OAuth和OpenID Connect图解指南

随着大型语言模型(LLM)的发展,人工智能正处于变革的爆发期。众所周知,LLM 可用于商业、科学和金融等应用,因而越来越多的公司(OpenAI、AI21、CoHere 等)都在提供 LLM 作为基础服务。虽然像 GPT-4 这样的 LLM 在问答等任务中取得了前所未有的性能,但因为其高吞吐量的特质,使得它们在应用中非常昂贵。
例如,ChatGPT 每天的运营成本超过 70 万美元,而使用 GPT-4 来支持客户服务可能会让一个小企业每月花费超过 2.1 万美元。除了金钱成本外,使用最大的 LLM 还会带来巨大的环境和能源影响。
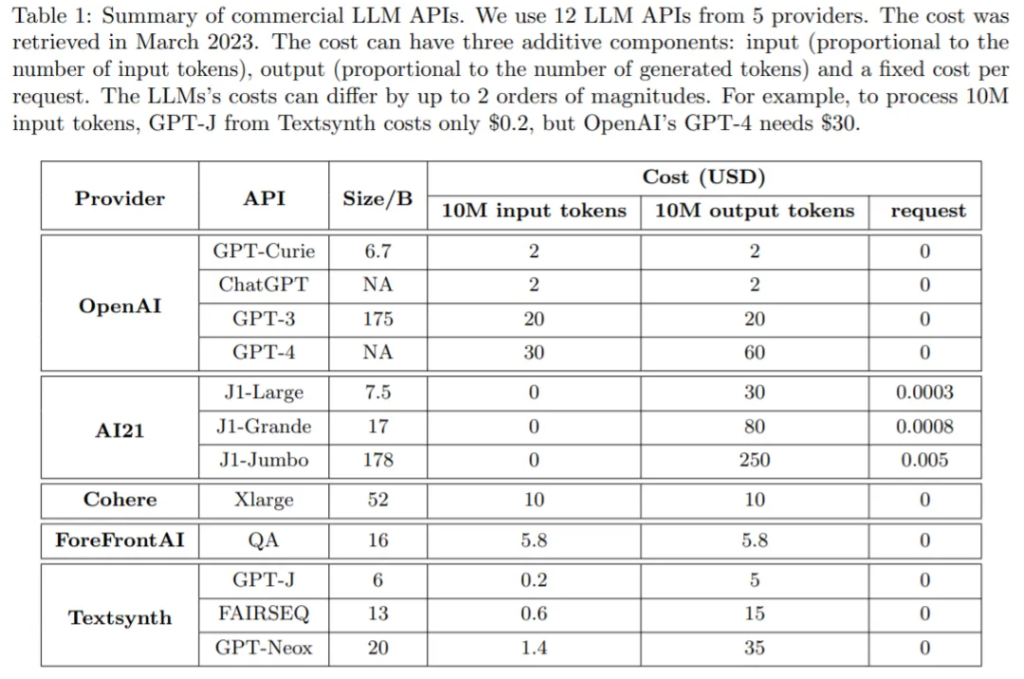
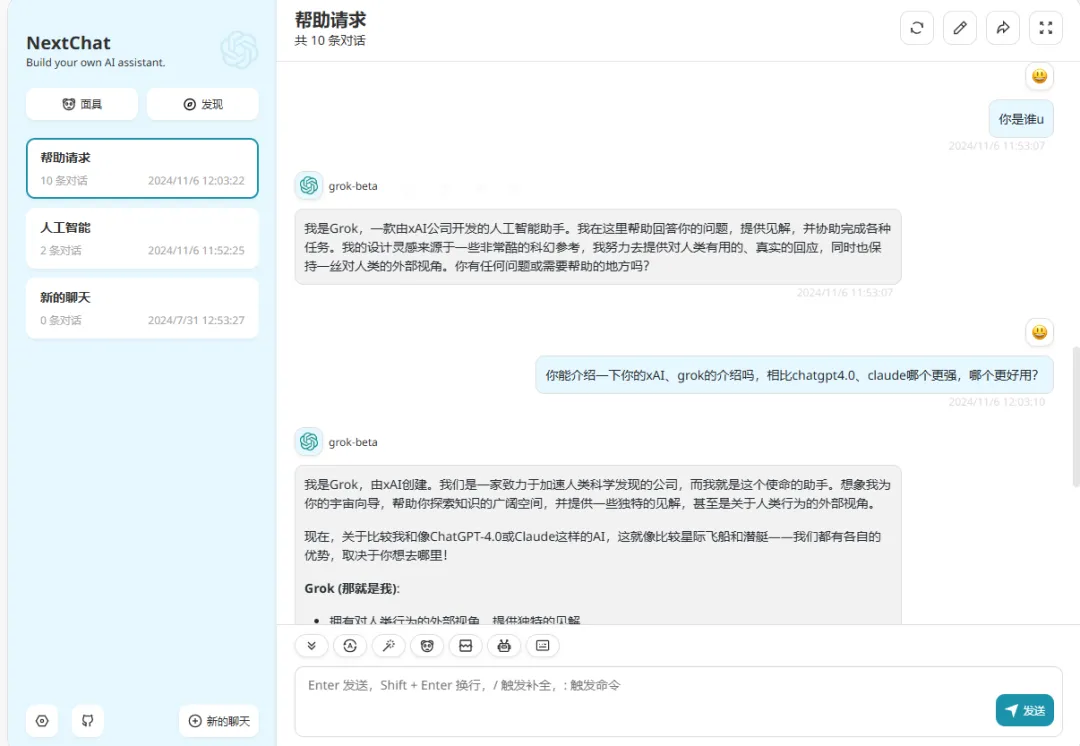
现在很多公司通过 API 提供 LLM 服务,它们收费各异。使用 LLM API 的成本通常包括三个组成部分:1)prompt 成本(与 prompt 的长度成比例),2)生成成本(与生成的长度成比例),以及 3)有时还会有对于每个查询的固定成本。
下表 1 比较了 12 个不同商业 LLM 的成本,这些 LLM 来自主流供应商,包括 OpenAI、AI21、CoHere 和 Textsynth。它们的成本相差高达 2 个数量级:例如,对于 1000 万个 token,OpenAI 的 GPT-4 的 prompt 成本为 30 美元,而 Textsynth 托管的 GPT-J 仅为 0.2 美元。
成本和准确性之间的平衡是决策制定的关键因素,尤其是在采用新技术时。如何有效和高效地利用 LLM 是从业者面临的关键挑战:如果任务相对简单,那么聚合来自 GPT-J (其规模比 GPT-3 小 30 倍)的多个响应可以实现与 GPT-3 类似的性能,从而实现成本和环境上的权衡。然而,在较为困难任务上,GPT-J 的性能可能会大大下降。因此,如何经济高效地使用 LLM 需要采用新的方法。
