

API货币化的最佳实践:定价、打包和计费

在波形智能创始人&CEO 姜昱辰看来,蛙蛙写作已经跑通了 PMF,在为用户创造价值。
半年时间,30 万用户,生成了将近 200 亿字数的文本,付费用户日均使用时长 4.7 小时。
主打无限长文本生成,专注小说和网文创作的蛙蛙写作,是基于波形智能自研的创作大模型 WEAVER,并且使用了 RecurrentGPT 技术实现了长文本输出长度的突破。
不少人会担心写作类产品会被不断升级的基础大模型的能力所覆盖,但姜昱辰丝毫不担心,「能与 L0 层技术(Scaling Law)有机结合的技术,即使在未来基础模型变得更加强大的时候,我们研发的技术能作为其增益,而非被它覆盖掉」,也就是说,「不要挡在OpenAI的路上」。
7 月 28 日,波形智能发布了个性化自适应私人语言模型「Weaver 2.0」,推出新一代 AI——Life-long Personalized Al(LPA),主打千人千面的普惠化 AI。在发布会之后,创始人&CEO 姜昱辰做客 Founder Park 直播间,与 Founder Park COO 艾之一起,聊了聊创业 500 天的收获与经验。
文章基于直播整理,Founder Park 略有调整。
艾之:我比较好奇,你们当时为什么会选择小说写作作为公司的业务切入点?作为以学术能力见长的创业团队,你们考虑的点有哪些?
姜昱辰:我本人是做 NLP 的,在这一波 AI 浪潮来临的时候面临着一些抉择,比如应该在学术上做什么样的研究,在这样一个规模化的时代,如果要做商业化哪个方向可行。
之所以选文本生成这个场景,首先肯定还是 TPF 驱动,我认为整个长文本生成的技术目前已经达到了商业可用的级别,到了一个可以赋能小说作者的水平。其次我们发现这个需求的市场非常大,我自己是一个资深的小说爱好者,包括之前做机器翻译的时候,就会感觉到这块在全球范围内都是一个通用的高频需求。
艾之:那你是在学术研究中发现了这个市场吗?比如写 paper 的时候发现这事正好 TPF 上了。
姜昱辰:不完全是这样,其实主要还是场景 pull 出技术。我之前做中英小说翻译的时候,就发现这个场景中有很多问题还没有被解决,因为会由需求推着去做可控的长文本生成技术。只不过之前技术不成熟,现在技术达到一定程度后,我们就可以把它技术化,商业化了。
艾之:所以你在学校的时候,就已经是一边看学术领域有哪些新东西可以做,另一边还非常积极地去发现现实世界里边还有什么样的问题需要解决。
姜昱辰:对,我是一个非常场景驱动的人,22 年底我就在想,大模型时代到来后,能做些什么。当时就觉得,这样一个技术要应用在真实世界当中,要为每个人创造价值,那就必定是个性化的。长文本也是,它要能达到商用的级别,上下文的限制问题一定要解决,memory 的问题要解决,个性化的问题要解决。某种程度上它带动了我去思考什么样的技术值得被开发。
艾之:蛙蛙写作,经过这五百天的磨练目前发展到什么程度了?
姜昱辰:从 1.0 到 2.0,半年时间,我们差不多有 30 万用户,生成了将近 200 亿字数的文本。最好的数据是现在我们(付费)用户的日均使用时长大概有 4.7 个小时,这说明我们的产品真的在为用户创造价值。
艾之:4.7 小时这个数据震惊到我了,说明用户真的在用这个产品去创作,把它带入到个人的创作流程中。那你们现在付费用户的主要群体是 B 端用户还是独立作者居多?
姜昱辰:独立作者会多一些,也分签约作者和非签约作者。
艾之:具体来说用户画像是怎样的?比如是全职作者还是兼职作者之类的?
姜昱辰:背景挺多样的,一开始我们以为全职作者会占主流,但事实上我们观察到很多人是用了我们产品后才变成作者的,并且用我们生成的东西去投稿赚钱,这部分用户比例挺大的,也挺出乎我们意料的。
艾之:有没有跟一些专业作者、编剧聊过?他们对 AI 生成工具的接受度有多高?
