尽音频缓冲区,否则不会播放最后一个音频数据,因为我们没有给它足够的时间。该算法与 ALSA 相同。我们得到仍需播放的样本数量,当缓冲区为空时,耗尽完成。
for (;;) {
u_int filled;
IAudioClient_GetCurrentPadding(client, &filled);
if (filled == 0)
break;
...
}如果我们的输入数据太小,甚至无法填满我们的音频缓冲区,那么此时我们仍然没有开始播放。我们这样做,否则永远不会用 “buffer empty” 条件向我们发出信号。
if (!started) {
IAudioClient_Start(client);
started = 1;
}WASAPI:错误报告
大多数 WASAPI 函数在成功时返回 0,在失败时返回错误代码。此错误代码的问题在于,有时我们无法直接将其转换为用户友好的错误消息 – 我们必须手动进行。首先,我们检查它是否是 code。在这种情况下,我们必须根据值设置自己的错误消息。例如,我们可能为每个可能的代码都有一个字符串数组。不要忘记索引越界检查!
int err = ...;
if ((err & 0xffff0000) == MAKE_HRESULT(SEVERITY_ERROR, FACILITY_AUDCLNT, 0)) {
err = err & 0xffff;
static const char audclnt_errors[][39] = {
"",
"AUDCLNT_E_NOT_INITIALIZED", // 0x1
...
"AUDCLNT_E_RESOURCES_INVALIDATED", // 0x26
};
const char *error_name = audclnt_errors[err];
}但是如果它不是代码,我们可以以通常的方式从 Windows 获取错误消息。
wchar_t buf[255];
int n = FormatMessageW(FORMAT_MESSAGE_FROM_SYSTEM | FORMAT_MESSAGE_IGNORE_INSERTS | FORMAT_MESSAGE_MAX_WIDTH_MASK
, 0, err, 0, buf, sizeof(buf)/sizeof(*buf), 0);
if (n == 0)
buf[0] = '\0';存储返回错误的函数的名称始终是一种很好的做法。用户必须知道到底哪个函数失败了,它返回了哪个代码以及错误描述。
FreeBSD 和 OSS
OSS 是 FreeBSD 和其他一些操作系统上的默认音频子系统。在 ALSA(高级 Linux 声音架构)取代它之前,OSS 也曾是 Linux 上的默认音频子系统。尽管一些文档指出,现代 Linux 仍然支持 OSS 层,但普遍认为它对于新软件的开发已不再具有主要作用。与其他音频 API 相比,OSS API 显得尤为简单,因为它仅使用标准的系统调用。OSS 的 I/O 操作与常规文件的 I/O 操作类似,这使得 OSS 极易理解和使用。
包括必要的头文件:
#include <sys/soundcard.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>OSS:枚举设备
打开系统混音器设备的方式与我们打开常规文件的方式完全相同。
int mixer = open("/dev/mixer", O_RDONLY, 0);
...
close(mixer);我们通过以下方式发出命令与此设备通信。获取具有设备控制代码的已注册设备的数量。
oss_sysinfo si = {};
ioctl(mixer, SNDCTL_SYSINFO, &si);
int n_devs = si.numaudios;我们使用SNDCTL_AUDIOINFO_EX 获取每个设备的属性。
for (int i = 0; i != n_devs; i++) {
oss_audioinfo ainfo = {};
ainfo.dev = i;
ioctl(mixer, SNDCTL_AUDIOINFO_EX, &ainfo);
...
}因为我们遍历所有设备(包括播放设备和录制设备),所以我们必须使用特定的字段来过滤出我们所需的内容:PCM_CAP_OUTPUT 表示这是一个播放设备,而 PCM_CAP_INPUT 则意味着这是一个录制设备。我们从同一个对象中获取其他必要的信息,其中最重要的是设备 ID。相关的结构体或类是 oss_audioinfo。
int is_playback_device = !!(ainfo.caps & PCM_CAP_OUTPUT);
int is_capture_device = !!(ainfo.caps & PCM_CAP_INPUT);
const char *device_id = ainfo.devnode;
const char *device_name = ainfo.name;OSS:打开音频缓冲区
我们使用 open() 函数打开音频设备并获取设备描述符。如果要使用默认设备,我们传递相应的设备路径。我们需要将正确的标志传递给 open() 函数:O_WRONLY 用于播放,O_RDONLY 用于录制(因为我们将从设备中读取数据)。此外,我们还可以在这里使用 O_NONBLOCK 标志,这使得我们的描述符是非阻塞的,即读/写函数不会阻塞,而是会立即返回一个错误(通常会设置 errno 为 EAGAIN 来表示资源暂时不可用)。
const char *device_id = NULL;
if (device_id == NULL)
device_id = "/dev/dsp";
int flags = (playback) ? O_WRONLY : O_RDONLY;
int dsp = open(device_id, flags | O_EXCL, 0);
...
