

2024年最佳天气API

马克·扎克伯格不久前在 Meta Connect 活动上发布了 LLaMA 3.2,它包含许多您一定想了解的功能。这种新模型旨在突破人工智能 (AI) 的界限,非常适合从医疗保健到数字营销等各种应用。
LLaMA 3.2 之所以脱颖而出,是因为它能够理解并响应文本和图像。您可以上传图像并提出相关问题,模型将提供相关答案。这使得它比仅分别处理文本或图像的传统模型更加通用。
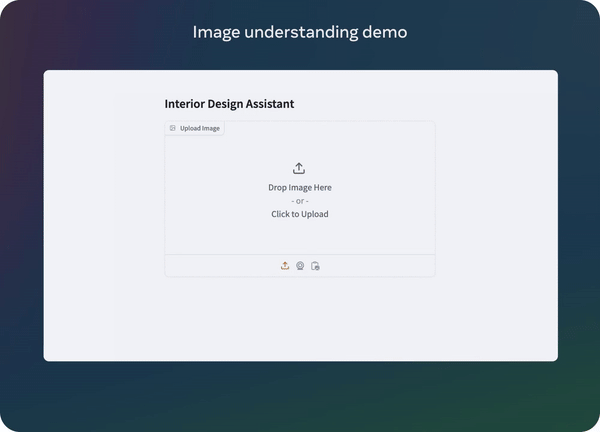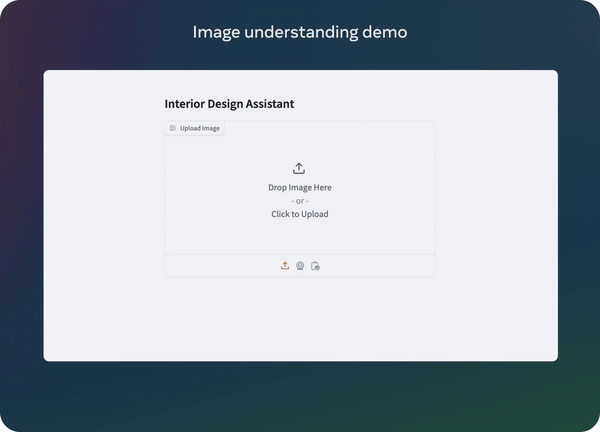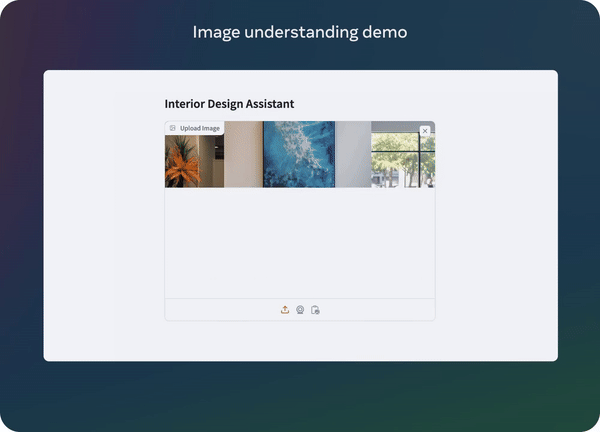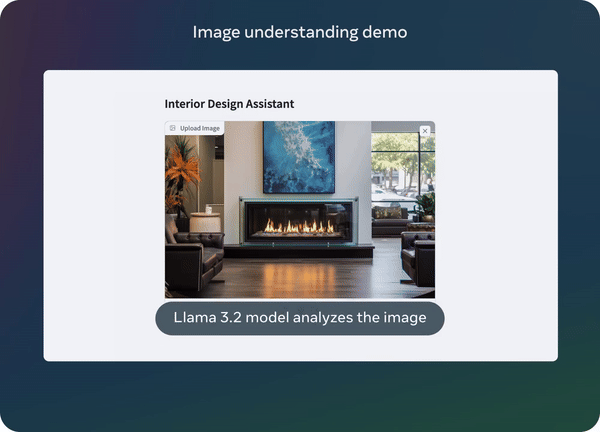
其中最大的亮点之一是 LLaMA 3.2 可以在移动设备和高通、ARM 处理器等边缘硬件上流畅运行。Meta 还发布了模板,帮助开发者使用 Swift 创建应用程序,让这项技术在移动应用程序中的使用变得前所未有的简单。
LLaMA 3.2 有多种尺寸可供选择:
Meta 提供预训练模型和指令微调版本。这意味着开发人员和研究人员可以轻松地将这些模型用于特定任务,而无需从头开始。
LLaMA 3.2 已在各种基准测试中取得了令人印象深刻的成绩:
这表明 LLaMA 3.2 能够理解复杂的视觉内容,这对于医疗诊断和自动化等领域至关重要。
Meta 鼓励开发人员使用 LLaMA Stack,它提供了各种用于批量和实时推理和微调的工具。此外,LLaMA 3.2 支持多种编程语言,如 Python、Node.js 和 Swift,为开发人员提供了创建 AI 驱动应用程序所需的一切。
该模型还支持多种语言的文本任务,包括英语、德语、法语、意大利语、葡萄牙语、印地语和泰语。虽然英语是图像文本任务的主要语言,但该模型将来可以针对其他语言进行微调。
1B 和 3B 参数模型是较大的 90B 模型的精简版本。这意味着它们已针对高性能进行了优化,而无需完全重新训练,从而使其能够高效地完成特定任务。
LLaMA 3.2 被宣传为开放重量级模型,但它确实有一些许可限制。幸运的是,大多数企业和开发人员不会遇到任何问题,除非他们要扩展到非常大的用户群。
Meta 展示了由 LLaMA 3.2 提供支持的深度伪造助手的演示,用户可以与数字孪生进行实时对话!