姜昱辰:7 月 28 日的新品发布会上邀请了一些导演编剧来参加我们的圆桌讨论,新版本里也有专门为影视工作者开发的工具。从这些专业人士的反应来看,虽然他们的第一反应都是恐惧,但是也会觉得利用新工具,和 AI 合作来做一些有意思的事情挺好。总体来说大家对于 AI 还是拥抱的态度。
艾之:那还是挺不错的,我觉得技术出来后,在垂类领域还是需要给 AI 灌进去很多垂类知识才能 work,你们是怎么把工作流、工作经验加到产品里面去的?刚开始是如何做冷启动的?
姜昱辰:我们最早的用户是通过收稿子的社群建立起来的,当时在小红书这些地方收短篇,甚至付钱收稿,相当于经历了一次 PMF 的验证过程,我们想着让他们到蛙蛙上投稿试试,这样积累了第一批用户,后来再把他们转化成核心用户。
艾之:这个有点像有奖征文。
姜昱辰:对对对,蛙蛙新概念作文大赛。我们也会把这些投稿作者拉到群里面,讨论我们的产品哪里好用哪里不好用,这对我们来说就是最早的一批种子用户。

艾之:你们这个劲用的还是挺巧的,挺有意思的一种冷启动方式。
从 23 年 3 月份到现在,你们的产品正式上线也有半年时间,在这段时间里,你们产品经历了哪些大的改版?我觉得对于创业团队来讲,一个产品的转向都是非常正常的事情,你们是怎样一个路径?
姜昱辰:我们一开始做的是纯 ToC 的互动内容平台,平台上所有内容都是 AI 生成的,当时也发布了一个小程序。后来慢慢意识到内容是整个产品中最重要的部分,不管做什么,还是需要人+AI 辅助生成高质量内容的这样一个抓手。出于这样的目的,我们做了蛙蛙写作,把用户吸引过来做一些创作。因为之前的版本是一个互动平台,第一个版本是一个多线内容的编辑器,我们把一键生成的接口开放给创作者,希望在 AI 一键生成基础上他们做一些审核修改的工作。
这个功能做得久了就会发现,我们好像真的能帮到大家写东西,跟一些用户接触交流之后,我们在去年年底的时候做了两个比较重要的变动,一个是把多线的部分隐藏变成单线,让整个创作逻辑变得更加清晰。第二件事是我们强化了编辑器的属性,一款好的 AI 辅助写作工具首先得是一款好的编辑器。所以我们把整个流程都变成了可编辑、可控的,跟 AI 可融合的。编辑器在长文本的创作上是非常非常重要的,在几百万字的情况下,非常需要人在中间有交互编辑的过程。这两个改动做了以后,就是现在蛙蛙写作所呈现出来的形态了。
艾之:你们在去拆解作者创作过程的时候,是原本已经很了解里面的流程了,还是说其实也要去找一些用户,去做非常深入的调研,观察他们怎么去用这个产品?
姜昱辰:我们有很多的研究,因为我不是专业写小说的,所以一开始跟大量的编剧以及行业里的人去沟通他们都是怎么样去创作的,怎么去写稿子的。蛮有意思的一点是,跟很多很厉害的作者去聊的时候,他们讲不出所以然来,但跟一些编辑去聊,他们可以把很多逻辑讲得很清楚。因为编辑们每天都在审稿,看得多了对写作这个东西本身更有分析。还有一个点,比较好的作者的创作习惯挺一致的,一般情况下都会写大纲和人物小传,把整个东西都构思好后再去做细节创作。我们把这个流程也加在了蛙蛙写作里面。
艾之:你们作为一个创业公司,大家一定会天然想到说你们的资源是有限的,没有办法无限制地投入到技术的研发上面,随心所欲地去做研究。见投资人或者说跟同行交流的时候,大家一定会问到,你做的这个事会不会有一天就被大模型吞没了?