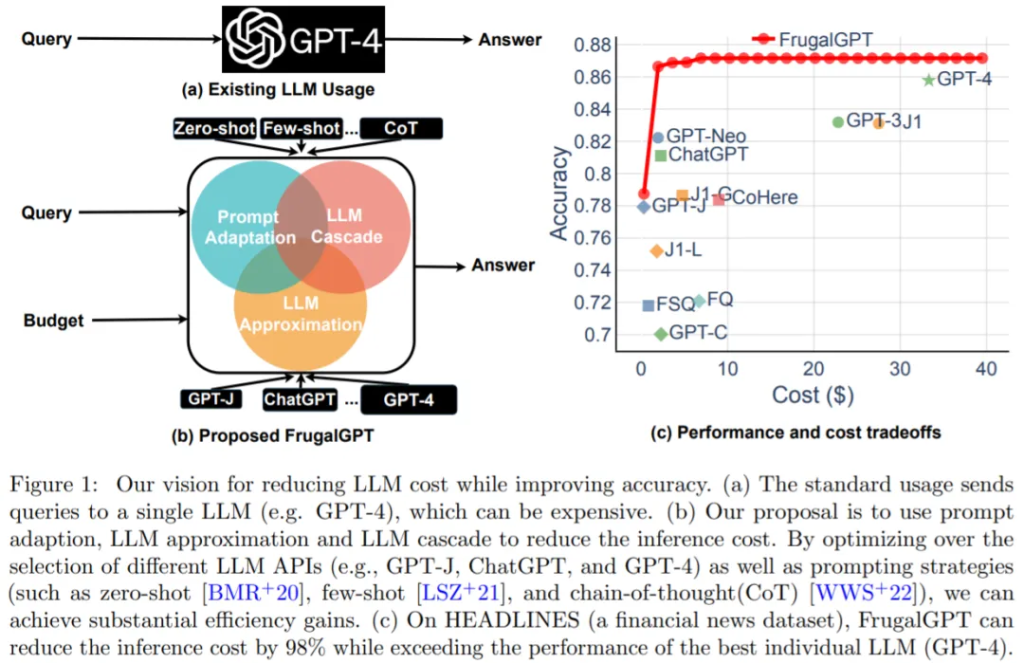
最近的一项研究尝试提出解决这一成本问题的方法,研究者通过实验表明,FrugalGPT 可以与最佳个体 LLM(例如 GPT-4) 的性能相媲美,成本降低高达 98%,或者在相同成本下将最佳个体 LLM 的准确性提高 4%。

来自斯坦福大学的研究者回顾了使用 LLM API(例如 GPT-4,ChatGPT,J1-Jumbo)所需的成本,并发现这些模型具有不同的定价,费用可能相差两个数量级,特别是在大量查询和文本上使用 LLM 可能更昂贵。基于这一点,该研究概述并讨论了用户可以利用的三种策略来降低使用 LLM 的推理成本:1)prompt 适应,2)LLM 近似和 3)LLM 级联。此外,该研究提出了级联 LLM 一个简单而灵活的实例 FrugalGPT,它学习在不同查询中使用哪些 LLM 组合以减少成本并提高准确性。
这项研究提出的思想和发现为可持续高效地使用 LLM 奠定了基础。如果能够在不增加预算的情况下采用更高级的 AI 功能,这可能会推动人工智能技术在各个行业的更广泛采用,即使是较小的企业也有能力在其运营中实施复杂的人工智能模型。
当然,这只是一个角度,FrugalGPT 到底能实现怎样的影响力,能否成为「AI 行业的游戏规则改变者」,还需要一段时间才能揭晓。在论文发布之后,这项研究也引发了一些争议:

「摘要严重夸大了论文的内容,这里的标题也有严重的误导性。他们所做的是设计了一种方法,以减少在论文中所涉及的一类问题中需要调用高端模型的次数。这不是以 2% 的成本替代 GPT-4,也不是以 4% 的精度替代 GPT-4。它是一种将 GPT-4 与更低廉的模型和支持性基础设施相结合的方法。摘要中没有指出的是,这需要建立一个自定义模型来对结果进行评分,而这是该机制的真正核心。…… 这种方法有合法的用例,其中包括基本的成本工程,如缓存结果。但对于大多数用例来说,这完全不相关,因为你没有一个合适的评分模型。」