close(dsp);让我们为要使用的音频格式配置设备。我们将要使用的值传递给 ioctl(),并在返回时使用设备驱动程序设置的实际值对其进行更新。当然,这个值可以与我们传递的值不同。在实际代码中,我们必须检测此类情况,并通知用户格式更改或退出并出现错误。
int format = AFMT_S16_LE;
ioctl(dsp, SNDCTL_DSP_SETFMT, &format);
int channels = 2;
ioctl(dsp, SNDCTL_DSP_CHANNELS, &channels);
int sample_rate = 44100;
ioctl(dsp, SNDCTL_DSP_SPEED, &sample_rate);要设置音频缓冲区长度,我们首先获取设备的 “fragment size” 属性。然后,我们使用此值将缓冲区长度转换为片段数。片段不是音频帧,片段大小不是样本的大小!然后我们使用控制代码设置 fragment 的数量。请注意,如果我们不想设置自己的缓冲区长度并使用默认缓冲区长度,则可以跳过本节。
audio_buf_info info = {};
if (playback)
ioctl(dsp, SNDCTL_DSP_GETOSPACE, &info);
else
ioctl(dsp, SNDCTL_DSP_GETISPACE, &info);
int buffer_length_msec = 500;
int frag_num = sample_rate * 16/8 * channels * buffer_length_msec / 1000 / info.fragsize;
int fr = (frag_num << 16) | (int)log2(info.fragsize); // buf_size = frag_num * 2^n
ioctl(dsp, SNDCTL_DSP_SETFRAGMENT, &fr);我们已经完成了设备的准备工作。现在我们获得用于播放或录制流的实际缓冲区长度。
audio_buf_info info = {};
int r;
if (playback)
r = ioctl(dsp, SNDCTL_DSP_GETOSPACE, &info);
else
r = ioctl(dsp, SNDCTL_DSP_GETISPACE, &info);
buffer_length_msec = info.fragstotal * info.fragsize * 1000 / (sample_rate * 16/8 * channels);
int buf_size = info.fragstotal * info.fragsize;
frame_size = 16/8 * sample_rate * channels;最后,我们分配所需大小的缓冲区。
void *buf = malloc(buf_size);
...
free(buf);OSS:录制音频
没有什么比使用 OSS 进行音频 I/O 更容易的了。我们使用通常的函数将我们的音频缓冲区和其中的最大可用字节数传递给它。它返回读取的字节数。该函数还会在缓冲区为空时阻止执行,因此无需为我们调用 sleep 函数。
int n = read(dsp, buf, buf_size);OSS:播放音频
对于播放流,我们首先将音频样本写入缓冲区,然后使用write() .它返回实际写入的字节数。这些函数在缓冲区已满时阻止执行。
int n = write(dsp, buf, n);OSS:排空
为了耗尽并同步缓冲区,我们仅使用 SNDCTL_DSP_SYNC 控制代码。它会阻塞进程,直到播放操作完成。
ioctl(dsp, SNDCTL_DSP_SYNC, 0);OSS:错误报告
失败时,open()、ioctl()、read() 或 write() 会返回负值,并设置 errno。我们可以像往常一样使用 strerror() 将 errno 转换为错误消息。
int err = ...;
const char *error_message = strerror(err);macOS 和 CoreAudio
CoreAudio 是 macOS 和 iOS 上的默认声音子系统。我对此没有什么经验,因为我不喜欢 Apple 的产品。我只是向您展示它对我的工作方式,但理论上可能有比我更好的解决方案。必要的包括:
#include <CoreAudio/CoreAudio.h>
#include <CoreFoundation/CFString.h>链接时,我们传递链接器标志。
CoreAudio:枚举设备
我们首先需要知道要为数组分配的最小字节数,为此我们使用 AudioObjectGetPropertyDataSize() 来获得所需的大小。然后,我们可以用这个信息来分配适当的数组,并使用 AudioObjectGetPropertyData() 来填充该数组。
const AudioObjectPropertyAddress prop_dev_list = { kAudioHardwarePropertyDevices, kAudioObjectPropertyScopeGlobal, kAudioObjectPropertyElementMaster };
u_int size;
AudioObjectGetPropertyDataSize(kAudioObjectSystemObject, &prop_dev_list, 0, NULL, &size);
AudioObjectID *devs = (AudioObjectID*)malloc(size);
AudioObjectGetPropertyData(kAudioObjectSystemObject, &prop_dev_list, 0, NULL, &size, devs);
int n_dev = size / sizeof(AudioObjectID);
...