姜昱辰:对,几乎天天会被问到,你会不会挡在 OpenAI 的路上,要做什么样的技术创新才不会被淘汰。
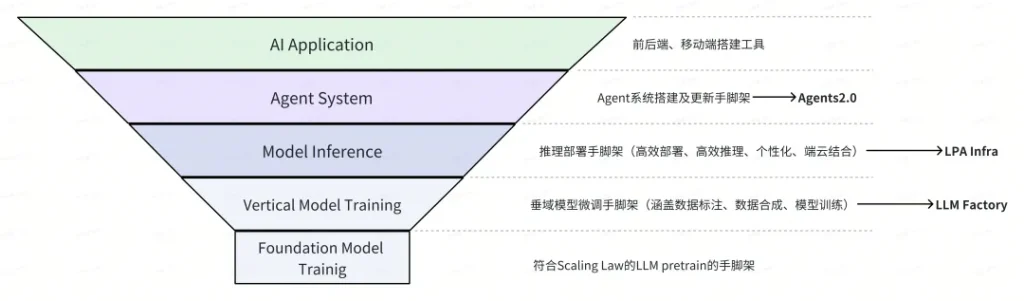
我觉得有两个维度,一个是会不会被大模型吞噬,另一个是会不会被大模型公司吞噬。之前我提到一个金字塔结构,或者说是 AI/LLM 的技术栈,最底层最核心的是基础模型。基础模型需要不断 scaling,以前我们认为 1B 的模型已经很大了,到了 2023 年,我们觉得 34B 的模型也不算很大了,参数也还在不断被扩大。这一层需要解决的技术问题是如何做到稳定地 scaling,以及在资源和模型表现之间找到好的平衡策略。
第二层是垂域模型。在基础模型之上,我们进行持续地预训练,开发了专用于垂域模型训练的「脚手架」——LLM factory,Weaver 就是利用这个训练出来的。垂域模型训练可以帮助适应特定领域的语料和知识,让模型的输出更专业。
第三层是模型推理。这一层在工业界相对少见,但在学术界研究较多。大模型本身是个概率分布,如何通过解码算法将这些概率分布转化为具体的输出句子。我们波形在这一层有较深入的研究,包括 score-based decoding 的技术(下图中的 LPA Infra)。
第四层是 Agent。Agent 需要具备 Memory、Reflection、对环境的认知能力,以及自我进化的能力。这些能力使得 Agent 能够根据环境进行反应和自我调整。我们在这一层进行了投入,并研发了端到端的可持续自进化的 Agent 系统 (self-evolving agent,下图中的 Agents 2.0)。
最外层是 AI 应用。这一层包含各种应用场景,比如项目化写作、AI 客服、AI 导购等。大概是这样一个分层。
艾之:有评论区在问,如果要达到类似的效果,可能用强模型微调一下就可以了,做垂类大模型的意义是什么?再顺着延伸下,这几层里面,哪几层做完之后会加高你们产品的门槛?不同的门槛对于团队的要求会是什么样子?
姜昱辰:我觉得这是一个非常典型的问题,网友的 mindset 和一些我们接触到的 B 端客户蛮不同的,他们比较倾向于训练一个所谓的「垂域大模型」。B 端客户通常会问:训练一个垂域模型需要多少钱?需要多少数据?但在问这个问题之前,首先应该问自己:我是否真的需要训练一个垂域模型?其实 80% 的场景中,并不需要训练垂域模型。
我做过一个红蓝榜:红榜是需要训练垂域模型的案例,蓝榜是不需要训练垂域模型的案例。红榜的例子包括对文风或语义有特殊要求的场景,比如写小说或标书,这些场景对风格有特别的要求,必须通过训练模型来达到效果。而在一些重逻辑推理的场景,比如 agent 处理信用证审单或解决数学题等,训练垂域模型可能并不必要,更多的是依靠模型的记忆能力和理解能力。
网友的问题是,几千条数据进行微调不就可以了,为什么还要垂域模型?其实微调本身也是在训练垂域模型。垂域大模型的定义非常宽广,可以涵盖各种成本的训练场景。比如几千条数据就能达到好的效果,这可以算是一种低成本的垂域模型训练。有些场景可能需要更复杂的训练,在前面进行持续预训练,这可能需要更高的成本。
使用 RAG 来解决问题也有门槛。模型需要理解 RAG,embedding 模型的效果也很重要,Similarity metric 的好坏对结果有很大影响。所以每一层都有其技术难点和关键点,把这些问题解决好都会有价值。
对一个企业来说,单独解决某一层的问题很难。无论是 C 端还是 B 端客户,最终需要的是一个 all-in-one 的解决方案。客户不会只因为你解决了某一个技术难题而选择你,而是因为你能帮助他们实现整体的目标,对蛙蛙来说就是帮创作者写出更好的小说。因此,一个 AI 公司需要在每一层都有所能力,尽管在不同地方可能有自己的擅长点,但在每一层上都不能缺席。
艾之:我觉得你的这个回答也解释了,或者说佐证了为什么大家觉得 2024 年应该有非常多的应用出来,但是其实没有。因为中间还是有非常多的断点,层与层之间没有完全连接上。
你们刚发布的 LPA,它在刚才讲的分层结构中是怎么样分布的?
