

Python语言调用免费查询ip地址API

想象一下,坐在异国他乡的咖啡馆里,饥肠辘辘的你正准备翻阅菜单寻找美味佳肴。然而,不幸的是,菜单上满是葡萄牙语,而你只会说英语。不过好消息是,每道菜旁边都配有图片。于是,你通过看图识别菜品,顺利完成点餐。
对于人类而言,通过实例学习是再自然不过的事情,但对于机器和软件应用来说,却并非易事。要让机器识别出至少一个物体,它必须从大量从不同角度拍摄的图片中学习该物体的特征——这是一个复杂且耗时耗力的过程。
计算机视觉(CV)的目标正是让计算机能够理解数字图像的内容。机器学习专家Jason Brownlee指出,计算机视觉通常涉及开发各种方法,试图再现人类视觉的能力。
再回到我们点餐的情境中。如果计算机要解决这一问题,它可以利用图像识别功能来实现。
图像识别(或称图像分类)是指将图像和对象进行分类,并将它们归入几个预定义的独立类别中的任务。具备图像识别能力的解决方案能够回答“这张图片描绘了什么?”的问题。例如,它可以区分手写数字的类型、人与电线杆、风景与肖像,或是猫与狗(一个常见的例子)。
图像识别是计算机视觉领域正在解决的一个问题。
计算机视觉是一系列更广泛的实践,旨在解决以下问题:
这张来自检测和分割讲座的幻灯片帮助我们了解计算机视觉任务之间的区别:
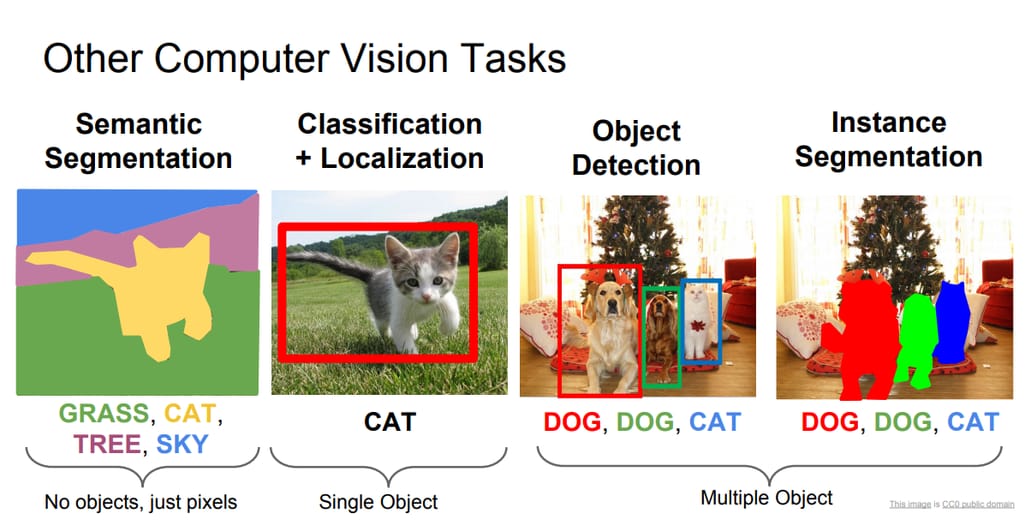
在了解基础知识后,我们来探讨一下您可以用于将视觉数据分析集成到新产品或现有产品中的现成API和解决方案
计算机视觉产品通常是客户可以通过机器学习即服务(MLaaS)平台访问的功能之一。MLaaS是基于云的平台,提供数据预处理、模型训练和评估工具,以及视觉、文本、音频、视频数据或语音分析。这些平台既适用于经验丰富的数据科学家,也适用于初学者。它们还可以与云存储解决方案集成。
提供商提供各种视觉数据处理功能,以解决特定行业的常见用例。图像分类、对象检测、视觉产品搜索、处理包含打印或手写文本的文档、医学图像分析等任务,在大多数情况下,都可以按需付费。
让我们概述其中的一些,重点关注两个主要方面:
1) 系统可识别的实体类型
2) 定价。
谷歌通过谷歌云提供REST和RPC API,推出了两款计算机视觉产品:Vision API和AutoML Vision。
Cloud Vision API 允许开发人员集成以下计算机视觉功能:对象检测、成人内容识别、光学字符识别(OCR)和图像标注(注释)。
您可以检测:
人脸和面部特征识别:可以识别面部特征(如眼睛、鼻子、嘴巴)并为面部和图像属性(如喜悦、惊讶、悲伤、愤怒)提供置信度评分。但不支持单独的人脸识别。
