

企业工商数据API用哪种?

本文将介绍如何为UCI机器学习库引入一个简单直观的API。用户可以借此查看数据集描述,搜索感兴趣的数据集,甚至可以根据数据集大小或机器学习任务分类下载。
UCI机器学习库是机器学习领域的一个神器。对于初学者和进阶学习者来说,它就像一家商店。它将数据库、业务知识以及用于机器学习算法实证分析的数据生成器集中在一起。1987年,加州大学欧文分校的David Aha和他的学生以ftp档案的形式创建了该网站。从那时开始,全世界的学生、教育工作者和研究人员将其作为机器学习数据集的主要来源。作为文档影响的一个标志,它已被引用超过1000次,使其成为计算机科学中引用率最高的100篇“论文”之一。
附UCI链接:
http://archive.ics.uci.edu/ml/index.php

相比之下,用户要操纵门户网站费时费力,因为感兴趣的数据集没有简单直观的API或下载链接,必须跳转多个页面才能转到目标数据所在的原始页面。此外,如果你对特定类型的机器学习任务(例如回归或分类)感兴趣并且想要下载与该任务相对应的所有数据集,很难通过简单的命令实现。
我很高兴能为UCI ML网站引入一个简单直观的API,用户可以轻松查找数据集描述,搜索他们感兴趣的特定数据集,甚至可以按大小或机器学习任务分类下载数据集。
这是一个由MIT授权的Python 3.6开源代码库,它提供了函数和方法,以便用户通过交互方式使用UCI ML数据集。以下Github页面可以下载/复制/分离代码库。
附Github:
运行此代码只需要以下三个广泛使用的Python包。为了便于安装这些支持包,setup.bash和setup.bat文件包含在我的repo中。只需在Linux / Windows shell中运行即可!
首先,确保你已连接到网络!然后,只需下载/克隆Github中的repo,确保安装了以上包。
git clone https://github.com/tirthajyoti/UCI-ML-API.git
{your_local_directory}
然后转到已克隆Git的your_local_directory并在终端上运行以下命令。
python Main.py
随后将打开一个菜单,允许你执行各种任务。菜单的屏幕截图如下:
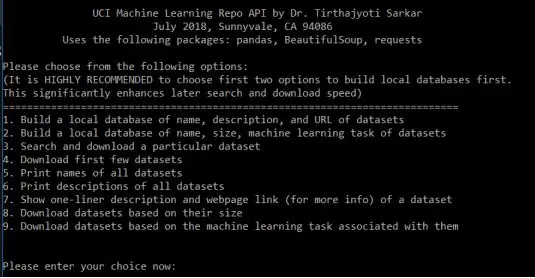
1. 抓取整个网站以构建本地数据库,其中包括数据集名称,描述和URL。
2. 抓取整个网站以构建本地数据库,其中包括数据集名称,大小和机器学习任务。
3. 搜索并下载特定数据集。
4. 下载前几个数据集。
5. 显示所有数据集的名称。
6. 显示所有数据集的简要描述。
7. 搜索数据集的单行描述和网页链接(了解更多信息)。
8. 根据数据集大小下载数据集。
9. 根据与之关联的机器学习任务下载数据集。
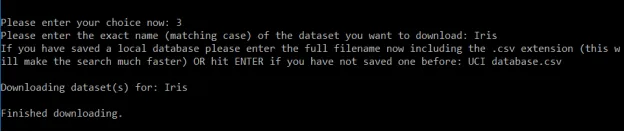
例如,如果要下载著名的Iris数据集,只需从菜单中选择选项3,输入存储的本地数据库的名称(以便搜索更迅速)。 就可以下载Iris数据集并将其存储在名为“Iris”的文件夹中!
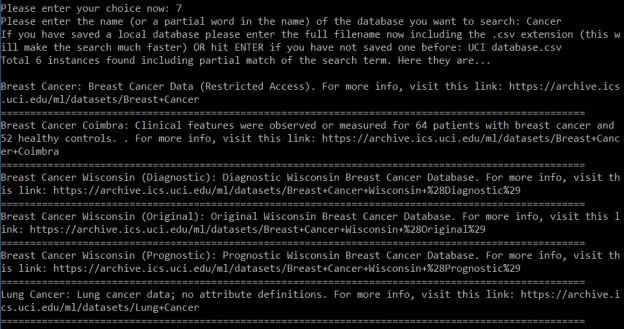
如果选择选项7,将使用关键字进行搜索,得到名称与搜索字符串匹配的所有数据集(甚至部分)的简短摘要。你还可以获得每个结果的网页链接,以便根据需要进一步探索数据。 下面的屏幕截图是使用关键词Cancer进行搜索的结果。
如果你想避开这个简单的用户API,而使用基础函数,也是可行的。
from UCI_ML_Functions import *import pandas as pd
read_dataset_table():从url读取数据集并进一步处理以便后续的数据清洗和分类。
url:
clean_dataset_table():清洗原始数据集(数据框对象(DataFrame))并返回数据。处理后的数据删除了包含空缺值的观测。并且删除了“默认任务”列,该列用来显示与数据集关联的主机学习任务。
build_local_table(filename=None, msg_flag=True):读取UCI ML网站并使用名称,大小,ML任务,数据类型等信息构建本地表。
build_dataset_list():抓取UCI ML数据集页面的信息,并构建包含所有数据集信息的列表。
build_dataset_dictionary():抓取UCI ML数据集页面的信息,并构建包含所有数据集名称和描述的字典(dictionary)。此外,还对应数据集生成了唯一标识符,下载器需要这个标识符字符串来下载数据文件。这种情况下,通用名称不起作用。
build_full_dataframe():构建一个包含所有信息的数据框(DataFrame),包括用于下载数据的URL链接。
build_local_database(filename=None, msg_flag=True):读取UCI ML网站并使用以下信息构建本地数据库:name,abstract,data page URL。
return_abstract(name,local_database=None,msg_flag=False):通过搜索给定的名称,返回特定数据集的单行描述(以及更多信息的网页链接)。
describe_all_dataset(msg_flag=False):调用build_dataset_dictionary函数并显示所有数据集的描述。
print_all_datasets_names(msg_flag=False):调用build_dataset_dictionary函数并显示所有数据集的名称。
extract_url_dataset(dataset,msg_flag=False):给定数据集标识符,此函数提取实际原始数据所在页面的URL。
download_dataset_url(url,directory,msg_flag=False,download_flag=True):从给定url中的链接下载所有文件。
download_datasets(num=10,local_database=None,msg_flag=True,download_flag=True):下载数据集并将它们放在以数据集命名的本地目录中。默认情况下,仅下载前10个数据集。用户可以选择要下载的数据集数量。
download_dataset_name(name,local_database=None,msg_flag=True,download_flag=True):根据下载指定名称的数据集。
download_datasets_size(size=’Small’,local_database=None,local_table=None,msg_flag=False,download_flag=True):下载满足’size’标准的所有数据集。
download_datasets_task(task=’Classification’,local_database=None,local_table=None,msg_flag=False,download_flag=True):下载用户想要的所有符合ML任务标准的数据集。
原文标题:
Introducing a simple and intuitive Python API for UCI machine learning repository
原文链接:
本文章转载微信公众号@数据派THU