姜昱辰:其实就像前面说的,「AI 公司在每一层都不能缺席」,LPA 是一个端到端的在每一层都有所融合的技术栈。具体而言,我们有几个核心的构建模块。在 memory 方面,我们有比较深厚的积累,很多人可能听说过我们的 RecurrentGPT。这种长短期记忆机制在 LPA 中都有继承。
LPA 的核心是一个叫 AI Persona 的系统。这个系统中的 memory 模块继承了 RecurrentGPT 的一些设计思路。另外AI Persona 中还包括 Personality、Pattern 和 Preference。Preference 数据包括用户在多个选项中的选择,AI Persona 会记住并反映在后续的互动中。构建 Preference 数据是 LPA 的一个核心部分。
另一个核心是如何在保护隐私的情况下,充分利用这些 Preference 数据。我们不能将用户数据用于训练大模型,而只是在本地化个性化交流中使用。这意味着 AI Persona 在本地保存用户信息,大模型在不访问这些私有数据的情况下,能够生成个性化的输出。
第三点是自适应。作为用户的 copilot,AI 需要能够随着用户的交互数据不断学习和成长。传统的模型更新方式,包括 Weaver 1.0 和 2.0 都是集中的大规模更新。我们希望实现的是持续更新。在这方面也下了很多功夫,最近还开源了我们的 self-evolving agent *框架。这个框架现在在 GitHub 上可用,增加了自适应化功能,让整个 Agent 能够从用户行为的轨迹中学习并更新。
*https://arxiv.org/abs/2406.18532
艾之:你刚提到 RecurrentGPT,这个东西对波形来说也是挺关键的。能不能讲一下 RecurrentGPT 那篇论文中核心的一些东西?
姜昱辰:一句话来说,首先它解决什么痛点?大模型的上下文长度有限,它做不到无限式的输出,不像以前的 RNN,它可以无限输出。我们的解决方案主要面向的是长文本和无限输出的场景。
用人话说就是我们设计了一套长短期动态记忆机制,让模型端到端地学会怎么遗忘、怎么记东西,怎么从短期记忆中提取记忆。这种机制解决了大模型在生成长文本后半部分内容时不连贯的问题。
艾之:所以当大模型生成很长的内容时,如果它后面开始漫无边际地胡说八道,其实是它忘了该记住的东西。
姜昱辰:对对对,还有另一个问题。就是大模型的可控性差。我们通过几个层面解决了这个问题:
在微调阶段,我们进行了一个名为 InstructCTG(Instruction based Control Text Generation)*的微调工作,这项技术提高了模型对指令的遵从性。
Agent 框架方面,我们是第一个使用 SOP 控制 Agent 的框架。通过 SOP,我们在 Agent 层面实现了更好的控制。
解码阶段,我们开发了一个叫做 Score-based Decoding 的技术,在解码时加强了模型的可控性。这项技术与我们的 LPA 紧密结合,使模型在生成文本时能够更好地遵循指令。
*https://arxiv.org/abs/2304.14293
艾之:那你觉得 Agent 到应用这一层,它和产品之间的界限清晰吗?还是说可能未来 Agent 就是 AI native 产品最核心的东西?