「他们只在三个(小的)数据集上评估了这一点,并且没有提供关于 FrugalGPT 选择各自模型的频率的信息。另外,他们报告说较小的模型取得了比 GPT-4 更高的准确性,这使我对这篇论文总体上非常怀疑。」
具体如何判断,让我们看一下论文内容。
接下来论文介绍了如何在预算范围内高效的使用 LLM API。如图 1 (b) 所示,该研究讨论了三种降低成本的策略,即 prompt 适应、LLM 近似和 LLM 级联。
策略 1:prompt 适应。LLM 查询的成本与 prompt 的大小呈线性增长。因此,降低使用 LLM API 成本的一个合理方法包括减小 prompt 大小,该研究将这个过程称为 prompt 适应。prompt 选择如图 2(a)所示:与使用包含许多示例以演示如何执行任务的 prompt 相比,可以只保留 prompt 中的一个小子集示例。这将导致更小的 prompt 和更低的成本。另一个例子是查询串联(图 2(b)所示)。
策略 2:LLM 近似。LLM 近似的概念非常简单:如果使用 LLM API 成本太高,可以使用更实惠的模型或基础设施进行近似。其中一个例子如图 2(c)所示,其基本思想是在向 LLM API 提交查询时将响应存储在本地缓存(例如数据库)中。LLM 近似的另一个例子是模型微调,如图 2 (d) 所示。
策略 3:LLM 级联。不同的 LLM API 在各种查询中都有自己的优势和劣势。因此,适当选择要使用的 LLM 既能降低成本又能提高性能。如图 2(e)所示为 LLM 级联的一个例子。
研究者进行了一项关于 FrugalGPT LLM 级联的实证研究,目标有三个:
实验设置分为几方面:LLM API(表 1)、任务、数据集(表 2)和 FrugalGPT 实例。
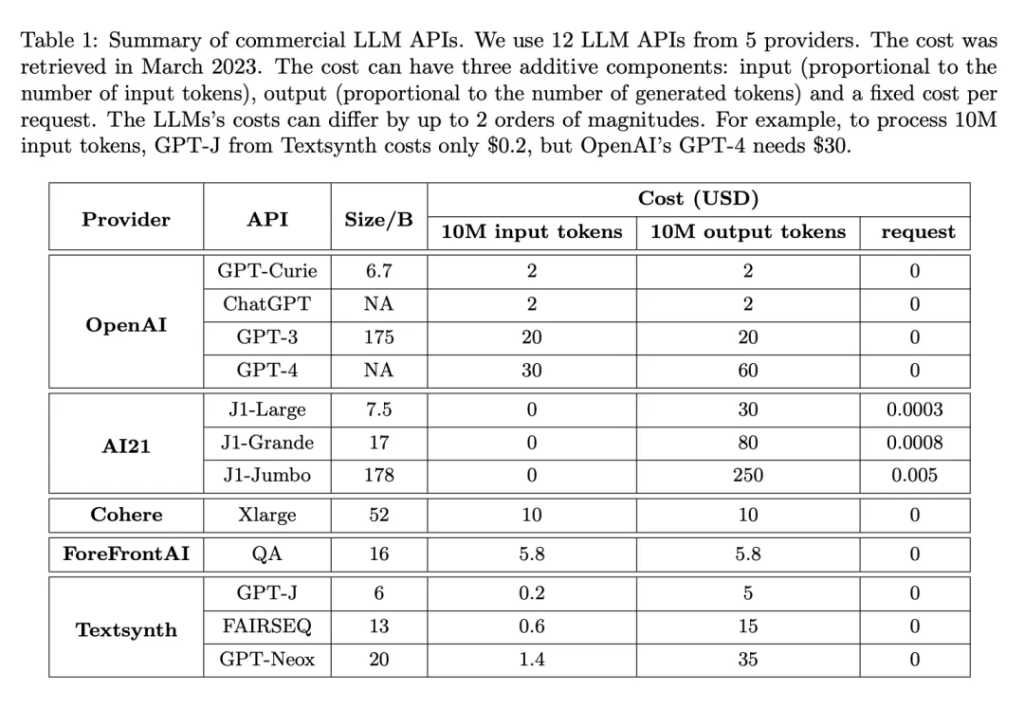