实体(标签)检测:可以检测和提取图像中实体的信息,涵盖广泛的类别。标签可以代表一般对象、产品、地点、动物种类、活动等。API支持英文标签,但可以使用Cloud Translation API将其翻译成其他语言。
徽标识别:识别流行产品徽标的特征。
光学字符识别(OCR):检测图像、PDF或TIFF文件中的打印和手写文本。
知名地标识别:允许检测图像中的自然和人造结构。
成人内容检测:评估内容是否属于成人、欺骗、暴力、医疗或挑逗性五个类别,并返回每个类别在图像中出现的可能性分数。
网络参考:返回图像的网络参考,如描述、实体ID、完全匹配的图像、包含匹配图像的页面、视觉上相似的图像和最佳猜测标签。
图像属性识别:识别诸如主色调等特征。
AutoML Vision是谷歌的另一款计算机视觉产品,允许用户训练机器学习模型,根据自定义标签对图像进行分类。用户可以直接从计算机上传已标注的图像。如果图像未标注但已按每个标签的文件夹分类,该工具将自动分配这些标签。用户还可以请求人工操作员为其数据集进行标注。目前,该产品处于测试阶段。
谷歌允许用户查看API如何分析他们选择的图像。
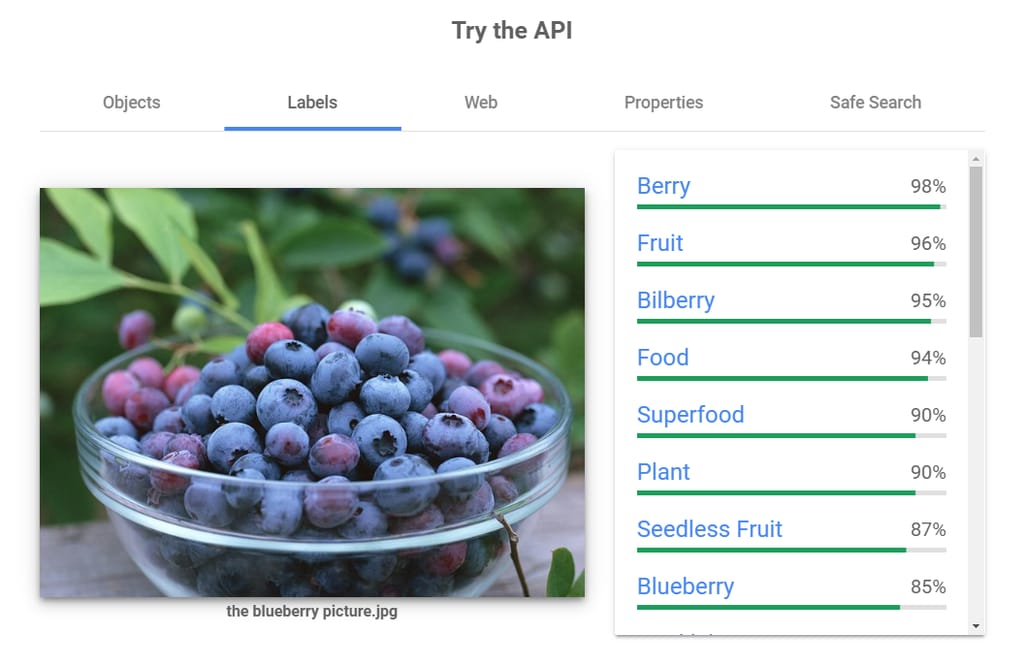
定价。 Vision API 的用户按图像计费,特别是按可计费单位计费——即每个应用于图像的功能。每月前1000个单位是免费的。从第1001个单位到5,000,000个单位,费用从1.50到3.50不等。每月5,000,001至20,000,000个单位的标签检测费用为1.00,其余功能的费用为每图像0.60。您可以查看其价格计算器以获取详细信息。
AutoML Vision 定价取决于所使用的功能。例如,使用图像分类的价格取决于所需的训练量(每小时 20 USD)、请求的人工标记量、图像数量和预测类型(在线或批量)。在线预测在 1000 张图像后计费。分析 1001—5000000 张图像的成本为每 1000 张图像 3 USD。如果您选择批量预测,则每个账户的第一个节点小时免费(一次),然后每个节点小时 2.02 USD。
Amazon Rekognition允许为应用程序嵌入图像和视频分析功能。该服务基于与Amazon Photos服务相同的图像和视频数据分析技术,用户无需具备机器学习专业知识。
通过 Recognition API 功能,您可以执行以下任务:
识别实体、对象和活动:检测标签——对象(如人、车、家具、衣物、宠物)、场景(如森林、海滩、城市街道)或概念(如户外)、活动(如踢足球、滑冰)。