free(devs);然后我们遍历数组以获取设备 ID。
for (int i = 0; i != n_dev; i++) {
AudioObjectID device_id = devs[i];
...
}对于每个设备,我们可以获得一个用户友好的名称,但我们必须使用 CFStringGetCString().
const AudioObjectPropertyAddress prop_dev_outname = { kAudioObjectPropertyName, kAudioDevicePropertyScopeOutput, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress prop_dev_inname = { kAudioObjectPropertyName, kAudioDevicePropertyScopeInput, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress *prop = (playback) ? &prop_dev_outname : &prop_dev_inname;
u_int size = sizeof(CFStringRef);
CFStringRef cfs;
AudioObjectGetPropertyData(devs[i], prop, 0, NULL, &size, &cfs);
CFIndex len = CFStringGetMaximumSizeForEncoding(CFStringGetLength(cfs), kCFStringEncodingUTF8);
char *device_name = malloc(len + 1);
CFStringGetCString(cfs, device_name, len + 1, kCFStringEncodingUTF8);
CFRelease(cfs);
...
free(device_name);CoreAudio:打开音频缓冲区
如果我们想使用默认设备,以下是获取其 ID 的方法。
AudioObjectID device_id;
const AudioObjectPropertyAddress prop_odev_default = { kAudioHardwarePropertyDefaultOutputDevice, kAudioObjectPropertyScopeGlobal, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress prop_idev_default = { kAudioHardwarePropertyDefaultInputDevice, kAudioObjectPropertyScopeGlobal, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress *a = (playback) ? &prop_odev_default : &prop_idev_default;
u_int size = sizeof(AudioObjectID);
AudioObjectGetPropertyData(kAudioObjectSystemObject, a, 0, NULL, &size, &device_id);获取支持的音频格式。似乎 CoreAudio 默认使用 float32 样本。
const AudioObjectPropertyAddress prop_odev_fmt = { kAudioDevicePropertyStreamFormat, kAudioDevicePropertyScopeOutput, kAudioObjectPropertyElementMaster };
const AudioObjectPropertyAddress prop_idev_fmt = { kAudioDevicePropertyStreamFormat, kAudioDevicePropertyScopeInput, kAudioObjectPropertyElementMaster };
AudioStreamBasicDescription asbd = {};
u_int size = sizeof(asbd);
const AudioObjectPropertyAddress *a = (playback) ? &prop_odev_fmt : &prop_idev_fmt;
AudioObjectGetPropertyData(device_id, a, 0, NULL, &size, &asbd);
int sample_rate = asbd.mSampleRate;
int channels = asbd.mChannelsPerFrame;创建音频长度为 500 毫秒的缓冲区。请注意,我们在这里使用自己的 ring buffer 在回调函数和 I/O 循环之间传输数据。
int buffer_length_msec = 500;
int buf_size = 32/8 * sample_rate * channels * buffer_length_msec / 1000;
ring_buf = ringbuf_alloc(buf_size);
...
ringbuf_free(ring_buf);注册 I/O 回调函数,当 CoreAudio 有更多数据需要我们(用于录制)或当它想要从我们那里读取一些数据(用于播放)时,它将调用该函数。我们可以将 ring buffer 作为用户参数传递。返回值是一个指针,我们稍后使用它来控制流。
AudioDeviceIOProcID io_proc_id = NULL;
void *udata = ring_buf;
AudioDeviceCreateIOProcID(device_id, proc, udata, &io_proc_id);
...
