

微博热搜API的免费调用教程

现如今已经是人工智能时代,人工智能技术正以前所未有的速度发展,其中语音识别和处理技术尤为突出。科大讯飞作为全球领先的智能语音和人工智能企业,其旗下的讯飞星火API为开发者提供了强大的语音识别、语音合成、自然语言处理等能力。撰写本篇文章是希望能够帮助那些想要利用讯飞星火API开发智能应用的开发者提供一个详细的入门教程。我们将一步步指导您如何获取API密钥,并进行可用性测试以及常见问题解答。
获取讯飞星火API步骤如下:
1.访问 https://xinghuo.xfyun.cn/sparkapi 官网
2.成为开发者,点击页面右上角“注册/登录”按钮,注册并完善信息,即可成为开发者。
3.访问控制台,登录后点在线调试进入控制台。
4.点击创建新应用创建应用。
5.进入服务详情页
可以访问接口文档,对应用进行自定义设置。

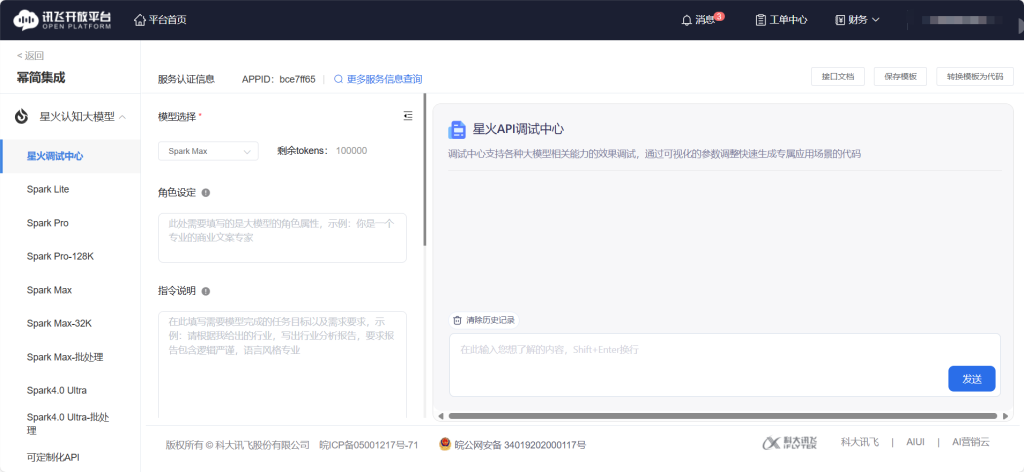
在获取API密钥后,进行可用性测试是确保其正常工作的重要步骤。
快速调用集成星火认知大模型(Python示例)
注:项目仅支持 Python3.8+
步骤一:安装PyPI上的包,在python环境中执行命令
pip install --upgrade spark_ai_python步骤二:python代码示例执行
from sparkai.llm.llm import ChatSparkLLM, ChunkPrintHandler
from sparkai.core.messages import ChatMessage
#星火认知大模型Spark Max的URL值,其他版本大模型URL值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_URL = 'wss://spark-api.xf-yun.com/v3.5/chat'
#星火认知大模型调用秘钥信息,请前往讯飞开放平台控制台(https://console.xfyun.cn/services/bm35)查看
SPARKAI_APP_ID = ''
SPARKAI_API_SECRET = ''
SPARKAI_API_KEY = ''
#星火认知大模型Spark Max的domain值,其他版本大模型domain值请前往文档(https://www.xfyun.cn/doc/spark/Web.html)查看
SPARKAI_DOMAIN = 'generalv3.5'
if __name__ == '__main__':
spark = ChatSparkLLM(
spark_api_url=SPARKAI_URL,
spark_app_id=SPARKAI_APP_ID,
spark_api_key=SPARKAI_API_KEY,
spark_api_secret=SPARKAI_API_SECRET,
spark_llm_domain=SPARKAI_DOMAIN,
streaming=False,
)
messages = [ChatMessage(
role="user",
content='你好呀'
)]
handler = ChunkPrintHandler()
a = spark.generate([messages], callbacks=[handler])
print(a)在使用讯飞星火API搭建应用时,除了获取和测试API密钥外,还需考虑以下因素:
注意: 该接口可以正式使用。如您需要申请使用,请点击前往产品页面。
Tips:
| 1 | 计费包含接口的输入和输出内容 |
| 2 | 1 token约等于1.5个中文汉字 或者 0.8个英文单词 |
| 3 | Spark Lite支持[搜索]内置插件;Spark Pro, Spark Max和Spark 4.0Ultra支持[搜索]、[天气]、[日期]、[诗词]、[字词]、[股票]六个内置插件 |
| 4 | Spark 4.0Ultra/Max现已支持system、Function Call功能 |
| 5 | Spark 4.0Ultra版本现已支持返回联网检索的信源标题及地址 |
Tips: 星火大模型API当前有Lite、Pro、Pro-128K、Max、Max-32K和4.0 Ultra六个版本,各版本独立计量tokens。
传输协议 :ws(s),为提高安全性,强烈推荐wss
| 请求版本 | 请求地址 |
| Spark4.0 Ultra | wss://spark-api.xf-yun.com/v4.0/chat |
| Spark Max-32K | wss://spark-api.xf-yun.com/chat/max-32k |
| Spark Max | wss://spark-api.xf-yun.com/v3.5/chat |
| Spark Pro-128K | wss://spark-api.xf-yun.com/chat/pro-128k |
| Spark Pro | wss://spark-api.xf-yun.com/v3.1/chat |
| Spark Lite | wss://spark-api.xf-yun.com/v1.1/chat |
URL鉴权是保护Web应用中敏感资源的重要安全措施,它通过在URL中嵌入特定参数来控制对资源的访问权限。这些参数通常包括时间戳、随机数、用户ID等,并结合密钥使用哈希算法生成签名,以验证请求的合法性。
讯飞星火URL鉴权参考 通用URL鉴权文档
# 参数构造示例如下
{
"header": {
"app_id": "12345",
"uid": "12345"
},
"parameter": {
"chat": {
"domain": "generalv3.5",