识别和分析人脸:在照片或视频中检测人物,检测面部特征、表情,为检测到的面部及其属性提供置信度评分百分比,并保存面部元数据。还可以将一张图像中的人脸与另一张图像中检测到的人脸进行比较。
识别名人:在视频和图像中识别著名人物。
捕捉动作:服务允许您跟踪视频中人物的行走路径、位置,并检测其面部特征。
检测不安全内容:Amazon Rekognition 识别裸体、暗示性内容(内衣或泳装)、暴力(如物理武器)和令人不安的场景(如尸体、上吊)。
检测图像中的文本:检测和识别文本,如字幕、街道名称、产品名称和车牌号。

定价。 亚马逊为其识别服务提供了免费套餐。用户需根据他们分析的媒体文件数量付费,且定价因地区而异,例如,来自爱尔兰和北弗吉尼亚的客户将支付略有不同的费用。您可以使用定价页面来获取报价
对于新用户,在首年内,每月可免费分析1000分钟的视频、5000张图像,并存储最多1000条面部元数据。
以下以北弗吉尼亚(美国东部)的客户为例说明费用情况:
分析存档视频的费用为每分钟0.10美元(按秒计费);直播视频分析的费用为每分钟0.12美元。面部元数据的存储费用为每月每1000条记录0.01美元。
图像分析定价根据处理的图像数量有所降低。前100万张图像的处理费用为1.00美元,接下来的900万张图像为0.80美元,再接下来的9000万张图像为0.60美元。如果您的月工作量超过1亿张图像,则需支付0.40美元。面部元数据的存储费用为每1000条记录0.01美元。
IBM在IBM Cloud上提供了Watson Visual Recognition服务,该服务依赖深度学习算法来分析图像中的场景、对象和其他内容。
用户可以在Watson Studio内部或外部构建、训练和测试自定义模型。
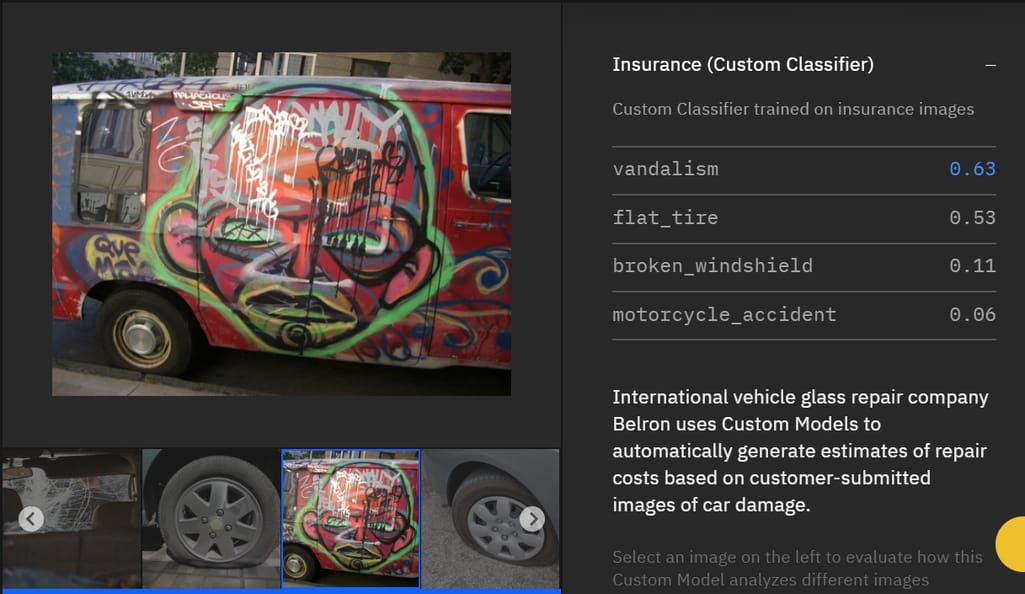
Beta 版中提供的另一个功能使用户能够训练对象检测模型。
预训练模型包括:
通用模型 – 提供来自数千个类的默认分类
显式模型 – 判断图像是否适合一般用途
食品模型 – 识别图像中的食物项目
Text model (文本模型) – 从自然场景图像中提取文本。
此外,开发者可以使用Core ML API将自定义模型集成到iOS应用中,并在Watson Studio的笔记本中进行云协作环境工作。
定价。IBM提供了两种定价计划——Lite和Standard。
Lite:用户每月可免费使用自定义和预训练模型分析1000张图像,并免费创建和重新训练两个自定义模型。作为特别促销优惠,还提供Core ML导出功能。