FrugalGPT 是在上述 API 之上开发的,并在一系列属于不同任务的数据集上进行了评估。其中,HEADLINES 是一个金融新闻数据集,目标是通过阅读金融新闻标题来确定金价趋势(上升、下降、中性或无),这对于过滤金融市场的相关新闻特别有用;OVERRULING 是一个法律文件数据集,其目标是确定一个给定的句子是否是一个「overruling」,即推翻以前的法律案件;COQA 是一个在对话环境中开发的阅读理解数据集,研究者将其改编为一个直接查询回答任务。
他们专注于 LLM 级联方法,级联长度为 3,因为这简化了优化空间,并且已经展示了良好的结果。每个数据集被随机分成一个训练集来学习 LLM 级联和一个测试集进行评估。
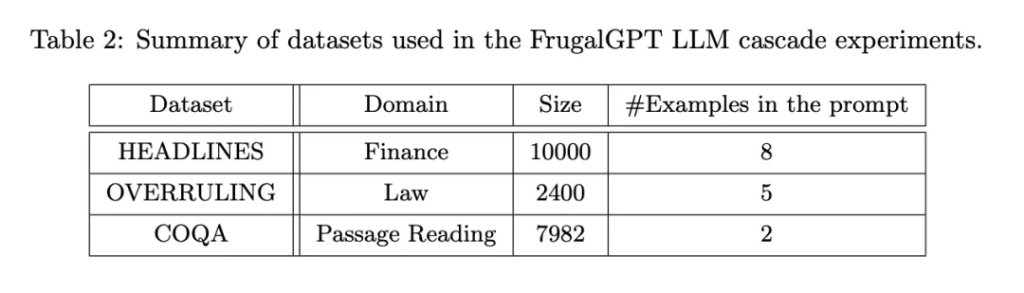
这里是一个 HEADLINES 数据集案例研究:设定预算为 6.5 美元,是 GPT-4 成本的五分之一。采用针对回归的 DistilBERT [SDCW19] 作为评分函数。值得注意的是,DistilBERT 比这里考虑的所有 LLM 都要小得多,因此成本较低。如图 3(a)所示,学习的 FrugalGPT 顺序调用 GPT-J、J1-L 和 GPT-4。对于任何给定的查询,它首先从 GPT-J 中提取一个答案。如果这个答案的分数大于 0.96,这个答案就被接受为最终的响应。否则,将对 J1-L 进行查询。如果 J1-L 的答案得分大于 0.37,则被接受为最终答案;否则,将调用 GPT-4 来获得最终答案。有趣的是,这种方法在许多查询中都优于 GPT-4。例如,基于纳斯达克的头条新闻「美国 GDP 数据惨淡,黄金脱离低点」,FrugalGPT 准确地预测了价格将下跌,而 GPT-4 提供了一个错误的答案(如图 3(b)所示)。
总体来说,FrugalGPT 的结果是既提高了准确率又降低了成本。如图 3 (c) 所示,其成本降低了 80%,而准确率甚至高出 1.5%。