"temperature": 0.5,
"max_tokens": 1024,
}
},
"payload": {
"message": {
# 如果想获取结合上下文的回答,需要开发者每次将历史问答信息一起传给服务端,如下示例
# 注意:text里面的所有content内容加一起的tokens需要控制在8192以内,开发者如有较长对话需求,需要适当裁剪历史信息
"text": [
#如果传入system参数,需要保证第一条是system
{"role":"system","content":"你现在扮演李白,你豪情万丈,狂放不羁;接下来请用李白的口吻和用户对话。"} #设置对话背景或者模型角色
{"role": "user", "content": "你是谁"} # 用户的历史问题
{"role": "assistant", "content": "....."} # AI的历史回答结果
# ....... 省略的历史对话
{"role": "user", "content": "你会做什么"} # 最新的一条问题,如无需上下文,可只传最新一条问题
]
}
}
}接口请求字段由三个部分组成:header,parameter, payload。 字段解释如下
header部分
| 参数名称 | 类型 | 必传 | 参数要求 | 参数说明 |
|---|---|---|---|---|
| app_id | string | 是 | 应用appid,从开放平台控制台创建的应用中获取 | |
| uid | string | 否 | 每个用户的id,非必传字段,用于后续扩展 ,”maxLength”:32 |
parameter.chat部分
| 参数名称 | 类型 | 必传 | 参数要求 | 参数说明 |
|---|---|---|---|---|
| domain | string | 是 | 取值为[lite,generalv3,pro-128k,generalv3.5,max-32k,4.0Ultra] | 指定访问的模型版本: lite指向Lite版本; generalv3指向Pro版本; pro-128k指向Pro-128K版本; generalv3.5指向Max版本; max-32k指向Max-32K版本; 4.0Ultra指向4.0 Ultra版本; 注意:不同的取值对应的url也不一样! |
| temperature | float | 否 | 取值范围 (0,1] ,默认值0.5 | 核采样阈值。用于决定结果随机性,取值越高随机性越强即相同的问题得到的不同答案的可能性越高 |
| max_tokens | int | 否 | Pro、Max、Max-32K、4.0 Ultra 取值为[1,8192],默认为4096; Lite、Pro-128K 取值为[1,4096],默认为4096。 | 模型回答的tokens的最大长度 |
| top_k | int | 否 | 取值为[1,6],默认为4 | 从k个候选中随机选择⼀个(⾮等概率) |
| show_ref_label | boolean | 否 | 取值范围[true,false] ,默认 false | 该参数仅4.0 Ultra版本支持,当设置为true时,如果输入内容触发联网检索插件,会先返回检索信源列表,然后再返回星火回复结果,否则仅返回星火回复结果 |
payload.message.text部分
注意:1、请确保text下所有content内容累计的tokens数量在模型上下文长度的限制之内。具体可参考下文中content字段的参数要求
2、如果传入system参数,需要保证第一条是system;多轮交互需要将之前的交互历史按照system-user-assistant-user-assistant进行拼接
| 参数名称 | 类型 | 必传 | 参数要求 | 参数说明 |
|---|---|---|---|---|
| role | string | 是 | 取值为[system,user,assistant] | system用于设置对话背景(仅Max、Ultra版本支持) user表示是用户的问题, assistant表示AI的回复 |
| content | string | 是 | 所有content的累计tokens长度,不同版本限制不同: Lite、Pro、Max、4.0 Ultra版本: 不超过8192; Max-32K版本: 不超过32* 1024; Pro-128K版本:不超过 128*1024; | 用户和AI的对话内容 |
在不返回检索信源的情况下,大模型流式返回结构如下:
# 接口为流式返回,此示例为最后一次返回结果,开发者需要将接口多次返回的结果进行拼接展示
{
"header":{
"code":0,
"message":"Success",
"sid":"cht000cb087@dx18793cd421fb894542",
"status":2
},
"payload":{
"choices":{
"status":2,
"seq":0,
"text":[
{
"content":"我可以帮助你的吗?",
"role":"assistant",
"index":0
}
]
},
"usage":{
"text":{
"question_tokens":4,
"prompt_tokens":5,
"completion_tokens":9,
"total_tokens":14
}
}
}
}在不返回检索信源的情况下,接口返回字段分为两个部分,header,payload。字段解释如下
header部分
| 字段名 | 类型 | 字段说明 |
|---|---|---|
| code | int | 错误码,0表示正常,非0表示出错;详细释义可在接口说明文档最后的错误码说明了解 |