Standard:图像分类和自定义图像分类每张图像费用为0.002,训练一个自定义模型每张图像费用为0.10。该计划还包括免费的Core ML导出功能。
Microsoft Azure Cloud用户可以从Microsoft的认知服务中选择多种功能。视觉服务分为六大类,涵盖图像和视频分析、面部检测、手写和打印文本识别与提取。这些API均为RESTful接口。
以下是Microsoft认知服务功能的简要列表:
面部检测:在单张图像中检测多达100个人物及其位置,识别包括年龄、性别、情绪、头部姿势、微笑、妆容或面部毛发等属性。为每个面部检测27个关键点 (Face API)。
成人内容检测:使用 Computer Vision API 检测图像是否色情或具有挑逗性。
品牌识别:检测图像中的品牌,包括其大致位置(Computer Vision API )。该功能仅提供英文版本。
地标检测:如果图像中检测到地标,则进行识别(Computer Vision API )。
名人识别:如果图像中存在名人,则进行识别(Computer Vision API )。
图像属性定义:定义图像的强调色、主色调以及是否为黑白(Computer Vision API )。
图像内容描述与分类:用完整句子描述图像内容并进行分类(Computer Vision API )
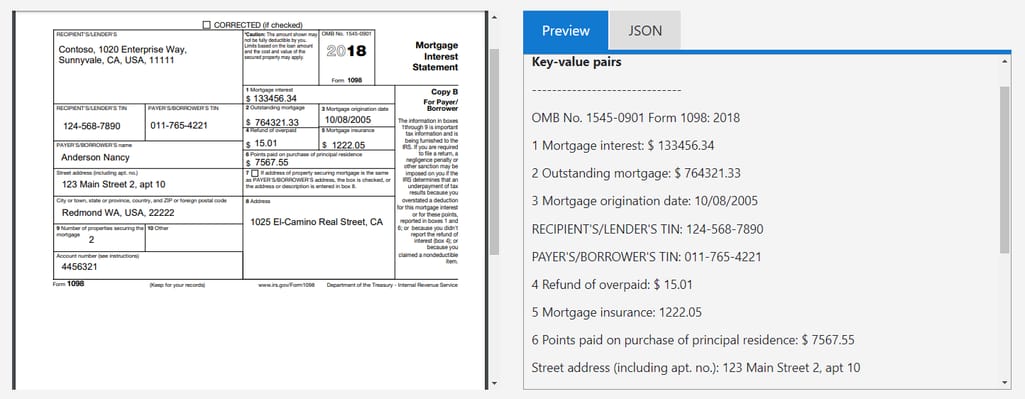
文档信息提取:从文档、收据和表单中提取文本、键值对和表格(表单识别器服务)。
文本识别:识别数字手写、常见多边形形状以及墨迹文档的布局坐标(墨迹识别器服务)。
定价。 服务费用取决于所使用的API、地区以及交易数量(而非API调用次数)。例如,使用面部识别API进行最多100万次交易,每1000次交易的费用为1美元。若交易次数超过1亿次,则每1000次交易的费用降至0.4美元。使用计算机视觉API检测成人内容,在最多100万次交易的情况下,每1000次交易的费用为1.5美元;若交易次数达到或超过1亿次,则每1000次交易的费用为0.65美元。
Clarifai开发了14个预构建的计算机视觉模型,用于识别视觉数据。该服务可通过Clarifai API访问。Clarifai强调其计算机视觉服务的易用性:用户只需将输入(图像或视频)发送到服务,即可获得预测结果。预测结果的类型取决于所运行的模型。
每个预构建模型都能识别给定的图像属性和所含概念。使用现成的模型,您可以实现以下功能:
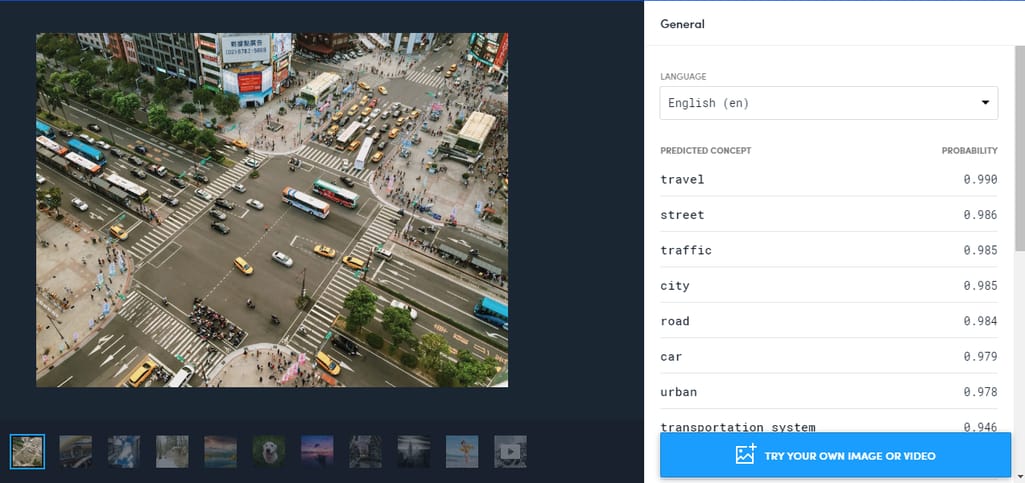
该公司还通过提供能够“识别”相关概念的模型,来考虑旅游、酒店和婚礼策划等业务的特殊性。此外,还提供基于特定图像和概念的训练模型。