为什么多个 LLM API 有可能产生比最好的单个 LLM 更好的性能?从本质上讲,这是由于生成的多样性:即使是一个低成本的 LLM 有时也能正确地回答更高成本的 LLM 所不能回答的查询。为了衡量这种多样性,研究者使用最大的性能改进,也可以成为 MPI。LLM A 相对于 LLM B 的 MPI 是指 LLM A 产生正确答案而 LLM B 提供错误答案的概率。这个指标实质上是衡量在调用 LLM B 的同时调用 LLM A 所能达到的最大性能提升。
图 4 显示了所有数据集的每一对 LLM API 之间的 MPI。在 HEADLINES 数据集上,GPT-C、GPT-J 和 J1-L 都可以将 GPT-4 的性能提高 6%。在 COQA 数据集上,有 13% 的数据点 GPT-4 出现了错误,但 GPT-3 提供了正确的答案。尽管这些改进的上界可能并不总是可以实现的,但它们确实证明了利用更低廉的服务来实现更好性能的可能性。

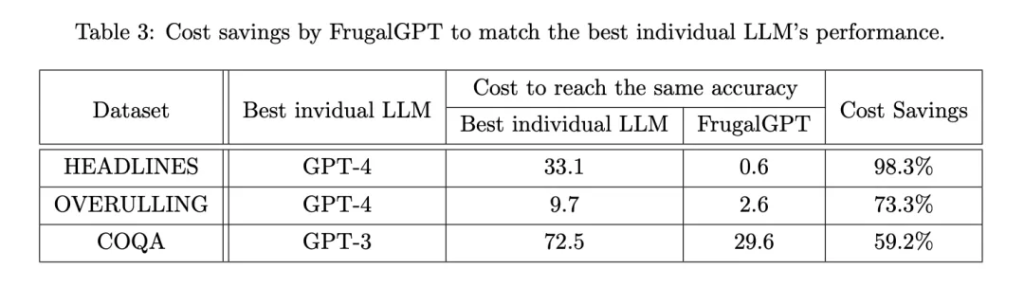
随后,研究者考察了 FrugalGPT 是否能在保持准确性的同时降低成本,如果能,又能降低多少。表 3 显示了 FrugalGPT 的总体成本节约,范围从 50% 到 98%。这是可行的,因为 FrugalGPT 可以识别那些可以由较小的 LLM 准确回答的查询,因此只调用那些具有成本效益的 LLM。而强大但昂贵的 LLM,如 GPT-4,只用于由 FrugalGPT 检测到的挑战性查询。
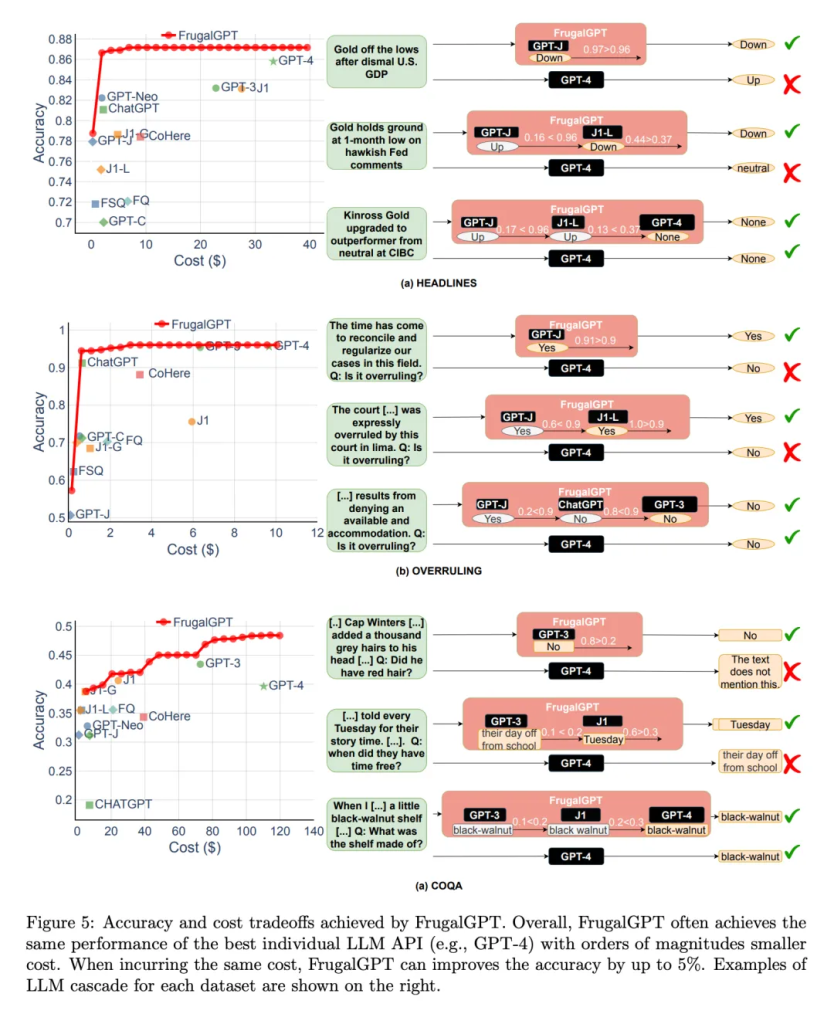
接着,研究者探讨了 FrugalGPT 实现的性能和成本之间的权衡,如图 5 所示,得出了几个有趣的观察结果。
首先,不同 LLM API 的成本排名并不是固定的。此外,更昂贵的 LLM APIs 有时会导致比其更便宜的同类产品更差的性能。这些观察结果强调了适当选择 LLM API 的重要性,即使在没有预算限制的情况下。