| message | string | 会话是否成功的描述信息 |
| sid | string | 会话的唯一id,用于讯飞技术人员查询服务端会话日志使用,出现调用错误时建议留存该字段 |
| status | int | 会话状态,取值为[0,1,2];0代表首次结果;1代表中间结果;2代表最后一个结果 |
payload.choices部分
| 字段名 | 类型 | 字段说明 |
|---|---|---|
| status | int | 文本响应状态,取值为[0,1,2]; 0代表首个文本结果;1代表中间文本结果;2代表最后一个文本结果 |
| seq | int | 返回的数据序号,取值为[0,9999999] |
| content | string | AI的回答内容 |
| role | string | 角色标识,固定为assistant,标识角色为AI |
| index | int | 结果序号,取值为[0,10]; 当前为保留字段,开发者可忽略 |
payload.usage部分(在最后一次结果返回)
| 字段名 | 类型 | 字段说明 |
|---|---|---|
| question_tokens | int | 保留字段,可忽略 |
| prompt_tokens | int | 包含历史问题的总tokens大小 |
| completion_tokens | int | 回答的tokens大小 |
| total_tokens | int | prompt_tokens和completion_tokens的和,也是本次交互计费的tokens大小 |
在返回检索信源的情况下,在大模型返回结果之前会先返回检索信源,结构如下:
{
"header": {
"code": 0,
"message": "Success",
"sid": "cht000b79a4@dx190da456b5db80a560",
"status": 1
},
"payload": {
"plugins": {
"text": [
{
"name": "ifly_search",
"content": "[{\"index\":1,\"url\":\"https://baike.baidu.com/item/%E6%9B%B9%E6%93%8D/6772\",\"title\":\"曹操(中国东汉末年权臣,曹魏政权的奠基者)_百度百科\"},{\"index\":2,\"url\":\"https://zhidao.baidu.com/question/437349472.html\",\"title\":\"曹操是哪一年出生的? - 百度知道\"},{\"index\":3,\"url\":\"http://www.lidaishi.com/default.aspx?did=130019\",\"title\":\"曹操的一生事迹简介-历代史历史网\"},{\"index\":4,\"url\":\"https://zhidao.baidu.com/question/374585705.html\",\"title\":\"曹操生于哪一年? - 百度知道\"},{\"index\":5,\"url\":\"https://baike.baidu.hk/item/%E6%9B%B9%E6%93%8D/6772\",\"title\":\"曹操(中國東漢末年權臣,曹魏政權的奠基者)_百度百科\"}]",
"content_type": "text",
"content_meta": null,
"role": "tool",
"status": "finished",
"invoked": {
"namespace": "ifly_search",
"plugin_id": "ifly_search",
"plugin_ver": "",
"status_code": 200,
"status_msg": "Success",
"type": "local"
}
}
]
}
}
}解析检索信源Python示例:
if('plugins' in data['payload']):
text_list = data['payload']['plugins']['text']
search_refer = text_list[0]
refer_content = search_refer['content']
refer_list = json.loads(refer_content)
print("参考内容:")
for line in refer_list:
num = line['index']
url = line['url']
title = line['title']
print(str(num) + "、" + title + "[ " + url + " ]")Function call 作为大模型能力扩展的核心,支持大模型在交互过程中识别出需要调度的外部接口:
注:当前仅Spark Max/4.0 Ultra 支持了该功能;需要请求参数payload.functions中申明大模型需要辨别的外部接口,申明方式见下方请求示例
# 参数构造示例如下,仅在原本生成的基础上,增加了functions.text字段,用于方法的注册
{
"header": {
"app_id": appid,
"uid": "1234"
},
"parameter": {
"chat": {
"domain": domain,
"random_threshold": 0.5,
"max_tokens": 2048,
"auditing": "default"
}
},
"payload": {
"message": {
"text": [