姜昱辰:非常好的问题。我们现在有个岗位叫 AI 产品经理,但它和传统的互联网产品经理有什么区别?我们对这个岗位有什么期望?我有一些自己的体会。
首先,一个好的 AI 产品经理必须懂 Agent。这是一个非常必要的条件。举个简单的例子,在蛙蛙的产品设计中,如何设计用户体验和用户交互?一方面需要考虑用户使用的流畅性,另一方面也要考虑现有技术的局限。虽然蛙蛙在一致性上表现优于 GPT,但它仍然有限制,这时候产品的交互设计就可以弥补其中 80% 的 GAP。
我们最近在讨论能否将蛙蛙的 memory 变成可见的、用户可以操作的部分。通过开放自然语言接口,让用户可以直接查看和修改模型的 memory。如果用户在使用过程中发现某些 memory 需要去掉,他们就可以直接删除。这种设计思路是传统产品经理想不到的,纯算法的技术人员如果没有产品设计的敏感度,也不会去考虑这个问题。
所以我觉得AI 时代对产品经理,以及应用团队提出了更高的要求。他们不仅需要具备传统的产品设计和用户体验设计能力,还需要了解和理解 AI 技术的特点和局限,找到技术与用户需求之间的最佳平衡点。
艾之:对,所以产品经理不能仅仅是懂模型,还要需要去理解垂域模型和基础模型之间相互演进的关系,怎么把一个好的大模型微调成你想要的,怎么把推理/Agent 的东西做得更好。
姜昱辰:评论区的网友讲得特别好,Agent 是一种交互方式,我特别认同。我觉得 Agent 的设计能力在这个时代不应该是做模型的人掌握的能力,而是产品经理应该掌握的能力。
艾之:所以我们在讨论 AI 产品的用户体验的时候,核心在讨论的是 Agent 的机制问题。
姜昱辰:对,我觉得双向思考是必要的。一方面,你仍然需要关注用户,这跟互联网时代没有任何区别。你需要为市场和用户设计产品。另一方面,你还必须考虑在当前技术边界内,如何进行设计来达到最佳效果。
艾之:我比较好奇在用户开始接触你们产品的时候,这个时候模型对用户是完全不了解的,没有办法做一些个性化的自适应工作,你们是怎么解决这个问题的?怎么让数据飞轮转起来的?
姜昱辰:个性化并不是我们在上线第一天就做的事情,而是一个逐步推进的过程。我们先进行了大量的长期工作,使产品达到了一个能用的 80 分水平,然后才上线。这项个性化技术是在上线半年后推出的,因为我们需要先收集用户的数据反馈并进行有效的互动,在保障用户隐私的情况下,使个性化变得可行。
在产品上线的第一天,我们就非常注重数据的收集和结构化构建。我们从一开始就认为需要 agent 和保障隐私的个性化,因此进行了充分的数据准备工作。所以我们先发布一个差不多能用的版本,打磨出一套数据 feed 机制,结构化地来收集数据。再等它转到一定程度,积累了足够多的用户数据和反馈后,我们再利用这些数据进行个性化训练。
艾之:所以你是先用 RecurrentGPT 结合模型,先把用户的数据搞到,给用户建模,之后再上 LPA,把整个事情转起来。
评论区有人说,在基础模型之上去额外建设很多工程化的工作,包括设计一些算法机制尝试去弥补大模型本身。这种堆砌工作是不是走偏了?将低代码平台无法堆起来的问题沿用到了 AI 时代,你怎么看?
姜昱辰:我觉得讲得特别好,非常同意。这里有两个点:
首先,不应该把我们的工作仅仅看作是在弥补大模型的不足。如果只是弥补不足,我们可能会被 OpenAI 干掉。更准确地说,我们是在补充大模型的功能,在 scaling 方面的提升会提供更长期的价值。
另一个是定制化的问题。低代码平台常常被认为不够实用,主要是因为它们在定制化和通用性之间难以找到平衡。每个场景的优化需要独特的设计,这往往会导致解决方案只能达到一个局部最优,而难以广泛适用。
在 AI 时代,只是做「手搓 Agent」的工作,是换汤不换药,本质上没有任何变化。有一个很有前景的技术,就是通过自然语言交互来设计 Agent 流程。将整个过程预置化,这样不仅提高了通用性,还大大简化了用户的操作。所以这是我认为可能破局的点。
艾之:明白,就是你先把里面的那个机制先做好了之后,再不断地优化和简化用户和产品的交互界面以及模型之间的距离。
姜昱辰:对,我觉得 AI 时代最需要关心的一个事情就是人和 AI 的交互。Human AI interaction。这个我觉得是非常非常重要的一个设计。怎么设计一个好的交互,让人在特别舒服又省力的情况下把 AI 生成的一些错误东西给纠正了,然后很轻松地做可控式搭建,应该是这样的一个工作。
艾之:长文本理解和长文本生成,这两件事情的技术难度到底如何?是不是说理解就比生成更容易,还是更难?