接下来,研究者还注意到,FrugalGPT 能够在所有被评估的数据集上实现平滑的性能 – 成本权衡。这为 LLM 用户提供了灵活的选择,并有可能帮助 LLM API 供应商节约能源和减少碳排放。事实上,FrugalGPT 可以同时降低成本和提高精确度,这可能是因为 FrugalGPT 整合了来自多个 LLM 的知识。
图 5 所示的例子查询进一步解释了为什么 FrugalGPT 可以同时提高性能和降低成本。GPT-4 在一些查询上犯了错误,比如例如(a)部分的第一个例子,但一些低成本的 API 提供了正确的预测。FrugalGPT 准确地识别了这些查询,并完全依赖低成本的 API。例如,GPT-4 错误地从法律陈述「现在是协调和规范我们在这个领域的案件的时候了」中推断出没有推翻,如图 5(b)所示。然而,FrugalGPT 接受了 GPT-J 的正确答案,避免了昂贵的 LLM 的使用,提高了整体性能。当然,单一的 LLM API 并不总是正确的;LLM 级联通过采用一连串的 LLM API 克服了这一点。例如,在图 5 (a) 所示的第二个例子中,FrugalGPT 发现 GPT-J 的生成可能不可靠,于是转向链中的第二个 LLM J1-L,以找到正确的答案。同样,GPT-4 提供了错误的答案。FrugalGPT 并不完美,仍有足够的空间来减少成本。例如,在图 5 (c) 的第三个例子中,链中所有的 LLM API 都给出了相同的答案。然而,FrugalGPT 不确定第一个 LLM 是否正确,导致需要查询链中的所有 LLM。确定如何避免这种情况仍然是一个开放的问题。
更多研究细节,可参考原论文。
参考链接:https://www.reddit.com/r/singularity/comments/13dnfd7/frugalgpt_can_match_the_performance_of_the_best/
文章转自微信公众号@机器之心