{"role": "user", "content": ""} # 用户的提问
]
},
"functions": {
"text": [
{
"name": "天气查询",
"description": "天气插件可以提供天气相关信息。你可以提供指定的地点信息、指定的时间点或者时间段信息,来精准检索到天气信息。",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "地点,比如北京。"
},
"date": {
"type": "string",
"description": "日期。"
}
},
"required": [
"location"
]
}
},
{
"name": "税率查询",
"description": "税率查询可以查询某个地方的个人所得税率情况。你可以提供指定的地点信息、指定的时间点,精准检索到所得税率。",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "地点,比如北京。"
},
"date": {
"type": "string",
"description": "日期。"
}
},
"required": [
"location"
]
}
}
]
}
}
}接口请求payload.functions字段解释如下:
| 参数名称 | 类型 | 必传 | 参数要求 | 参数说明 |
|---|---|---|---|---|
| text | array | 是 | 列表形式,列表中的元素是json格式 | 元素中包含name、description、parameters属性 |
| name | string | 是 | function名称 | 用户输入命中后,会返回该名称 |
| description | string | 是 | function功能描述 | 描述function功能即可,越详细越有助于大模型理解该function |
| parameters | json | 是 | function参数列表 | 包含type、properties、required字段 |
| parameters.type | string | 是 | 参数类型 | |
| parameters.properties | string | 是 | 参数信息描述 | 该内容由用户定义,命中该方法时需要返回哪些参数 |
| properties.x.type | string | 是 | 参数类型描述 | 该内容由用户定义,需要返回的参数是什么类型 |
| properties.x.description | string | 是 | 参数详细描述 | 该内容由用户定义,需要返回的参数的具体描述 |
| parameters.required | array | 是 | 必须返回的参数列表 | 该内容由用户定义,命中方法时必须返回的字段 |
// 触发了function_call的情况下,只会返回一帧结果,其中status 为2
{"header":{"code":0,"message":"Success","sid":"cht000b41d5@dx18b851e6931b894550","status":2},"payload":{"choices":{"status":2,"seq":0,"text":[{"content":"","role":"assistant","content_type":"text","function_call":{"arguments":"{\"datetime\":\"今天\",\"location\":\"合肥\"}","name":"天气查询"},"index":0}]},"usage":{"text":{"question_tokens":3,"prompt_tokens":3,"completion_tokens":0,"total_tokens":3}}}}| 字段名 | 类型 | 字段说明 |
|---|---|---|
| function_call | json | function call 返回结果 |
| function_call.arguments | json | 客户在请求体中定义的参数及参数值 |
| function_call.name | string | 客户在请求体中定义的方法名称 |
问题1:如何找到讯飞星火 API
幂简集成是国内领先的API集成管理平台,专注于为开发者提供全面、高效、易用的API集成解决方案。幂简API平台可以通过以下两种方式找到所需API:通过关键词搜索API(例如,输入’有道翻译 API‘这类品类词,更容易找到结果)、或者从API hub分类页进入寻找。
问题2:讯飞星火 API的替代品有哪些?
市场上存在免费、付费两种替代者
例如
百川大模型API接口介绍及对接-百川智能 -超全API平台-幂简集成
Copilot AI大模型API接口介绍及对接 -超全API平台-幂简集成
混元大模型API接口介绍及对接-腾讯 -超全API平台-幂简集成
豆包大模型API接口介绍及对接-字节跳动 -超全API平台-幂简集成
千帆大模型API接口介绍及对接-百度智能云 -超全API平台-幂简集成
360多模态大语言模型API接口介绍及对接 -超全API平台-幂简集成
更多竞品可以在讯飞星火API开放平台找到。
本文详细介绍了获取讯飞星火大模型API密钥的步骤,从访问科大讯飞官网到注册账户,再到创建项目和获取密钥,为开发者提供了全面的操作指南。文章还包括了如何进行 API 可用性测试的示例,以及使用过程中需要注意的关键因素,如接口说明、服务配置等。通过这些详细的步骤和实用的建议,开发者可以轻松地将讯飞星火大模型的强大功能融入到自己的项目中。