购物者可以上传自己喜欢的商品图片,LLaMA 3.2 会帮您找到可供购买的类似商品,让购物变得更轻松、更个性化。
学生可以就教科书中的图像提出问题,并获得详细的解释,以增强他们的理解和参与度。
LLaMA 3.2 可以帮助医生快速分析 X 射线和 MRI,识别骨折或肿瘤等问题,以加强对患者的护理。
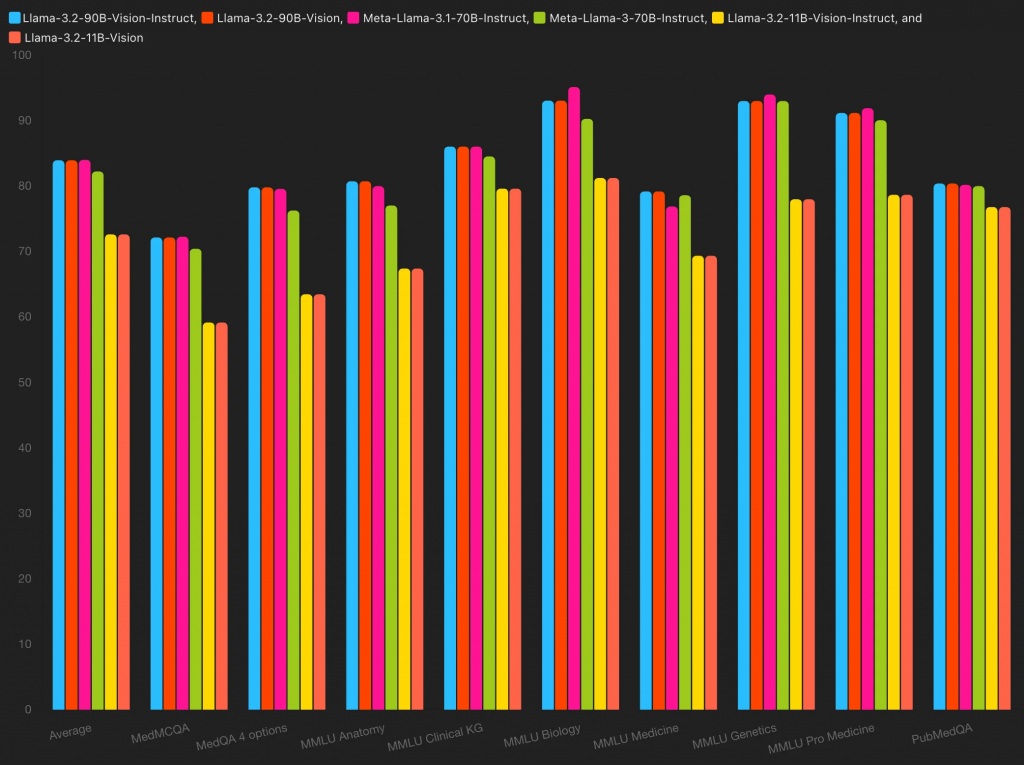
例如,对医疗保健领域的 Llama-3.2 90B、11B、3B 和 1B 的分析显示:
🥇 Llama-3.1 70B Instruct表现优异,平均成绩为 84%(MMLU 大学生物学、MMLU 专业医学)
🥈 Meta-Llama-3.2-90B-Vision(Instruct 和 Base)以 83.95% 的平均得分排名第二
🥉 Meta-Llama-3-70B-Instruct位居第三,平均分数为 82.24%(MMLU 医学遗传学、MMLU 大学生物学)
LLaMA 3.2 可以分析实时视频来检测异常行为或潜在威胁,从而提高公共场所的安全性。
自然保护者可以使用 LLaMA 3.2 分析无人机拍摄的镜头,以监测动物种群并实时检测偷猎活动。
借助 LLaMA 3.2,Meta 巩固了其在多模态 AI 技术方面的领先地位。无论您是希望创建移动应用程序的开发人员,还是探索小众任务的研究人员,LLaMA 3.2 都能提供您所需的灵活性和强大功能。
准备好深入研究了吗?您可以通过幂简集成API hub访问 LLaMA API 模型和 200 多个其他模型。
使用下面的代码片段免费测试 LLaMA 3.2
import os
from together import Together
client = Together(base_url="https://api.aimlapi.com/v1", api_key="<YOUR_API_KEY>")
response = client.chat.completions.create(
model="meta-llama/Llama-Vision-Free",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "What sort of animal is in this picture? What is its usual diet? What area is
the animal native to? And isn’t there some AI model that’s related to the image?",
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/3/3a/LLama.jpg/444px-
LLama.jpg?20050123205659",
},
},
],
}
],
max_tokens=300,
)
print("Assistant: ", response.choices[0].message.content)