姜昱辰:我觉得这两个的技术栈都挺难的。
长文本理解涉及到逻辑能力和对信息的处理能力。理解和解析信息需要较强的逻辑推理能力,这是从能力角度出发的要求。从技术角度来说我们面临的挑战是如何在有限的上下文窗口内增强模型的理解能力,这可能就会涉及到 scaling。
生成不一样,它需要维持自一致性和逻辑连贯性。生成模型要能够在长时间(甚至是 life-long)内保持逻辑一致性,这在处理大量文本生成时尤为重要。从技术方案来说,我们现在用的是 recurrent decoding 方案,关注如何在上下文窗口大小不变的情况下让模型有更好的记忆更新机制的问题。Recurrent decoding 技术的一个主要限制是它对大量文本的处理速度较慢,因为它需要逐轮生成和处理内容,可能不适合需要「量子速读」的场景。
艾之:就长文本生成来说,输出文字长度到什么程度就能达到专业水平?
姜昱辰:体感来说 50 万字以上你就会感受到一个比较明显的差距了,这时候如果没有用专门一套长文本生成的方案,一般模型带不动这么长的 context。
艾之:所以说,如果有一个模型可以一直服务于我们做个性化的事情,在接下来的所有时间里都保持一致,这是非常有价值的一套框架。
我自己试你们产品的时候,能感觉到蛙蛙生成的文风相比 GPT-4 更有人味,机器的味道没有那么重。你们是怎么做到比它生成得快还好的?

姜昱辰:我们有几个维度的调整。
第一我们在文风上做了一些调整。尤其是在从通用领域进入垂直领域的时候。对于输出要求很高的场景,文本上的调整尤为关键。这里并不是说数据越多越好,而是需要有高质量的数据。所以如何精选高质量的数据成了我们非常重要的工作。
我们当时手上有 5T 的数据量,最后其实只选出了 50GB 的数据。这是一个非常严格的筛选过程。我们意识到并不是越多越好,而是需要一个「黄金配比」,比如多少中文、多少英文、多少小语种。这种好的配比是至关重要的,因为即使你要训练一个中文模型,也并不意味着你只需要中文的语料。跨语言的转换能力(cross-lingual transferability)也非常重要。
第二,在 SFT(Supervised Fine-Tuning)阶段,我们做了一个叫做「指令的反向翻译」(instruction back translation)的技术。因为我们主要是一个输出场景,输出质量非常重要,必须是「杰作」。所以我们拿过来一批好作品,标注出它们的特征和模式,这个任务比正向标注简单得多,高效得多。
第三,在 RLHF(Reinforcement Learning from Human Feedback)阶段,我们做了一个技术叫 Constitutional DPO。这个技术的核心是将模型的任务分解,每个模型只需负责一个方向,比如人物的一致性,内容的趣味性等等。这样做的好处是任务更轻松,大大提升了标注员之间的一致性(IAA),这反过来又帮助了模型的训练。
艾之:可不可以理解成,把一个比较抽象的形容词,比如说「好」或者「不好」先进行量化拆解。我们先要把抽象的概念转化为一些具体的、可测量的指标。然后在每一个量化的拆解部分,我们再将其对应到一个具体的模型。这个模型的任务非常明确、非常聚焦,只负责处理特定的指标,不涉及其他方面的内容。接下来,我们会分析在这几个象限中,什么样的作品表现得最好,以及它们在这些象限中具体表现如何。如果一个作品在这些象限中都表现得很好,那么我们就认为它是写得好的。
姜昱辰:对,这也是一个很好的把行业 know-how 用起来的例子。我们请了大量专业的作者过来确定标准,把行业 know-how 给沉淀下来。
艾之:你们在做的就是把一些手艺活的东西,尽可能地用理性去拆解它。有评论区提问,蛙蛙会用大量的生成数据吗?
姜昱辰:会,这其实就是我前面提到的,instruction back translation 和 Constitutional DPO 本质上就是一种数据合成的范式。我们应用了大量自动化的数据标注流程。虽然在系统中确实有一部分数据是由人类标注的,但这些人类标注的数据更多是作为一个参考数据集,用来训练数据标注模型。所以整个过程是一个相当长的 pipeline,其中包含了非常多由 AI 自己生成的数据。
艾之:我们刚才提到,从模型到产品大致分了几个层次。你们基本上是从模型层以上逐步构建的。那么你觉得,现在的创业团队是否也需要从这个层次开始?当时波形创业时,你们是如何判断这是一个合适的时间点?
因为回顾过去十年,不同的产业阶段确实适合不同类型的创业者下场创业。如果个人与时代无法同频共振,很多时候是无法推出好的产品,也无法培养出优秀的公司。所以节奏感非常重要,你对此有什么个人的思考?