定价。 Clarifai的定价基于使用量,为客户提供三种定价计划选择——社区版、基础版(随用随付,月结账单)和企业及公共部门版(价格按需提供)。这些计划服务涵盖了机器学习操作、托管、咨询、移动SDK、基础设施等更多内容。
社区版:包括5000次免费操作、10个免费自定义概念、10000张免费输入图像等其他功能。
基础版:用户可训练自定义模型,每1000个模型版本费用为1.2美元。使用预建模型进行预测的费用为每1000次操作1.2美元,而使用自定义模型进行预测则为每1000次操作3.2美元。图像搜索费用为每1000次操作1.2美元;添加或编辑输入图像的费用同样为每1000次操作1.2美元。
医疗行业的专家同样能够利用图像识别工具。Zebra Medical Vision提供实时分析医学图像(如计算机断层扫描和X光片)的解决方案。该公司利用数百万张成像扫描的专有数据库,结合机器学习和深度学习工具,开发用于管理放射科医生工作流程的软件。其解决方案专注于识别特定病症,并有一项功能用于标记和优先处理病例。能够检测CT扫描中的脑、心血管、肺、肝和骨骼疾病,X光扫描中的40种不同病症,以及2D乳腺X光片中的乳腺癌。Zebra Medical Vision符合HIPAA和GDPR标准。
定价:Zebra的AI1一体化解决方案的费用高达每次扫描1美元。
您还可以考虑DeepAI、Hive、Nanonets、Imagga等其他供应商的工具。Sightengine的图像和视频审核API、xModerator的图像审核服务,以及Face++ AI Open Platform的面部和身体识别API和SDK,也可能非常适合您的需求。
市面上存在大量商业化的图像识别及其他计算机视觉任务API,因此选择合适的API以满足您的需求和要求至关重要。您可以根据以下标准评估各产品:
视觉分析功能:浏览产品页面和文档,了解API能够识别和检测的实体类型。文档通常包含更详细的信息,因此建议仔细阅读。
视觉数据类型和分析模式:API或产品是否支持图像分析、视频分析或两者兼有?同时,供应商会明确提供哪种类型的预测(批量和在线)。
计费方式:供应商提供基于使用量的定价,并公开大部分定价信息,因此您可以根据预计的工作量估算每个解决方案的成本。
API 使用情况。只有当开发人员知道如何使用 API 时,它们才会变得有用。文档中将提供有关如何启用API、进行API调用以及响应示例的教程。
支持服务:必须提供24/7的技术支持,通过多个渠道(电话、电子邮件、论坛等)进行。供应商通常会提供多种支持计划供购买。