AudioDeviceDestroyIOProcID(device_id, io_proc_id);回调函数如下所示:
OSStatus io_callback(AudioDeviceID device, const AudioTimeStamp *now,
const AudioBufferList *indata, const AudioTimeStamp *intime,
AudioBufferList *outdata, const AudioTimeStamp *outtime,
void *udata)
{
...
return 0;
}CoreAudio:录制音频
我们从 AudioDeviceStart()开始录制。
AudioDeviceStart(device_id, io_proc_id);然后,一段时间后,我们的回调函数被调用。在内部,我们必须将所有音频样本添加到我们的 ring 缓冲区中。
const float *d = indata->mBuffers[0].mData;
size_t n = indata->mBuffers[0].mDataByteSize;
ringbuf *ring = udata;
ringbuf_write(ring, d, n);
return 0;在我们的 I/O 循环中,我们尝试从缓冲区读取一些数据。如果缓冲区为空,则等待,然后重试。我在这里的 ring buffer 实现允许我们直接使用 buffer。我们获取缓冲区,对其进行处理,然后释放它。
ringbuffer_chunk buf;
size_t h = ringbuf_read_begin(ring_buf, -1, &, NULL);
if (.len == 0) {
// Buffer is empty. Wait until some new data is available
int period_ms = 100;
usleep(period_ms*1000);
continue;
}
...
ringbuf_read_finish(ring_buf, h);CoreAudio:播放音频
在回调函数中,我们将音频样本从环形缓冲区写入 CoreAudio 的缓冲区。请注意,我们从缓冲区中读取 2 次,因为一旦我们到达环形缓冲区中内存区域的末尾,我们就必须从头开始。如果缓冲区中没有足够的数据,我们会传递 silence (数据区域填充为零),以便在播放这些数据时不会听到意外。
float *d = outdata->mBuffers[0].mData;
size_t n = outdata->mBuffers[0].mDataByteSize;
ringbuf *ring = udata;
ringbuffer_chunk buf;
size_t h = ringbuf_read_begin(ring, n, &buf, NULL);
memcpy(buf.ptr, d, buf.len);
ringbuf_read_finish(ring, h);
d = (char*)d + buf.len;
n -= buf.len;
if (n != 0) {
h = ringbuf_read_begin(ring, n, &buf, NULL);
memcpy(buf.ptr, d, buf.len);
ringbuf_read_finish(ring, h);
d = (char*)d + buf.len;
n -= buf.len;
}
if (n != 0)
memset(d, 0, n);在我们的主 I/O 循环中,我们首先获得空闲缓冲区,我们在其中写入新的音频样本。当缓冲区已满时,我们第一次启动流并等待调用我们的回调函数。
ringbuffer_chunk buf;
size_t h = ringbuf_write_begin(ring_buf, 16*1024, &buf, NULL);
if (buf.len == 0) {
if (!started) {
AudioDeviceStart(device_id, io_proc_id);
started = 1;
}
// Buffer is full. Wait.
int period_ms = 100;
usleep(period_ms*1000);
continue;
}
...
ringbuf_write_finish(ring_buf, h);CoreAudio:耗用
要耗尽缓冲区,我们只需等待环形缓冲区为空。当环形缓冲区为空时(意味着所有数据都已处理完毕),我们再进行后续操作。请注意,如果输入的数据量小于缓冲区的大小,那么我们的音频流可能还未真正启动。若遇到这种情况,我们应先调用 AudioDeviceStop() 停止音频设备,然后再根据需要调用 AudioDeviceStart() 重新启动。
size_t free_space;
ringbuffer_chunk d;
ringbuf_write_begin(ring_buf, 0, &d, &free_space);
if (free_space == ring_buf->cap) {
AudioDeviceStop(device_id, io_proc_id);
break;
}
if (!started) {
AudioDeviceStart(device_id, io_proc_id);
started = 1;
}
// Buffer isn't empty. Wait.
int period_ms = 100;
usleep(period_ms*1000);最终结果
我认为我们已经介绍了最常见的音频API及其用例,希望您能从中学到一些新的和有用的知识。然而,有几项内容并未在本教程中涵盖:
- ALSA 的 SIGIO 通知。据我所知,并非所有设备都支持此功能。
- 通过 Windows 事件发送 WASAPI 通知。这仅对实时低延迟应用程序有用。
- WASAPI 独占模式、环回模式。解释有关以独占模式打开音频缓冲区的细节会让我投入更多的时间,以至于我不确定我现在是否可以做到。并且 loopback 模式不是跨平台的。如果你愿意,你可以通过阅读官方文档或 ffaudio 的源代码来了解这些东西。