姜昱辰:我觉得是这样的,现在的 AI 是一个涉及未来 10 到 20 年,甚至 30 年的大事件,这一点大家应该都有共识。在这样一个背景下,我们刚刚经历的过去一到两年的时间,其实是非常早期的阶段。所以 AI 确实是一个改变时代的技术,但这不是一蹴而就的。你看从上世纪 40 年代第一台计算机 ENIAC 的发布到真正 PC 普及和互联网兴起,中间还隔了很长时间。
所以我的建议是,如果你身处这个行业,需要有耐心,你需要做出一些贡献。回到前面的问题——什么样的人适合进来?我觉得,至少你要对技术栈有所贡献,现在进来才是合适的。因为当前的技术栈还不完整,所有人都需要在造轮子上做一些事情。如果你对造轮子有热情并且有相关的技术经验,那么现在下场是非常好的时机。现在是开荒阶段,你可以获得非常宝贵的经验,而且你可以在市场和场景中找到很多好的技术栈机会,处于一个非常有利的位置。
总而言之我觉得这件事没有明确标准。没有特别明确的答案可以说什么样性格的人适合现在加入,什么背景的人不适合。这是非常个人化的选择,关键在于你是否拥抱这个时代。如果你愿意,那就欢迎你的加入。
艾之:波形在产品开发和市场反馈上已经达成了一个小的 TPF 闭环,虽然还未完全成熟。但我相信,在这一年半的创业过程中,你一定也在不断思考 TPF 和 PMF 的问题。作为一个从吭哧吭哧写论文的研究人员,转变为吭哧吭哧跑市场、跑用户的创业者,你感觉找到一些手感了吗?
姜昱辰:确实,我的思考也在变得越来越深刻。早期更多关注的是 TMF,认为某个场景可以通过技术来解决问题,或者觉得某个痛点很重要,就投入时间和资源去攻克技术难题。但现在更多的是看 TPF,如何在产品交互设计上优化,让技术与产品结合得更好,实现质的提升。这是我在创业过程中学到的一大课题,确实有了更深刻的认知。
艾之:那你当时选择的时候是如何评估这个市场和场景的?
姜昱辰:我们当时确认这是一个高频需求市场,并且在现有技术范围内能够实现 TPF。多个因素叠加后,我认为这是一个值得进入的市场。另外就是要热爱,不热爱整个过程会非常痛苦。
艾之:你们有走过什么弯路吗?
姜昱辰:肯定有。最初尝试的方向偏向于纯 AI 驱动的解决方案,但发现产品边界在那个阶段无法找到 TPF。然后我们就调整了策略,转向更用户导向的方案,在这一过程中找到了某种程度的 PMF。接下来的一段时间里,我们可能会回过头重新评估之前的方向,看看是否达到了 TPF 的临界点。如果达到了,我们一定会继续推进。
艾之:你觉得现在蛙蛙产品算成了吗?到什么节点,取得什么里程碑的时候你觉得可以跟大家很自信地说,我们做成了这件事?
姜昱辰:「成了」这个词确实很微妙。我感觉从 PMF 的角度来说,蛙蛙确实已经算是跑通了 PMF,ROI 也达到了正收益,我们在为用户创造价值。从用户留存和日均使用时长来看,这确实达到了一个闭环产品的水准。
但从另一个角度来说,蛙蛙作为一个工具型产品,不管是从我们自身的角度,还是从整个 AI 发展的角度来看,它其实还是一个中间态的产品。就像我前面提到的,我们最初想做的是一个互动内容平台,而蛙蛙写作的核心使命其实是为我们积累数据和沉淀技术,以便我们未来能够做出更高级、更有趣的产品形态。
艾之:你会怎么看波形?一方面你们在推进技术的发展,另一方面也在不断尝试做一些产品,持续观察市场需求。我看你们基本上以半年为一个小周期,较大幅度地迭代产品和开拓场景。到底哪一条线才是你们真正的主轴线呢?
姜昱辰:用一句话定义,我觉得我们是一个持续寻找 TPF 的组织。在产品跟技术上就会相辅相成,互相去迭代,去成就。半年对于创业公司来说节奏上也是比较好的一个迭代周期。
原文转自 微信公众号@Founder Park







